



Einführung
Stellen Sie sich vor, Sie bauen einen medizinischen Chatbot auf, und die massiven, ressourcenhungrigen Großsprachenmodelle (LLMs) scheinen für Ihre Bedürfnisse übertrieben zu sein. Hier kommen kleine Sprachmodelle (SLMs) wie Gemma ins Spiel. In diesem Artikel untersuchen wir, wie SLMs Ihre perfekte Lösung für fokussierte, effiziente KI -Aufgaben sein können. Wenn Sie verstehen, was Gemma einzigartig macht, um es für spezialisierte Bereiche wie Healthcare zu optimieren, führen wir Sie durch den gesamten Prozess. Sie erfahren, wie gut abtürt wird, sondern auch die Leistung, sondern auch die Kosten senkt und die Latenz reduziert, wodurch SLMS zu einem Spielveränderer in der KI-Landschaft wird. Unabhängig davon, ob Sie an engen Budgets arbeiten oder auf Edge -Geräten bereitstellen, zeigt dieser Artikel Ihnen, wie Sie die SLMs für Ihre spezifischen Anforderungen optimal nutzen können. Dieser Artikel basiert auf einem aktuellen Vortrag, der Nikhil Rana und Joinal über die Feinabstimmung und den Inferenz kleiner Sprachmodelle wie Gemma auf dem Datahack Summit 2024 gibt.
Lernergebnisse
- Verstehen Sie die Vorteile kleiner Sprachmodelle (SLMs) wie Gemma gegenüber großen Sprachmodellen (LLMs).
- Erfahren Sie, wie wichtig es ist, SLMs für domänenspezifische Aufgaben zu finden und die Leistung zu verbessern.
- Erforschen Sie den Schritt-für-Schritt-Prozess der feinen SLMs mit Beispielen und wichtigen Überlegungen.
- Entdecken Sie Best Practices für die Bereitstellung von SLMs und die Reduzierung der Latenz auf Kantengeräte.
- Identifizieren Sie häufige Herausforderungen bei der Feinabstimmung von SLMs und wie Sie sie effektiv überwinden können.
Inhaltsverzeichnis
- Einführung
- Was sind kleine Sprachmodelle?
- Vorteile von SLMs gegenüber LLMs
- Was ist Gemma?
- Verschiedene Versionen von Gemma
- Was ist Feinabstimmung?
- Feinabstimmungsprozess
- Wann verwenden Sie SLMS vs. LLMs für Inferenz?
- Überlegungen vor der Bereitstellung von SLMs
- MediaPipe und WebAssembly für die Bereitstellung von SLMs on Edge -Geräte
- Wie werden LLMs heute bereitgestellt?
- Wie kann SLMS mit weniger Parametern gut funktionieren?
- Abschluss
- Häufig gestellte Fragen
Was sind kleine Sprachmodelle?
Kleinsprachenmodelle sind verkleinerte Versionen der am häufigsten bekannten Großsprachenmodelle. Im Gegensatz zu ihren größeren Gegenstücken, die auf riesigen Datensätzen trainieren und erhebliche Rechenressourcen erfordern, sind SLMs leichter und effizienter ausgelegt. Sie zielen auf bestimmte Aufgaben und Umgebungen ab, in denen Geschwindigkeit, Speicher und Verarbeitungsleistung von entscheidender Bedeutung sind.
SLMs bieten mehrere Vorteile, einschließlich reduzierter Latenz und niedrigeren Kosten bei der Bereitstellung, insbesondere in den Edge -Computing -Szenarien. Während sie möglicherweise nicht über das expansive allgemeine Kenntnis von LLMs verfügen, können sie mit domänenspezifischen Daten fein abgestimmt werden, um spezielle Aufgaben mit Präzision auszuführen. Dies macht sie ideal für Szenarien, in denen schnelle, ressourceneffiziente Antworten unerlässlich sind, z. B. in mobilen Anwendungen oder Geräten mit geringer Leistung.
SLMS ist ein Gleichgewicht zwischen Leistung und Effizienz und macht sie zu einer leistungsstarken Alternative für Unternehmen oder Entwickler, die ihre KI-betriebenen Lösungen ohne die mit LLM verbundenen starken Gemeinkosten optimieren möchten.

Vorteile von SLMs gegenüber LLMs
Kleinsprachenmodelle bieten mehrere Vorteile gegenüber ihren größeren Kollegen, Großsprachenmodellen, insbesondere in Bezug auf Effizienz, Präzision und Kosteneffizienz.
Maßgeschneiderte Effizienz und Präzision
SLMs sind speziell für gezielte, oft Nischenaufgaben ausgelegt, sodass sie ein Genauigkeitsniveau erreichen können, das allgemeine LLMs möglicherweise nicht leicht erreichen. Durch die Konzentration auf bestimmte Domänen oder Anwendungen können SLMs ohne den unnötigen Aufwand des verallgemeinerten Wissens hochrelevante Ausgänge erzeugen.
Geschwindigkeit
Aufgrund ihrer kleineren Größe bieten SLMs eine geringere Latenz in der Verarbeitung und können sie perfekt für Echtzeitanwendungen wie AI-gesteuerten Kundendienst, Datenanalyse oder Konversationsmittel, bei denen schnelle Antworten kritisch sind, perfekt gemacht. Diese verkürzte Verarbeitungszeit verbessert die Benutzererfahrung, insbesondere in ressourcenbezogenen Umgebungen wie mobilen oder eingebetteten Systemen.
Kosten
Die reduzierte Rechenkomplexität von SLMs führt zu geringeren finanziellen Kosten. Schulungen und Bereitstellungen sind weniger ressourcenintensiv, was SLMs erschwinglicher macht. Dies ist ideal für kleine Unternehmen oder bestimmte Anwendungsfälle. SLMs benötigen weniger Schulungsdaten und Infrastruktur und bieten eine kostengünstige Alternative zu LLMs für leichtere Anwendungen.
Was ist Gemma?
Gemma ist ein herausragendes Beispiel für ein kleines Sprachmodell (SLM), das spezifische Anwendungsfälle mit Präzision und Effizienz behandelt. Es sticht als maßgeschneiderte Lösung in der Landschaft von Sprachmodellen hervor, um die Stärken kleinerer Modelle zu nutzen und gleichzeitig eine hohe Leistung in gezielten Anwendungen aufrechtzuerhalten.
Gemma ist bemerkenswert für seine Vielseitigkeit über verschiedene Versionen hinweg, die jeweils für verschiedene Aufgaben optimiert sind. Zum Beispiel richten sich verschiedene Versionen von Gemma an die Bedürfnisse, die von der Kundenunterstützung bis hin zu spezialisierteren Bereichen wie medizinischen oder rechtlichen Bereichen reichen. Diese Versionen verfeinern ihre Fähigkeiten, um ihren jeweiligen Anwendungsbereichen zu entsprechen, um sicherzustellen, dass das Modell relevante und genaue Antworten liefert.
Die leichte und effiziente Architektur von Gemma weist ein Gleichgewicht zwischen Leistung und Ressourcenverwendung auf, wodurch sie für Umgebungen mit begrenzter Rechenleistung geeignet ist. Die vorgebreiteten Modelle bieten eine starke Basis für die Feinabstimmung und ermöglichen eine Anpassung für bestimmte Industrieanforderungen oder Nischenanwendungen. Im Wesentlichen zeigt Gemma, wie kleine Sprachmodelle spezielle, qualitativ hochwertige Ergebnisse liefern können und gleichzeitig kostengünstig und ressourceneffizient sind. Unabhängig davon, ob sie breit oder auf bestimmte Aufgaben zugeschnitten ist, erweist Gemma in verschiedenen Kontexten ein wertvolles Instrument.
Verschiedene Versionen von Gemma
Die Gemma-Familie umfasst eine Reihe leichter, hochmoderner Modelle, die auf derselben Forschung und Technologie basieren, die für die Gemini-Modelle verwendet werden. Jede Version von Gemma befasst sich mit bestimmten Anforderungen und Anwendungen und bietet Funktionen, die von der Textgenerierung bis zu multimodalen Funktionen reichen.
Gemma 1 Familie
Die Gemma 1 -Familie repräsentiert die erste Suite von Modellen innerhalb des Gemma -Ökosystems, die ein breites Spektrum von Aufgaben zur Verarbeitung von Text und Erzeugung ausmachen sollen. Diese Modelle sind grundlegend für die Gemma -Serie und bieten verschiedene Funktionen, um unterschiedliche Benutzeranforderungen zu erfüllen. Die Familie kategorisiert Modelle nach Größe und Spezialisierung, wobei jedes Modell verschiedene Stärken für verschiedene Anwendungen bringt.

Gemma 2b und 2b-it :
- GEMMA 2B : Dieses Modell ist Teil der ursprünglichen Gemma 1-Reihe und ist für eine breite Palette von textbasierten Aufgaben mit starker Leistung ausgelegt. Seine allgemeinen Fähigkeiten machen es zu einer vielseitigen Wahl für Anwendungen wie Inhaltserstellung, Verständnis für natürliches Sprache und andere gemeinsame Textverarbeitungsbedürfnisse.
- Gemma 2B-IT : Eine Variante des 2B-Modells ist der 2B-It speziell auf Kontexte zugeschnitten, die sich auf die Informationstechnologie beziehen. Dieses Modell bietet eine verbesserte Leistung für IT-zentrierte Anwendungen, z. B. die Generierung technischer Dokumentation, Code-Snippets und IT-bezogene Abfragen, wodurch es für Benutzer gut geeignet ist, die einen speziellen Support in technologiebedingten Bereichen benötigen.
Gemma 7b und 7b-it :
- GEMMA 7B : Das 7B -Modell repräsentiert eine leistungsstarke Version innerhalb der Gemma 1 -Familie. Die erhöhte Kapazität ermöglicht es ihm, komplexere und vielfältigere Aufgaben der Textgenerierung effektiv zu erledigen. Es ist für anspruchsvolle Anwendungen konzipiert, die ein tieferes Verständnis des Kontextes und eine nuanciertere Textausgabe erfordern, wodurch es für die anspruchsvolle Erstellung von Inhalten und eine detaillierte Verarbeitung natürlicher Sprache geeignet ist.
- Gemma 7B-IT : Aufbau auf den Funktionen des 7B-Modells ist der 7B-It für IT-spezifische Anwendungen optimiert. Es bietet fortschrittliche Unterstützung für Aufgaben wie technische Inhaltegenerierung und komplexe Codeunterstützung, für Benutzer, die leistungsstarke Tools für IT und programmbezogene Herausforderungen benötigen.
Code Gemma
Code -Gemma -Modelle sind spezielle Versionen der Gemma -Familie, die speziell für Programmieraufgaben unterstützt wurden. Sie konzentrieren sich auf den Abschluss der Code und die Erzeugung von Code und bieten wertvolle Unterstützung in Umgebungen, in denen eine effiziente Code -Handhabung von entscheidender Bedeutung ist. Diese Modelle sind optimiert, um die Produktivität in integrierten Entwicklungsumgebungen (IDEs) und Codierungsassistenten zu verbessern.
Code Gemma 2B :
- Der Code Gemma 2B ist auf kleinere Codegenerierungsaufgaben zugeschnitten. Es ist ideal für Umgebungen, in denen die Komplexität der Code -Snippets relativ überschaubar ist. Dieses Modell bietet eine solide Leistung für die Routinecodierungsanforderungen, z. B. das Abschluss einfacher Codefragmente oder die Bereitstellung grundlegender Codevorschläge.
Code Gemma 7b und 7b-it :
- Code Gemma 7B : Dieses Modell, das fortgeschrittener ist, eignet sich für die Behandlung komplexerer Codierungsaufgaben. Es bietet anspruchsvolle Funktionen für die Codebetastung und kann sich mit komplizierten Anforderungen an die Codegenerierung befassen. Die erhöhte Kapazität des 7B-Modells macht es effektiver für anspruchsvollere Codierungsszenarien und bietet verbesserte Genauigkeit und kontextbezogene Vorschläge.
- Code Gemma 7B-IT : Aufbau auf den Funktionen des 7B-Modells wird die 7B-IT-Variante speziell für IT-bezogene Programmieraufgaben optimiert. Es zeichnet sich aus, um Code im Zusammenhang mit IT- und technologiebedingten Projekten zu generieren und zu vervollständigen. Dieses Modell bietet erweiterte Funktionen, die auf komplexe IT -Umgebungen zugeschnitten sind und Aufgaben wie detaillierte Codeunterstützung und technische Inhaltsgenerierung unterstützen.
Wiederkehrender Gemma
Wiederkehrende Gemma -Modelle richten sich an Anwendungen, die eine schnelle und effiziente Textgenerierung erfordern. Sie liefern eine geringe Latenz- und Hochgeschwindigkeitsleistung, wodurch sie ideal für Szenarien, in denen die Echtzeitverarbeitung von entscheidender Bedeutung ist.
- Wiederkehrende Gemma 2b bietet robuste Funktionen für dynamische Aufgaben zur Erzeugung von Text. Die optimierte Architektur sorgt für schnelle Antworten und minimale Verzögerung. Damit ist es ideal für Anwendungen wie Echtzeit-Chatbots, Live-Inhaltsgenerierung und andere Szenarien, in denen eine schnelle Textausgabe unerlässlich ist. Dieses Modell verarbeitet effektiv hochvolumige Anforderungen und bietet eine effiziente und zuverlässige Leistung.
- Wiederkehrender Gemma 2B-It baut auf den Fähigkeiten des 2B-Modells auf, ist jedoch speziell auf Informationstechnologiekontexte zugeschnitten. Es zeichnet sich durch die Erzeugung und Verarbeitung von Text auf IT -Aufgaben und Inhalte mit geringer Latenz aus. Die 2B-It-Variante ist besonders nützlich für IT-fokussierte Anwendungen wie technische Support-Chatbots und dynamische IT-Dokumentation, bei denen sowohl Geschwindigkeit als auch domänenspezifische Relevanz von entscheidender Bedeutung sind.
Paligemma
Paligemma stellt einen signifikanten Fortschritt innerhalb der Gemma -Familie als erstes multimodales Modell dar. Dieses Modell integriert sowohl visuelle als auch textuelle Eingaben und bietet vielseitige Funktionen für den Umgang mit einer Reihe multimodaler Aufgaben.
Paligemma 2.9b :
In Anweisungen und gemischten Versionen im Vertex-Modellgarten erhältlich, zeichnet sich dieses Modell bei der Verarbeitung von Bildern und Text aus. Es liefert Top -Leistung bei multimodalen Aufgaben wie visueller Frage, die Beantwortung, Bildunterschrift und Bilderkennung. Durch die Integration von Bild- und Texteingaben generiert es detaillierte Textantworten basierend auf visuellen Daten. Diese Fähigkeit macht es für Anwendungen, die sowohl visuelles als auch textuelles Verständnis benötigen, sehr effektiv.
Gemma 2 und zugehörige Werkzeuge
Gemma 2 stellt einen signifikanten Sprung in der Entwicklung von Sprachmodellen dar und kombiniert fortschrittliche Leistung mit verbesserten Sicherheits- und Transparenzmerkmalen. Hier ist ein detaillierter Blick auf Gemma 2 und seine zugehörigen Werkzeuge:

Gemma 2
- Leistung : Das 27B -Gemma 2 -Modell ist in seiner Größenklasse ausgestattet und bietet eine herausragende Leistung, die die Modelle mit erheblich größerem Maßstab aufnehmen. Dies macht es zu einem leistungsstarken Werkzeug für eine Reihe von Anwendungen und bietet wettbewerbsfähige Alternativen zu Modellen doppelt so groß.
- 9b Gemma 2 : Diese Variante ist bemerkenswert für ihre außergewöhnliche Leistung, die andere Modelle wie LLAMA 3 8B übertrifft und effektiv mit offenen Modellen in seiner Kategorie konkurriert.
- 2B Gemma 2 : Das 2B-Modell ist für seine überlegenen Konversationsfähigkeiten bekannt und übertrifft die GPT-3,5-Modelle in der Chatbot-Arena und etabliert sich als führende Wahl für die KI der Konversation des Geräts.
Verbundene Werkzeuge
- ShieldgeMma :
- Funktion : ShieldgeMma ist auf Anleitungsmodelle spezialisiert, die die Sicherheit von Eingängen der Textaufforderung und generierten Antworten sicherstellen und sicherstellen.
- Zweck : Es bewertet die Einhaltung der vordefinierten Sicherheitsrichtlinien und macht es zu einem wesentlichen Instrument für Anwendungen, bei denen die Maderung und Sicherheit von Inhalten von entscheidender Bedeutung ist.
- Gemma -Umfang :
- Funktion : Gemma Scope dient als Forschungsinstrument, das darauf abzielt, die inneren Funktionen der Gemma 2 -Generativ -AI -Modelle zu analysieren und zu verstehen.
- Zweck : Es bietet Einblicke in die Mechanismen und Verhaltensweisen des Modells und unterstützt Forscher und Entwickler bei der Verfeinerung und Optimierung der Modelle.
Zugangspunkte
- Google AI Studio : Eine Plattform, die Zugriff auf verschiedene KI -Modelle und Tools, einschließlich Gemma 2, für Entwicklung und Experimente bietet.
- Kaggle : Eine bekannte Plattform für Datenwissenschaft und maschinelles Lernen, auf der Gemma 2-Modelle für Forschung und Wettbewerb verfügbar sind.
- Umarmend : Ein beliebtes Repository für maschinelles Lernenmodelle, einschließlich Gemma 2, in dem Benutzer diese Modelle herunterladen und nutzen können.
- Vertex AI : Ein Google Cloud -Dienst, der Zugriff auf Gemma 2 und andere KI -Tools für skalierbare Modellbereitstellungen und -verwaltung bietet.
Die Fortschritte von Gemma 2 in Bezug auf Leistung, Sicherheit und Transparenz in Kombination mit seinen zugehörigen Tools positionieren sie als vielseitige und leistungsstarke Ressource für eine Vielzahl von AI -Anwendungen und Forschungsbemühungen.
Was ist Feinabstimmung?
Die Feinabstimmung ist ein entscheidender Schritt im Lebenszyklus des maschinellen Lernens, insbesondere für Modelle wie SLMS (Small Language Models). Es umfasst die Anpassung eines vorgebildeten Modells auf einem speziellen Datensatz, um seine Leistung für bestimmte Aufgaben oder Domänen zu verbessern.
Feinabstimmung baut auf einem vorgebildeten Modell auf, das bereits allgemeine Funktionen aus einem breiten Datensatz gelernt hat. Anstatt ein Modell von Grund auf neu zu trainieren, was rechnerisch teuer und zeitaufwändig ist, verfeinert Feinabstimmung dieses Modell, um es für bestimmte Anwendungsfälle besser geeignet zu machen. Die Kernidee besteht darin, das vorhandene Wissen des Modells anzupassen, um bestimmte Arten von Daten oder Aufgaben besser umzugehen.
Gründe für die Feinabstimmung SLMs
- Domänenspezifisches Wissen : Vorausgebildete Modelle können verallgemeinert werden, ohne spezialisiertes Wissen in Nischenbereichen. Mit der Feinabstimmung kann das Modell domänenspezifische Sprache, Terminologie und Kontext einbeziehen, wodurch es für spezielle Anwendungen wie medizinische Chatbots oder Rechtsdokumentenanalysen wirksamer wird.
- Verbesserung der Konsistenz : Selbst leistungsstarke Modelle können ihre Ausgaben variabilisch aufweisen. Die Feinabstimmung hilft bei der Stabilisierung der Antworten des Modells und sorgt dafür, dass es konsequent mit den gewünschten Ausgaben oder Standards für eine bestimmte Anwendung übereinstimmt.
- Reduzierung von Halluzinationen : Große Modelle erzeugen manchmal Reaktionen, die sachlich falsch oder irrelevant sind. Feinabstimmung hilft, diese Probleme zu mildern, indem das Verständnis des Modells verfeinert und seine Ausgaben für bestimmte Kontexte zuverlässiger und relevanter werden.
- Reduzierung der Latenz und Kosten : Kleinere Modelle oder SLMs, die für bestimmte Aufgaben fein abgestimmt sind, können effizienter arbeiten als größere allgemeine Modelle. Diese Effizienz führt zu geringeren Rechenkosten und schnelleren Verarbeitungszeiten, wodurch sie für Echtzeitanwendungen und kostengünstige Umgebungen geeigneter werden.
Feinabstimmungsprozess
Die Feinabstimmung ist eine entscheidende Technik für maschinelles Lernen und natürliche Sprachverarbeitung, die ein vorgebildetes Modell anpasst, um bei bestimmten Aufgaben oder Datensätzen bessere Leistung zu erzielen. Hier finden Sie einen detaillierten Überblick über den Feinabstimmungsvorgang:

STEP1: Auswählen des rechten vorgebildeten Modells
Der erste Schritt im Feinabstimmungsprozess ist die Auswahl eines vorgebildeten Modells, das als Fundament dient. Dieses Modell wurde bereits in einem großen und vielfältigen Datensatz geschult, in dem allgemeine Sprachmuster und -wissen erfasst werden. Die Auswahl des Modells hängt von der jeweiligen Aufgabe ab und wie gut das erste Training des Modells mit der gewünschten Anwendung übereinstimmt. Wenn Sie beispielsweise an einem medizinischen Chatbot arbeiten, können Sie ein Modell auswählen, das auf einem breiten Textbereich vorgebracht wurde, dann jedoch speziell für medizinische Kontexte fein abgestimmt ist.
Schritt2: Datenauswahl und -vorbereitung
Daten spielen eine entscheidende Rolle bei der Feinabstimmung. Der für die Feinabstimmung verwendete Datensatz sollte für die Zielaufgabe relevant sein und für die spezifische Domäne oder Anwendung repräsentativ sein. Beispielsweise würde ein medizinischer Chatbot einen Datensatz mit medizinischen Dialogen, Patientenabfragen und Gesundheitsversorgung benötigen.
- Datenreinigung : Reinigen und vorab die Daten vorab, um irrelevante oder verrückte Inhalte zu entfernen, die sich negativ auf den Feinabstimmungsvorgang auswirken könnten.
- Ausgleich des Datensatzes : Um eine Überanpassung zu vermeiden, stellen Sie sicher, dass der Datensatz ausgewogen und vielfältig genug ist, um verschiedene Aspekte der Aufgabe darzustellen. Dies beinhaltet genügend Beispiele für jede Kategorie oder jeden Eingangstyp.
Schritt 3: Hyperparameter -Tuning
Bei der Feinabstimmung wird mehrere Hyperparameter angepasst, um die Leistung des Modells zu optimieren:
- Lernrate : Die Lernrate bestimmt, wie viel die Modellgewichte mit jeder Iteration anpassen können. Eine zu hohe Lernrate kann dazu führen, dass das Modell zu schnell zu einer suboptimalen Lösung konvergiert, während eine zu niedrige Rate den Trainingsprozess verlangsamen kann.
- Stapelgröße : Die Chargengröße bezieht sich auf die Anzahl der in einer Iteration verwendeten Trainingsbeispiele. Größere Chargengrößen können den Trainingsprozess beschleunigen, erfordern jedoch möglicherweise mehr Rechenressourcen.
- Anzahl der Epochen : Eine Epoche ist ein vollständiger Durchgang im gesamten Trainingsdatensatz. Die Anzahl der Epochen betrifft die Ausbildung des Modells. Zu wenige Epochen können zu Unteranpassungen führen, während zu viele zu Überanpassungen führen können.
Schritt 4: Training des Modells
Während der Trainingsphase ist das Modell dem Feinabstimmungsdatensatz ausgesetzt. Der Trainingsprozess umfasst die Anpassung der Modellgewichte basierend auf dem Fehler zwischen den vorhergesagten Ausgängen und den tatsächlichen Beschriftungen. In dieser Phase passt das Modell sein allgemeines Wissen an die Einzelheiten der Feinabstimmung an.
- Verlustfunktion : Die Verlustfunktion misst, wie gut die Vorhersagen des Modells mit den tatsächlichen Werten übereinstimmen. Häufige Verlustfunktionen umfassen Kreuzentropie für Klassifizierungsaufgaben und mittlerer quadratischer Fehler bei Regressionsaufgaben.
- Optimierungsalgorithmus : Verwenden Sie Optimierungsalgorithmen wie ADAM oder SGD (stochastischer Gradientenabfälle), um die Verlustfunktion durch Aktualisierung der Modellgewichte zu minimieren.
Schritt 5: Bewertung
Nach der Feinabstimmung wird das Modell bewertet, um seine Leistung in der Zielaufgabe zu bewerten. Dies beinhaltet das Testen des Modells in einem separaten Validierungsdatensatz, um sicherzustellen, dass es gut funktioniert und effektiv auf neue, unsichtbare Daten verallgemeinert wird.
- Metriken : Die Bewertungsmetriken variieren je nach Aufgabe. Verwenden Sie Metriken wie Genauigkeit, Präzision, Rückruf und F1 -Score für Klassifizierungsaufgaben. Verwenden Sie BLEU -Werte oder andere relevante Maßnahmen für Erzeugungsaufgaben.
Schritt6: Feinabstimmungsanpassungen
Basierend auf den Bewertungsergebnissen können weitere Anpassungen erforderlich sein. Dies kann zusätzliche Feinabstimmungsrunden mit unterschiedlichen Hyperparametern, Anpassung des Trainingsdatensatzes oder das Einbeziehen von Techniken zum Umgang mit Überanpassung oder Unteranpassung umfassen.
Beispiel: Medizinischer Chatbot
Für einen medizinischen Chatbot beinhaltet die Feinabstimmung eines allgemein vorgebrachten Sprachmodells die Schulung von Datensätzen für medizinische Dialoge, der sich auf medizinische Terminologie, Patienteninteraktionsmuster und relevante Gesundheitsinformationen konzentriert. Dieser Prozess stellt sicher, dass der Chatbot medizinische Kontexte versteht und genaue, domänenspezifische Antworten liefern kann.

Parametereffiziente Feinabstimmung
Parametereffizientes Feinabstimmung ist ein raffinierter Ansatz zur Anpassung vor ausgebildeter Sprachmodelle (LLMs) mit minimalem Rechen- und Ressourcenaufwand. Diese Methode konzentriert sich auf die Optimierung des Feinabstimmungsprozesses, indem die Anzahl der Parameter reduziert wird, die aktualisiert werden müssen, wodurch kostengünstiger und effizienter wird. Hier ist eine Aufschlüsselung des parametereffizienten Feinabstimmungsprozesses:

STEP1: Vorabbau
Die Reise beginnt mit der Vorbereitung eines Sprachmodells auf einem großen, unbezeichneten Textkorpus. Diese unbeaufsichtigte Vorbereitungsphase ausstäbt das Modell mit einem breiten Verständnis der Sprache aus und ermöglicht es ihm, bei einer Vielzahl allgemeiner Aufgaben eine gute Leistung zu erzielen. In dieser Phase lernt das Modell aus enormen Datenmengen und entwickelt die für die anschließenden Feinabstimmung erforderlichen grundlegenden Fähigkeiten.
Schritt 2a: herkömmliche Feinabstimmung
In der herkömmlichen Feinabstimmung wird das vorgebildete LLM in einem kleineren, bezeichneten Zieldatensatz weiter geschult. In diesem Schritt werden alle ursprünglichen Modellparameter basierend auf der spezifischen Aufgabe oder Domäne aktualisiert. Dieser Ansatz kann zwar zu einem hochspezialisierten Modell führen, ist jedoch häufig ressourcenintensiv und kostspielig, da es erhebliche Rechenleistung erfordert, um eine große Anzahl von Parametern anzupassen.
Schritt 2B: Parametereffiziente Feinabstimmung
Die parametereffiziente Feinabstimmung bietet eine optimiertere Alternative, indem sich nur auf eine Teilmenge der Parameter des Modells konzentriert. In dieser Methode:
- Die ursprünglichen Modellparameter bleiben gefroren : Die Kernparameter des vorgebreiteten Modells bleiben unverändert. Dieser Ansatz nutzt das bereits bestehende Wissen, das im ursprünglichen Modell codiert ist und gleichzeitig Ressourcen speichert.
- Hinzufügen neuer Parameter : Anstatt das gesamte Modell zu aktualisieren, besteht diese Technik darin, einen kleineren Satz neuer Parameter hinzuzufügen, die speziell auf die Feinabstimmung zugeschnitten sind.
- Neue Parameter mit Feinabstimmungen : Nur diese neu hinzugefügten Parameter werden während des Feinabstimmungsprozesses eingestellt. Dies führt zu einer ressourceneffizienteren Methode, da die Aktualisierung einer geringeren Anzahl von Parametern weniger rechnerisch teuer ist.
Diese Methode reduziert die Rechenbelastung und die finanziellen Kosten, die mit der Feinabstimmung verbunden sind, erheblich, was sie zu einer attraktiven Option für Anwendungen mit begrenzten Ressourcen oder für Aufgaben macht, bei denen nur geringfügige Anpassungen erforderlich sind.
Wann verwenden Sie SLMS vs. LLMs für Inferenz?
Die Entscheidung zwischen kleinen Sprachmodellen (SLMs) und Großsprachenmodellen (LLMs) für Inferenz hängt von verschiedenen Faktoren ab, einschließlich Leistungsanforderungen, Ressourcenbeschränkungen und Anwendungsspezifikationen. Hier ist eine detaillierte Aufschlüsselung, mit der das am besten geeignete Modell für Ihre Anforderungen ermittelt wird:
Aufgabenkomplexität und Präzision
- SLMs : Ideal für Aufgaben, die eine hohe Effizienz und Präzision erfordern, aber kein komplexes oder sehr nuanciertes Sprachverständnis beinhalten. SLMS Excel in spezifischen, gut definierten Aufgaben wie domänenspezifischen Abfragen oder Routinedatenverarbeitung. Wenn Sie beispielsweise ein Modell benötigen, um Kundendienstkarten in einer Nischenindustrie zu verarbeiten, kann ein SLM schnelle und genaue Antworten ohne unnötigen Rechenaufwand liefern.
- LLMs : Am besten für Aufgaben geeignet, die komplexe Sprachgenerierung, nuanciertes Verständnis oder kreative Erstellung von Inhalten beinhalten. LLMs haben die Fähigkeit, eine breite Palette von Themen zu bewältigen und detaillierte und kontextbezogene Antworten zu liefern. Für Aufgaben wie die Erzeugung umfassender Forschungszusammenfassungen oder die Ausübung anspruchsvoller Konversations -KI bieten LLMs aufgrund ihrer größeren Modellgröße und ihrer umfangreicheren Schulung eine überlegene Leistung.
Verfügbarkeit von Ressourcen
- SLMS : Verwenden Sie SLMS, wenn die Rechenressourcen begrenzt sind. Ihre kleinere Größe führt zu einem geringeren Speicherverbrauch und schnelleren Verarbeitungszeiten, wodurch sie für Umgebungen geeignet sind, in denen die Effizienz von entscheidender Bedeutung ist. Das Bereitstellen eines SLM on Edge-Geräte oder mobilen Plattformen stellt beispielsweise sicher, dass die Anwendung reaktionsschnell und ressourceneffizient bleibt.
- LLMs : Entscheiden Sie sich für LLMs, wenn die Ressourcen ausreichend sind und die Aufgabe ihre Verwendung rechtfertigt. Während LLMs erhebliche Rechenleistung und Speicher benötigt, bieten sie eine robustere Leistung für komplizierte Aufgaben. Wenn Sie beispielsweise eine groß angelegte Textanalyse oder ein Multi-Turn-Konversationssystem durchführen, kann LLMs ihre umfangreichen Funktionen nutzen, um qualitativ hochwertige Ausgänge zu liefern.
Latenz und Geschwindigkeit
- SLMs : Wenn niedrige Latenz- und schnelle Reaktionszeiten von entscheidender Bedeutung sind, sind SLMs die bevorzugte Wahl. Ihre optimierte Architektur ermöglicht eine schnelle Schlussfolgerung und macht sie ideal für Echtzeitanwendungen. Zum Beispiel profitieren Chatbots, die hohe Abfragen in Echtzeit verarbeiten, von der geringen Latenz von SLMs.
- LLMs : Obwohl LLMs aufgrund ihrer Größe und Komplexität eine höhere Latenz aufweisen können, sind sie für Anwendungen geeignet, bei denen die Reaktionszeit im Vergleich zur Tiefe und Qualität des Ausgangs weniger kritisch ist. Für Anwendungen wie eingehende Inhaltsgenerierung oder detaillierte Sprachanalyse überwiegen die Vorteile der Verwendung eines LLM die langsameren Reaktionszeiten.
Kostenüberlegungen
- SLMS : Kosteneffektiv für Szenarien mit Budgetbeschränkungen. Das Training und die Bereitstellung von SLMs sind im Vergleich zu LLMs im Allgemeinen günstiger. Sie bieten eine kostengünstige Lösung für Aufgaben, bei denen keine hohe Rechenleistung erforderlich ist.
- LLMs : aufgrund ihrer Größe und der erforderlichen Rechenressourcen teurer. Sie sind jedoch für Aufgaben gerechtfertigt, die umfangreiches Sprachverständnis und Erzeugungsfähigkeiten erfordern. Für Anwendungen, bei denen die Ausgangsqualität von größter Bedeutung ist und das Budget zulässt, kann die Investition in LLMs erhebliche Renditen erzielen.
Einsatz und Skalierbarkeit
- SLMs : Ideal für die Bereitstellung in Umgebungen mit begrenzten Ressourcen, einschließlich Kantengeräten und mobiler Anwendungen. Ihr kleinerer Fußabdruck stellt sicher, dass sie leicht in verschiedene Plattformen mit begrenzter Verarbeitungsleistung integriert werden können.
- LLMs : Geeignet für groß angelegte Bereitstellungen, bei denen Skalierbarkeit erforderlich ist. Sie können große Datenmengen und komplexe Abfragen effizient bewältigen, wenn ausreichende Ressourcen verfügbar sind. Beispielsweise sind Anwendungen auf Unternehmensebene, für die umfangreiche Datenverarbeitung und hoher Durchsatz erforderlich sind, für LLMs gut geeignet.
Überlegungen vor der Bereitstellung von SLMs
Bei der Vorbereitung auf die Bereitstellung von SLMs (Small Language Models) sollten mehrere wichtige Überlegungen berücksichtigt werden, um eine erfolgreiche Integration und den Betrieb sicherzustellen. Dazu gehören:
Ressourcenbeschränkungen
- Speicher- und Verarbeitungsleistung : SLMs sind so konzipiert, dass es leicht ist, aber es ist wichtig, die Speicher- und Verarbeitungsfunktionen der Zielumgebung zu bewerten. Stellen Sie sicher, dass die Bereitstellungsplattform über ausreichende Ressourcen verfügt, um die Anforderungen des Modells zu erfüllen, obwohl SLMs im Vergleich zu größeren Modellen weniger anspruchsvoll sind.
- Stromverbrauch : Für Kantengeräte ist Stromeffizienz von entscheidender Bedeutung. Bewerten Sie den Stromverbrauch des Modells, um einen übermäßigen Energieverbrauch zu vermeiden. Dies kann ein Problem in batteriebetriebenen oder geringen Stromumgebungen sein.
Latenz und Leistung
- Reaktionszeit : Da SLMs für eine schnellere Inferenz optimiert sind, stellen Sie sicher, dass die Bereitstellungsumgebung den Vorgängen mit geringer Latenz unterstützt. Die Leistung kann je nach Hardware variieren. Daher ist es wichtig, das Modell unter realen Bedingungen zu testen, um sicherzustellen, dass es die Leistungserwartungen entspricht.
- Skalierbarkeit : Betrachten Sie die Skalierbarkeit der Bereitstellungslösung. Stellen Sie sicher, dass das System unterschiedliche Lasten verarbeiten und mit zunehmender Anzahl von Benutzern oder Anforderungen effizient skalieren kann.
Kompatibilität und Integration
- Plattformkompatibilität : Stellen Sie sicher, dass die Bereitstellungsplattform mit dem Modellformat und dem verwendeten Technologiestapel kompatibel ist. Dies umfasst die Überprüfung der Kompatibilität mit Betriebssystemen, Programmierumgebungen und zusätzlicher Software, die für die Integration erforderlich sind.
- Integration mit vorhandenen Systemen : Bewerten Sie, wie sich die SLM in vorhandene Anwendungen oder Dienste integrieren lässt. Eine nahtlose Integration ist entscheidend dafür, dass das Modell in der breiteren Systemarchitektur effektiv funktioniert.
Sicherheit und Privatsphäre
- Datensicherheit : Bewerten Sie die vorhandenen Sicherheitsmaßnahmen, um sensible Daten zu schützen, die vom SLM verarbeitet wurden. Stellen Sie sicher, dass Datenverschlüsselung und sichere Kommunikationsprotokolle zum Schutz der Informationen verwendet werden.
- Datenschutzbedenken : Überlegen Sie, wie die Bereitstellung Benutzerdaten umgeht und die Datenschutzbestimmungen entspricht. Stellen Sie sicher, dass die Bereitstellung den Datenschutzstandards hält und die Vertraulichkeit der Benutzer beibehält.
Wartung und Updates
- Modellwartung : Planen Sie eine regelmäßige Wartung und Aktualisierung des SLM. Dies umfasst die Überwachungsmodellleistung, die Behandlung potenzieller Probleme und die Aktualisierung des Modells nach Bedarf, um sich an Änderungen der Daten oder Anforderungen anzupassen.
- Versionsverwaltung : Implementieren Sie die Versionskontroll- und Managementpraktiken, um Modellaktualisierungen zu verarbeiten und reibungslose Übergänge zwischen verschiedenen Modellversionen zu gewährleisten.
MediaPipe und WebAssembly für die Bereitstellung von SLMs on Edge -Geräte
Dies sind zwei Technologien, die die Bereitstellung von SLMs on Edge -Geräten erleichtern, die jeweils unterschiedliche Vorteile bieten:
Mediapipe
- Echtzeitleistung : MediaPipe ist für die Echtzeitverarbeitung konzipiert, wodurch es für die Bereitstellung von SLMs geeignet ist, die eine schnelle Schlussfolgerung auf Edge-Geräte erfordern. Es bietet effiziente Pipelines für die Verarbeitung von Daten und die Integration verschiedener maschineller Lernmodelle.
- Modulare Architektur : Die modulare Architektur von MediaPipe ermöglicht eine einfache Integration von SLMs in andere Komponenten und Vorverarbeitungsschritte. Diese Flexibilität ermöglicht die Erstellung maßgeschneiderter Lösungen, die auf bestimmte Anwendungsfälle zugeschnitten sind.
- CLOSSPLATFORM-Support : MediaPipe unterstützt verschiedene Plattformen, einschließlich mobiler und Webumgebungen. Diese plattformübergreifende Fähigkeit stellt sicher, dass SLMs konsistent über verschiedene Geräte und Betriebssysteme eingesetzt werden können.
WebAssembly
- Leistung und Portabilität : WebAssembly (WASM) bietet nahezu native Leistung in Webumgebungen und ist ideal für die Bereitstellung von SLMs, die in Browsern effizient ausgeführt werden müssen. Es ermöglicht die Ausführung von Code, die in Sprachen wie C und Rost mit minimalem Overhead geschrieben wurden.
- Sicherheit und Isolation : Die WebAssembly wird in einer sicheren Sandbox -Umgebung ausgeführt, die die Sicherheit und Isolation von SLM -Bereitstellungen verbessert. Dies ist besonders wichtig, wenn Sie mit sensiblen Daten oder in die Integration in Webanwendungen integrieren.
- Kompatibilität : WebAssembly ist mit modernen Browsern kompatibel und kann zum Bereitstellen von SLMs in einer Vielzahl von webbasierten Anwendungen verwendet werden. Diese breite Kompatibilität stellt sicher, dass SLMs von Benutzern auf verschiedenen Plattformen leicht zugreifen und genutzt werden können.
Wie werden LLMs heute bereitgestellt?
Die Bereitstellung von großsprachigen Modellen (LLMs) hat sich erheblich weiterentwickelt, wobei erweiterte Cloud -Technologien, Microservices und Integrationsrahmen verwendet werden, um ihre Leistung und Zugänglichkeit zu verbessern. Dieser moderne Ansatz stellt sicher, dass LLMs effektiv in verschiedene Plattformen und Dienste integriert werden und eine nahtlose Benutzererfahrung und robuste Funktionalität bieten.

Integration mit Kommunikationsplattformen
Die Integration mit Kommunikationsplattformen ist ein wesentlicher Aspekt der Bereitstellung von LLMs. Diese Modelle sind in weit verbreitete Kommunikationstools wie Slack, Discord und Google Chat eingebettet. Durch die Integration in diese Plattformen können LLMs direkt mit Benutzern über vertraute Chat -Schnittstellen interagieren. Dieses Setup ermöglicht es LLMs, in Echtzeit Fragen zu bearbeiten und auf Anfragen zu reagieren, wodurch ihr geschulter Wissen nutzt, um relevante Antworten zu liefern. Der Integrationsprozess umfasst die Konfiguration von Namespaces basierend auf Kanalquellen oder Bot -Namen, wodurch die Anforderungen an die entsprechenden Modell- und Datenquellen weitergeleitet werden.
Cloud-basierte Microservices
Cloud-basierte Microservices spielen eine entscheidende Rolle bei der Bereitstellung von LLMs. Plattformen wie Google Cloud Run werden verwendet, um Microservices zu verwalten, die verschiedene Aufgaben wie Analyse von Eingabemeldungen, Verarbeitungsdaten und Schnittstellen mit dem LLM verarbeiten. Jeder Dienst arbeitet über bestimmte Endpunkte wie /Discord /Message oder /Slack /Message, um sicherzustellen, dass die Daten standardisiert und effizient verarbeitet werden. Dieser Ansatz unterstützt skalierbare und flexible Bereitstellungen und berücksichtigt verschiedene Kommunikationskanäle und Anwendungsfälle.
Datenverwaltung
In the realm of Data Management, cloud storage solutions and vectorstores are essential. Files and data are uploaded to cloud storage buckets and processed to create contexts for the LLM. Large files are chunked and indexed in vectorstores, allowing the LLM to retrieve and utilize relevant information effectively. Langchain tools facilitate this orchestration by parsing questions, looking up contexts in vectorstores, and managing chat histories, ensuring that responses are accurate and contextually relevant.
Pub/Sub Messaging Systems
Pub/Sub Messaging Systems are employed for handling large volumes of data and tasks. This system enables parallel processing by chunking files and sending them through Pub/Sub channels. This method supports scalable operations and efficient data management. Unstructured APIs and Cloud Run convert documents into formats for LLMs, integrating diverse data types into the model's workflow.
Integration with Analytics and Data Sources
Integration with Analytics and Data Sources further enhances LLM performance. Platforms like Google Cloud and Azure OpenAI provide additional insights and functionalities, refining the LLM's responses and overall performance. Command and storage management systems handle chat histories and file management. They support ongoing training and fine-tuning of LLMs based on real-world interactions and data inputs.
Limitations
- Latency: Processing requests through cloud-based LLMs can introduce latency, impacting real-time applications or interactive user experiences.
- Cost: Continuous usage of cloud resources for LLM deployment can incur significant costs, especially for high-volume or resource-intensive tasks.
- Privacy Concerns: Transmitting sensitive data to the cloud for processing raises privacy and security concerns, particularly in industries with strict regulations.
- Dependence on Internet Connectivity: Cloud-based LLM deployments require a stable internet connection, limiting functionality in offline or low-connectivity environments.
- Scalability Challenges: Scaling cloud-based LLM deployments can be challenging, causing performance issues during peak usage periods.
How Can SLMs Function Well with Fewer Parameters?
SLMs can deliver impressive performance despite having fewer parameters compared to their larger counterparts. Thanks to several effective training methods and strategic adaptations.
Training Methods
- Transfer Learning : SLMs benefit significantly from transfer learning, a technique where a model is initially trained on a broad dataset to acquire general knowledge. This foundational training allows the SLM to adapt to specific tasks or domains with minimal additional training. By leveraging pre-existing knowledge, SLMs can efficiently tune their capabilities to meet particular needs, enhancing their performance without requiring extensive computational resources.
- Knowledge Distillation : Knowledge distillation allows SLMs to perform efficiently by transferring insights from a larger model (like an LLM) into a smaller SLM. This process helps SLMs achieve comparable performance while reducing computational needs. It ensures SLMs handle specific tasks effectively without the overhead of larger models.
Domain-Specific Adaptation
SLMs can be tailored to excel in specific domains through targeted training on specialized datasets. This domain-specific adaptation enhances their effectiveness for specialized tasks. For example, SLMs developed by NTG are adept at understanding and analyzing construction Health, Safety, and Environment (HSE) terminology. By focusing on specific industry jargon and requirements, these models achieve higher accuracy and relevance in their analyses compared to more generalized models.
Effectiveness Factors
The effectiveness of an SLM depends on its training, fine-tuning, and task alignment. SLMs can outperform larger models in certain scenarios, but they are not always superior. They excel in specific use cases with advantages like lower latency and reduced costs. For broader or more complex applications, LLMs may still be preferable due to their extensive training and larger parameter sets.
Abschluss
Fine-tuning and inference with Small Language Models (SLMs) like Gemma show their adaptability and efficiency. By selecting and tailoring pre-trained models, fine-tuning for specific domains, and optimizing deployment, SLMs achieve high performance with lower costs. Techniques such as parameter-efficient methods and domain-specific adaptations make SLMs a strong alternative to larger models. They offer precision, speed, and cost-effectiveness for various tasks. As technology evolves, SLMs will increasingly enhance AI-driven solutions across industries.
Häufig gestellte Fragen
Q 1. What are Small Language Models (SLMs)?A. SLMs are lightweight AI models designed for specific tasks or domains, offering efficient performance with fewer parameters compared to larger models like LLMs.
Q 2. Why should I consider fine-tuning an SLM?A. Fine-tuning enhances an SLM's performance for particular tasks, improves consistency, reduces errors, and can make it more cost-effective compared to using larger models.
Q 3. What are the key steps in the fine-tuning process?A. The fine-tuning process involves selecting the right pre-trained model, preparing domain-specific data, adjusting hyperparameters, and evaluating the model's performance.
Q 4. How does parameter-efficient fine-tuning differ from conventional fine-tuning?A. Parameter-efficient fine-tuning updates only a small subset of model parameters, which is less resource-intensive than conventional methods that update the entire model.
Q 5. When should I use SLMs instead of LLMs for inference?A. SLMs are ideal for tasks requiring fast, efficient processing with lower computational costs, while LLMs are better suited for complex tasks requiring extensive general knowledge.
Das obige ist der detaillierte Inhalt vonFeinabstimmung und Schlussfolgerung kleiner Sprachmodelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

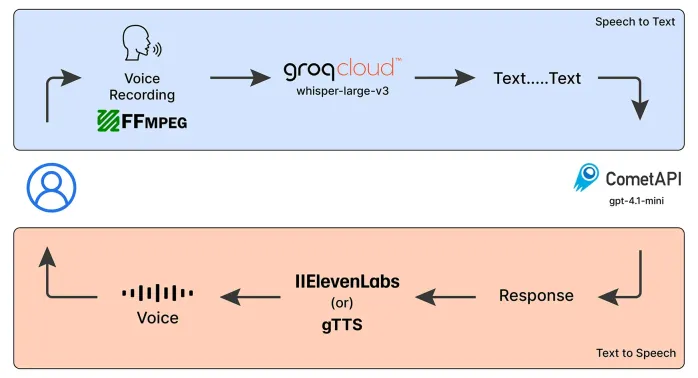 Notfallbetreiber Sprach -Chatbot: Unterstützung bei der UnterstützungMay 07, 2025 am 09:48 AM
Notfallbetreiber Sprach -Chatbot: Unterstützung bei der UnterstützungMay 07, 2025 am 09:48 AMSprachmodelle haben sich in der Welt schnell entwickelt. Jetzt ist es wichtig zu verstehen, wie wir die Funktionen dieses multimodalen Modells nutzen können
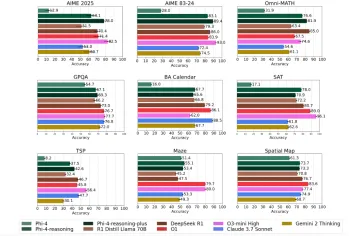 Die Phi-4-Argumentationsmodelle von Microsoft erklärten einfachMay 07, 2025 am 09:45 AM
Die Phi-4-Argumentationsmodelle von Microsoft erklärten einfachMay 07, 2025 am 09:45 AMMicrosoft ist nicht wie Openai, Google und Meta. Besonders nicht, wenn es um große Sprachmodelle geht. Während andere Tech -Giganten es vorziehen, mehrere Modelle zu starten, die die Benutzer mit Auswahlmöglichkeiten fast überwältigen. Microsoft startet einige,
 Top 20 Git -Befehle, die jeder Entwickler wissen sollte - Analytics VidhyaMay 07, 2025 am 09:44 AM
Top 20 Git -Befehle, die jeder Entwickler wissen sollte - Analytics VidhyaMay 07, 2025 am 09:44 AMGit kann sich wie ein Puzzle anfühlen, bis Sie die Schlüsselbewegungen lernen. In diesem Leitfaden finden Sie die Top 20 Git -Befehle, die dadurch bestellt werden, wie oft sie verwendet werden. Jeder Eintrag beginnt mit einer kurzen Zusammenfassung „Was es tut“, gefolgt von einer Bildanzeige
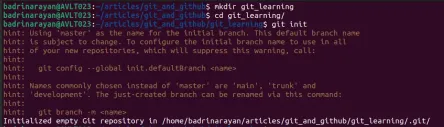 Git -Tutorial für AnfängerMay 07, 2025 am 09:36 AM
Git -Tutorial für AnfängerMay 07, 2025 am 09:36 AMIn der Softwareentwicklung kann das Verwalten von Code über mehrere Mitwirkende hinweg schneller werden. Stellen Sie sich vor, mehrere Personen bearbeiten das gleiche Dokument gleichzeitig, fügen jeweils neue Ideen hinzu, reparieren Fehler oder Optimierfunktionen. Ohne Struktur
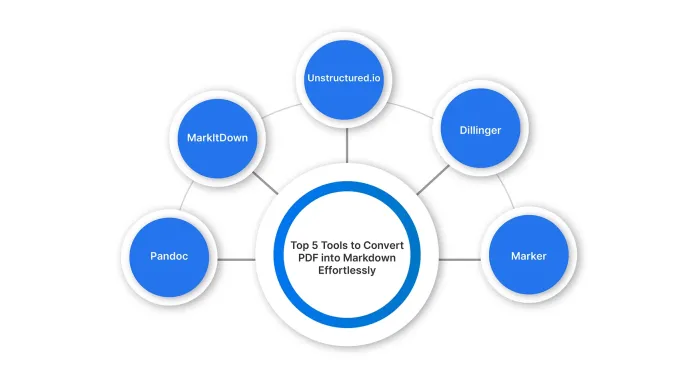 Top 5 PDF zum Markdown -Konverter für mühelose Formatierung - Analytics VidhyaMay 07, 2025 am 09:21 AM
Top 5 PDF zum Markdown -Konverter für mühelose Formatierung - Analytics VidhyaMay 07, 2025 am 09:21 AMVerschiedene Formate wie PPTX, DOCX oder PDF zum Markdown -Konverter sind ein wesentliches Werkzeug für Inhaltautoren, Entwickler und Dokumentationsspezialisten. Wenn Sie die richtigen Werkzeuge haben
 QWEN3 -Modelle: Zugriff, Funktionen, Anwendungen und mehrMay 07, 2025 am 09:18 AM
QWEN3 -Modelle: Zugriff, Funktionen, Anwendungen und mehrMay 07, 2025 am 09:18 AMQwen hat still ein Modell nach dem anderen hinzugefügt. Jedes seiner Modelle ist voller Merkmale und Größen, die so quantifiziert sind, dass es einfach unmöglich zu ignorieren ist. Nach QVQ, QWEN2.5-VL und QWEN2.5-OMNI in diesem Jahr die
 Wie man Lag -Systeme und KI -Agenten mit QWEN3 bautMay 07, 2025 am 09:10 AM
Wie man Lag -Systeme und KI -Agenten mit QWEN3 bautMay 07, 2025 am 09:10 AMQwen hat gerade 8 neue Modelle im Rahmen seiner neuesten Familie veröffentlicht - QWEN3, die vielversprechende Fähigkeiten präsentiert. Das Flaggschiff-Modell, QWEN3-235B-A22B, übertraf die meisten anderen Modelle, darunter Deepseek-R1, OpenAs O1, O3-Mini,
 Warum Sam Altman und andere jetzt Vibes als neues Messgerät für die neuesten Fortschritte in der KI verwendenMay 06, 2025 am 11:12 AM
Warum Sam Altman und andere jetzt Vibes als neues Messgerät für die neuesten Fortschritte in der KI verwendenMay 06, 2025 am 11:12 AMLassen Sie uns die steigende Verwendung von "Vibes" als Bewertungsmetrik im KI -Feld diskutieren. Diese Analyse ist Teil meiner laufenden Forbes -Spalte zu KI -Fortschritten und untersucht komplexe Aspekte der KI -Entwicklung (siehe Link hier). Stimmung in der AI -Bewertung Tradi


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

mPDF
mPDF ist eine PHP-Bibliothek, die PDF-Dateien aus UTF-8-codiertem HTML generieren kann. Der ursprüngliche Autor, Ian Back, hat mPDF geschrieben, um PDF-Dateien „on the fly“ von seiner Website auszugeben und verschiedene Sprachen zu verarbeiten. Es ist langsamer und erzeugt bei der Verwendung von Unicode-Schriftarten größere Dateien als Originalskripte wie HTML2FPDF, unterstützt aber CSS-Stile usw. und verfügt über viele Verbesserungen. Unterstützt fast alle Sprachen, einschließlich RTL (Arabisch und Hebräisch) und CJK (Chinesisch, Japanisch und Koreanisch). Unterstützt verschachtelte Elemente auf Blockebene (wie P, DIV),

Sicherer Prüfungsbrowser
Safe Exam Browser ist eine sichere Browserumgebung für die sichere Teilnahme an Online-Prüfungen. Diese Software verwandelt jeden Computer in einen sicheren Arbeitsplatz. Es kontrolliert den Zugriff auf alle Dienstprogramme und verhindert, dass Schüler nicht autorisierte Ressourcen nutzen.

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

VSCode Windows 64-Bit-Download
Ein kostenloser und leistungsstarker IDE-Editor von Microsoft

DVWA
Damn Vulnerable Web App (DVWA) ist eine PHP/MySQL-Webanwendung, die sehr anfällig ist. Seine Hauptziele bestehen darin, Sicherheitsexperten dabei zu helfen, ihre Fähigkeiten und Tools in einem rechtlichen Umfeld zu testen, Webentwicklern dabei zu helfen, den Prozess der Sicherung von Webanwendungen besser zu verstehen, und Lehrern/Schülern dabei zu helfen, in einer Unterrichtsumgebung Webanwendungen zu lehren/lernen Sicherheit. Das Ziel von DVWA besteht darin, einige der häufigsten Web-Schwachstellen über eine einfache und unkomplizierte Benutzeroberfläche mit unterschiedlichen Schwierigkeitsgraden zu üben. Bitte beachten Sie, dass diese Software

