

 Technologie-PeripheriegeräteKIGoogles neue Methode ASPIRE: Bietet LLM-Selbstbewertungsfunktionen, löst effektiv das „Illusions'-Problem und übertrifft das Volumenmodell um das Zehnfache
Technologie-PeripheriegeräteKIGoogles neue Methode ASPIRE: Bietet LLM-Selbstbewertungsfunktionen, löst effektiv das „Illusions'-Problem und übertrifft das Volumenmodell um das Zehnfache
Das „Illusions“-Problem großer Modelle ist bald gelöst?
Forscher der University of Wisconsin-Madison und Google haben kürzlich das ASPIRE-System eingeführt, das es großen Modellen ermöglicht, ihre Ergebnisse selbst zu bewerten.
Wenn der Benutzer sieht, dass das vom Modell generierte Ergebnis eine niedrige Punktzahl aufweist, wird ihm klar, dass die Antwort möglicherweise eine Illusion ist.
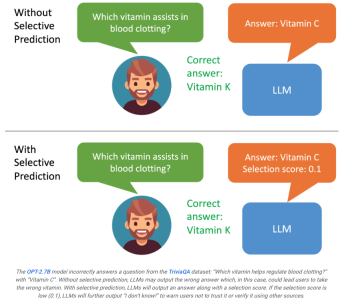
Wenn das System den Ausgabeinhalt basierend auf den Bewertungsergebnissen weiter filtern kann, beispielsweise wenn die Bewertung niedrig ist, kann ein großes Modell Aussagen wie „Ich kann diese Frage nicht beantworten“ generieren, was möglicherweise der Fall ist Maximieren Sie die Verbesserung des Halluzinationsproblems.

Papieradresse: https://aclanthology.org/2023.findings-emnlp.345.pdf
ASPIRE ermöglicht LLM, die Antwort und den Konfidenzwert der Antwort auszugeben.
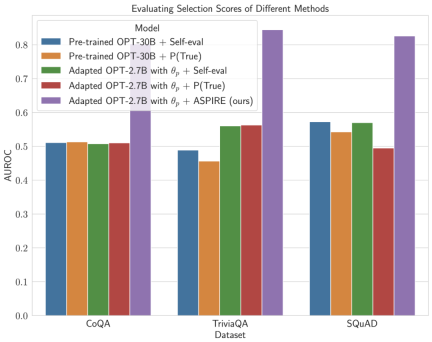
Die experimentellen Ergebnisse der Forscher zeigen, dass ASPIRE herkömmliche selektive Vorhersagemethoden für verschiedene QA-Datensätze (wie den CoQA-Benchmark) deutlich übertrifft.
Lassen Sie LLM nicht nur Fragen beantworten, sondern diese Antworten auch auswerten.
Im Benchmark-Test der selektiven Vorhersage erzielten Forscher mit dem ASPIRE-System Ergebnisse von mehr als dem Zehnfachen des Maßstabs des Modells.
Es ist, als würde man die Schüler bitten, ihre eigenen Antworten am Ende des Lehrbuchs zu überprüfen. Auch wenn es etwas unzuverlässig klingt, wird man bei sorgfältiger Überlegung nach der Beantwortung einer Frage tatsächlich mit der Antwort zufrieden sein. Es wird eine Wertung geben.
Das ist die Essenz von ASPIRE, die drei Phasen umfasst:
(1) Abstimmung auf eine bestimmte Aufgabe,
(2) Antwortproben,
( 3 ) Selbsteinschätzung des Lernens.
In den Augen der Forscher ist ASPIRE nicht nur ein weiteres Framework, es stellt eine vielversprechende Zukunft dar, die die LLM-Zuverlässigkeit umfassend verbessert und Halluzinationen reduziert.
Wenn LLM ein vertrauenswürdiger Partner im Entscheidungsprozess sein kann.
Solange wir die Fähigkeit zur selektiven Vorhersage weiter optimieren, ist der Mensch der vollständigen Ausschöpfung des Potenzials großer Modelle einen Schritt näher gekommen.
Forscher hoffen, mit ASPIRE die Entwicklung der nächsten Generation von LLM voranzutreiben und so eine zuverlässigere und selbstbewusstere künstliche Intelligenz zu schaffen. Der Mechanismus von ASPIRE: Aufgabenspezifische Feinabstimmung
Anhand eines Trainingsdatensatzes für die Generierungsaufgabe wird das vorab trainierte LLM optimiert, um seine Vorhersageleistung zu verbessern.
Zu diesem Zweck können Parameter-effiziente Feinabstimmungstechniken (z. B. Soft-Cue-Word-Feinabstimmung und LoRA) eingesetzt werden, um vorab trainierte LLMs auf die Aufgabe abzustimmen, da sie damit effektiv eine starke Generalisierung erreichen können eine kleine Anzahl von Zieldaten.
Konkret werden die LLM-Parameter (θ) eingefroren und adaptive Parameter zur Feinabstimmung hinzugefügt. 
Diese Feinabstimmung kann die Leistung der selektiven Vorhersage verbessern, da sie nicht nur die Vorhersagegenauigkeit verbessert, sondern auch die Wahrscheinlichkeit einer korrekten Ausgabe der Sequenz erhöht.
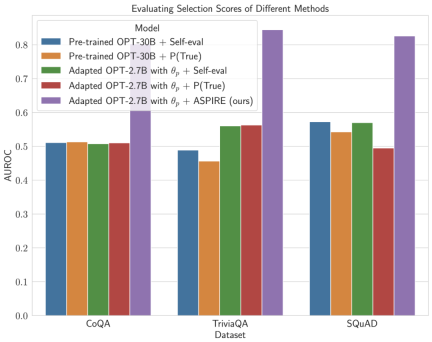
Nachdem ASPIRE auf eine bestimmte Aufgabe abgestimmt wurde, verwendet ASPIRE LLM und hat gelernt Das Ziel des Forschers besteht darin, Ausgabesequenzen mit hoher Wahrscheinlichkeit zu generieren. Sie verwendeten Beam Search als Dekodierungsalgorithmus, um Ausgabesequenzen mit hoher Wahrscheinlichkeit zu generieren, und verwendeten die Rouge-L-Metrik, um zu bestimmen, ob die generierten Ausgabesequenzen korrekt waren. Nachdem ASPIRE die High-Likelihood-Ausgabe jeder Abfrage abgetastet hat, fügt ASPIRE adaptive Parameter Da die Generierung der Ausgabesequenz nur von θ und Die Forscher haben In diesem Rahmen kann jede Parameter-effiziente Feinabstimmungsmethode zum Trainieren von In dieser Arbeit verwenden die Forscher die Feinabstimmung von Soft-Cues, einen einfachen, aber effektiven Mechanismus zum Erlernen von „Soft-Cues“, um eingefrorene Sprachmodelle so abzustimmen, dass sie effektiver als herkömmliche diskrete Text-Cues sind, um bestimmte nachgelagerte Aufgaben auszuführen. Der Kern dieses Ansatzes ist die Erkenntnis, dass, wenn Hinweise entwickelt werden können, die die Selbsteinschätzung effektiv anregen, diese Hinweise durch die Feinabstimmung weicher Hinweise in Kombination mit gezielten Trainingszielen erkennbar sein sollten. Nach dem Training Die Forscher definieren dann einen Auswahlwert, der die Wahrscheinlichkeit, eine Antwort zu generieren, mit dem erlernten Selbstbewertungswert (d. h. der Wahrscheinlichkeit, dass die Vorhersage für die Abfrage richtig ist) kombiniert, um selektive Vorhersagen zu treffen. Ergebnisse Um die Wirksamkeit von ASPIRE zu demonstrieren, verwendeten die Forscher verschiedene offene, vorab trainierte Transformer (OPT)-Modelle, um sie anhand von drei Frage-Antwort-Datensätzen (CoQA, TriviaQA und SQuAD) auszuwerten. Durch die Anpassung des Trainings mithilfe von Soft Cues Zum Beispiel zeigte das OPT-2.7B-Modell mit ASPIRE eine bessere Leistung im Vergleich zum größeren vorab trainierten OPT-30B-Modell mit CoQA- und SQuAD-Datensätzen. Diese Ergebnisse deuten darauf hin, dass kleinere LLMs bei entsprechender Abstimmung in einigen Fällen die Genauigkeit größerer Modelle erreichen oder möglicherweise sogar übertreffen können. Bei der näheren Betrachtung der Berechnung von Auswahlwerten für feste Modellvorhersagen erzielte ASPIRE für alle Datensätze höhere AUROC-Werte als die Basismethoden (zufällig ausgewählte korrekte Ausgabesequenzen haben höhere Werte als zufällig ausgewählte falsche Ausgabesequenzen). Wahrscheinlichkeit einer höheren Auswahlpunktzahl). Zum Beispiel verbessert ASPIRE beim CoQA-Benchmark den AUROC von 51,3 % auf 80,3 % im Vergleich zum Ausgangswert. Bei der Auswertung des TriviaQA-Datensatzes ergab sich ein interessantes Muster. Während das vorab trainierte OPT-30B-Modell eine höhere Grundgenauigkeit aufweist, verbessert sich seine selektive Vorhersageleistung nicht wesentlich, wenn herkömmliche Selbstbewertungsmethoden (Selbstbewertung und P(True)) angewendet werden. Im Gegensatz dazu übertrifft das viel kleinere OPT-2.7B-Modell in dieser Hinsicht andere Modelle, nachdem es mit ASPIRE erweitert wurde. Dieser Unterschied verkörpert ein wichtiges Problem: Größere LLMs, die herkömmliche Selbstbewertungstechniken verwenden, sind bei der selektiven Vorhersage möglicherweise nicht so effektiv wie kleinere, durch ASPIRE erweiterte Modelle. Die experimentelle Reise der Forscher mit ASPIRE verdeutlicht einen wichtigen Wandel in der LLM-Landschaft: Die Kapazität eines Sprachmodells ist nicht das A und O seiner Leistung. Im Gegensatz dazu kann die Modelleffektivität durch Richtlinienanpassungen erheblich verbessert werden, was selbst in kleineren Modellen genauere und zuverlässigere Vorhersagen ermöglicht. Damit demonstriert ASPIRE das Potenzial von LLM, die Sicherheit seiner eigenen Antworten sinnvoll zu bestimmen und andere 10x größere Modelle bei selektiven Vorhersageaufgaben deutlich zu übertreffen. Antwortstichprobe
 , unterschiedliche Antworten für jede Trainingsfrage zu generieren und einen Datensatz für das Selbstbewertungslernen zu erstellen.
, unterschiedliche Antworten für jede Trainingsfrage zu generieren und einen Datensatz für das Selbstbewertungslernen zu erstellen. Selbstbewertungslernen
 und nur Feinabstimmungen
und nur Feinabstimmungen  hinzu, um Selbstbewertung zu lernen.
hinzu, um Selbstbewertung zu lernen.  abhängt, kann durch das Einfrieren von θ und dem gelernten
abhängt, kann durch das Einfrieren von θ und dem gelernten  eine Änderung des Vorhersageverhaltens des LLM beim Lernen der Selbstbewertung vermieden werden.
eine Änderung des Vorhersageverhaltens des LLM beim Lernen der Selbstbewertung vermieden werden.  so optimiert, dass das angepasste LLM selbstständig richtige und falsche Antworten unterscheiden kann.
so optimiert, dass das angepasste LLM selbstständig richtige und falsche Antworten unterscheiden kann. 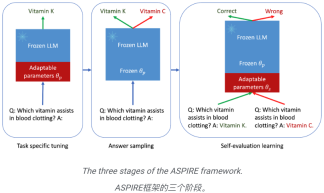
 und
und  verwendet werden.
verwendet werden. 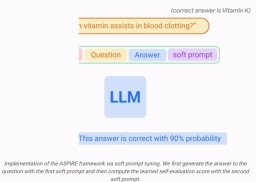
 und
und  erhielten die Forscher die Vorhersage der Abfrage durch Beam-Search-Dekodierung.
erhielten die Forscher die Vorhersage der Abfrage durch Beam-Search-Dekodierung.  Die Forscher beobachteten eine erhebliche Verbesserung der LLM-Genauigkeit.
Die Forscher beobachteten eine erhebliche Verbesserung der LLM-Genauigkeit. 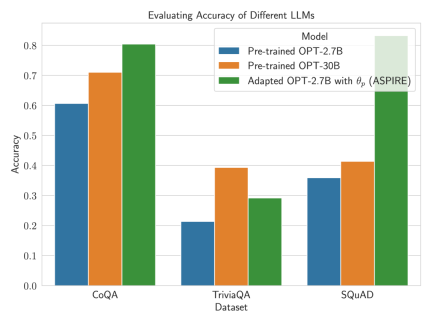
Das obige ist der detaillierte Inhalt vonGoogles neue Methode ASPIRE: Bietet LLM-Selbstbewertungsfunktionen, löst effektiv das „Illusions'-Problem und übertrifft das Volumenmodell um das Zehnfache. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Werkzeuganruf in LLMsApr 14, 2025 am 11:28 AM
Werkzeuganruf in LLMsApr 14, 2025 am 11:28 AMGroße Sprachmodelle (LLMs) sind immer beliebter, wobei die Tool-Calling-Funktion ihre Fähigkeiten über die einfache Textgenerierung hinaus erweitert hat. Jetzt können LLMs komplexe Automatisierungsaufgaben wie dynamische UI -Erstellung und autonomes A erledigen
 Wie ADHS -Spiele, Gesundheitstools und KI -Chatbots die globale Gesundheit verändernApr 14, 2025 am 11:27 AM
Wie ADHS -Spiele, Gesundheitstools und KI -Chatbots die globale Gesundheit verändernApr 14, 2025 am 11:27 AMKann ein Videospiel Angst erleichtern, Fokus aufbauen oder ein Kind mit ADHS unterstützen? Da die Herausforderungen im Gesundheitswesen weltweit steigen - insbesondere bei Jugendlichen - wenden sich Innovatoren einem unwahrscheinlichen Tool zu: Videospiele. Jetzt einer der größten Unterhaltungsindus der Welt
 UN -Input zu KI: Gewinner, Verlierer und MöglichkeitenApr 14, 2025 am 11:25 AM
UN -Input zu KI: Gewinner, Verlierer und MöglichkeitenApr 14, 2025 am 11:25 AM„Die Geschichte hat gezeigt, dass der technologische Fortschritt das Wirtschaftswachstum zwar nicht selbstverträglich macht, aber nicht eine gerechte Einkommensverteilung sicherstellt oder integrative menschliche Entwicklung fördert“, schreibt Rebeca Grynspan, Generalsekretärin von UNCTAD, in der Präambel.
 Lernverhandlungsfähigkeiten über generative KIApr 14, 2025 am 11:23 AM
Lernverhandlungsfähigkeiten über generative KIApr 14, 2025 am 11:23 AMEasy-Peasy, verwenden Sie generative KI als Ihren Verhandlungslehrer und Sparringspartner. Reden wir darüber. Diese Analyse eines innovativen KI -Durchbruch
 Ted enthüllt von Openai, Google, Meta geht vor Gericht, Selfie mit mir selbstApr 14, 2025 am 11:22 AM
Ted enthüllt von Openai, Google, Meta geht vor Gericht, Selfie mit mir selbstApr 14, 2025 am 11:22 AMDie TED2025 -Konferenz, die in Vancouver stattfand, beendete gestern, dem 11. April, ihre 36. Ausgabe. Es enthielt 80 Redner aus mehr als 60 Ländern, darunter Sam Altman, Eric Schmidt und Palmer Luckey. Teds Thema "Humanity Ranagined" wurde maßgeschneidert gemacht
 Joseph Stiglitz warnt vor der drohenden Ungleichheit inmitten der Monopolmacht der AIApr 14, 2025 am 11:21 AM
Joseph Stiglitz warnt vor der drohenden Ungleichheit inmitten der Monopolmacht der AIApr 14, 2025 am 11:21 AMJoseph Stiglitz ist der renommierte Ökonom und Empfänger des Nobelpreises in Wirtschaftswissenschaften im Jahr 2001. Stiglitz setzt, dass KI bestehende Ungleichheiten und konsolidierte Macht in den Händen einiger dominanter Unternehmen verschlimmern kann, was letztendlich die Wirtschaft untergräbt
 Was ist eine Graphendatenbank?Apr 14, 2025 am 11:19 AM
Was ist eine Graphendatenbank?Apr 14, 2025 am 11:19 AMGrafikdatenbanken: Datenmanagement durch Beziehungen revolutionieren Wenn sich die Daten erweitern und sich ihre Eigenschaften über verschiedene Bereiche hinweg entwickeln, entstehen Diagrammdatenbanken als transformative Lösungen für die Verwaltung miteinander verbundener Daten. Im Gegensatz zu traditioneller
 LLM Routing: Strategien, Techniken und Python -ImplementierungApr 14, 2025 am 11:14 AM
LLM Routing: Strategien, Techniken und Python -ImplementierungApr 14, 2025 am 11:14 AMLLM -Routing von großer Sprachmodell (LLM): Optimierung der Leistung durch intelligente Aufgabenverteilung Die sich schnell entwickelnde Landschaft von LLMs zeigt eine Vielzahl von Modellen mit jeweils einzigartigen Stärken und Schwächen. Einige zeichnen sich über kreative Inhalte aus


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

ZendStudio 13.5.1 Mac
Leistungsstarke integrierte PHP-Entwicklungsumgebung

VSCode Windows 64-Bit-Download
Ein kostenloser und leistungsstarker IDE-Editor von Microsoft

WebStorm-Mac-Version
Nützliche JavaScript-Entwicklungstools

