
Heim >Technologie-Peripheriegeräte >KI >Der Swin-Moment des visuellen Mamba-Modells, die Chinesische Akademie der Wissenschaften, Huawei und andere haben VMamba ins Leben gerufen
Der Swin-Moment des visuellen Mamba-Modells, die Chinesische Akademie der Wissenschaften, Huawei und andere haben VMamba ins Leben gerufen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-22 15:21:111003Durchsuche
Transformers Position im Bereich der Großmodelle ist unerschütterlich. Mit zunehmender Modellskala und zunehmender Sequenzlänge werden jedoch die Einschränkungen der traditionellen Transformer-Architektur deutlich. Glücklicherweise ändert sich diese Situation mit dem Aufkommen von Mamba schnell. Seine herausragende Leistung sorgte sofort für Aufsehen in der KI-Community. Das Aufkommen von Mamba hat große Durchbrüche beim groß angelegten Modelltraining und der Sequenzverarbeitung gebracht. Seine Vorteile verbreiten sich schnell in der KI-Community und wecken große Hoffnung für zukünftige Forschung und Anwendungen.
Am vergangenen Donnerstag hat die Einführung von Vision Mamba (Vim) sein großes Potenzial unter Beweis gestellt, das Rückgrat der nächsten Generation des visuellen Basismodells zu werden. Nur einen Tag später schlugen Forscher der Chinesischen Akademie der Wissenschaften, Huawei und des Pengcheng-Labors VMamba vor: Ein visuelles Mamba-Modell mit globalem Empfangsfeld und linearer Komplexität. Diese Arbeit markiert den visuellen Mamba-Model-Swin-Moment.

- Papiertitel: VMamba: Visual State Space Model
- Papieradresse: https://arxiv.org/abs/2401.10166
- Codeadresse: https://github .com/MzeroMiko/VMamba
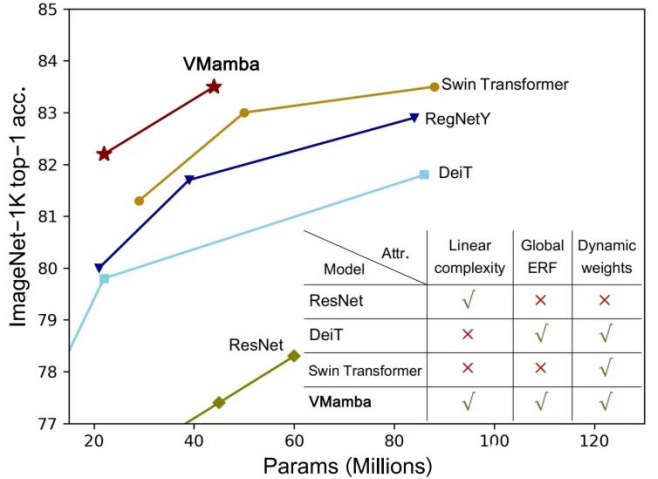
CNN und Visual Transformer (ViT) sind derzeit die beiden am weitesten verbreiteten grundlegenden visuellen Modelle. Obwohl CNN eine lineare Komplexität aufweist, verfügt ViT über leistungsfähigere Datenanpassungsfunktionen, jedoch auf Kosten einer höheren Rechenkomplexität. Forscher glauben, dass ViT über eine starke Anpassungsfähigkeit verfügt, da es über ein globales Empfangsfeld und dynamische Gewichte verfügt. Inspiriert durch das Mamba-Modell entwarfen Forscher ein Modell, das sowohl hervorragende Eigenschaften bei linearer Komplexität aufweist, nämlich das Visual State Space Model (VMamba). Umfangreiche Experimente haben gezeigt, dass VMamba bei verschiedenen visuellen Aufgaben gute Leistungen erbringt. Wie in der Abbildung unten gezeigt, erreicht VMamba-S eine Genauigkeit von 83,5 % auf ImageNet-1K, was 3,2 % höher als Vim-S und 0,5 % höher als Swin-S ist.
Einführung in die Methode

Der Schlüssel zum Erfolg von VMamba liegt in der Einführung des S6-Modells, das ursprünglich zur Lösung von NLP-Aufgaben (Natural Language Processing) entwickelt wurde. Im Gegensatz zum Aufmerksamkeitsmechanismus von ViT reduziert das S6-Modell die quadratische Komplexität effektiv auf Linearität, indem jedes Element im 1D-Vektor mit vorherigen Scaninformationen interagiert. Dieses Zusammenspiel macht VMamba effizienter bei der Verarbeitung großer Datenmengen. Daher legte die Einführung des S6-Modells eine solide Grundlage für den Erfolg von VMamba.
Da visuelle Signale (z. B. Bilder) jedoch nicht wie Textsequenzen auf natürliche Weise geordnet sind, kann die Datenscanmethode in S6 nicht direkt auf visuelle Signale angewendet werden. Zu diesem Zweck entwickelten Forscher einen Cross-Scan-Scanmechanismus. Cross-Scan-Modul (CSM) verwendet eine Vier-Wege-Scan-Strategie, d. h. das gleichzeitige Scannen aus den vier Ecken der Feature-Map (siehe Abbildung oben). Diese Strategie stellt sicher, dass jedes Element im Feature Informationen von allen anderen Standorten in verschiedene Richtungen integriert und so ein globales Empfangsfeld bildet, ohne die lineare Rechenkomplexität zu erhöhen.
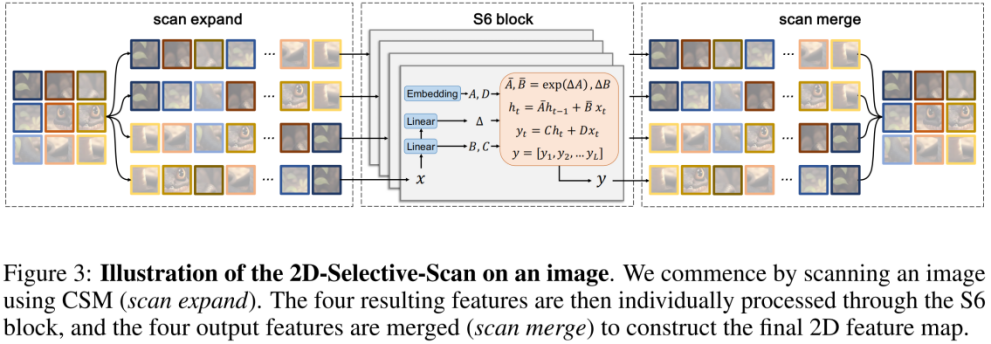
Basierend auf CSM hat der Autor das 2D-Selective-Scan-Modul (SS2D) entworfen. Wie in der Abbildung oben gezeigt, besteht SS2D aus drei Schritten:
- scan expand reduziert ein 2D-Feature in einen 1D-Vektor entlang von 4 verschiedenen Richtungen (oben links, unten rechts, unten links, oben rechts).
- Der S6-Block sendet die vier im vorherigen Schritt erhaltenen 1D-Vektoren unabhängig an die S6-Operation.
- Scan Merge verschmilzt die resultierenden 4 1D-Vektoren zu einer 2D-Feature-Ausgabe.
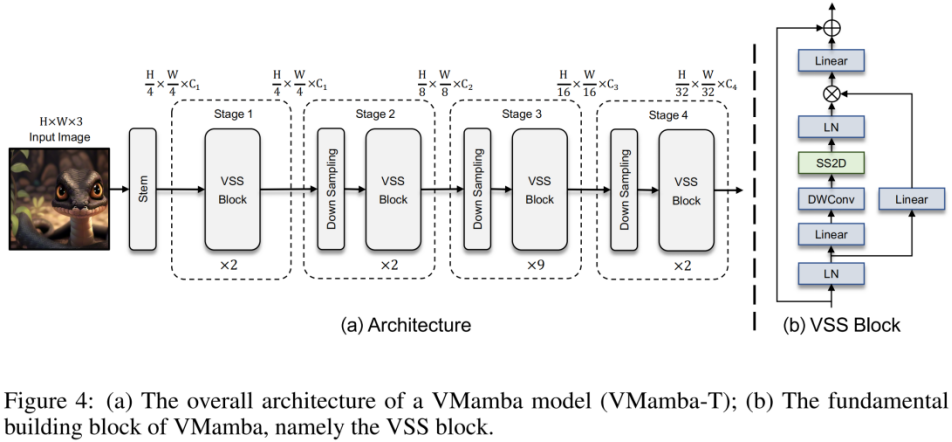
Das obige Bild ist das in diesem Artikel vorgeschlagene VMamba-Strukturdiagramm. Das Gesamtgerüst von VMamba ähnelt dem gängigen visuellen Modell. Der Hauptunterschied liegt in den im Basismodul (VSS-Block) verwendeten Operatoren. Der VSS-Block verwendet die oben eingeführte 2D-selektive Scan-Operation, nämlich SS2D. SS2D stellt sicher, dass VMamba ein „globales Empfangsfeld“ auf Kosten einer „linearen Komplexität“ erreicht. Experimentelle Ergebnisse VMamba-S erreichte eine Leistung von 83,5 % und übertraf damit RegNetY-8G um 1,8 % und Swin-S um 0,5 %. VMamba-B erreichte eine Leistung von
Effektives Empfangsfeld
VMamba verfügt über ein globales effektives Empfangsfeld, und unter anderen Modellen verfügt nur DeiT über diese Funktion. Es ist jedoch erwähnenswert, dass die Kosten von DeiT quadratischer Komplexität entsprechen, während VMamaba linearer Komplexität entspricht. Skalierung der Eingabeskala
Die obige Abbildung (b) zeigt, dass die Komplexität der Modelle der VMamba-Serie linear zunimmt, wenn die Eingabe größer wird, was mit dem CNN-Modell übereinstimmt. Die Leistung übertrifft RegNetY-4G um 2,2 %, DeiT-S um 2,4 % und Swin-T um 0,9 %.
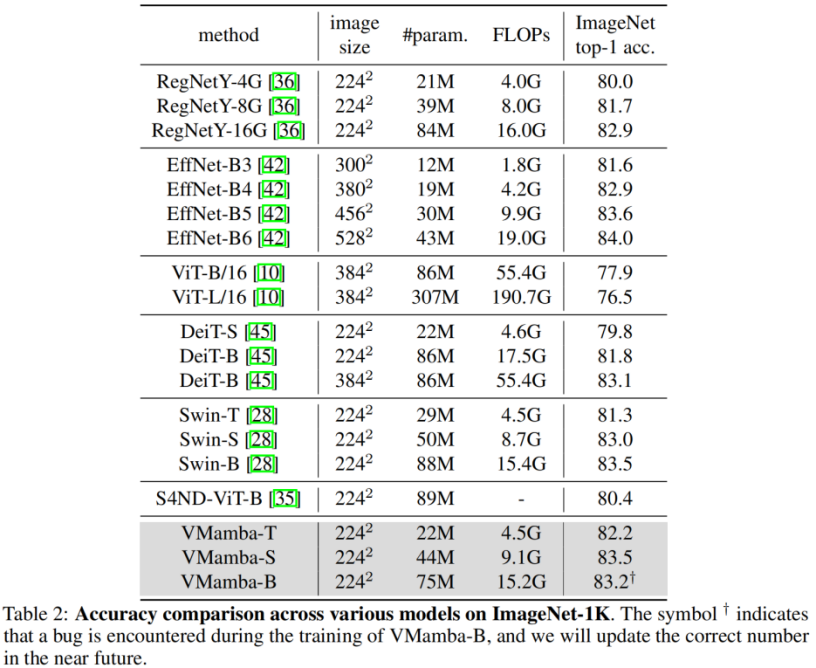 83,2 %
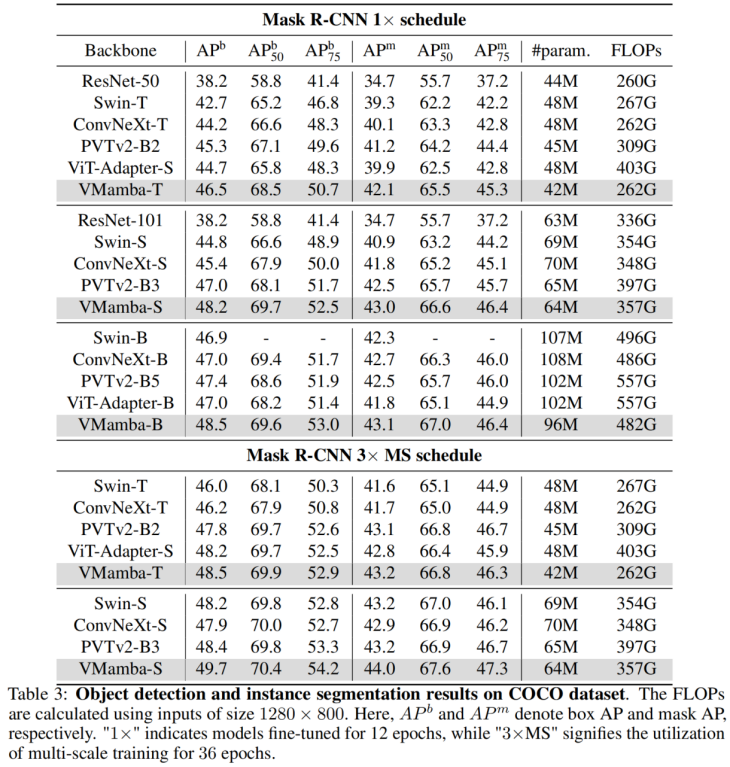
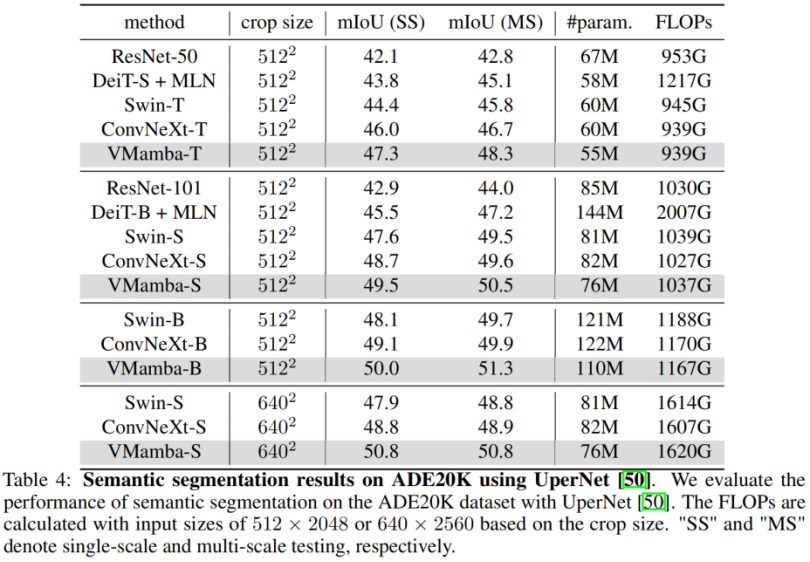
83,2 %Diese Ergebnisse sind viel höher als die des Vision Mamba (Vim)-Modells und bestätigen das Potenzial von VMamba vollständig. COCO-Zielerkennung 48,2 %/48,5 % mAP, übertraf Swin-T/S/B um 3,8 %/3,6 %/1,6 % mAP und übertraf ConvNeXt-T/S/B um 2,3 %/2,8 %/1,5 % mAP. Diese Ergebnisse bestätigen, dass VMamba in visuellen Downstream-Experimenten vollständig funktioniert und demonstriert sein Potenzial, gängige grundlegende visuelle Modelle zu ersetzen.
 Die obige Abbildung (a) zeigt, dass VMamba bei unterschiedlichen Eingabebildgrößen die stabilste Leistung (ohne Feinabstimmung) aufweist. Interessanterweise zeigt nur VMamba bei einer Erhöhung der Eingabegröße von 224 × 224 auf 384 × 384 eine signifikante Leistungssteigerung (VMamba-S von 83,5 % auf 84,0 %), was seine Robustheit gegenüber Änderungen im Geschlecht der Eingabebildgröße unterstreicht.
Die obige Abbildung (a) zeigt, dass VMamba bei unterschiedlichen Eingabebildgrößen die stabilste Leistung (ohne Feinabstimmung) aufweist. Interessanterweise zeigt nur VMamba bei einer Erhöhung der Eingabegröße von 224 × 224 auf 384 × 384 eine signifikante Leistungssteigerung (VMamba-S von 83,5 % auf 84,0 %), was seine Robustheit gegenüber Änderungen im Geschlecht der Eingabebildgröße unterstreicht. Abschließend freuen wir uns darauf, dass neben CNNs und ViTs weitere Mamba-basierte Vision-Modelle vorgeschlagen werden, um eine dritte Option für grundlegende Vision-Modelle bereitzustellen.
Das obige ist der detaillierte Inhalt vonDer Swin-Moment des visuellen Mamba-Modells, die Chinesische Akademie der Wissenschaften, Huawei und andere haben VMamba ins Leben gerufen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist das CSS-Box-Modell?
- Beschreiben Sie kurz, was die Speichereinheit für Daten in einem Computer ist.
- So verwenden Sie die Vlookup-Funktion von Excel, um mehrere Datenspalten gleichzeitig abzugleichen
- Was soll ich tun, wenn WPS-Text die Datenquelle nicht öffnen kann?
- Wie läuft die Konvertierung eines E-R-Diagramms in ein relationales Datenmodell ab?