
Heim >Technologie-Peripheriegeräte >KI >Aktualisierter Point Transformer: effizienter, schneller und leistungsfähiger!
Aktualisierter Point Transformer: effizienter, schneller und leistungsfähiger!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-17 08:27:051318Durchsuche
Originaltitel: Point Transformer V3: Simpler, Faster, Stronger
Papierlink: https://arxiv.org/pdf/2312.10035.pdf
Codelink: https://github.com/Pointcept/PointTransformerV3
Autor Einheit: HKU SH AI Lab MPI PKU MIT
Idee für die Abschlussarbeit:
Dieser Artikel zielt nicht darauf ab, Innovationen innerhalb des Aufmerksamkeitsmechanismus zu suchen. Stattdessen liegt der Schwerpunkt darauf, die Macht der Skalierung zu nutzen, um bestehende Kompromisse zwischen Genauigkeit und Effizienz im Kontext der Punktwolkenverarbeitung zu überwinden. Inspiriert von den jüngsten Fortschritten beim Lernen großräumiger 3D-Darstellungen erkennt dieser Artikel an, dass die Modellleistung stärker von der Skalierung als von der Komplexität des Designs abhängt. Daher wird in diesem Artikel Point Transformer V3 (PTv3) vorgeschlagen, bei dem Einfachheit und Effizienz Vorrang vor der Genauigkeit bestimmter Mechanismen haben, die nach der Skalierung weniger Einfluss auf die Gesamtleistung haben, z. B. Punktwolken, die in bestimmten Mustern organisiert sind, um KNNs zu ersetzen genaue Nachbarschaftssuche. Dieses Prinzip ermöglicht eine erhebliche Skalierung und erweitert das Empfangsfeld von 16 auf 1024 Punkte, während es gleichzeitig effizient bleibt (3x schnellere Verarbeitung und 10x mehr Speichereffizienz im Vergleich zum Vorgänger PTv2). PTv3 erzielt hochmoderne Ergebnisse bei mehr als 20 nachgelagerten Aufgaben, die Innen- und Außenszenarien abdecken. PTv3 bringt diese Ergebnisse mit weiteren Verbesserungen durch gemeinsames Training mit mehreren Datensätzen auf die nächste Ebene.
Netzwerkdesign:
Jüngste Fortschritte beim 3D-Darstellungslernen [85] haben Fortschritte bei der Überwindung von Datenskalenbeschränkungen bei der Punktwolkenverarbeitung durch die Einführung kollaborativer Trainingsmethoden für mehrere 3D-Datensätze gemacht. In Kombination mit dieser Strategie überbrückt ein effizientes Faltungs-Backbone [12] effektiv die Genauigkeitslücke, die typischerweise mit Punktwolkentransformatoren verbunden ist [38, 84]. Allerdings haben Punktwolkentransformatoren selbst aufgrund der Effizienzlücke von Punktwolkentransformatoren im Vergleich zu spärlichen Faltungen noch nicht vollständig von diesem Skalenvorteil profitiert. Diese Entdeckung bildete die ursprüngliche Motivation für diese Arbeit: die Entwurfsentscheidungen von Punkttransformatoren aus der Perspektive des Skalierungsprinzips neu abzuwägen. In diesem Artikel wird davon ausgegangen, dass die Modellleistung stärker von der Skalierung als vom komplexen Design beeinflusst wird.
Daher stellt dieser Artikel Point Transformer V3 (PTv3) vor, bei dem Einfachheit und Effizienz Vorrang vor der Genauigkeit bestimmter Mechanismen haben, um Skalierbarkeit zu erreichen. Solche Anpassungen haben nach der Skalierung vernachlässigbare Auswirkungen auf die Gesamtleistung. Insbesondere hat PTv3 die folgenden Anpassungen vorgenommen, um eine überlegene Effizienz und Skalierbarkeit zu erreichen:
- Inspiriert von zwei jüngsten Fortschritten [48, 77] und der Erkenntnis der Skalierbarkeitsvorteile strukturierter unstrukturierter Punktwolken änderte PTv3 die traditionelle räumliche Nähe, die durch K-Nearest definiert wird Die Abfrage von Nachbarn (KNN) macht 28 % der Weiterleitungszeit aus. Stattdessen wird das Potenzial serialisierter Nachbarschaften in Punktwolken untersucht, die nach bestimmten Mustern organisiert sind.
- PTv3 verwendet einen vereinfachten Ansatz, der speziell auf serialisierte Punktwolken zugeschnitten ist und komplexere Aufmerksamkeits-Patch-Interaktionsmechanismen wie Shift-Window (was die Fusion von Aufmerksamkeitsoperatoren behindert) und Nachbarschaftsmechanismen (was zu einem hohen Speicherverbrauch führt) ersetzt.
- PTv3 eliminiert die Abhängigkeit von der relativen Positionskodierung, die 26 % der Vorlaufzeit ausmacht, und setzt stattdessen auf einfachere Front-End-Faltungsschichten mit geringer Dichte.
In diesem Artikel werden diese Entwürfe als intuitive Entscheidungen betrachtet, die auf Skalierungsprinzipien und Fortschritten bei bestehenden Punktwolkentransformatoren beruhen. Wichtig ist, dass dieser Artikel hervorhebt, wie wichtig es ist, zu verstehen, wie sich Skalierbarkeit auf das Backbone-Design auswirkt, und nicht auf das detaillierte Moduldesign.
Dieses Prinzip verbessert die Skalierbarkeit erheblich und überwindet den traditionellen Kompromiss zwischen Genauigkeit und Effizienz (siehe Abbildung 1). PTv3 bietet eine 3,3-mal schnellere Inferenz und eine 10,2-mal geringere Speichernutzung als sein Vorgänger. Noch wichtiger ist, dass PTv3 seine inhärente Fähigkeit nutzt, den Erfassungsbereich zu skalieren und sein Empfangsfeld von 16 auf 1024 Punkte zu erweitern und gleichzeitig die Effizienz beizubehalten. Diese Skalierbarkeit untermauert seine überlegene Leistung bei realen Wahrnehmungsaufgaben, wobei PTv3 bei mehr als 20 nachgelagerten Aufgaben in Innen- und Außenszenarien hochmoderne Ergebnisse erzielt. PTv3 verbessert diese Ergebnisse weiter, indem es seine Datengröße durch Training mit mehreren Datensätzen weiter erhöht [85]. Wir hoffen, dass die Erkenntnisse dieses Artikels zukünftige Forschungen in dieser Richtung inspirieren werden.
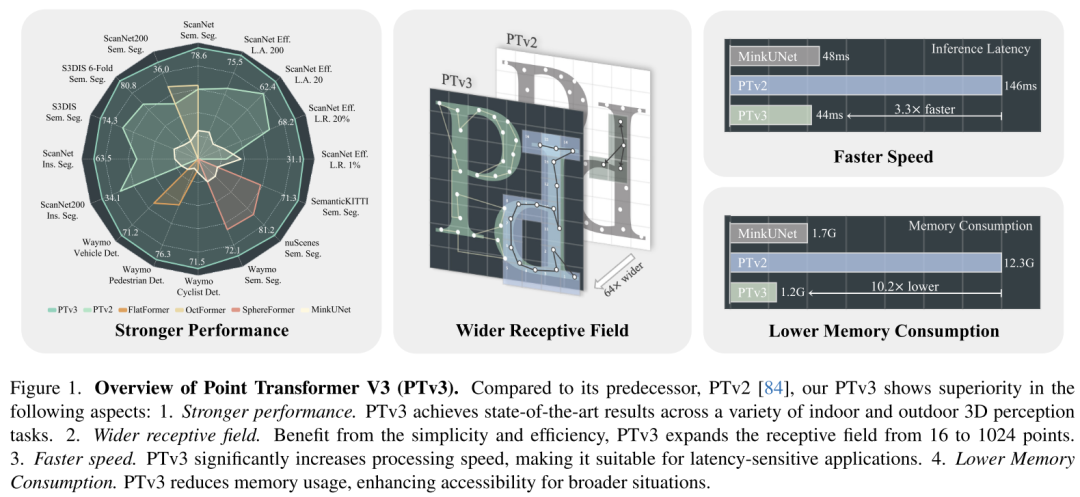
Abbildung 1. Übersicht über Point Transformer V3 (PTv3). Im Vergleich zu seinem Vorgänger PTv2 [84] zeigt PTv3 in diesem Artikel eine Überlegenheit in den folgenden Aspekten: 1. Stärkere Leistung. PTv3 erzielt modernste Ergebnisse bei einer Vielzahl von 3D-Wahrnehmungsaufgaben im Innen- und Außenbereich. 2. Breiteres Empfangsfeld. Dank seiner Einfachheit und Effizienz erweitert PTv3 das Empfangsfeld von 16 auf 1024 Punkte. 3. Schneller. PTv3 erhöht die Verarbeitungsgeschwindigkeit erheblich und eignet sich daher für latenzempfindliche Anwendungen. 4. Reduzieren Sie den Speicherverbrauch. PTv3 reduziert die Speichernutzung und verbessert die Zugänglichkeit in einem breiteren Spektrum von Situationen.
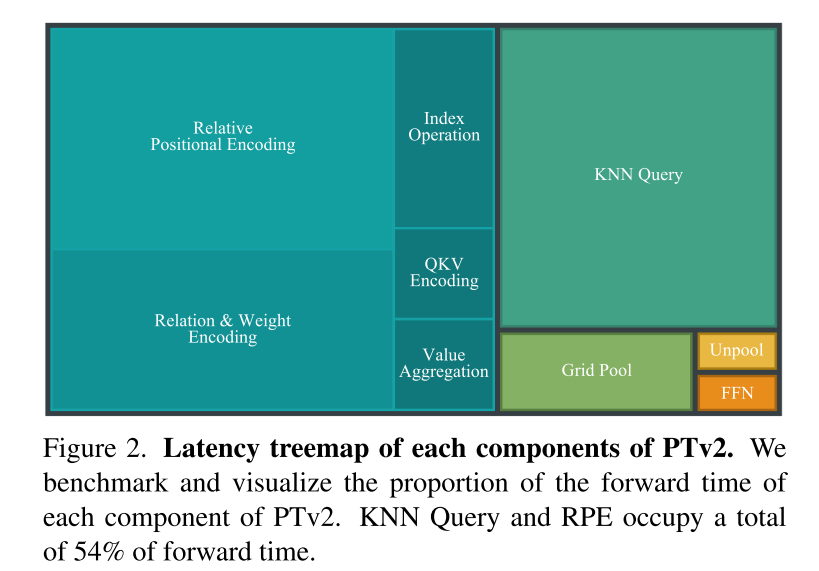
Abbildung 2. Verzögerungsbaumdiagramm jeder Komponente von PTv2. Dieser Artikel bewertet und visualisiert das Vorwärtszeitverhältnis jeder Komponente von PTv2. KNN-Abfragen und RPE beanspruchen insgesamt 54 % der Weiterleitungszeit.

Abbildung 3. Punktwolken-Serialisierung. Dieser Artikel demonstriert vier Serialisierungsmuster durch Triplett-Visualisierung. Für jedes Triplett werden die raumfüllende Kurve für die Serialisierung (links), die Sortierreihenfolge der Punktwolken-Serialisierungsvariablen innerhalb der raumfüllenden Kurve (Mitte) und die gruppierten Patches der serialisierten Punktwolke für die lokale Aufmerksamkeit angezeigt (rechts). Durch die Transformation der vier Serialisierungsmodi kann der Aufmerksamkeitsmechanismus verschiedene räumliche Beziehungen und Kontexte erfassen und so die Modellgenauigkeit und Generalisierungsfähigkeit verbessern.
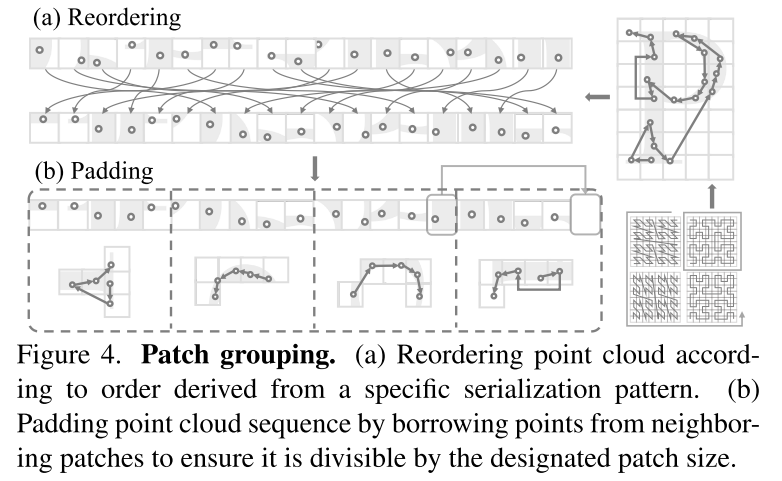
Abbildung 4. Patch-Gruppierung. (a) Neuordnung von Punktwolken gemäß einer aus einem bestimmten Serialisierungsschema abgeleiteten Reihenfolge. (b) Füllen Sie die Punktwolkensequenz, indem Sie Punkte aus benachbarten Patches übernehmen, um sicherzustellen, dass sie durch die angegebene Patchgröße teilbar ist.
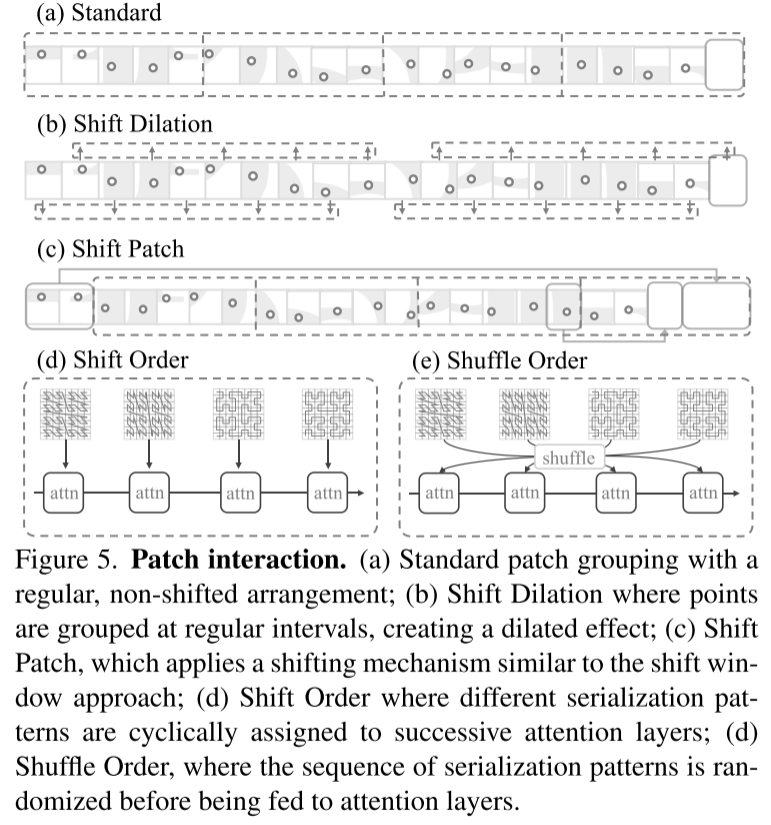
Abbildung 5. Patch-Interaktion. (a) Standard-Patch-Gruppierung mit einer regelmäßigen, nicht verschobenen Anordnung; (b) Translationserweiterung, bei der Punkte in regelmäßigen Abständen zusammengefasst werden, um einen Expansionseffekt zu erzeugen; (c) Shift Patch, der einen Verschiebungsmechanismus ähnlich dem verwendet Shift-Window-Methode; (d) Shift Order, bei der verschiedene Serialisierungsmuster zyklisch aufeinanderfolgenden Aufmerksamkeitsschichten zugewiesen werden; (d) Shuffle Order, bei der die Reihenfolge der Serialisierungsmuster vor der Eingabe in die Aufmerksamkeitsschicht randomisiert wird;
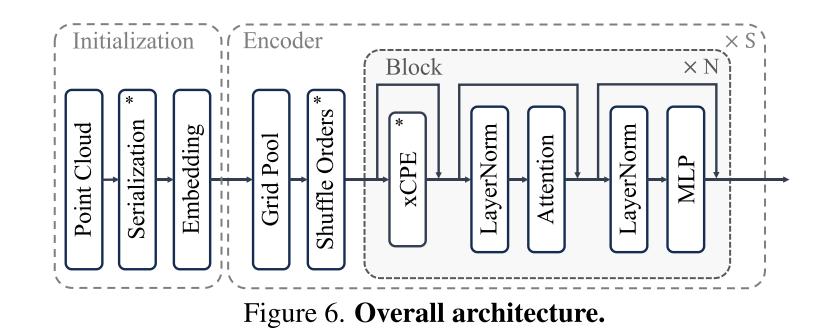
Abbildung 6. Gesamtarchitektur.
Experimentelle Ergebnisse:
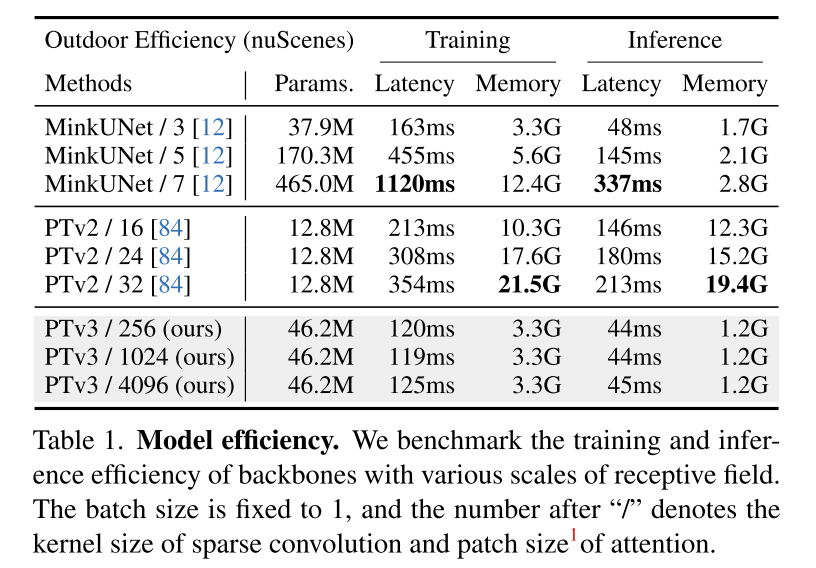
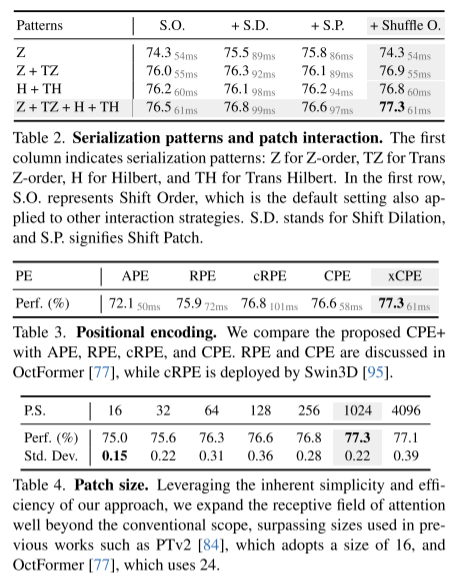
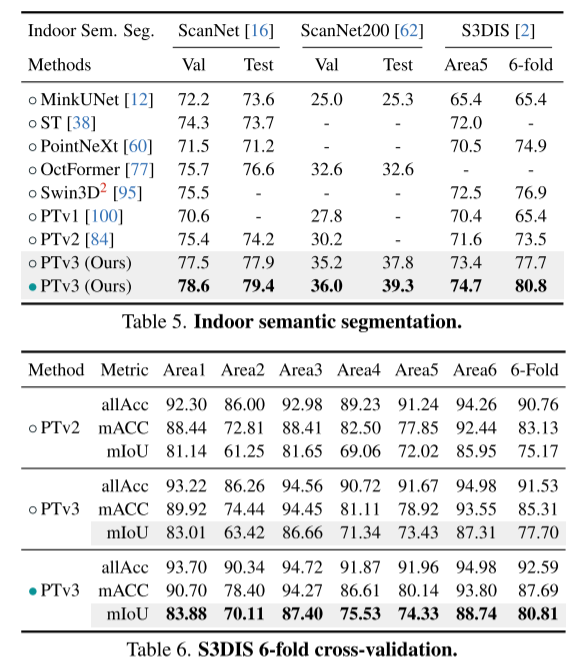
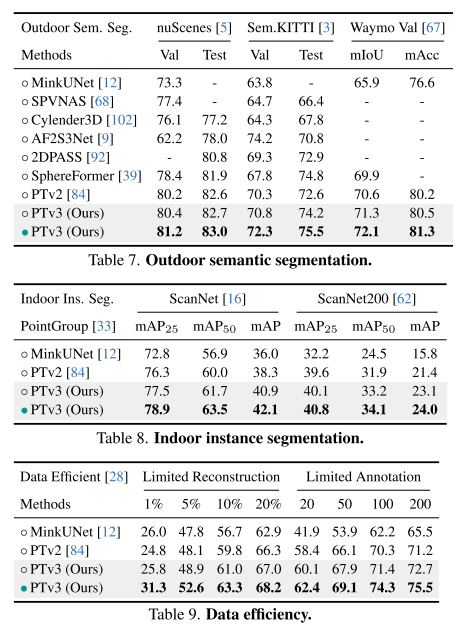
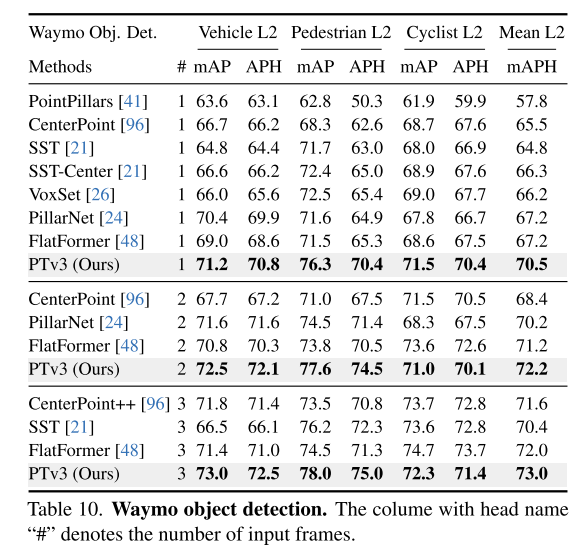
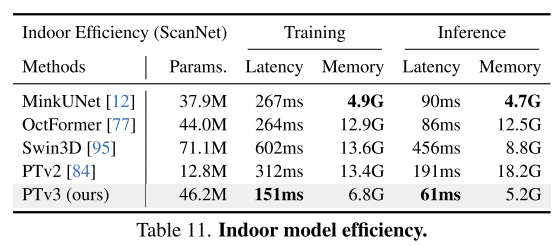
Zusammenfassung:
In diesem Artikel wird Point Transform er V3 vorgestellt, der darauf abzielt, die Genauigkeit bei der Verarbeitung von Punktwolken zu verbessern Ein großer Fortschritt gegenüber dem traditionellen Kompromiss zwischen Effizienz und Effizienz. Basierend auf einer neuartigen Interpretation des Skalierungsprinzips im Backbone-Design argumentiert dieser Artikel, dass die Modellleistung stärker von der Skalierung als von der Komplexität des Designs beeinflusst wird. Durch die Priorisierung der Effizienz gegenüber der Genauigkeit kleinerer Schlagmechanismen nutzt dieses Papier die Macht der Skalierung und verbessert dadurch die Leistung. Kurz gesagt, dieser Artikel kann ein Modell leistungsfähiger machen, indem er es einfacher und schneller macht.
Zitat:
Wu, X., Jiang, L., Wang, P., Liu, Z., Liu, X., Qiao, Y., Ouyang, W., He, T. und Zhao , H. (2023). Point Transformer V3: Einfacher, schneller, stärker
Das obige ist der detaillierte Inhalt vonAktualisierter Point Transformer: effizienter, schneller und leistungsfähiger!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Das Training von ViT und MAE reduziert den Rechenaufwand um die Hälfte! Sea und die Peking-Universität haben gemeinsam den effizienten Optimierer Adan vorgeschlagen, der für tiefe Modelle verwendet werden kann
- Analyse der KI-Trainingsbeschleunigungsprinzipien und Austausch technischer Praxis
- Programmierer sind in Gefahr! Es heißt, dass OpenAI weltweit Outsourcing-Truppen rekrutiert und ChatGPT-Code-Farmer Schritt für Schritt schult
- NUS und Byte arbeiteten branchenübergreifend zusammen, um durch Modelloptimierung ein 72-mal schnelleres Training zu erreichen, und gewannen den AAAI2023 Outstanding Paper.
- QTNet: Neue zeitliche Fusionslösung für Punktwolken, Bilder und multimodale Detektoren (NeurIPS 2023)