
Heim >Technologie-Peripheriegeräte >KI >Die Shanghai Jiao Tong University veröffentlicht die Inferenz-Engine PowerInfer. Ihre Token-Generierungsrate ist nur 18 % niedriger als die von A100. Sie kann 4090 als Ersatz für A100 ersetzen.
Die Shanghai Jiao Tong University veröffentlicht die Inferenz-Engine PowerInfer. Ihre Token-Generierungsrate ist nur 18 % niedriger als die von A100. Sie kann 4090 als Ersatz für A100 ersetzen.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-16 21:27:051190Durchsuche
Um den Inhalt neu zu schreiben, ohne die ursprüngliche Bedeutung zu ändern, muss die Sprache ins Chinesische umgeschrieben werden und der Originalsatz muss nicht erscheinen
Die Redaktion dieser Website


Auf einer einzelnen RTX 4090 (24G) mit Falcon (ReLU)-40B-FP16 erreichte PowerInfer eine 11-fache Geschwindigkeitssteigerung im Vergleich zu llama.cpp!
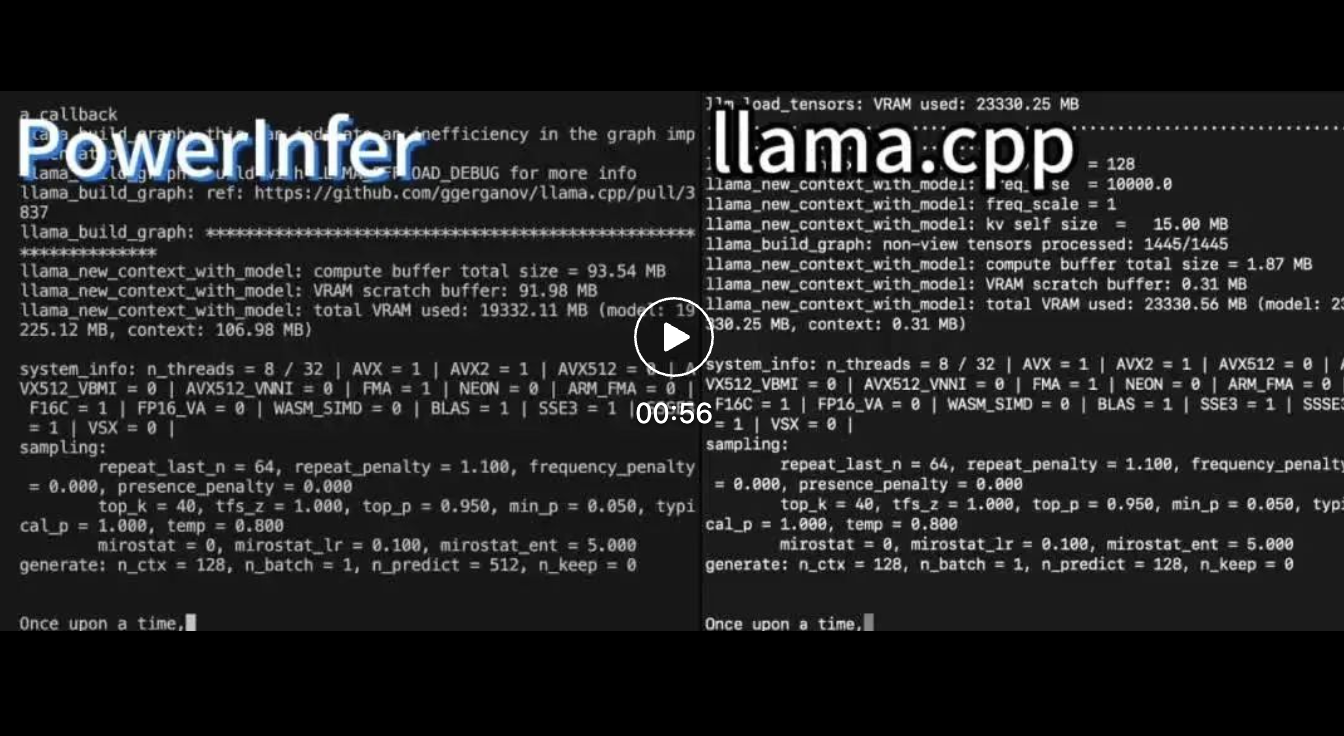 Über verschiedene LLMs auf einer einzelnen NVIDIA RTX 4090-GPU beträgt die durchschnittliche Token-Generierungsrate von PowerInfer 13,20 Token/Sekunde, mit einem Spitzenwert von 29,08 Token/Sekunde, was nur 18 % niedriger ist als beim Top-Server-A100 GPU.
Über verschiedene LLMs auf einer einzelnen NVIDIA RTX 4090-GPU beträgt die durchschnittliche Token-Generierungsrate von PowerInfer 13,20 Token/Sekunde, mit einem Spitzenwert von 29,08 Token/Sekunde, was nur 18 % niedriger ist als beim Top-Server-A100 GPU.
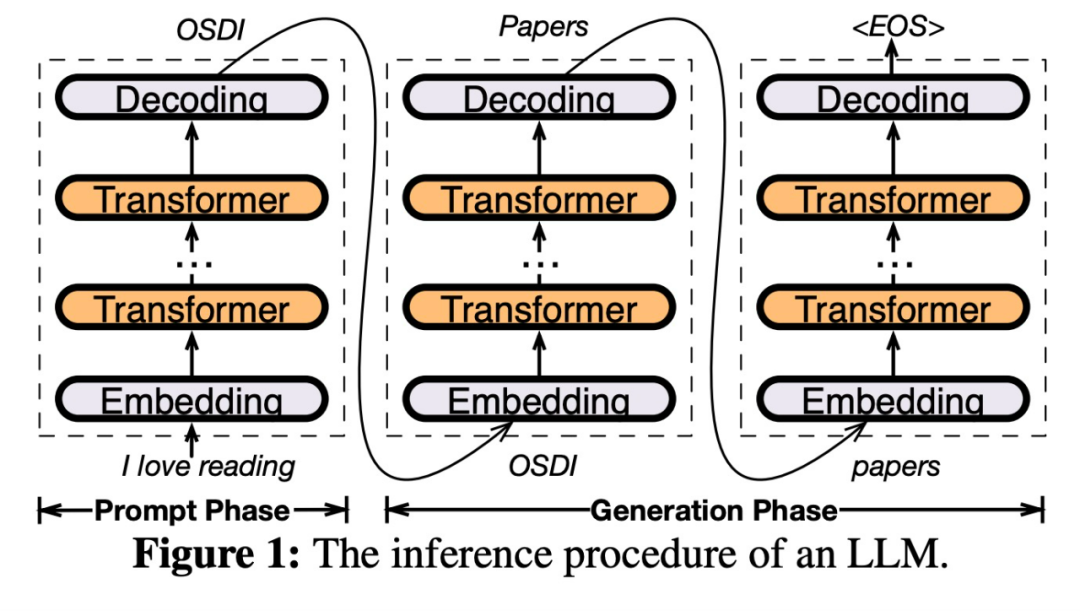
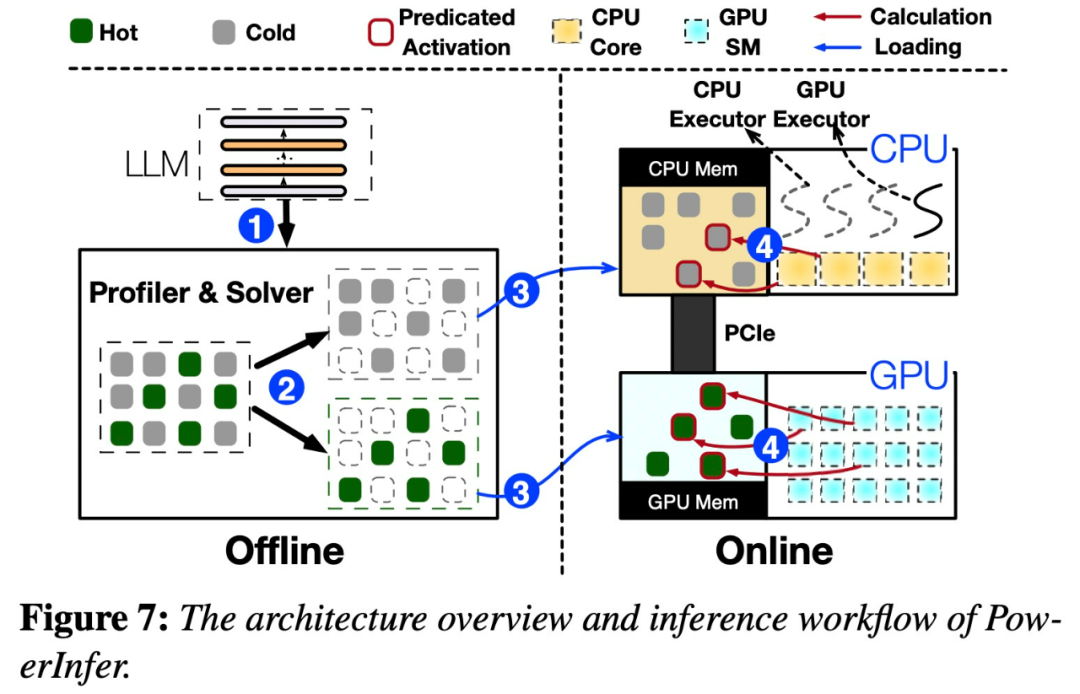
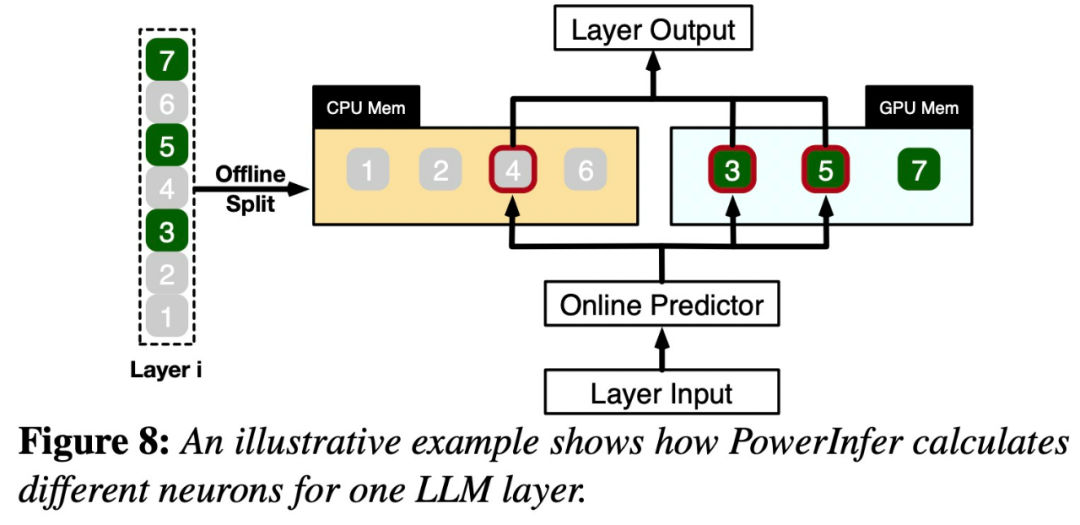
Das obige ist der detaillierte Inhalt vonDie Shanghai Jiao Tong University veröffentlicht die Inferenz-Engine PowerInfer. Ihre Token-Generierungsrate ist nur 18 % niedriger als die von A100. Sie kann 4090 als Ersatz für A100 ersetzen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wo ist die Adresse der World VR Industry Conference?
- Stärken Sie die Modebranche mit Technologie und unterstützen Sie den Bezirk Futian beim Aufbau eines „Bay Area Fashion Headquarters Center'.
- Huawei Cloud und eine Reihe von Unternehmen haben eine Aktionsinitiative gestartet: Gemeinsam ein offenes industrielles Ökosystem für autonomes Fahren aufbauen
- Die Nachfrage nach KI-Rechenleistung ist stark gestiegen, und Shanghai Lingang wird eine Rechenleistungsindustrie im zweistelligen Milliardenbereich aufbauen
- Aus dem Nichts! Assistent für künstliche Intelligenz Ai Pin veröffentlicht: Kann den Bildschirm von Ihrer Handfläche aus werfen [mit Analyse der Industriekette für künstliche Intelligenz]