
Heim >Technologie-Peripheriegeräte >KI >Google führt den BIG-Bench Mistake-Datensatz ein, um KI bei der Verbesserung der Fehlerkorrekturfähigkeiten zu unterstützen
Google führt den BIG-Bench Mistake-Datensatz ein, um KI bei der Verbesserung der Fehlerkorrekturfähigkeiten zu unterstützen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-16 18:57:16751Durchsuche
Google Research hat kürzlich eine Evaluierungsstudie zu beliebten Sprachmodellen durchgeführt und dabei seinen eigenen BIG-Bench-Benchmark und den neu erstellten „BIG-Bench Mistake“-Datensatz verwendet. Sie konzentrierten sich hauptsächlich auf die Fehlerwahrscheinlichkeit und Fehlerkorrekturfähigkeit des Sprachmodells. Diese Studie liefert wertvolle Daten, um die Leistung von Sprachmodellen auf dem Markt besser zu verstehen.
Google-Forscher sagten, sie hätten einen speziellen Benchmark-Datensatz namens „BIG-Bench Mistake“ erstellt, um die „Fehlerwahrscheinlichkeit“ und „Selbstkorrekturfähigkeit“ großer Sprachmodelle zu bewerten. Dies liegt daran, dass es in der Vergangenheit an entsprechenden Datensätzen mangelte, um diese Schlüsselindikatoren effektiv bewerten und testen zu können.
Die Forscher verwendeten das PaLM-Sprachmodell, um 5 Aufgaben in ihrer eigenen BIG-Bench-Benchmark-Aufgabe auszuführen, und fügten die generierte „Gedankenkette“-Trajektorie zum „Logikfehler“-Teil hinzu, um die Modellgenauigkeit erneut zu testen.
Um die Genauigkeit des Datensatzes zu verbessern, wiederholten die Google-Forscher den oben genannten Prozess und erstellten schließlich einen Benchmark-Datensatz speziell für die Auswertung, der 255 logische Fehler enthielt, die als „BIG-Bench-Fehler“ bezeichnet wurden.
Forscher wiesen darauf hin, dass die logischen Fehler im Datensatz „BIG-Bench Mistake“ sehr offensichtlich sind, sodass er als guter Standard für Sprachmodelltests verwendet werden kann. Dieser Datensatz hilft dem Modell, aus einfachen Fehlern zu lernen und seine Fähigkeit zur Fehlererkennung schrittweise zu verbessern.
Die Forscher verwendeten diesen Datensatz, um Modelle auf dem Markt zu testen und stellten fest, dass die meisten Sprachmodelle zwar logische Fehler im Argumentationsprozess erkennen und sich selbst korrigieren können, dieser Prozess jedoch nicht sehr ideal ist. Oft ist auch menschliches Eingreifen erforderlich, um die Modellausgaben zu korrigieren.
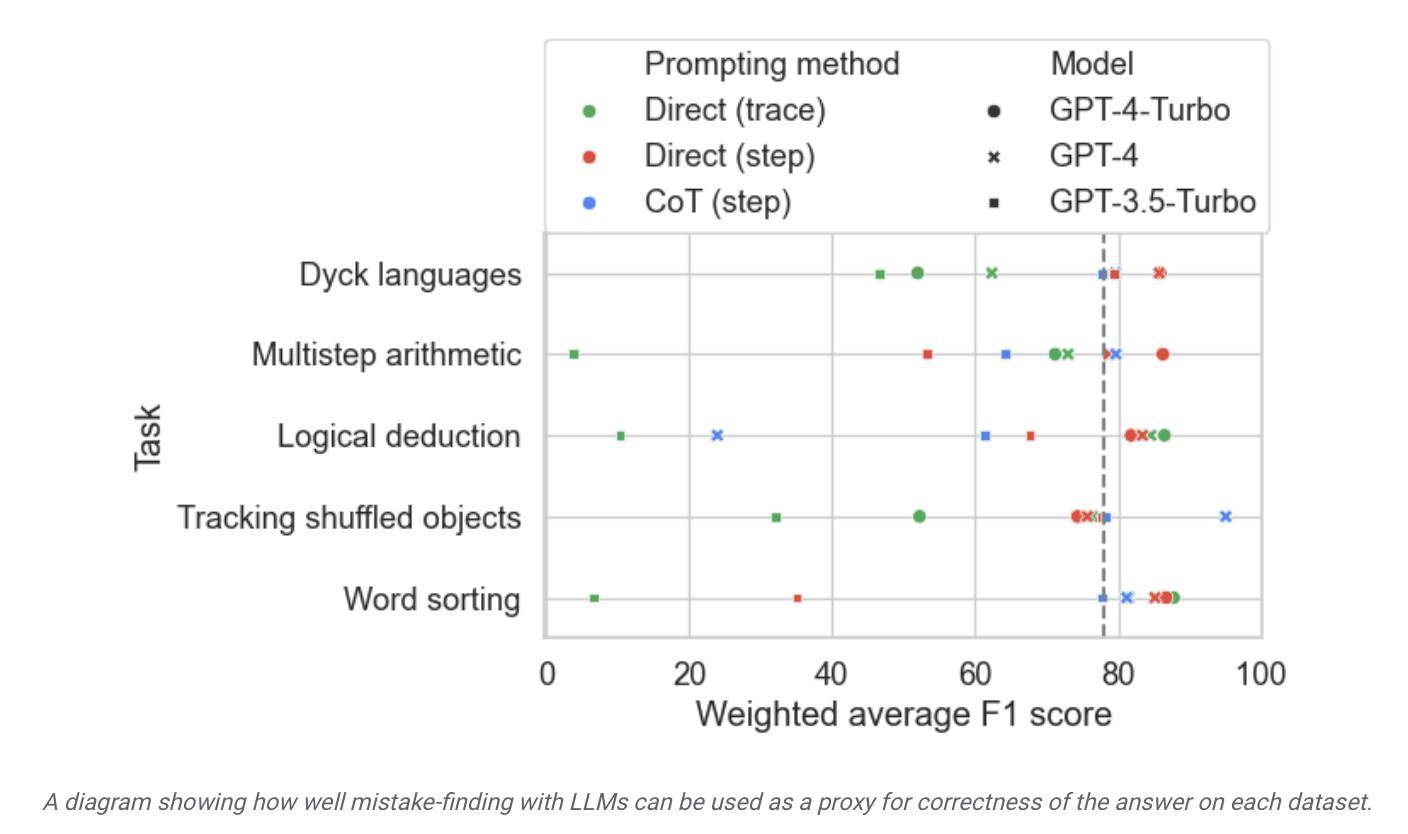
▲ Bildquelle: Pressemitteilung von Google Research
Dem Bericht zufolge gilt Google zwar als das derzeit fortschrittlichste große Sprachmodell, seine Selbstkorrekturfähigkeit ist jedoch relativ begrenzt. Beim Testen fand das leistungsstärkste Modell nur 52,9 % der logischen Fehler.

Google-Forscher behaupteten außerdem, dass dieser BIG-Bench-Fehlerdatensatz dazu beiträgt, die Selbstkorrekturfähigkeit des Modells zu verbessern. Nach der Feinabstimmung des Modells auf relevante Testaufgaben „schneiden selbst kleine Modelle normalerweise besser ab als große Modelle ohne Stichprobe.“ Eingabeaufforderungen.
Dementsprechend glaubt Google, dass im Hinblick auf die Modellfehlerkorrektur proprietäre kleine Modelle zur „Überwachung“ großer Modelle verwendet werden können, im Vergleich dazu, große Sprachmodelle lernen zu lassen, „Selbstfehler zu korrigieren“, indem kleine dedizierte Modelle zur Überwachung eingesetzt werden Große Modelle tragen zur Verbesserung der Effizienz bei, reduzieren die damit verbundenen Kosten für die KI-Bereitstellung und erleichtern die Feinabstimmung.
Das obige ist der detaillierte Inhalt vonGoogle führt den BIG-Bench Mistake-Datensatz ein, um KI bei der Verbesserung der Fehlerkorrekturfähigkeiten zu unterstützen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr