
Heim >Technologie-Peripheriegeräte >KI >NVIDIA, Mila und Caltech veröffentlichen gemeinsam ein multimodales molekulares Struktur-Text-Modell, das LLM mit der Arzneimittelforschung kombiniert
NVIDIA, Mila und Caltech veröffentlichen gemeinsam ein multimodales molekulares Struktur-Text-Modell, das LLM mit der Arzneimittelforschung kombiniert

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-14 20:00:05934Durchsuche

Autor |. Liu Shengchao
Herausgeber |. Kaixia
Seit 2021 hat die Kombination aus großer Sprache und Multimodalität die Forschungsgemeinschaft für maschinelles Lernen erobert.
Können wir diese Techniken angesichts der Entwicklung großer Modelle und multimodaler Anwendungen auf die Arzneimittelforschung anwenden? Und können diese Textbeschreibungen in natürlicher Sprache neue Perspektiven für dieses herausfordernde Problem eröffnen? Die Antwort lautet „Ja“, und wir sind diesbezüglich optimistisch Das Institute of Technology schlägt ein multimodales Molekülstruktur-Text-Modell MoleculeSTM vor, bei dem die chemische Struktur und die Textbeschreibung von Molekülen durch kontrastive Lernstrategien gemeinsam erlernt werden.
Diese Forschung trägt den Titel „Multimodale Molekülstruktur – Textmodell für textbasiertes Abrufen und Bearbeiten“ und wurde am 18. Dezember 2023 in „Nature Machine Intelligence“ veröffentlicht.
 Link zum Papier: https://www.nature.com/articles/s42256-023-00759-6 muss neu geschrieben werden
Link zum Papier: https://www.nature.com/articles/s42256-023-00759-6 muss neu geschrieben werden
Dr. Liu Shengchao ist der erste Autor und Professor Anima Anandkumar von NVIDIA Research der korrespondierende Autor. Nie Weili, Wang Chengpeng, Lu Jiarui, Qiao Zhuoran, Liu Ling, Tang Jian und Xiao Chaowei sind Co-Autoren.
Dieses Projekt wurde von Dr. Liu Shengchao durchgeführt, nachdem er im März 2022 zu NVIDIA Research kam, unter der Leitung der Lehrer Nie Weili, Lehrer Tang Jian, Lehrer Xiao Chaowei und Lehrer Anima Anandkumar.
Dr. Liu Shengchao sagte: „Unsere Motivation bestand darin, vorläufige Untersuchungen zu LLM und Arzneimittelentwicklung durchzuführen und schließlich MoleculeSTM vorzuschlagen.“ ist sehr einfach und unkompliziert, das heißt, die Beschreibung von Molekülen kann in zwei Kategorien unterteilt werden: interne chemische Struktur und externe Funktionsbeschreibung. Hier verwenden wir eine kontrastive Vortrainingsmethode, um diese beiden Arten von Informationen auszurichten und zu verbinden. Das spezifische Diagramm ist in der Abbildung unten dargestellt
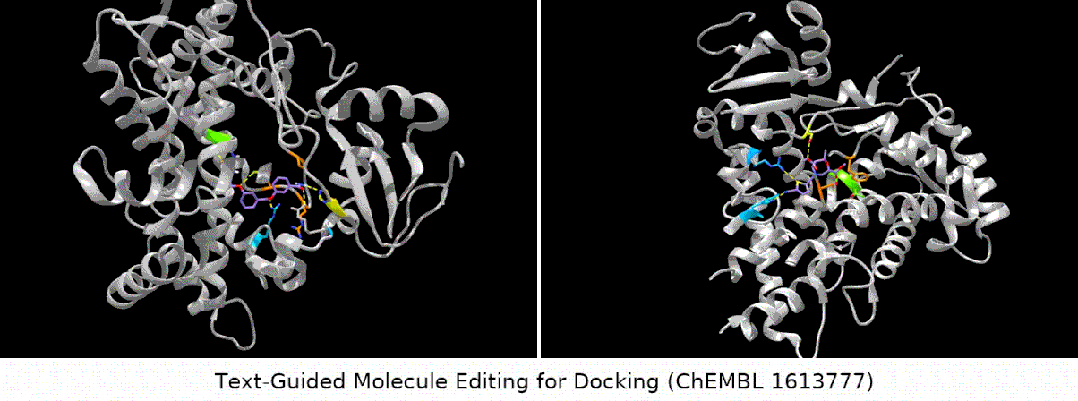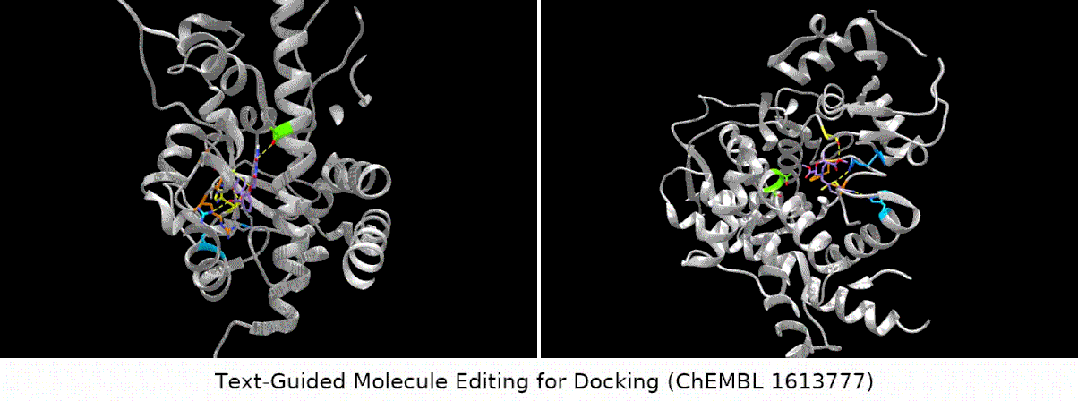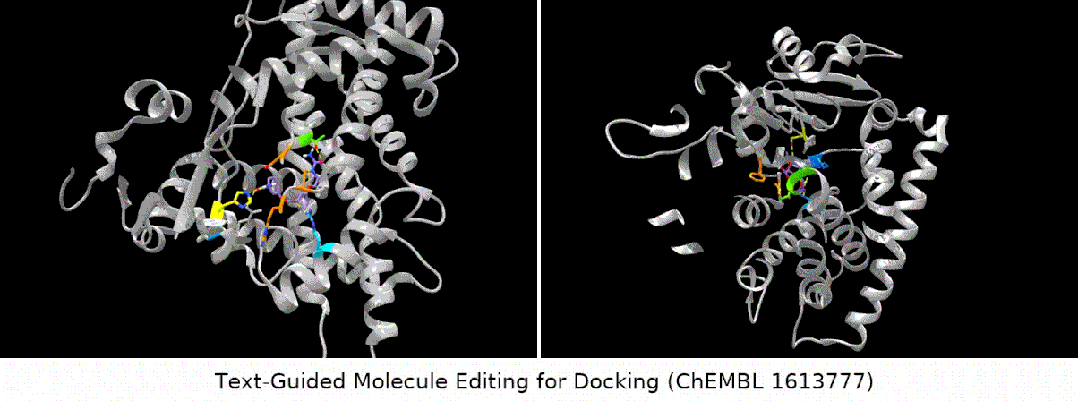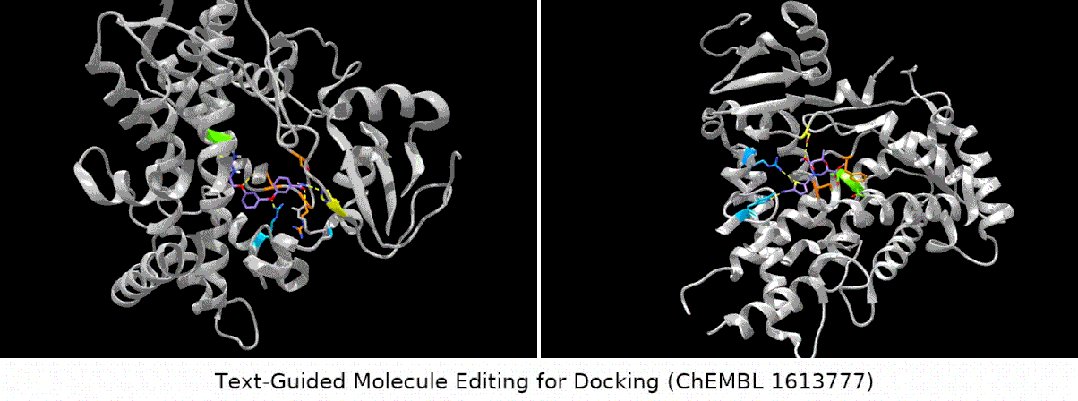 Abbildung: MoleculeSTM-Flussdiagramm.
Abbildung: MoleculeSTM-Flussdiagramm.
Und diese Ausrichtung von MoleculeSTM hat eine sehr gute Eigenschaft: Wenn es einige Aufgaben gibt, die im chemischen Raum schwer zu lösen sind, können wir sie in den natürlichen Sprachraum übertragen. Und Aufgaben in natürlicher Sprache werden aufgrund ihrer Eigenschaften relativ einfacher zu lösen sein. Auf dieser Grundlage haben wir eine Vielzahl nachgelagerter Aufgaben konzipiert, um die Wirksamkeit zu überprüfen. Im Folgenden besprechen wir einige Erkenntnisse im Detail.
Merkmale natürlicher Sprache und großer Sprachmodelle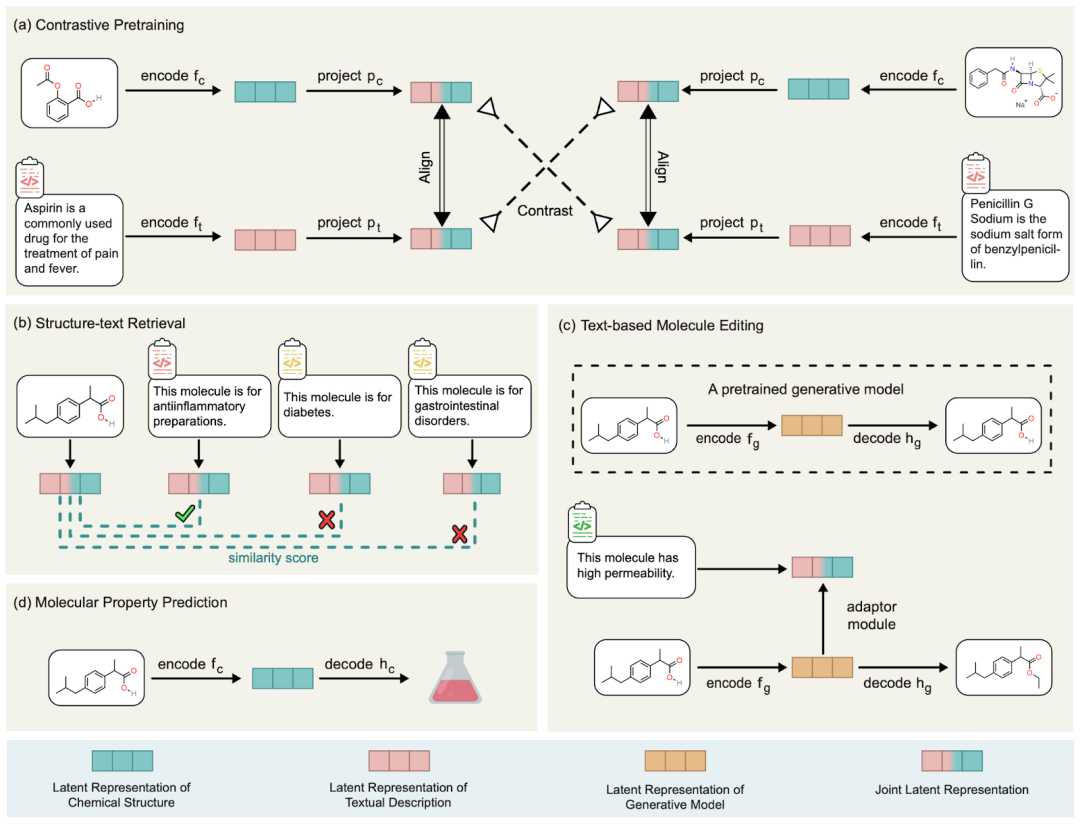
Offener Wortschatz bedeutet, dass wir das gesamte aktuelle menschliche Wissen in natürlicher Sprache ausdrücken können, sodass neues Wissen, das in der Zukunft erscheinen wird, auch in vorhandener Sprache zusammengefasst und zusammengefasst werden kann. Zusammenfassen. Wenn beispielsweise ein neues Protein auftaucht, hoffen wir, seine Funktion in natürlicher Sprache beschreiben zu können.
Kompositionalität bedeutet, dass in natürlicher Sprache ein komplexer Begriff durch mehrere einfache Begriffe gemeinsam ausgedrückt werden kann. Dies ist sehr hilfreich für Aufgaben wie die Bearbeitung mehrerer Attribute: Es ist sehr schwierig, Moleküle im chemischen Raum so zu bearbeiten, dass sie mehrere Eigenschaften gleichzeitig erfüllen, aber wir können mehrere Eigenschaften sehr einfach in natürlicher Sprache ausdrücken.
In unserer aktuellen Arbeit ChatDrug (https://arxiv.org/abs/2305.18090) haben wir die Dialogeigenschaften zwischen natürlicher Sprache und großen Sprachmodellen untersucht. Freunde, die sich dafür interessieren, können es sich ansehen
- Aufgabendesign „Durch Merkmale induziert“ bezieht sich auf die Gestaltung von Planungs- und Anordnungsaufgaben entsprechend den Merkmalen des Produkts oder Systems.
- Bei vorhandenen Sprach-Bild-Aufgaben können sie als kunstbezogene Aufgaben angesehen werden, z. B. bei der Generierung von Bildern oder Texten. Das heißt, ihre Ergebnisse sind unterschiedlich und unsicher. Bei wissenschaftlichen Entdeckungen handelt es sich jedoch um wissenschaftliche Probleme, die in der Regel zu relativ klaren Ergebnissen führen, beispielsweise zur Erzeugung kleiner Moleküle mit bestimmten Funktionen. Dies bringt größere Herausforderungen bei der Aufgabengestaltung mit sich
- Die erste Aufgabe, die wir in Betracht ziehen, besteht darin, rechnerische Simulationen durchführen und Ergebnisse erzielen zu können. Zukünftig werden Ergebnisse der Nasslaborverifizierung berücksichtigt, dies ist jedoch nicht Gegenstand der aktuellen Arbeit.
- Zweitens betrachten wir nur Probleme mit unklaren Ergebnissen. Konkrete Beispiele sind die Verbesserung der Wasserlöslichkeit oder Penetrationsfähigkeit eines bestimmten Moleküls. Manche Probleme führen zu klaren Ergebnissen, wie zum Beispiel das Hinzufügen einer bestimmten funktionellen Gruppe an einer bestimmten Position in einem Molekül. Wir glauben, dass solche Aufgaben für Arzneimittel- und Chemieexperten einfacher und unkomplizierter sind. Es kann also in Zukunft als Proof-of-Concept-Aufgabe verwendet werden, wird aber nicht zum Hauptziel der Aufgabe.
Deshalb haben wir drei große Aufgabenkategorien entwickelt:
- Zero-Shot-Strukturtext-Retrieval;
- Wir werden uns im nächsten Abschnitt auf die zweite Aufgabe konzentrieren
Diese Aufgabe besteht darin, ein Molekül und eine Beschreibung in natürlicher Sprache (z. B. zusätzliche Attribute) einzugeben Gleichzeitig ist es wünschenswert, in der Lage zu sein, komplexe sprachliche Textbeschreibungen neuer Moleküle auszugeben. Dabei handelt es sich um eine textgesteuerte Lead-Optimierung. Die spezifische Methode besteht darin, das bereits trainierte Molekülerzeugungsmodell und unser vorab trainiertes MoleculeSTM zu verwenden, um die Ausrichtung ihrer latenten Räume zu lernen, eine Latentrauminterpolation durchzuführen und dann die Zielmoleküle durch Dekodierung zu generieren. Das Prozessdiagramm ist wie folgt.
Der Inhalt, der neu geschrieben werden muss, ist: ein zweistufiges Prozessdiagramm der textgesteuerten molekularen Bearbeitung ohne Stichprobe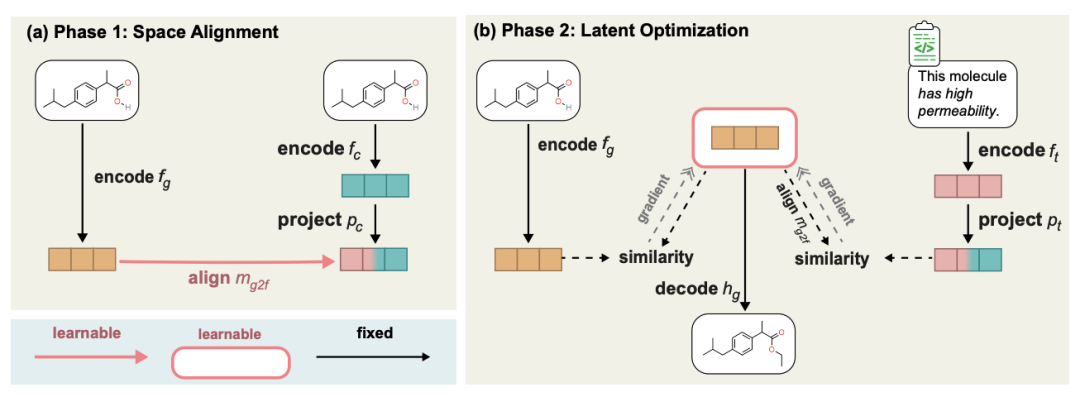 Hier zeigen wir die qualitativen Ergebnisse mehrerer Gruppen der molekularen Bearbeitung, neu formuliert wie folgt: (Die Einzelheiten zu den Ergebnissen der verbleibenden nachgelagerten Aufgaben finden Sie im Originalpapier. Wir betrachten hauptsächlich vier Arten von molekularen Bearbeitungsaufgaben:
Hier zeigen wir die qualitativen Ergebnisse mehrerer Gruppen der molekularen Bearbeitung, neu formuliert wie folgt: (Die Einzelheiten zu den Ergebnissen der verbleibenden nachgelagerten Aufgaben finden Sie im Originalpapier. Wir betrachten hauptsächlich vier Arten von molekularen Bearbeitungsaufgaben:
- Arzneimittelähnlichkeitsbearbeitung: (Anhang D.5) dient dazu, das Eingangsmolekül und das Zielmolekülarzneimittel einander näher zu bringen.
- Nachbarschaftssuche nach patentierten Arzneimitteln: Bei Arzneimitteln, die patentiert wurden, werden häufig Zwischenmedikamente zusammen gemeldet. Was wir hier tun, ist die Kombination des Zwischenwirkstoffs mit der Beschreibung in natürlicher Sprache, um zu sehen, ob daraus der endgültige Zielwirkstoff erzeugt werden kann.
- Bindungsaffinitätseditor: Wir haben mehrere ChEMBL-Assays als Ziele ausgewählt, mit dem Ziel, eine höhere Bindungsaffinität zwischen den Eingabemolekülen und den Zielen zu erreichen.
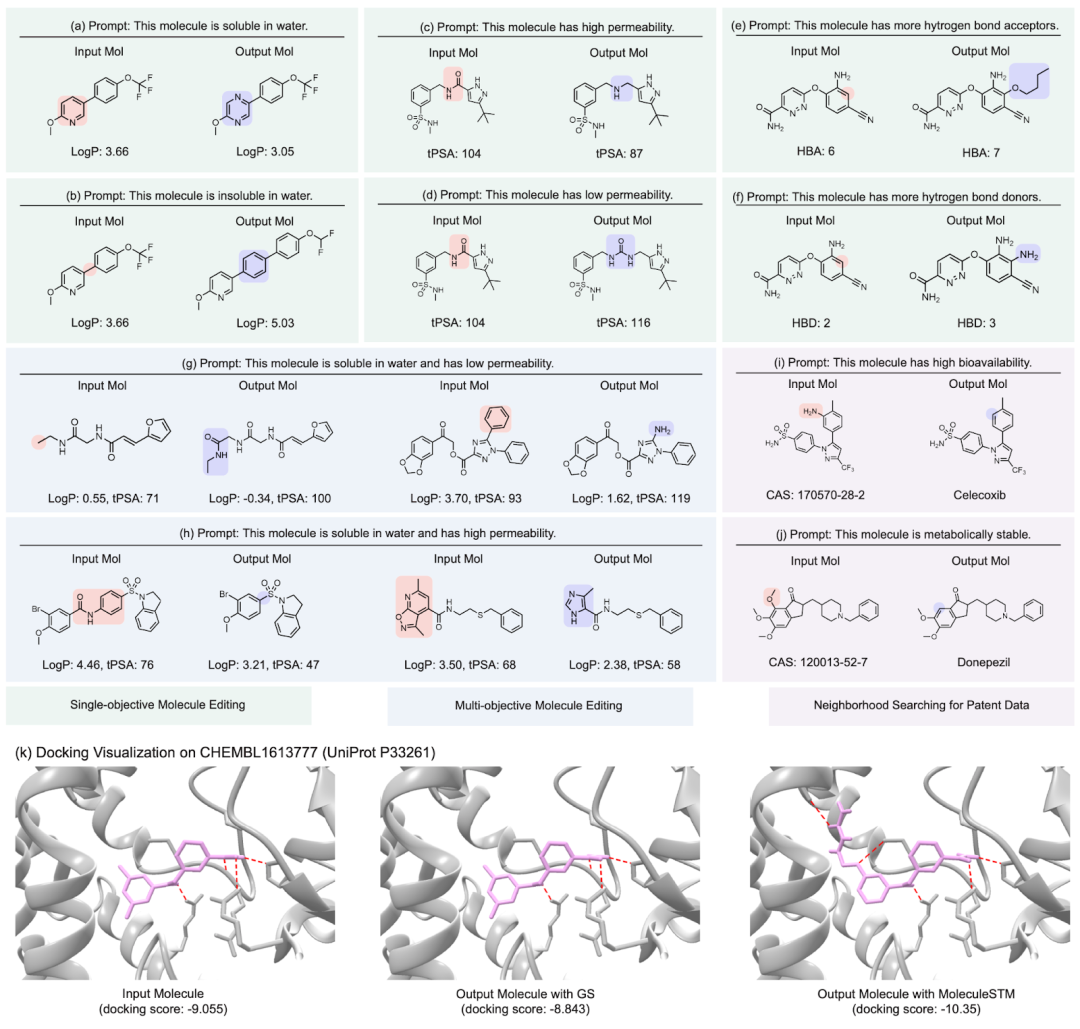 Was noch interessanter ist, ist die letzte Art von Aufgabe. Wir haben festgestellt, dass MoleculeSTM tatsächlich einen Ligandenabgleich basierend auf der Textbeschreibung der Zielproteinverbindung durchführen kann Optimierung. (Hinweis: Die Informationen zur Proteinstruktur werden hier erst nach der Auswertung bekannt.)
Was noch interessanter ist, ist die letzte Art von Aufgabe. Wir haben festgestellt, dass MoleculeSTM tatsächlich einen Ligandenabgleich basierend auf der Textbeschreibung der Zielproteinverbindung durchführen kann Optimierung. (Hinweis: Die Informationen zur Proteinstruktur werden hier erst nach der Auswertung bekannt.)
Das obige ist der detaillierte Inhalt vonNVIDIA, Mila und Caltech veröffentlichen gemeinsam ein multimodales molekulares Struktur-Text-Modell, das LLM mit der Arzneimittelforschung kombiniert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!