Heim > Artikel > Technologie-Peripheriegeräte > Meta führt ein Audio-to-Image-KI-Framework zur Generierung der Synchronisation von Charakterdialogszenen ein
Meta führt ein Audio-to-Image-KI-Framework zur Generierung der Synchronisation von Charakterdialogszenen ein

- PHPznach vorne
- 2024-01-13 11:39:06944Durchsuche
IT House News Am 9. Januar kündigte Meta kürzlich ein KI-Framework namens audio2photoreal an, das eine Reihe realistischer NPC-Charaktermodelle generieren und die Charaktermodelle mithilfe vorhandener Synchronisationsdateien automatisch „lippensynchronisieren“ kann.


▲ Bildquelle Meta-Forschungsbericht (dasselbe unten)
IT House hat aus dem offiziellen Forschungsbericht erfahren, dass das Audio2photoreal-Framework nach Erhalt der Synchronisierungsdatei zunächst eine Reihe von NPC-Modellen generiert und dann Quantisierungstechnologie und Diffusionsalgorithmus verwendet, um Modellaktionen zu generieren Diffusionsalgorithmen werden verwendet, um die vom Rahmen erzeugten Zeichenbewegungseffekte zu verbessern.
Die Forscher erwähnten, dass das Framework „hochwertige Aktionsbeispiele“ mit 30 FPS erzeugen und auch unfreiwillige „gewohnheitsmäßige Handlungen“ von Menschen wie „Fingerzeigen“, „Handgelenke drehen“ oder „Achselzucken“ während Gesprächen simulieren kann.


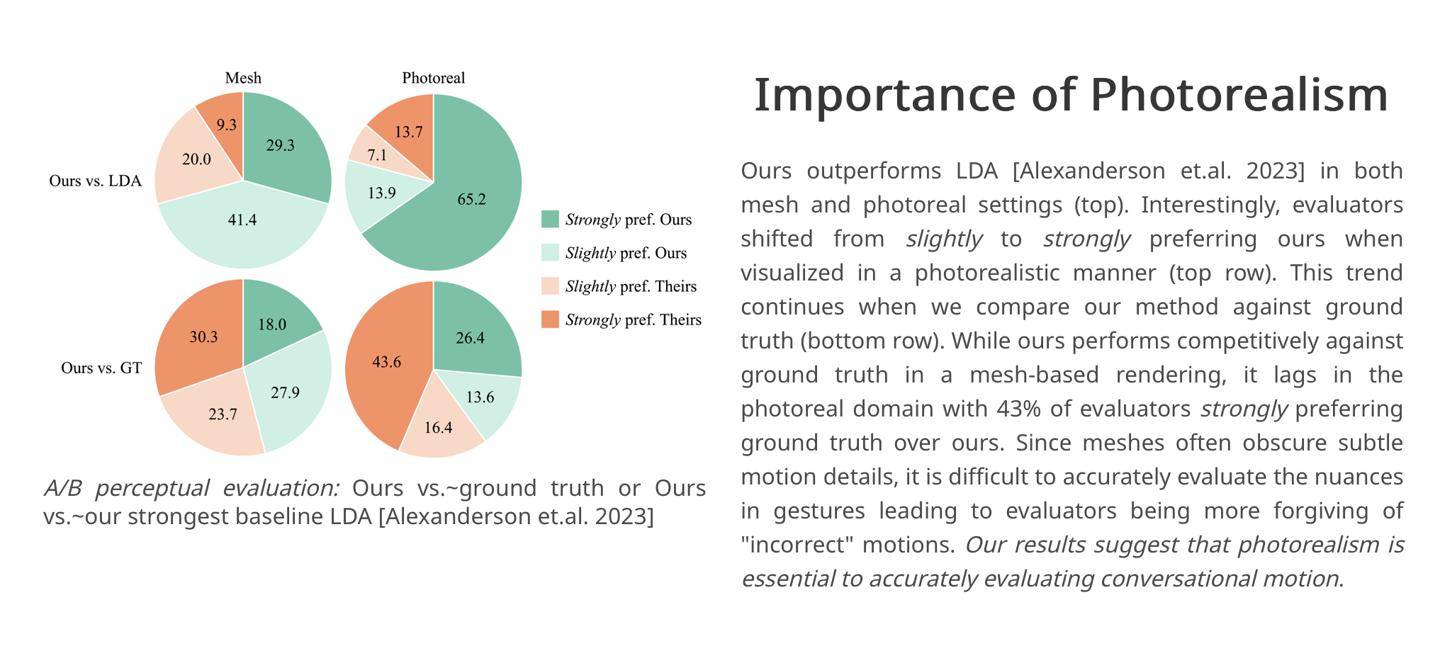
Die Forscher zitierten ihre eigenen experimentellen Ergebnisse. 43 % der Bewerter waren mit den vom Framework generierten Charakterdialogszenen „sehr zufrieden“. Daher glauben die Forscher, dass das Audio2photoreal-Framework „dynamischer und ausdrucksstärker“ sein kann „im Vergleich zu Konkurrenzprodukten in der Branche. Kraft“ Aktion.
Es wird berichtet, dass das Forschungsteam den relevanten Code und die Datensätze nun auf GitHub veröffentlicht hat. Interessierte Partner können hier darauf zugreifen.
Das obige ist der detaillierte Inhalt vonMeta führt ein Audio-to-Image-KI-Framework zur Generierung der Synchronisation von Charakterdialogszenen ein. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr