
Heim >Technologie-Peripheriegeräte >KI >2023 Telecom AI Company Summit Papers und Wettbewerbsaustausch
2023 Telecom AI Company Summit Papers und Wettbewerbsaustausch

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-11 22:18:05637Durchsuche
In den letzten Jahren hat China Telecom weiterhin hart an der Technologie der künstlichen Intelligenz gearbeitet. Am 28. November 2023 änderte die China Telecom Digital Intelligence Technology Branch offiziell ihren Namen in China Telecom Artificial Intelligence Technology Co., Ltd. (im Folgenden „Telecom AI Company“ genannt). Im Jahr 2023 gewannen Telekommunikations-KI-Unternehmen aufeinanderfolgende Auszeichnungen in 21 führenden in- und ausländischen KI-Wettbewerben, meldeten mehr als 100 Patente an und veröffentlichten mehr als 30 Artikel in führenden Konferenzen und Fachzeitschriften wie CVPR, ACM MM und ICCV, was die Leistung von demonstrierte Erste Ergebnisse im Bereich der künstlichen Intelligenz
Als professionelles Unternehmen für China Telecom zur Durchführung von Geschäften mit künstlicher Intelligenz ist Telecom AI Company ein technologiebasiertes, fähigkeitsbasiertes und plattformbasiertes Unternehmen. Das Unternehmen ist bestrebt, die Kerntechnologien der künstlichen Intelligenz zu erobern, Spitzentechnologien zu erforschen und die Erweiterung des Industrieraums zu fördern, mit dem Ziel, ein Anbieter von Dienstleistungen für künstliche Intelligenz im zweistelligen Milliardenbereich zu werden. In den letzten zwei Jahren hat die Telecom AI Company erfolgreich unabhängig eine Reihe innovativer Anwendungsergebnisse entwickelt, wie die Galaxy AI Algorithm Warehouse Empowerment Platform, die Nebula AI Level 4 Computing Power Platform und das Star Universal Basic Large Model. Mittlerweile beschäftigt das Unternehmen mehr als 800 Mitarbeiter mit einem Durchschnittsalter von 31 Jahren, von denen 80 % F&E-Personal sind und 70 % von großen in- und ausländischen Internetunternehmen sowie führenden KI-Unternehmen stammen. Um den Forschungs- und Entwicklungsfortschritt im Zeitalter großer Modelle zu beschleunigen, verfügt das Unternehmen über mehr als 2.500 Schulungskarten mit einer Rechenleistung von A100 und mehr als 300 Vollzeitmitarbeiter für die Datenannotation. Gleichzeitig kooperiert das Unternehmen auch mit wissenschaftlichen Forschungseinrichtungen wie dem Shanghai Artificial Intelligence Laboratory, der Xi'an Jiaotong University, der Beijing University of Posts and Telecommunications und dem Zhiyuan Research Institute, um gemeinsam erstklassige Technologie für künstliche Intelligenz und Technologie für China zu entwickeln 60 Millionen Videonetzwerke der Telekommunikation und Hunderte Millionen BenutzerszenarienAls nächstes werden wir einige wichtige wissenschaftliche Forschungsergebnisse überprüfen und teilen, die von Telekommunikations-KI-Unternehmen im Jahr 2023 erzielt wurden. In diesem Austausch werden die technischen Errungenschaften des CV-Algorithmus-Teams des AI R&D Center vorgestellt, das bei der ICCV 2023-Veranstaltung die Temporal Action Localization-Streckenmeisterschaft gewonnen hat. Die ICCV ist eine der drei Top-Konferenzen im Bereich der internationalen Computer Vision. Sie findet alle zwei Jahre statt und genießt in der Branche ein hohes Ansehen. In diesem Artikel werden die algorithmischen Ideen und Lösungen vorgestellt, die das Team bei dieser Herausforderung übernommen hat
ICCV 2023 Perception Test Challenge-Time Action Positioning Champion Technology Sharing

Die erste von DeepMind ins Leben gerufene ICCV 2023-Herausforderung zum Wahrnehmungstest zielt darauf ab, die Fähigkeiten des Modells in Bezug auf Video-, Audio- und Textmodalitäten zu bewerten. Der Wettbewerb umfasst vier Kompetenzbereiche, vier Argumentationstypen und sechs Rechenaufgaben, um die Fähigkeiten multimodaler Wahrnehmungsmodelle umfassend zu bewerten. Die Kernaufgabe des Temporal Action Localization Track besteht darin, ein tiefgreifendes Verständnis und eine genaue Aktionspositionierung von unbearbeiteten Videoinhalten durchzuführen. Diese Technologie ist für verschiedene Anwendungsszenarien wie autonome Fahrsysteme und Videoüberwachungsanalysen von großer Bedeutung
Bei diesem Wettbewerb besteht das teilnehmende Team aus Mitgliedern der Verkehrsalgorithmus-Abteilung des Telekommunikations-KI-Unternehmens. Das Team heißt CTCV. Telekommunikations-KI-Unternehmen haben umfangreiche Forschungen auf dem Gebiet der Computer-Vision-Technologie durchgeführt und umfangreiche Erfahrungen gesammelt. Seine technologischen Errungenschaften wurden in vielen Geschäftsfeldern wie Stadtverwaltung und Verkehrssicherheit weithin genutzt und bedienen weiterhin eine große Anzahl von Benutzern
Die Einleitung ist der Anfang eines Artikels und soll den Leser interessieren und Hintergrundinformationen liefern. Eine gute Einleitung fesselt die Aufmerksamkeit des Lesers, fasst das Thema des Artikels zusammen und inspiriert ihn zum Weiterlesen. Beim Verfassen einer Einleitung müssen Sie auf eine prägnante und klare Sprache sowie einen präzisen und aussagekräftigen Inhalt achten. Der Zweck der Einleitung besteht darin, den Leser in das Thema des Artikels einzuführen. Daher ist es notwendig, relevante Fakten, Daten oder zum Nachdenken anregende Fragen zu zitieren. Kurz gesagt: Die Einleitung ist das Tor zum Artikel und kann darüber entscheiden, ob der Leser weiterliest
Ein herausforderndes Problem beim Videoverständnis ist die Aufgabe, Aktionen in Videos zu lokalisieren und zu klassifizieren, nämlich die Temporal Action Localization (TAL)
DieTAL-Technologie hat in letzter Zeit erhebliche Fortschritte gemacht. Beispielsweise verwenden TadTR und ReAct einen Transformer-basierten Decoder ähnlich DETR zur Aktionserkennung und modellieren Aktionsinstanzen als lernbare Menge. TallFormer verwendet einen Transformer-basierten Encoder, um Videodarstellungen zu extrahieren
Obwohl die oben genannten Methoden gute Ergebnisse bei der zeitlichen Aktionslokalisierung erzielt haben, gibt es einige Einschränkungen bei der Videowahrnehmung. Um Aktionsinstanzen besser zu lokalisieren, ist eine zuverlässige Darstellung von Videofunktionen von entscheidender Bedeutung. Unser Team verwendete zunächst das VideoMAE-v2-Framework, fügte die Adapter+Linear-Schicht hinzu, trainierte ein Aktionskategorie-Vorhersagemodell mit zwei verschiedenen Backbone-Netzwerken und nutzte die vorherige Schicht der Modellklassifizierungsschicht, um Merkmale für die TAL-Aufgabe zu extrahieren. Als nächstes haben wir die TAL-Aufgabe mit dem verbesserten ActionFormer-Framework trainiert und die WBF-Methode geändert, um sie an die TAL-Aufgabe anzupassen. Am Ende erreichte unsere Methode einen mAP von 0,50 im Bewertungssatz und lag damit an erster Stelle, 3 Prozentpunkte vor dem zweitplatzierten Team und 34 Prozentpunkte höher als das Basismodell von Google DeepMind
2 Wettbewerbslösung
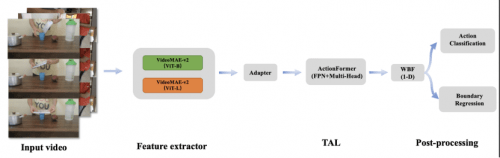 Die Algorithmusübersicht ist in der folgenden Abbildung dargestellt:
Die Algorithmusübersicht ist in der folgenden Abbildung dargestellt:
2.1 Datenverbesserung
Im Track „Temporale Aktionslokalisierung“ handelt es sich bei dem vom CTCV-Team verwendeten Datensatz um ein unbeschnittenes Video zur Aktionslokalisierung, das eine hohe Auflösung aufweist und die Merkmale mehrerer Aktionsinstanzen enthält. Bei der Analyse des Datensatzes wurde festgestellt, dass dem Trainingssatz im Vergleich zum Validierungssatz drei Kategoriebezeichnungen fehlten. Um die Angemessenheit der Modellüberprüfung sicherzustellen und die Anforderungen des Wettbewerbs zu erfüllen, sammelte das Team eine kleine Menge Videodaten und fügte sie dem Trainingsdatensatz hinzu, um die Trainingsbeispiele anzureichern. Gleichzeitig enthält jede Videovoreinstellung nur eine Aktion
, um den Anmerkungsprozess zu vereinfachenBitte beachten Sie das selbst zusammengestellte Videobeispiel in Abbildung 2
2.2 Aktionserkennung und Merkmalsextraktion
In den letzten Jahren sind viele Basismodelle entstanden, die auf umfangreichem Datentraining basieren. Diese Modelle wenden die leistungsstarken Generalisierungsfähigkeiten der Basismodelle durch Null-Proben-Erkennung, lineare Erkennung und schnelle Feinabstimmung an und andere Methoden haben den Fortschritt in vielen Aspekten der künstlichen Intelligenz effektiv gefördert
Bewegungslokalisierung und -erkennung in TAL-Spuren sind eine große Herausforderung. Beispielsweise sind die beiden Aktionen „so tun, als würde man etwas in Stücke reißen“ und „etwas in Stücke reißen“ sehr ähnlich, was zweifellos größere Herausforderungen für die Feature-Ebene mit sich bringt. Daher ist der Effekt der direkten Verwendung vorhandener vorab trainierter Modelle zum Extrahieren von Merkmalen nicht ideal
Daher hat unser Team den TAL-Datensatz durch Parsen der JSON-Annotationsdatei in einen Aktionserkennungsdatensatz umgewandelt. Anschließend verwenden wir Vit-B und Vit-L als Backbone-Netzwerke, fügen nach dem VideoMAE-v2-Netzwerk eine Adapterschicht und eine lineare Schicht zur Klassifizierung hinzu und trainieren Aktionsklassifikatoren in derselben Datendomäne. Wir entfernen auch die lineare Ebene aus dem Aktionsklassifizierungsmodell und verwenden sie für die Extraktion von Videomerkmalen. Die Merkmalsdimension des VitB-Modells beträgt 768, während die Merkmalsdimension des ViTL-Modells 1024 beträgt. Wenn wir diese beiden Features gleichzeitig verknüpfen, generieren wir ein neues Feature mit der Dimension 1792, das als Alternative zum Training des zeitlichen Aktionslokalisierungsmodells verwendet wird. In der frühen Phase des Trainings haben wir Audiofunktionen ausprobiert, aber die experimentellen Ergebnisse zeigten, dass der mAP-Index abnahm. Daher haben wir in nachfolgenden Experimenten Audiofunktionen nicht berücksichtigt
2.3 Sequentielle Aktionspositionierung
Actionformer ist ein ankerfreies Modell, das mit zeitsequentieller Aktionspositionierung entwickelt wurde. Es umfasst multiskalige Merkmale und lokale Selbstaufmerksamkeit in der zeitlichen Dimension. In diesem Wettbewerb wählte das CTCV-Team Actionformer als Benchmark-Modell für die Aktionspositionierung, das zur Vorhersage der Grenzen (Start- und Endzeiten) und Kategorien von Aktionsereignissen verwendet wird
CTCV-Team vereinheitlichte die Verarbeitung von Aktionsgrenzenregressions- und Aktionsklassifizierungsaufgaben. Bezogen auf die grundlegende Trainingsstruktur werden Videofunktionen zunächst in einen Multiskalen-Transformer codiert. Anschließend wird im Kopfzweig der Regression und Klassifizierung des Modells eine Merkmalspyramidenschicht eingeführt, um die Fähigkeit des Netzwerks zum Ausdruck von Merkmalen zu verbessern. Der Kopfzweig jedes Zeitschritts generiert einen Aktionskandidaten. Gleichzeitig werden durch die Erhöhung der Anzahl der Köpfe auf 32 und die Einführung der fpn1D-Struktur die Positionierungs- und Erkennungsfähigkeiten des Modells weiter verbessert
1-D’s 2,4 WBF
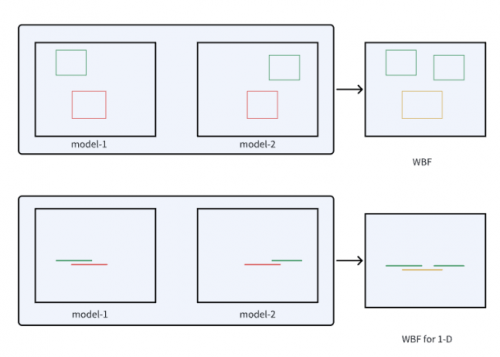
Weighted Boxes Fusion (WBF) ist eine innovative Erkennungsrahmenfusionsmethode. Diese Methode nutzt die Konfidenz aller Erkennungsrahmen, um den endgültigen Vorhersagerahmen zu erstellen, und zeigt gute Ergebnisse bei der Bildzielerkennung. Im Gegensatz zu NMS- und Soft-NMS-Methoden verwirft die gewichtete Boxfusion keine Vorhersagen, sondern verwendet die Konfidenzwerte aller vorgeschlagenen Begrenzungsboxen, um eine durchschnittliche Box zu erstellen. Diese Methode verbessert die Genauigkeit der Vorhersage von Rechtecken erheblich
Inspiriert durch WBF hat das CTCV-Team den eindimensionalen Begrenzungsrahmen einer Aktion mit einem eindimensionalen Liniensegment analogisiert und die WBF-Methode modifiziert, um sie für TAL-Aufgaben geeignet zu machen. Die experimentellen Ergebnisse zeigen die Wirksamkeit dieser Methode, wie in Abbildung 3dargestellt
3 Experimentelle Ergebnisse
3.1 Bewertungsindikatoren. Bewertungskriterien
Die Bewertungsmetrik ist mAP, die für diese Herausforderung verwendet wird. mAP wird durch Berechnung der durchschnittlichen Genauigkeit über verschiedene Aktionskategorien und IoU-Schwellenwerte bestimmt. Das CTCV-Team bewertet IoU-Schwellenwerte in Schritten von 0,1 im Bereich von 0,1 bis 0,5
3.2 Die experimentellen Details werden wie folgt umgeschrieben:
Um ein vielfältiges Modell zu erhalten, hat das CTCV-Team 80 % des Trainingsdatensatzes insgesamt fünfmal neu abgetastet. Die Funktionen von Vit-B, Vit-L und Concat wurden für das Modelltraining verwendet und 15 verschiedene Modelle wurden erfolgreich erhalten. Schließlich werden die Bewertungsergebnisse dieser Modelle in das WBF-Modul eingegeben und jedem Modellergebnis das gleiche Fusionsgewicht zugewiesen
Die experimentellen Ergebnisse sind wie folgt:
Der Leistungsvergleich verschiedener Funktionen ist in Tabelle 1 dargestellt. Die erste und zweite Zeile zeigen die Ergebnisse unter Verwendung der ViT-B- und ViT-L-Funktionen. Die dritte Zeile zeigt die Ergebnisse der ViT-B- und ViT-L-Feature-Kaskade
Während des Experiments stellte das CTCV-Team fest, dass die durchschnittliche Präzision (mAP) der Kaskadenmerkmale etwas niedriger war als bei ViT-L, aber immer noch besser als bei ViT-B. Dennoch haben wir durch die Durchführung verschiedener Methoden am Verifizierungssatz die Vorhersageergebnisse verschiedener Merkmale im Bewertungssatz mithilfe von WBF zusammengeführt, und der letztendlich an das System übermittelte mAP betrug 0,50
Der Inhalt, der neu geschrieben werden muss, ist: 4 Fazit
Das CTCV-Team hat eine Reihe von Strategien übernommen, um die Leistung in diesem Wettbewerb zu verbessern. Zunächst ergänzten sie die Trainingsdaten durch Datenerfassung um fehlende Klassen im Validierungssatz. Zweitens verwendeten sie das VideoMAE-v2-Framework, um eine Adapterebene zum Trainieren des Video-Feature-Extraktors hinzuzufügen, und trainierten die TAL-Aufgabe mithilfe des verbesserten ActionFormer-Frameworks. Darüber hinaus haben sie die WBF-Methode modifiziert, um die Testergebnisse effektiv zusammenzuführen. Am Ende erreichte das CTCV-Team im Bewertungssatz einen mAP von 0,50 und belegte damit den ersten Platz. Telekommunikations-KI-Unternehmen halten seit jeher an der Entwicklungsphilosophie fest: „Technologie kommt aus dem Geschäft und geht ins Geschäft“. Sie betrachten Wettbewerbe als wichtige Plattform zum Testen und Verbessern technischer Fähigkeiten und optimieren und verbessern technische Lösungen weiterhin durch die Teilnahme an Wettbewerben, um Kunden qualitativ hochwertigere Dienstleistungen zu bieten. Gleichzeitig bietet die Teilnahme am Wettbewerb auch wertvolle Lern- und Weiterentwicklungsmöglichkeiten für die Teammitglieder
Das obige ist der detaillierte Inhalt von2023 Telecom AI Company Summit Papers und Wettbewerbsaustausch. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr