Heim > Artikel > Technologie-Peripheriegeräte > Die neue Methode der Tsinghua-Universität findet erfolgreich präzise Videoclips! SOTA wurde übertroffen und ist Open Source
Die neue Methode der Tsinghua-Universität findet erfolgreich präzise Videoclips! SOTA wurde übertroffen und ist Open Source

- WBOYnach vorne
- 2024-01-09 15:26:221215Durchsuche
Mit nur einem Satz Beschreibung können Sie den entsprechenden Clip in einem großen Video finden!
Bei der Beschreibung von „Eine Person trinkt Wasser, während sie die Treppe hinuntergeht“ kann die neue Methode durch den Abgleich von Videobildern und Schritten sofort die entsprechenden Start- und Endzeitstempel finden:

Sogar „lachende“ Semantik Auch schwer zu verstehende Elemente können genau positioniert werden:

Die Methode heißt Adaptive Dual Branch Promotion Network (ADPN) und wurde vom Forschungsteam der Tsinghua-Universität vorgeschlagen.
Konkret wird ADPN verwendet, um eine visuell-linguistische modalübergreifende Aufgabe namens Videoclip-Positionierung (Temporal Sentence Grounding, TSG) auszuführen, bei der relevante Clips aus dem Video basierend auf dem Abfragetext lokalisiert werden sollen.
ADPN zeichnet sich durch seine Fähigkeit aus, die Konsistenz und Komplementarität von visuellen und akustischen Modalitäten in Videos effizient zu nutzen, um die Positionierungsleistung von Videoclips zu verbessern.
Im Vergleich zu anderen TSG-Arbeiten PMI-LOC und UMT, die Audio verwenden, hat die ADPN-Methode im Audiomodus deutlichere Leistungsverbesserungen erzielt und in mehreren Tests neue SOTA gewonnen.
Derzeit wurde diese Arbeit von ACM Multimedia 2023 angenommen und ist vollständig Open Source.

Werfen wir einen Blick darauf, was ADPN ist ~
Videoclips in einem Satz positionieren
Videoclip-Positionierung (Temporal Sentence Grounding, TSG) ist eine wichtige visuell-linguistische modalübergreifende Aufgabe.
Ihr Zweck besteht darin, die Start- und Endzeitstempel von Segmenten zu finden, die semantisch mit ihnen in einem unbearbeiteten Video übereinstimmen, basierend auf Abfragen in natürlicher Sprache. Dazu muss die Methode über starke zeitliche, modalübergreifende Argumentationsfähigkeiten verfügen.
Die meisten bestehenden TSG-Methoden berücksichtigen jedoch nur die visuellen Informationen im Video, wie RGB, optischer Fluss(optische Flüsse), Tiefe(Tiefe) usw., während die Audioinformationen, die das Video natürlich begleiten, ignoriert werden. .
Audioinformationen enthalten oft eine reichhaltige Semantik und sind konsistent und ergänzend zu visuellen Informationen. Wie in der Abbildung unten gezeigt, helfen diese Eigenschaften der TSG-Aufgabe.
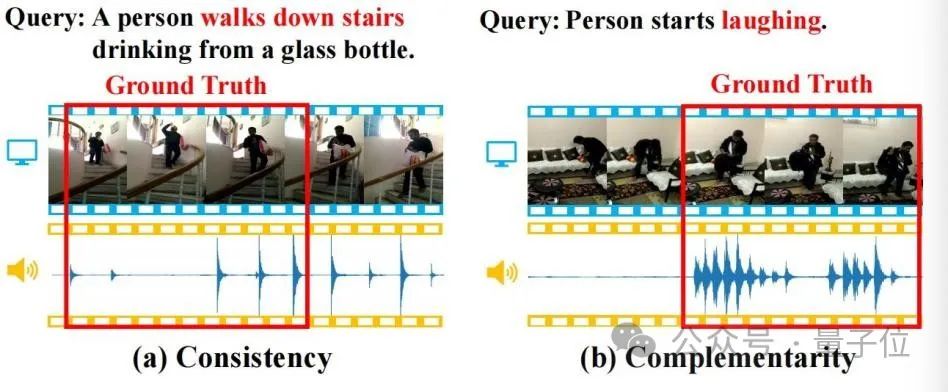
△Abbildung 1
(a) Konsistenz: Das Videobild und die Schritte stimmen durchweg mit der Semantik von „die Treppe hinunter“ in der Abfrage überein; (b) Komplementarität: Das Videobild ist schwer zu identifizieren Verhalten, um die semantische Bedeutung von „Lachen“ in der Abfrage zu lokalisieren, aber das Vorhandensein von Lachen liefert einen starken komplementären Positionierungshinweis.
Daher haben Forscher die Aufgabe der audiogestützten Videocliplokalisierung (Audio-enhanced Temporal Sentence Grounding, ATSG) eingehend untersucht, mit dem Ziel, Lokalisierungshinweise sowohl aus visuellen als auch aus akustischen Modalitäten besser zu erfassen Die Modalität bringt auch die folgenden Herausforderungen mit sich:
Die Konsistenz und Komplementarität von Audio- und visuellen Modalitäten hängen mit dem Abfragetext zusammen. Um die audiovisuelle Konsistenz und Komplementarität zu erfassen, ist daher die Modellierung der drei Modi für die zustandsbehaftete Interaktion zwischen Text, Bild und Audio erforderlich.- Es gibt erhebliche modale Unterschiede zwischen Audio und Bild. Die Informationsdichte und die Rauschintensität der beiden sind unterschiedlich, was sich auf die Leistung des audiovisuellen Lernens auswirkt.
- Um die oben genannten Herausforderungen zu lösen, schlugen Forscher eine neuartige ATSG-Methode „
“ (Adaptive Dual-branch Prompted Network, ADPN) vor. Durch ein Modellstrukturdesign mit zwei Zweigen kann diese Methode die Konsistenz und Komplementarität zwischen Audio und Bild adaptiv modellieren und modales Audiorauschen mithilfe einer Rauschunterdrückungsoptimierungsstrategie basierend auf Kurslerninterferenzen weiter eliminieren, was die Bedeutung von Audiosignalen für Video verdeutlicht Abruf.
Die Gesamtstruktur von ADPN ist in der folgenden Abbildung dargestellt:
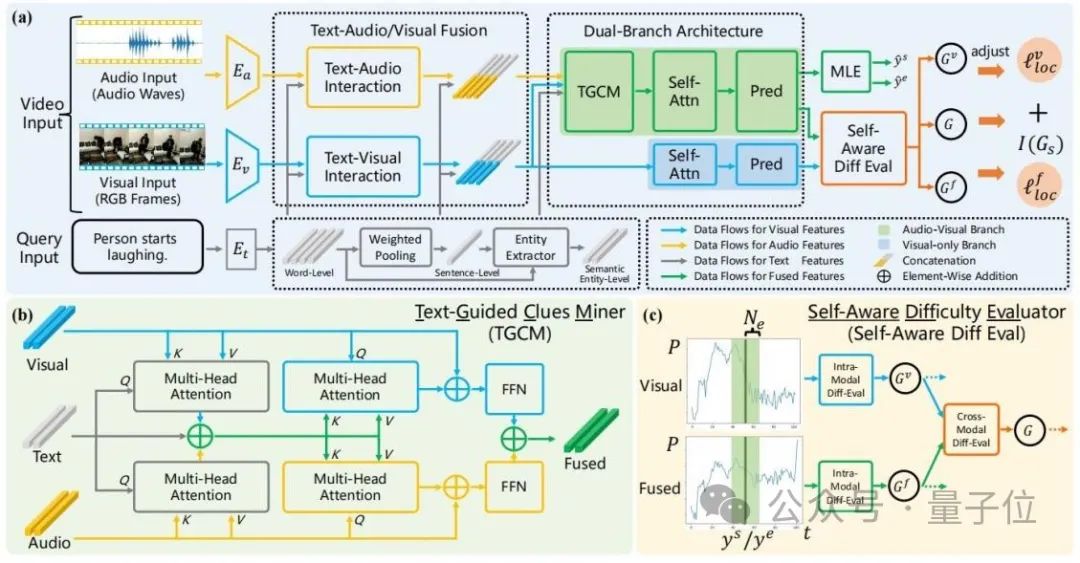 △ Abbildung 2: Gesamtschema des Adaptive Dual Branch Promotion Network (ADPN)
△ Abbildung 2: Gesamtschema des Adaptive Dual Branch Promotion Network (ADPN)
Es umfasst hauptsächlich drei Designs:
1 Design der NetzwerkstrukturAngesichts der Tatsache, dass das Rauschen von Audio offensichtlicher ist und Audio für TSG-Aufgaben normalerweise redundantere Informationen enthält, muss dem Lernprozess von Audio- und visuellen Modalitäten eine unterschiedliche Bedeutung beigemessen werden. Daher handelt es sich bei diesem Artikel um eine Dualität branch Die Netzwerkstruktur nutzt Audio und Bild für multimodales Lernen und verbessert gleichzeitig die visuellen Informationen.
Insbesondere unter Bezugnahme auf Abbildung 2(a) trainiert ADPN gleichzeitig einen Zweig (visueller Zweig) , der nur visuelle Informationen verwendet, und einen Zweig (gemeinsamer Zweig) , der sowohl visuelle Informationen als auch Audioinformationen verwendet.
Die beiden Zweige haben ähnliche Strukturen, wobei der gemeinsame Zweig eine textgesteuerte Hinweis-Mining-Einheit (TGCM) hinzufügt, um die modale Interaktion zwischen Text, Bild und Audio zu modellieren. Während des Trainingsprozesses aktualisieren die beiden Zweige gleichzeitig die Parameter, und in der Inferenzphase wird das Ergebnis des gemeinsamen Zweigs als Modellvorhersageergebnis verwendet. 2. Text-Guided Clues Miner die Interaktion zwischen den drei Modalitäten Text-Bild-Audio zu modellieren.
Siehe Abbildung 2(b), TGCM ist in zwei Schritte unterteilt: „Extraktion“ und „Vermehrung“. Zuerst wird Text als Abfragebedingung verwendet und die zugehörigen Informationen werden aus den visuellen und akustischen Modalitäten extrahiert und integriert. Anschließend werden die visuellen und akustischen Modalitäten als Abfragebedingung verwendet und die integrierten Informationen werden auf die visuellen und akustischen Modalitäten übertragen Audiomodi durch Aufmerksamkeit. Ihre jeweiligen Modalitäten werden schließlich durch FFN funktionsverschmelzt.
3. Strategie zur Optimierung des Lehrplan-LernensDie Forscher stellten fest, dass die Audiodaten Rauschen enthalten, was sich auf die Wirkung des multimodalen Lernens auswirkt. Deshalb verwendeten sie die Intensität des Rauschens als Referenz für den Schwierigkeitsgrad der Beispiele und führten das Lernen im Lehrplan ein (Curriculum Learning, CL)
Entstören Sie den Optimierungsprozess, siehe Abbildung 2(c). Sie bewerten die Schwierigkeit des Samples anhand der Differenz in der vorhergesagten Ausgabe der beiden Zweige. Sie glauben, dass ein zu schwieriges Sample mit hoher Wahrscheinlichkeit darauf hinweist, dass sein Audio zu viel Rauschen enthält und nicht für das geeignet ist TSG-Aufgabe, daher basiert der Verlust für den Trainingsprozess auf der Bewertungsbewertung der Stichprobenschwierigkeit. Die Funktionsterme werden neu gewichtet, um durch Rauschen im Audio verursachte schlechte Gradienten zu verwerfen.(Weitere Informationen zur Modellstruktur und den Trainingsdetails finden Sie im Originaltext.)
Mehrfachtests Neues SOTA
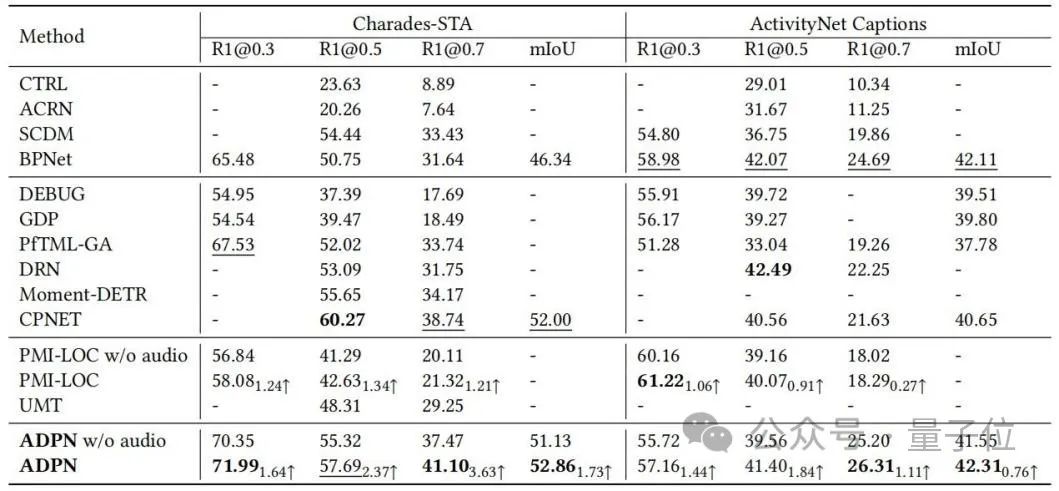
Die Forscher führten experimentelle Auswertungen an den Benchmark-Datensätzen Charades-STA und ActivityNet Captions des TSG durch Aufgabe erstellt und mit der Basismethode verglichen. Der Vergleich ist in Tabelle 1 dargestellt. Die ADPN-Methode kann eine SOTA-Leistung erzielen; im Vergleich zu anderen TSG-Arbeiten PMI-LOC und UMT, die Audio nutzen, erzielt die ADPN-Methode deutlichere Leistungsverbesserungen durch die Audiomodalität, was darauf hindeutet, dass die ADPN-Methode die Audiomodalität nutzt fördern die Überlegenheit der TSG.
△Tabelle 1: Experimentelle Ergebnisse zu Charades-STA und ActivityNet Captions
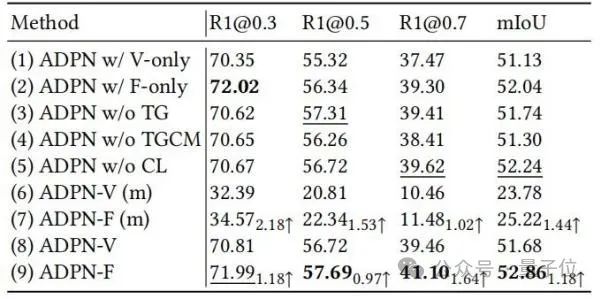
Die Forscher demonstrierten außerdem die Wirksamkeit verschiedener Designeinheiten bei ADPN durch Ablationsexperimente, wie in Tabelle 2 gezeigt.
 △Tabelle 2: Ablationsexperiment an Charades-STA
△Tabelle 2: Ablationsexperiment an Charades-STA
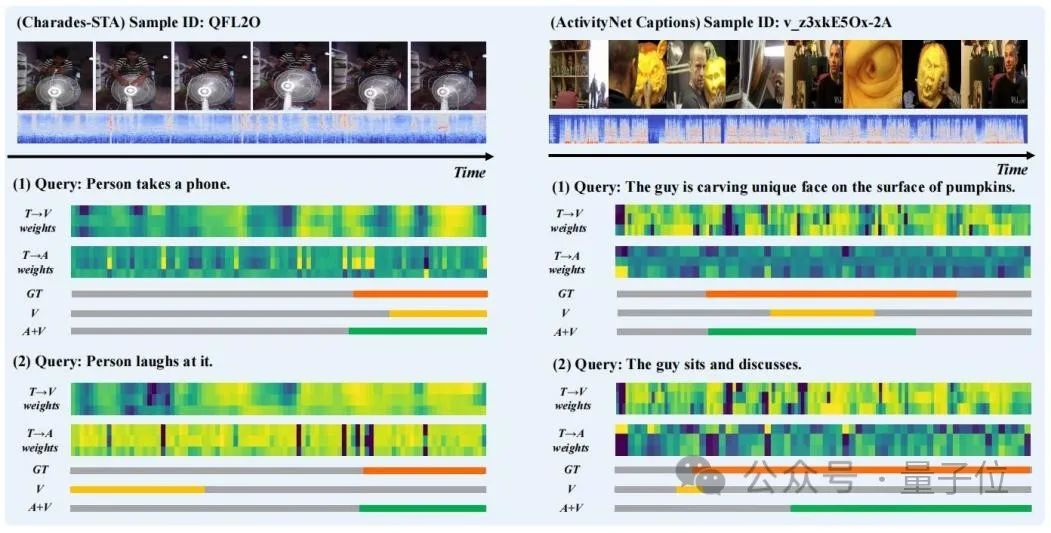
Die Forscher wählten die Vorhersageergebnisse einiger Proben zur Visualisierung aus und zeichneten den „Text zum Sehen“ (T→V) im „Extraktions“-Schritt in TGCM ) und „Text zu Audio“ (T→A) Aufmerksamkeitsgewichtsverteilung, wie in Abbildung 3 dargestellt.
Es ist zu beobachten, dass die Einführung der Audiomodalität die Vorhersageergebnisse verbessert. Aus dem Fall „Person lacht darüber“ können wir erkennen, dass die Aufmerksamkeitsgewichtsverteilung von T→A näher an der Grundwahrheit liegt, was die fehlgeleitete Führung der Modellvorhersage durch die Gewichtsverteilung von T→V korrigiert.
△ Abbildung 3: Falldarstellung
Zusammenfassend schlugen die Forscher in diesem Artikel ein neuartiges adaptives Dual-Branch-Facilitation-Netzwerk
(ADPN)vor, um die Frage der audioverstärkten Videoclip-Lokalisierung
(ATSG) zu lösen.
 Sie entwarfen eine Modellstruktur mit zwei Zweigen, um den visuellen Zweig und den audiovisuellen gemeinsamen Zweig gemeinsam zu trainieren und den Informationsunterschied zwischen Audio- und visuellen Modalitäten aufzulösen.
Sie entwarfen eine Modellstruktur mit zwei Zweigen, um den visuellen Zweig und den audiovisuellen gemeinsamen Zweig gemeinsam zu trainieren und den Informationsunterschied zwischen Audio- und visuellen Modalitäten aufzulösen.
Sie schlugen außerdem eine textgesteuerte Hinweis-Mining-Einheit
(TGCM)vor, die die Textsemantik als Leitfaden für die Modellierung der Interaktion zwischen Text und audiovisueller Kommunikation nutzt. Schließlich entwarfen die Forscher eine auf Kurslernen basierende Optimierungsstrategie, um Audiorauschen weiter zu eliminieren, die Probenschwierigkeit als Maß für die Rauschintensität auf selbstbewusste Weise zu bewerten und den Optimierungsprozess adaptiv anzupassen. Sie führten zunächst eine eingehende Untersuchung der Audioeigenschaften in ATSG durch, um den Leistungsverbesserungseffekt der Audiomodi besser zu verbessern.
In Zukunft hoffen sie, einen geeigneteren Bewertungsmaßstab für ATSG zu erstellen, um tiefergehende Forschung in diesem Bereich zu fördern.
Papier-Link: https://dl.acm.org/doi/pdf/10.1145/3581783.3612504
Lager-Link: https://github.com/hlchen23/ADPN-MM
Das obige ist der detaillierte Inhalt vonDie neue Methode der Tsinghua-Universität findet erfolgreich präzise Videoclips! SOTA wurde übertroffen und ist Open Source. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So fügen Sie mithilfe von HTML5 ein automatisch abspielendes Video in eine Seite ein
- Wie kann das Problem gelöst werden, dass die Attributleiste oben in der KI fehlt?
- Mit welcher Software können AI-Dateien geöffnet und bearbeitet werden?
- Was ist die Kurzvideo-App-Software?
- Warum kann ich auf Douyin keine Videos herunterladen und speichern?