
Heim >System-Tutorial >LINUX >Installieren Sie Apache Hadoop auf CentOS!
Installieren Sie Apache Hadoop auf CentOS!

- PHPznach vorne
- 2024-01-07 09:14:191045Durchsuche
| Einführung | Die Apache Hadoop-Softwarebibliothek ist ein Framework, das die verteilte Verarbeitung großer Datenmengen auf einem Computercluster mithilfe eines einfachen Programmiermodells ermöglicht. Apache™ Hadoop® ist Open-Source-Software für zuverlässiges, skalierbares, verteiltes Computing. |
Das Projekt umfasst folgende Module:
- Hadoop Common: Gemeinsame Tools, die andere Hadoop-Module unterstützen.
- Hadoop Distributed File System (HDFS™): Ein verteiltes Dateisystem, das Zugriffsunterstützung mit hohem Durchsatz auf Anwendungsdaten bietet.
- Hadoop YARN: Jobplanungs- und Clusterressourcenmanagement-Framework.
- Hadoop MapReduce: Ein YARN-basiertes Parallelverarbeitungssystem für große Datenmengen.
Dieser Artikel hilft Ihnen Schritt für Schritt bei der Installation von Hadoop unter CentOS und der Konfiguration eines Einzelknoten-Hadoop-Clusters.
Java installierenBevor Sie Hadoop installieren, stellen Sie bitte sicher, dass Java auf Ihrem System installiert ist. Verwenden Sie diesen Befehl, um die installierte Java-Version zu überprüfen.
java -version java version "1.7.0_75" Java(TM) SE Runtime Environment (build 1.7.0_75-b13) Java HotSpot(TM) 64-Bit Server VM (build 24.75-b04, mixed mode)
Um Java zu installieren oder zu aktualisieren, befolgen Sie bitte die nachstehenden Schritt-für-Schritt-Anweisungen.
Der erste Schritt besteht darin, die neueste Java-Version von der offiziellen Oracle-Website herunterzuladen.
cd /opt/ wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/7u79-b15/jdk-7u79-linux-x64.tar.gz" tar xzf jdk-7u79-linux-x64.tar.gz
Erfordert Setup, um alternativ eine neuere Version von Java zu verwenden. Verwenden Sie dazu den folgenden Befehl.
cd /opt/jdk1.7.0_79/ alternatives --install /usr/bin/java java /opt/jdk1.7.0_79/bin/java 2 alternatives --config java There are 3 programs which provide 'java'. Selection Command ----------------------------------------------- * 1 /opt/jdk1.7.0_60/bin/java + 2 /opt/jdk1.7.0_72/bin/java 3 /opt/jdk1.7.0_79/bin/java Enter to keep the current selection[+], or type selection number: 3 [Press Enter]
Jetzt müssen Sie möglicherweise auch den Befehl alternatives verwenden, um die Befehlspfade javac und jar festzulegen.
alternatives --install /usr/bin/jar jar /opt/jdk1.7.0_79/bin/jar 2 alternatives --install /usr/bin/javac javac /opt/jdk1.7.0_79/bin/javac 2 alternatives --set jar /opt/jdk1.7.0_79/bin/jar alternatives --set javac /opt/jdk1.7.0_79/bin/javac
Der nächste Schritt besteht darin, die Umgebungsvariablen zu konfigurieren. Verwenden Sie die folgenden Befehle, um diese Variablen korrekt festzulegen.
Java_HOME-Variable festlegen:
export JAVA_HOME=/opt/jdk1.7.0_79
JRE_HOME-Variable festlegen:
export JRE_HOME=/opt/jdk1.7.0_79/jre
PATH-Variable festlegen:
export PATH=$PATH:/opt/jdk1.7.0_79/bin:/opt/jdk1.7.0_79/jre/binInstallieren Sie Apache Hadoop
Nach dem Einrichten der Java-Umgebung. Beginnen Sie mit der Installation von Apache Hadoop.
Der erste Schritt besteht darin, ein Systembenutzerkonto für die Hadoop-Installation zu erstellen.
useradd hadoop passwd hadoop
Jetzt müssen Sie den SSH-Schlüssel für den Benutzer hadoop konfigurieren. Verwenden Sie den folgenden Befehl, um die passwortlose SSH-Anmeldung zu aktivieren.
su - hadoop ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys exit
Laden Sie jetzt die neueste verfügbare Version von Hadoop von der offiziellen Website hadoop.apache.org herunter.
cd ~ wget http://apache.claz.org/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz tar xzf hadoop-2.6.0.tar.gz mv hadoop-2.6.0 hadoop
Der nächste Schritt besteht darin, die von Hadoop verwendeten Umgebungsvariablen festzulegen.
Bearbeiten Sie ~/.bashrc und fügen Sie die folgenden Werte am Ende der Datei hinzu.
export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Übernehmen Sie Änderungen in der aktuellen Betriebsumgebung.
source ~/.bashrc
Bearbeiten Sie $HADOOP_HOME/etc/hadoop/hadoop-env.sh und legen Sie die Umgebungsvariable JAVA_HOME fest.
export JAVA_HOME=/opt/jdk1.7.0_79/
Jetzt beginnen wir mit der Konfiguration eines einfachen Hadoop-Einzelknoten-Clusters.
Bearbeiten Sie zunächst die Hadoop-Konfigurationsdatei und nehmen Sie die folgenden Änderungen vor.
cd /home/hadoop/hadoop/etc/hadoop
Bearbeiten wir core-site.xml.
fs.default.name hdfs://localhost:9000
Dann bearbeiten Sie hdfs-site.xml:
dfs.replication 1 dfs.name.dir file:///home/hadoop/hadoopdata/hdfs/namenode dfs.data.dir file:///home/hadoop/hadoopdata/hdfs/datanode
und bearbeiten Sie mapred-site.xml:
mapreduce.framework.name yarn
Letzte Bearbeitung Yarn-Site.xml:
yarn.nodemanager.aux-services mapreduce_shuffle
Formatieren Sie nun den Namensknoten mit dem folgenden Befehl:
hdfs namenode -format
Um alle Hadoop-Dienste zu starten, verwenden Sie den folgenden Befehl:
cd /home/hadoop/hadoop/sbin/ start-dfs.sh start-yarn.sh
Um zu überprüfen, ob alle Dienste normal starten, verwenden Sie den jps-Befehl:
jps
Sie sollten eine Ausgabe wie diese sehen.
26049 SecondaryNameNode 25929 DataNode 26399 Jps 26129 JobTracker 26249 TaskTracker 25807 NameNode
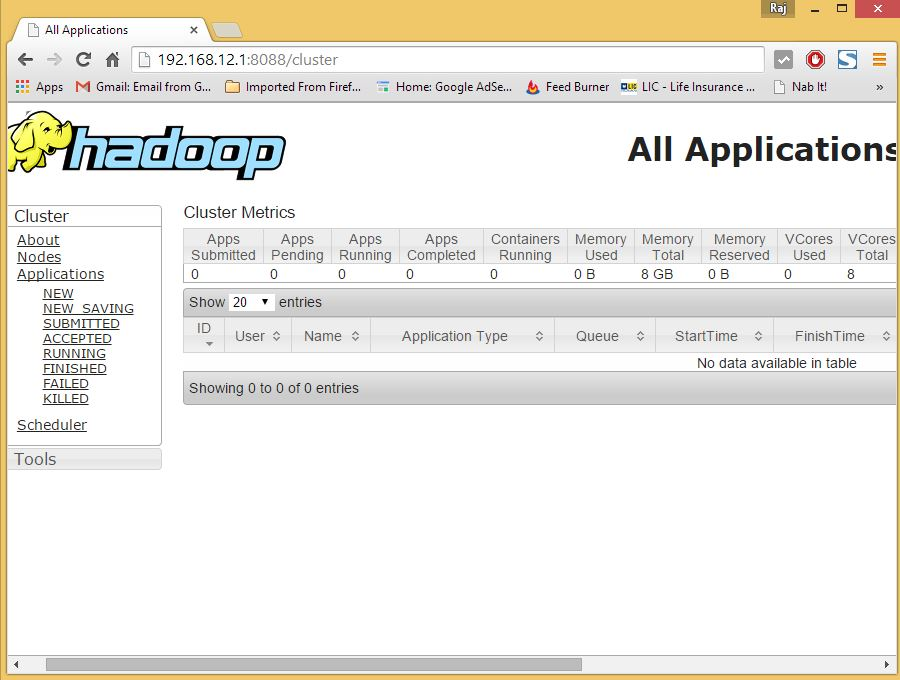
Jetzt können Sie in Ihrem Browser auf den Hadoop-Dienst zugreifen: http://Ihre-IP-Adresse:8088/.
hadoop
Das obige ist der detaillierte Inhalt vonInstallieren Sie Apache Hadoop auf CentOS!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Einführung in die Python-Implementierung der Linux-Befehlsfunktion xxd -i
- So fügen Sie MySQL zum Red Hat-System hinzu
- So führen Sie eine .sh-Datei unter einem Linux-System aus
- So ändern Sie die IP-Adresse unter Linux
- So lösen Sie das Problem, dass Red Hat Linux 6.5 nach der Installation nicht gestartet werden kann