
Heim >System-Tutorial >LINUX >Erfahren Sie, wie Sie die integrierten AWK-Variablen in Linux verwenden
Erfahren Sie, wie Sie die integrierten AWK-Variablen in Linux verwenden

- PHPznach vorne
- 2024-01-06 16:22:06571Durchsuche
| Einführung | Wir werden die Funktionen von awk schrittweise entmystifizieren. In diesem Abschnitt stellen wir das Konzept der integrierten Variablen in awk vor. Es gibt zwei Arten von Variablen, die Sie in awk verwenden können: benutzerdefinierte Variablen und integrierte Variablen. |

Wir werden die Fähigkeiten von awk nach und nach entmystifizieren. In diesem Abschnitt stellen wir das Konzept der integrierten Variablen von awk vor. Es gibt zwei Arten von Variablen, die Sie in awk verwenden können: benutzerdefinierte Variablen und integrierte Variablen. Die integrierten Variablen von awk verfügen bereits über vordefinierte Werte, wir können diese Werte jedoch auch sorgfältig ändern.
Zu den integrierten awk-Variablen gehören:- DATEINAME: Aktueller Eingabedateiname
- NR: Aktuelle Eingabezeilennummer (bezogen auf Eingabezeile 1, 2, 3 usw.)
- NF: Feldnummer der aktuellen Eingabezeile
- OFS: Ausgabefeldtrennzeichen
- FS: Eingabefeldtrennzeichen
- ORS: Ausgabedatensatztrennzeichen
- RS: Trennzeichen für Eingabedatensätze
Lassen Sie uns weiterhin einige Methoden zur Verwendung der oben genannten integrierten awk-Variablen demonstrieren. Um den Namen der aktuellen Eingabedatei zu lesen, können Sie die integrierte Variable FILENAME wie folgt verwenden: $ awk ' { print FILENAME } '. ~/domains.txt
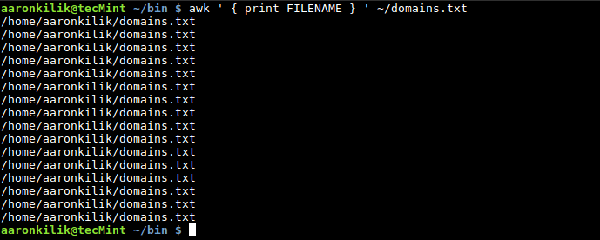
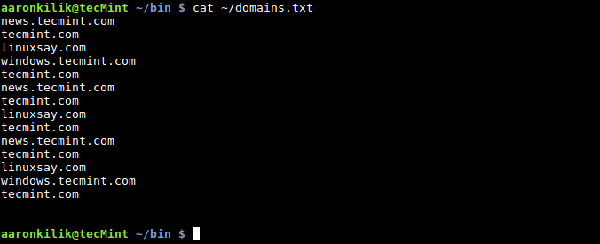
Sie werden sehen, dass jede Zeile den Dateinamen einmal ausgibt. Dies ist das Standardverhalten von awk, wenn Sie die integrierte Variable FILENAME verwenden. Wir können NR verwenden, um die Anzahl der Zeilen (Datensätze) in einer Eingabedatei zu zählen. Denken Sie daran: Es zählt auch leere Zeilen, wie wir im folgenden Beispiel sehen werden. Inhalt der Ausgabedatei Wenn wir den Befehl cat verwenden, um die Datei domains.txt anzuzeigen, werden wir feststellen, dass sie 14 Textzeilen und 2 Leerzeilen enthält: $ cat ~/domains.txt
$ awk ' END { print "Number of records in file is: ", NR } ' ~/domains.txt

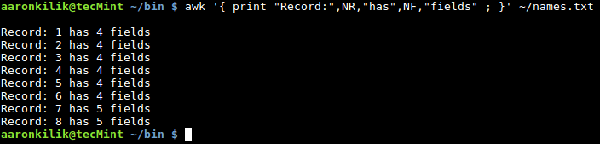
$ awk '{ "Record:",NR,"has",NF,"fields" ; }' ~/names.txt
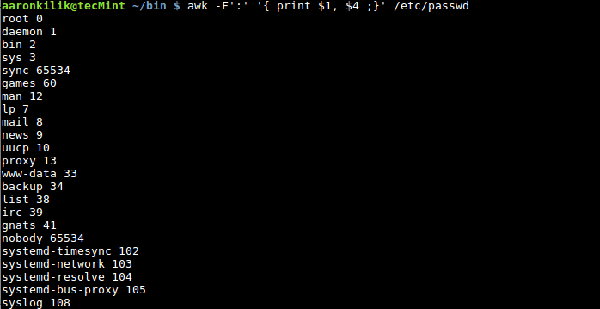
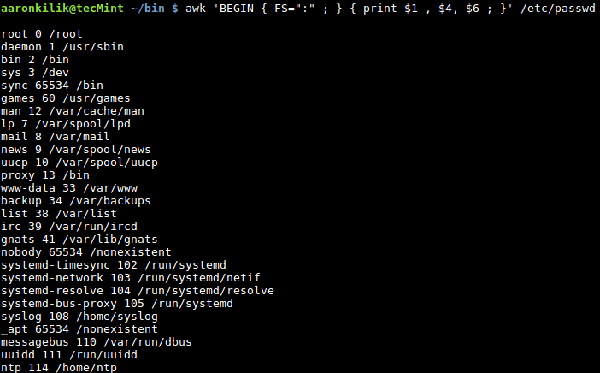
Sie können auch ein Trennzeichen für die Eingabedatei mithilfe der integrierten FS-Variablen angeben, die definiert, wie awk Eingabezeilen in Felder unterteilt. Der Standardwert von FS ist „Leerzeichen“ und „Tab“, aber wir können den FS-Wert auch in ein beliebiges Zeichen ändern, damit awk die Eingabezeile je nach Situation aufteilen kann. Es gibt zwei Möglichkeiten, dies zu erreichen: Die erste besteht darin, die integrierten FS-Variablen zu verwenden, die zweite darin, die Option -F von awk zu verwenden. Schauen wir uns die Datei /etc/passwd auf dem Linux-System an. Jedes Feld in der Datei ist durch einen Doppelpunkt (:) getrennt. Wenn wir daher bestimmte Felder herausfiltern möchten, können wir den Doppelpunkt (:) als neu angeben Feldtrennzeichen und awk filtern jedes Feld in der Passwortdatei. Wir können die Option -F wie folgt verwenden: $ awk -F':' '{ print $1, $4 ;}' /etc/passwd
Darüber hinaus können wir auch die integrierten FS-Variablen wie folgt verwenden: $ awk ' BEGIN { FS=":" } { print $1, $4 } ' /etc/passwd
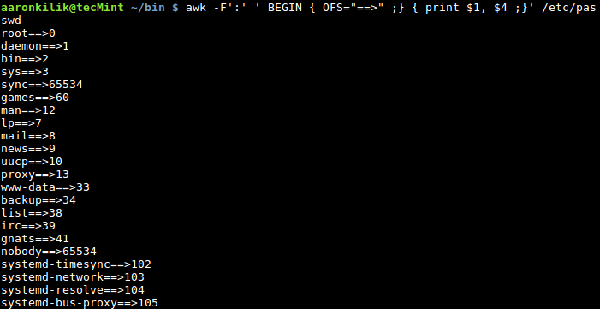
Verwenden Sie die integrierte OFS-Variable, um ein Feldtrennzeichen für die Ausgabe anzugeben, das definiert, wie das angegebene Zeichen zum Trennen der Ausgabefelder verwendet wird. Verwenden Sie das Trennzeichen für die awk-Ausgabe: $ awk -F':' ' BEGIN { OFS ="= =>" ;} { print $1, $4 ;}' /etc/passwd
In diesem Abschnitt haben wir die Idee kennengelernt, integrierte awk-Variablen mit vordefinierten Werten zu verwenden. Wir können diese Werte aber auch ändern, obwohl dies nicht empfohlen wird, es sei denn, Sie wissen, was Sie tun, und verstehen (diese Variablenwerte) vollständig.
Danach werden wir weiterhin lernen, wie man Shell-Variablen in awk-Befehlsoperationen verwendet, also bleiben Sie bitte mit uns auf dem Laufenden.
Das obige ist der detaillierte Inhalt vonErfahren Sie, wie Sie die integrierten AWK-Variablen in Linux verwenden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!