
Heim >Technologie-Peripheriegeräte >KI >Verbessern Sie die wichtigsten Punkte von Pytorch und verbessern Sie den Optimierer!
Verbessern Sie die wichtigsten Punkte von Pytorch und verbessern Sie den Optimierer!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-05 13:22:011316Durchsuche
Hallo, ich bin Xiaozhuang!
Heute sprechen wir über den Optimierer in Pytorch.
Die Wahl des Optimierers hat einen direkten Einfluss auf den Trainingseffekt und die Geschwindigkeit des Deep-Learning-Modells. Verschiedene Optimierer sind für unterschiedliche Probleme geeignet und ihre Leistungsunterschiede können dazu führen, dass das Modell schneller und stabiler konvergiert oder bei einer bestimmten Aufgabe eine bessere Leistung erbringt. Daher müssen bei der Auswahl eines Optimierers Kompromisse und Entscheidungen getroffen werden, die auf den Merkmalen des spezifischen Problems basieren.
Daher ist die Wahl des richtigen Optimierers entscheidend für die Optimierung von Deep-Learning-Modellen. Die Wahl des Optimierers hat nicht nur einen erheblichen Einfluss auf die Leistung des Modells, sondern auch auf die Effizienz des Trainingsprozesses.
PyTorch bietet eine Vielzahl von Optimierern, mit denen neuronale Netze trainiert und Modellgewichte aktualisiert werden können. Zu diesen Optimierern gehören die gängigen Modelle SGD, Adam, RMSprop usw. Jeder Optimierer hat seine einzigartigen Eigenschaften und anwendbaren Szenarien. Die Auswahl eines geeigneten Optimierers kann die Modellkonvergenz beschleunigen und die Trainingsergebnisse verbessern. Wenn Sie den Optimierer verwenden, müssen Sie Hyperparameter wie Lernrate und Gewichtsabfall festlegen sowie Verlustfunktionen und Modellparameter definieren.

Gemeinsame Optimierer
Lassen Sie uns zunächst einige häufig verwendete Optimierer in PyTorch auflisten und ihnen eine kurze Einführung geben:
Lassen Sie uns verstehen, wie SGD (stochastischer Gradientenabstieg) funktioniert. SGD ist ein häufig verwendeter Optimierungsalgorithmus zur Lösung der Parameter von Modellen für maschinelles Lernen. Es schätzt den Gradienten durch zufällige Auswahl einer kleinen Menge von Proben und verwendet die negative Richtung des Gradienten, um die Parameter zu aktualisieren. Dadurch kann die Leistung des Modells während eines iterativen Prozesses schrittweise optimiert werden. Der Vorteil von SGD ist die hohe Recheneffizienz, die besonders für
Der stochastische Gradientenabstieg ist ein häufig verwendeter Optimierungsalgorithmus zur Minimierung der Verlustfunktion. Dabei wird der Gradient der Gewichte relativ zur Verlustfunktion berechnet und die Gewichte in negativer Richtung des Gradienten aktualisiert. Dieser Algorithmus wird häufig beim maschinellen Lernen und Deep Learning verwendet.
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
(2) Adam
Adam ist ein adaptiver Algorithmus zur Optimierung der Lernrate, der die Ideen von AdaGrad und RMSProp kombiniert. Im Vergleich zum herkömmlichen Gradientenabstiegsalgorithmus kann Adam für jeden Parameter unterschiedliche Lernraten berechnen, um sich besser an die Eigenschaften verschiedener Parameter anzupassen. Durch die adaptive Anpassung der Lernrate kann Adam die Konvergenzgeschwindigkeit und Leistung des Modells verbessern.
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
(3) Adagrad
Adagrad ist ein adaptiver Lernratenoptimierungsalgorithmus, der die Lernrate basierend auf dem historischen Gradienten der Parameter anpasst. Wenn die Lerngeschwindigkeit jedoch allmählich abnimmt, kann es sein, dass das Training vorzeitig abbricht.
optimizer = torch.optim.Adagrad(model.parameters(), lr=learning_rate)
(4) RMSProp
RMSProp ist auch ein adaptiver Lernratenalgorithmus, der die Lernrate unter Berücksichtigung des gleitenden Durchschnitts des Gradienten anpasst.
optimizer = torch.optim.RMSprop(model.parameters(), lr=learning_rate)
(5) Adadelta
Adadelta ist ein adaptiver Lernratenoptimierungsalgorithmus und eine verbesserte Version von RMSProp, der die Lernrate dynamisch anpasst, indem er den gleitenden Durchschnitt des Gradienten und den gleitenden Durchschnitt der Parameter berücksichtigt.
optimizer = torch.optim.Adadelta(model.parameters(), lr=learning_rate)
Ein vollständiger Fall
Lassen Sie uns hier darüber sprechen, wie Sie mit PyTorch ein einfaches Convolutional Neural Network (CNN) für die handschriftliche Ziffernerkennung trainieren.
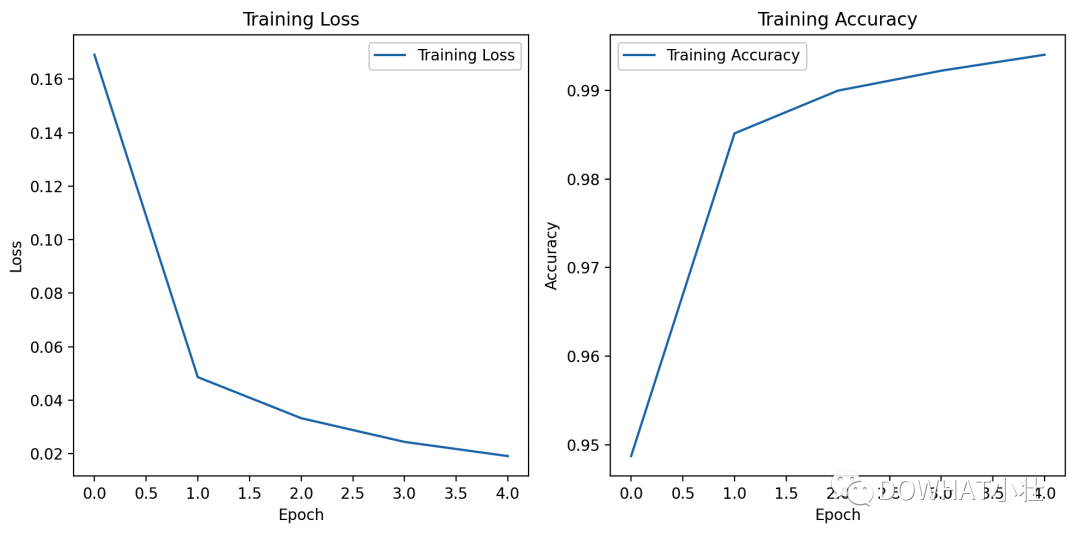
In diesem Fall werden der MNIST-Datensatz und die Matplotlib-Bibliothek verwendet, um die Verlustkurve und die Genauigkeitskurve zu zeichnen.
import torchimport torch.nn as nnimport torch.optim as optimfrom torchvision import datasets, transformsfrom torch.utils.data import DataLoaderimport matplotlib.pyplot as plt# 设置随机种子torch.manual_seed(42)# 定义数据转换transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])# 下载和加载MNIST数据集train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)# 定义简单的卷积神经网络模型class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)self.relu = nn.ReLU()self.pool = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)self.fc1 = nn.Linear(64 * 7 * 7, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.conv1(x)x = self.relu(x)x = self.pool(x)x = self.conv2(x)x = self.relu(x)x = self.pool(x)x = x.view(-1, 64 * 7 * 7)x = self.fc1(x)x = self.relu(x)x = self.fc2(x)return x# 创建模型、损失函数和优化器model = CNN()criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型num_epochs = 5train_losses = []train_accuracies = []for epoch in range(num_epochs):model.train()total_loss = 0.0correct = 0total = 0for inputs, labels in train_loader:optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()total_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = correct / totaltrain_losses.append(total_loss / len(train_loader))train_accuracies.append(accuracy)print(f"Epoch {epoch+1}/{num_epochs}, Loss: {train_losses[-1]:.4f}, Accuracy: {accuracy:.4f}")# 绘制损失曲线和准确率曲线plt.figure(figsize=(10, 5))plt.subplot(1, 2, 1)plt.plot(train_losses, label='Training Loss')plt.title('Training Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.subplot(1, 2, 2)plt.plot(train_accuracies, label='Training Accuracy')plt.title('Training Accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()plt.tight_layout()plt.show()# 在测试集上评估模型model.eval()correct = 0total = 0with torch.no_grad():for inputs, labels in test_loader:outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = correct / totalprint(f"Accuracy on test set: {accuracy * 100:.2f}%")
Im obigen Code definieren wir ein einfaches Faltungs-Neuronales Netzwerk (CNN), das mithilfe von Kreuzentropieverlust und Adam-Optimierer trainiert wird.
Während des Trainingsprozesses haben wir den Verlust und die Genauigkeit jeder Epoche aufgezeichnet und mithilfe der Matplotlib-Bibliothek die Verlustkurve und die Genauigkeitskurve gezeichnet.
Ich bin Xiao Zhuang, bis zum nächsten Mal!
Das obige ist der detaillierte Inhalt vonVerbessern Sie die wichtigsten Punkte von Pytorch und verbessern Sie den Optimierer!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierte Erläuterung des PyTorch-Batch-Trainings und des Optimierervergleichs
- Detailliertes Beispiel einer Tensordatenstruktur in Pytorch
- Codebeispiel für die Wissensdestillation mit PyTorch
- Basierend auf PyTorch ist die benutzerfreundliche, feinkörnige Bilderkennungs-Deep-Learning-Tool-Bibliothek Hawkeye Open Source
- So verwenden Sie PyTorch für das Training neuronaler Netzwerke