
Heim >Technologie-Peripheriegeräte >KI >Großformatige Modelle können Bilder bereits mit nur einer einfachen Konversation mit Anmerkungen versehen! Forschungsergebnisse von Tsinghua & NUS
Großformatige Modelle können Bilder bereits mit nur einer einfachen Konversation mit Anmerkungen versehen! Forschungsergebnisse von Tsinghua & NUS

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-05 12:56:09749Durchsuche
Nachdem das multimodale große Modell das Erkennungs- und Segmentierungsmodul integriert hat, wird das Ausschneiden von Bildern einfacher!
Unser Modell kann die gesuchten Objekte durch Beschreibungen in natürlicher Sprache schnell kennzeichnen und Texterklärungen bereitstellen, um Ihnen die einfache Erledigung der Aufgabe zu erleichtern.
Das neue multimodale große Modell, das vom NExT++-Labor der National University of Singapore und dem Team von Liu Zhiyuan an der Tsinghua-Universität entwickelt wurde, bietet uns starke Unterstützung. Dieses Modell wurde sorgfältig ausgearbeitet, um den Spielern beim Lösen von Rätseln umfassende Hilfe und Anleitung zu bieten. Es kombiniert Informationen aus mehreren Modalitäten, um den Spielern neue Methoden und Strategien zum Lösen von Rätseln zu präsentieren. Die Anwendung dieses Modells wird den Spielern zugute kommen

Mit der Einführung von GPT-4v hat der multimodale Bereich eine Reihe neuer Modelle wie LLaVA, BLIP-2 usw. eingeführt. Die Entstehung dieser Modelle hat einen großen Beitrag zur Verbesserung der Leistung und Effektivität multimodaler Aufgaben geleistet.
Um die regionalen Verständnisfähigkeiten multimodaler Großmodelle weiter zu verbessern, entwickelte das Forschungsteam ein multimodales Modell namens NExT-Chat. Dieses Modell ist in der Lage, gleichzeitig Dialog, Erkennung und Segmentierung durchzuführen.
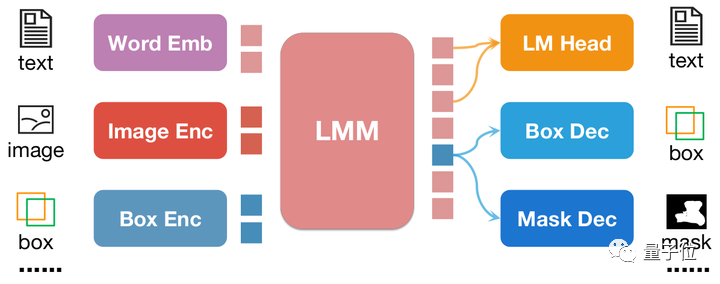
Das größte Highlight von NExT-Chat ist die Möglichkeit, Positionseingabe und -ausgabe in sein multimodales Modell einzuführen. Diese Funktion ermöglicht es NExT-Chat, die Benutzerbedürfnisse während der Interaktion genauer zu verstehen und darauf zu reagieren. Durch die Standorteingabe kann NExT-Chat relevante Informationen und Vorschläge basierend auf dem geografischen Standort des Benutzers bereitstellen und so das Benutzererlebnis verbessern. Durch die Standortausgabe kann NExT-Chat Benutzern relevante Informationen zu bestimmten geografischen Standorten übermitteln, um ihnen besser zu helfen
Dabei bezieht sich die Standorteingabefunktion auf die Beantwortung von Fragen basierend auf dem angegebenen Gebiet, während sich die Standortausgabefunktion auf den Standort bezieht. spezifischen Dialog. Diese beiden Fähigkeiten sind in Puzzlespielen sehr wichtig.

Selbst komplexe Positionierungsprobleme können einfach gelöst werden:

Neben der Objektpositionierung kann NExT-Chat auch das Bild oder einen bestimmten Teil davon beschreiben:
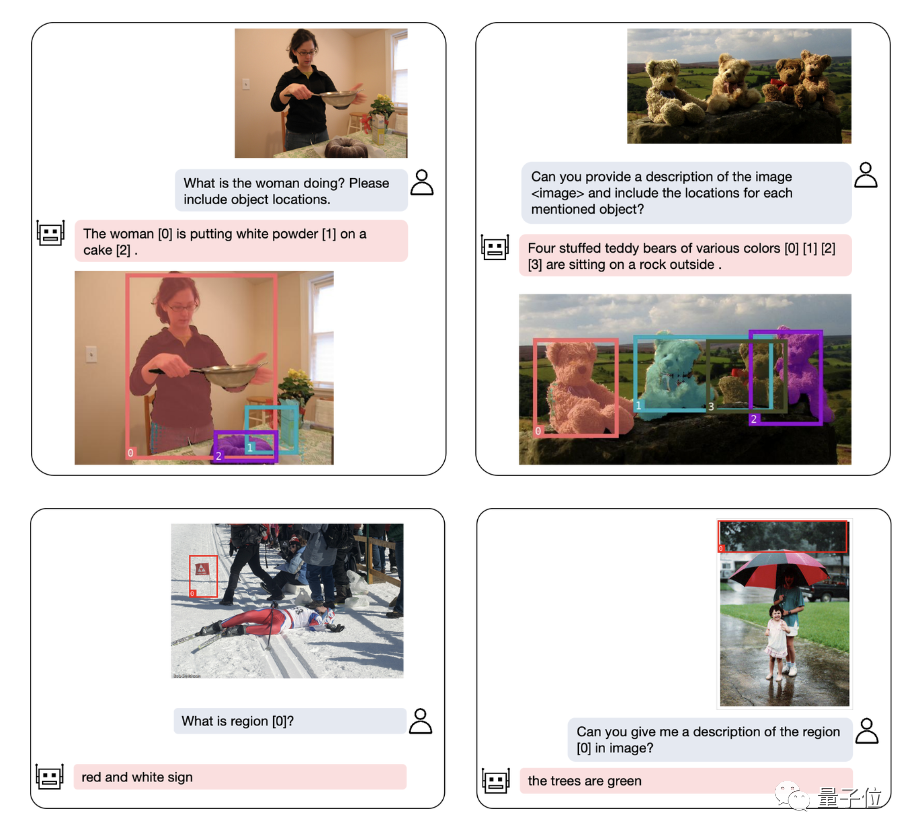
Nach der Analyse des Inhalts des image Anschließend kann NExT-Chat die erhaltenen Informationen verwenden, um eine Inferenz durchzuführen:

Um die Leistung von NExT-Chat genau zu bewerten, führte das Forschungsteam Tests mit mehreren Aufgabendatensätzen durch.
SOTA für mehrere Datensätze erreichen
Der Autor zeigte zunächst die experimentellen Ergebnisse von NExT-Chat für die Aufgabe „Referenzielle Ausdruckssegmentierung“ (RES).
Obwohl nur eine sehr kleine Menge an Segmentierungsdaten verwendet wird, hat NExT-Chat gute referenzielle Segmentierungsfunktionen bewiesen, sogar eine Reihe überwachter Modelle (wie MCN, VLT usw.) besiegt und mehr als das Fünffache der Segmentierungsmaske verwendet . Kommentierte LISA-Methode.
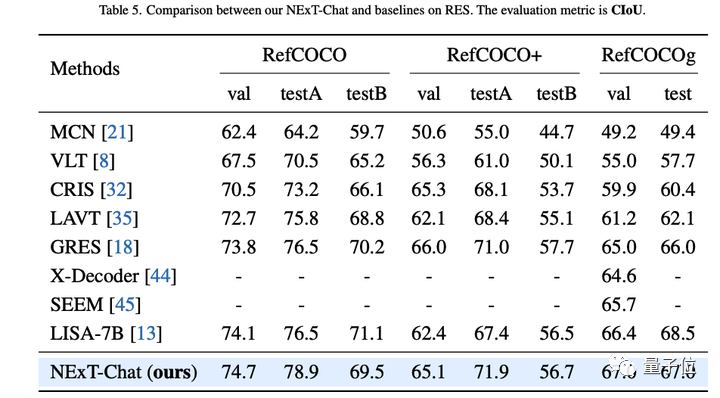
△NExT-Chat-Ergebnisse zur RES-Aufgabe
Dann zeigte das Forschungsteam die experimentellen Ergebnisse von NExT-Chat zur REC-Aufgabe.
Wie in der folgenden Tabelle gezeigt, kann NExT-Chat im Vergleich zu einer Reihe überwachter Methoden (wie UNITER) bessere Ergebnisse erzielen.
Ein interessantes Ergebnis ist, dass NExT-Chat etwas weniger effektiv ist als Shikra, das ähnliche Box-Trainingsdaten verwendet.
Der Autor vermutet, dass dies daran liegt, dass es bei der pix2emb-Methode schwieriger ist, LM-Verlust und Erkennungsverlust auszugleichen, und Shikra näher an der Vortrainingsform des vorhandenen großen Klartextmodells liegt.
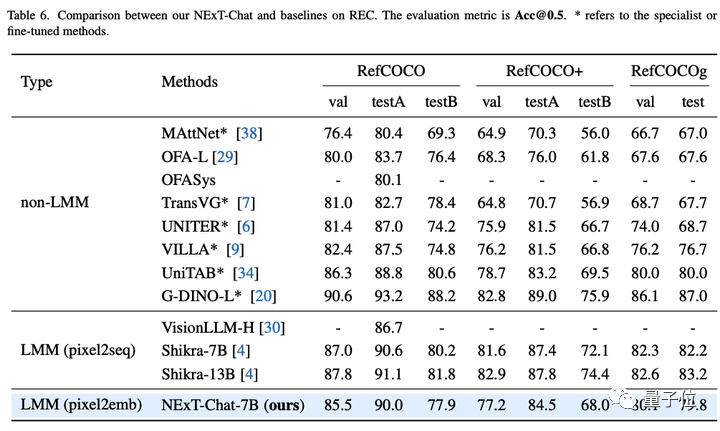
△NExT-Chat-Ergebnisse bei der REC-Aufgabe
Bei der Bildillusionsaufgabe kann NExT-Chat, wie in Tabelle 3 gezeigt, die beste Genauigkeit bei zufälligen und beliebten Datensätzen erzielen.
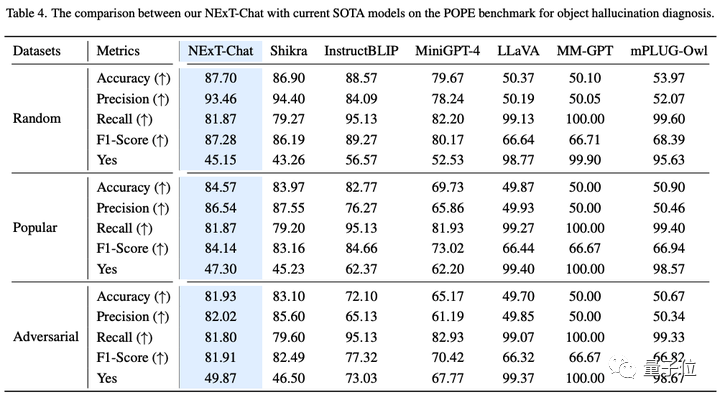
△NExT-Chat-Ergebnisse im POPE-Datensatz
In der Gebietsbeschreibungsaufgabe kann NExT-Chat auch die beste CIDEr-Leistung erzielen und in diesem Indikator Kosmos-2 im 4-Schuss-Fall schlagen.
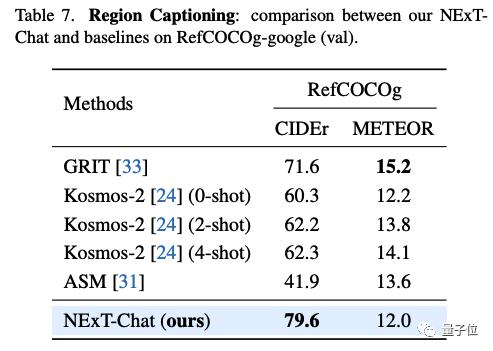
△NExT-Chat-Ergebnisse im RefCOCOg-Datensatz
Welche Methoden werden also hinter NExT-Chat verwendet?
Schlagen Sie eine neue Methode zur Bildcodierung vor
Mängel traditioneller Methoden
Traditionelle Modelle führen hauptsächlich eine LLM-bezogene Positionsmodellierung über pix2seq durch.
Zum Beispiel unterteilt Kosmos-2 das Bild in 32x32-Blöcke und verwendet die ID jedes Blocks, um die Koordinaten des Punkts darzustellen. Shikra wandelt die Koordinaten des Objektrahmens in Klartext um, damit LLM die Koordinaten verstehen kann.
Allerdings ist die Modellausgabe mit der pix2seq-Methode hauptsächlich auf einfache Formate wie Boxen und Punkte beschränkt, und es ist schwierig, sie auf andere dichtere Positionsdarstellungsformate wie Segmentierungsmasken zu verallgemeinern.
Um dieses Problem zu lösen, schlägt dieser Artikel eine neue einbettungsbasierte Positionsmodellierungsmethode pix2emb vor.
pix2emb-Methode
Im Gegensatz zu pix2seq werden alle Positionsinformationen von pix2emb über den entsprechenden Encoder und Decoder codiert und decodiert, anstatt sich auf den Textvorhersageheader von LLM selbst zu verlassen.
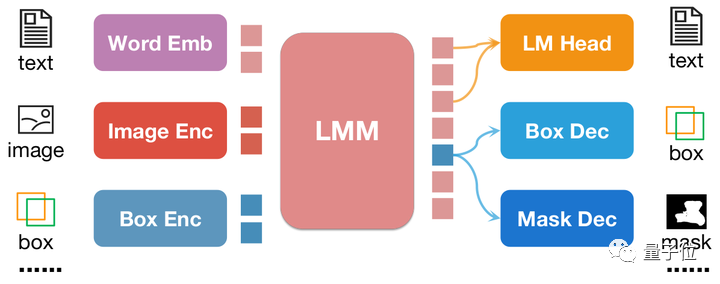
△Einfaches Beispiel der pix2emb-Methode
Wie in der Abbildung oben gezeigt, wird die Positionseingabe durch den entsprechenden Encoder in Positionseinbettung codiert, und die Ausgabepositionseinbettung wird durch Box Decoder und Mask Decoder in Boxen und Masken umgewandelt .
Dies bringt zwei Vorteile mit sich:
- Das Ausgabeformat des Modells kann problemlos auf komplexere Formen erweitert werden, beispielsweise auf eine Segmentierungsmaske.
- Das Modell kann die vorhandenen praktischen Methoden in der Aufgabe leicht finden. Der Erkennungsverlust in diesem Artikel verwendet beispielsweise L1-Verlust und GIoU-Verlust (pix2seq kann nur Text verwenden, um Verlust zu generieren). SAM, um es zu initialisieren.
Durch die Kombination von pix2seq mit pix2emb hat der Autor ein neues NExT-Chat-Modell trainiert.
NExT-Chat-Modell
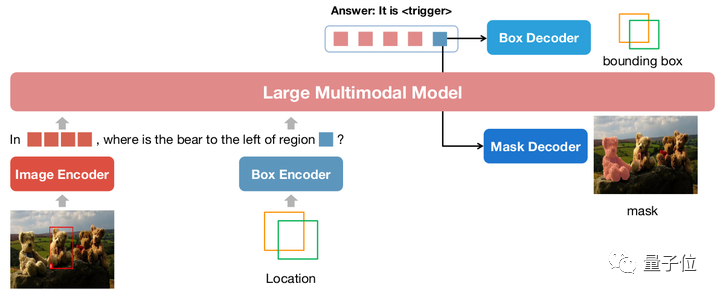
△NExT-Chat-Modellarchitektur
NExT-Chat übernimmt die LLaVA-Architektur als Ganzes, das heißt, Bildinformationen werden durch Image Encoder codiert und zum Verständnis in LLM eingegeben Basis, Entsprechung ist ein Box-Encoder und ein Zwei-Positions-Ausgangsdecoder.
Um das Problem zu lösen, dass LLM nicht weiß, wann der LM-Kopf der Sprache oder der Positionsdecoder verwendet werden soll, führt NExT-Chat zusätzlich einen neuen Token-Typ zur Identifizierung von Positionsinformationen ein.
Wenn das Modell ausgibt, wird die Einbettung des Tokens zur Dekodierung an den entsprechenden Positionsdecoder und nicht an den Sprachdecoder gesendet.
Um die Konsistenz der Positionsinformationen zwischen der Eingabestufe und der Ausgabestufe aufrechtzuerhalten, führt NExT-Chat außerdem eine zusätzliche Ausrichtungsbeschränkung ein:
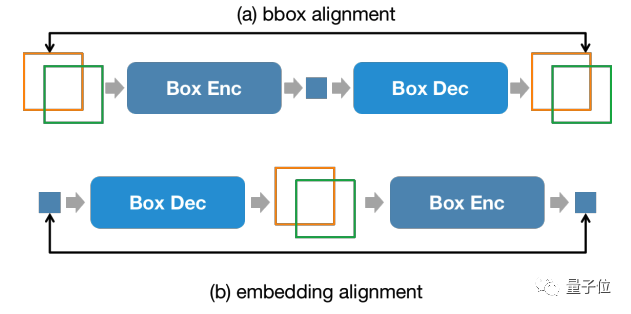
△Positionseingabe- und -ausgabebeschränkungen
Wie in der Abbildung gezeigt Oben werden Box und Position eingebettet Es wird durch Decoder, Encoder bzw. Decoder-Encoder kombiniert und darf sich vorher und nachher nicht ändern.
Der Autor stellte fest, dass diese Methode die Konvergenz der Positionseingabefunktionen erheblich fördern kann.
Das Modelltraining von NExT-Chat umfasst hauptsächlich drei Phasen:
- Die erste Phase: Training des Modells grundlegende Box-Eingabe- und Ausgabefunktionen. NExT-Chat verwendet Flickr-30K, RefCOCO, VisualGenome und andere Datensätze mit Box-Eingabe und -Ausgabe für das Vortraining. Während des Trainingsprozesses werden alle LLM-Parameter trainiert.
- Die zweite Stufe: LLMs Fähigkeit zur Anweisungsfolge anpassen. Durch die Feinabstimmung der Daten durch einige Shikra-RD-, LLaVA-instruct- und andere Anweisungen kann das Modell besser auf menschliche Anforderungen reagieren und humanere Ergebnisse ausgeben.
- Die dritte Stufe: Geben Sie dem NExT-Chat-Modell Segmentierungsfunktionen an. Durch die beiden oben genannten Trainingsphasen verfügt das Modell bereits über gute Positionsmodellierungsfunktionen. Der Autor erweitert diese Fähigkeit weiter, um die Ausgabe zu maskieren. Experimente haben ergeben, dass NExT-Chat durch die Verwendung einer sehr geringen Menge an Maskenanmerkungsdaten und Trainingszeit (ca. 3 Stunden) schnell gute Segmentierungsfunktionen erreichen kann.
Der Vorteil eines solchen Trainingsprozesses besteht darin, dass die Erkennungsrahmendaten umfangreich sind und der Trainingsaufwand geringer ist.
NExT-Chat trainiert grundlegende Positionsmodellierungsfunktionen anhand umfangreicher Erkennungsrahmendaten und kann diese dann schnell auf Segmentierungsaufgaben erweitern, die schwieriger sind und seltener Anmerkungen enthalten.
Das obige ist der detaillierte Inhalt vonGroßformatige Modelle können Bilder bereits mit nur einer einfachen Konversation mit Anmerkungen versehen! Forschungsergebnisse von Tsinghua & NUS. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!