
Heim >Technologie-Peripheriegeräte >KI >Analyse häufig verwendeter KI-Aktivierungsfunktionen: Deep-Learning-Praxis von Sigmoid, Tanh, ReLU und Softmax
Analyse häufig verwendeter KI-Aktivierungsfunktionen: Deep-Learning-Praxis von Sigmoid, Tanh, ReLU und Softmax

- 王林nach vorne
- 2023-12-28 23:35:131658Durchsuche
Aktivierungsfunktionen spielen eine entscheidende Rolle beim Deep Learning. Sie können nichtlineare Eigenschaften in neuronale Netze einführen, wodurch das Netzwerk besser lernen und komplexe Eingabe-Ausgabe-Beziehungen simulieren kann. Die richtige Auswahl und Verwendung von Aktivierungsfunktionen hat einen wichtigen Einfluss auf die Leistung und den Trainingseffekt neuronaler Netze. Nachteile und Optimierungslösungen Erkunden Sie fünf Dimensionen, um Ihnen ein umfassendes Verständnis der Aktivierungsfunktionen zu vermitteln.
 1. Sigmoid-Funktion
1. Sigmoid-Funktion
Sigmoid-Funktionsformel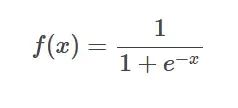 Einführung: Die Sigmoid-Funktion ist eine häufig verwendete nichtlineare Funktion, die jede reelle Zahl zwischen 0 und 1 abbilden kann.
Einführung: Die Sigmoid-Funktion ist eine häufig verwendete nichtlineare Funktion, die jede reelle Zahl zwischen 0 und 1 abbilden kann.
SIgmoid-Funktionsbild 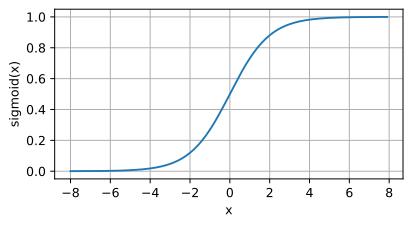 Anwendungsszenario:
Anwendungsszenario:
- Behandeln Sie Regressionsprobleme oder binäre Klassifizierungsprobleme.
- Das Folgende sind die Vorteile:
- kann jeden Eingabebereich
- zwischen 0 und 1 zuordnen, was zum Ausdrücken von Wahrscheinlichkeiten geeignet ist.
- Der Bereich ist begrenzt, was die Berechnungen einfacher und schneller macht. Nachteile: Wenn der Eingabewert sehr groß ist, kann der Gradient sehr klein werden, was zum Problem des verschwindenden Gradienten führt.
- Verwenden Sie andere Aktivierungsfunktionen wie ReLU: Verwenden Sie andere Aktivierungsfunktionen in Kombination mit ReLU oder seinen Varianten (Leaky ReLU und Parametric ReLU).
- Verwenden Sie Optimierungstechniken in Deep-Learning-Frameworks: Verwenden Sie Optimierungstechniken, die von Deep-Learning-Frameworks (wie TensorFlow oder PyTorch) bereitgestellt werden, wie z. B. Gradient Clipping, Lernratenanpassung usw. 2. Tanh-Funktion
Tanh-Funktionsformel 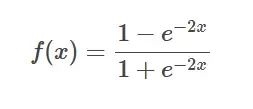 Einführung: Die T
Einführung: Die T
Tanh-Funktionsbild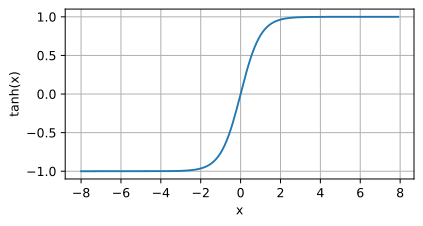 Anwendungsszenario: Wenn eine Funktion erforderlich ist, die steiler als Sigmoid ist, oder in bestimmten Anwendungen, die eine Ausgabe im Bereich von -1 bis 1 erfordern.
Anwendungsszenario: Wenn eine Funktion erforderlich ist, die steiler als Sigmoid ist, oder in bestimmten Anwendungen, die eine Ausgabe im Bereich von -1 bis 1 erfordern.
Das Folgende sind die Vorteile: Sie bietet einen größeren Dynamikbereich und eine steilere Kurve, was die Konvergenzgeschwindigkeit beschleunigen kann
Der Nachteil der Tanh-Funktion besteht darin, dass sich ihre Ableitung schnell 0 nähert, wenn der Eingang nahe bei ±1 liegt , wodurch der Gradient verschwindet Problem
Optimierungslösung:
- Verwenden Sie andere Aktivierungsfunktionen wie ReLU: Verwenden Sie andere Aktivierungsfunktionen wie ReLU oder seine Varianten (Leaky ReLU und Parametric ReLU) in Kombination.
- Restverbindung verwenden: Restverbindung ist eine effektive Optimierungsstrategie, wie z. B. ResNet (Restnetzwerk).
ReLU-Funktion
ReLU-Funktionsformel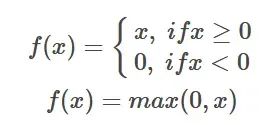 Einführung: Die ReLU-Aktivierungsfunktion ist eine einfache nichtlineare Funktion und ihr mathematischer Ausdruck ist f(x) = max( 0,
Einführung: Die ReLU-Aktivierungsfunktion ist eine einfache nichtlineare Funktion und ihr mathematischer Ausdruck ist f(x) = max( 0,
ReLU-Funktionsbild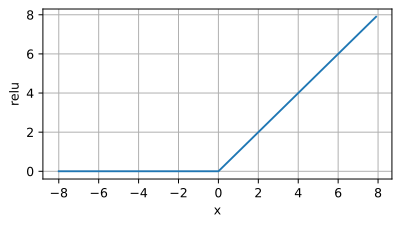 Anwendungsszenario: Die ReLU-Aktivierungsfunktion wird häufig in Deep-Learning-Modellen verwendet, insbesondere in Faltungs-Neuronalen Netzen (CNN). Seine Hauptvorteile bestehen darin, dass es einfach zu berechnen ist, das Problem des verschwindenden Gradienten effektiv lindern und das Modelltraining beschleunigen kann. Daher wird ReLU häufig als bevorzugte Aktivierungsfunktion beim Training tiefer neuronaler Netze verwendet.
Anwendungsszenario: Die ReLU-Aktivierungsfunktion wird häufig in Deep-Learning-Modellen verwendet, insbesondere in Faltungs-Neuronalen Netzen (CNN). Seine Hauptvorteile bestehen darin, dass es einfach zu berechnen ist, das Problem des verschwindenden Gradienten effektiv lindern und das Modelltraining beschleunigen kann. Daher wird ReLU häufig als bevorzugte Aktivierungsfunktion beim Training tiefer neuronaler Netze verwendet.
Das Folgende sind die Vorteile:
- Verringern Sie das Problem des verschwindenden Gradienten: Im Vergleich zu Aktivierungsfunktionen wie Sigmoid und Tanh verkleinert ReLU den Gradienten nicht, wenn der Aktivierungswert positiv ist, und vermeidet so den verschwindenden Gradienten Problem.
- Beschleunigtes Training: Aufgrund der Einfachheit und Recheneffizienz von ReLU kann es den Modelltrainingsprozess erheblich beschleunigen.
Nachteile:
- „Totes Neuron“-Problem: Wenn der Eingabewert kleiner oder gleich 0 ist, ist die Ausgabe von ReLU 0, was dazu führt, dass das Neuron ausfällt. totes Neuron „Yuan“.
- Asymmetrie: Der Ausgabebereich von ReLU ist [0, +∞), und die Ausgabe ist 0, wenn der Eingabewert negativ ist, was zu einer asymmetrischen Verteilung der ReLU-Ausgabe führt und die Vielfalt der Generation begrenzt .
Optimierungsschema:
- Leaky ReLU: Leaky ReLU gibt eine kleinere Steigung aus, wenn die Eingabe kleiner oder gleich 0 ist, wodurch das vollständige Problem des „toten Neurons“ vermieden wird.
- Parametrisches ReLU (PReLU): Im Gegensatz zu Leaky ReLU ist die Steigung von PReLU nicht festgelegt, sondern kann anhand der Daten erlernt und optimiert werden. 4. Softmax-Funktion: Formel für Softmax-Funktion Sein Hauptmerkmal besteht darin, dass der Ausgabewertbereich zwischen 0 und 1 liegt und die Summe aller Ausgabewerte 1 beträgt.
Softmax-Berechnungsprozess
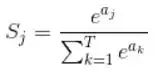 Anwendungsszenario:
Anwendungsszenario:
Weit verbreitet in der Verarbeitung natürlicher Sprache, Bildklassifizierung, Spracherkennung und anderen Bereichen. Das Folgende sind die Vorteile: Bei Problemen mit mehreren Klassifizierungen kann für jede Kategorie ein relativer Wahrscheinlichkeitswert bereitgestellt werden, um die spätere Entscheidungsfindung und Klassifizierung zu erleichtern.
Nachteile: 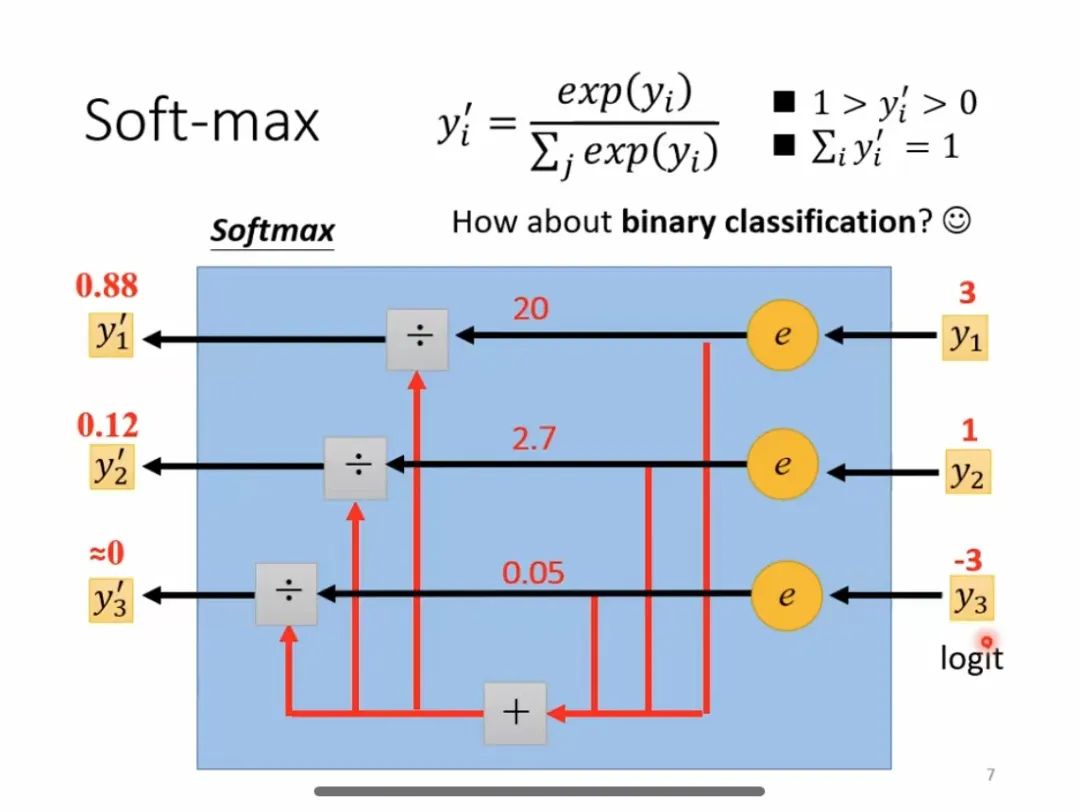 Es wird Probleme mit dem Verschwinden des Gradienten oder der Explosion des Gradienten geben.
Es wird Probleme mit dem Verschwinden des Gradienten oder der Explosion des Gradienten geben.
Optimierungsschema:
- Verwenden Sie andere Aktivierungsfunktionen wie ReLU: Verwenden Sie andere Aktivierungsfunktionen in Kombination mit ReLU oder seinen Varianten (Leaky ReLU und Parametric ReLU).
Verwenden Sie Optimierungstechniken in Deep-Learning-Frameworks: Verwenden Sie Optimierungstechniken, die von Deep-Learning-Frameworks (wie TensorFlow oder PyTorch) bereitgestellt werden, wie z. B. Batch-Normalisierung, Gewichtsabfall usw.
Das obige ist der detaillierte Inhalt vonAnalyse häufig verwendeter KI-Aktivierungsfunktionen: Deep-Learning-Praxis von Sigmoid, Tanh, ReLU und Softmax. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!