
Heim >Technologie-Peripheriegeräte >KI >Die Dimensionsreduzierung des Transformer-Modells verringert sich und die LLM-Leistung bleibt unverändert, wenn mehr als 90 % der Komponenten einer bestimmten Schicht entfernt werden.
Die Dimensionsreduzierung des Transformer-Modells verringert sich und die LLM-Leistung bleibt unverändert, wenn mehr als 90 % der Komponenten einer bestimmten Schicht entfernt werden.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-12-28 15:44:20943Durchsuche
Im Zeitalter der Großmodelle unterstützt allein Transformer den gesamten wissenschaftlichen Forschungsbereich. Seit ihrer Veröffentlichung haben Transformer-basierte Sprachmodelle bei einer Vielzahl von Aufgaben eine hervorragende Leistung gezeigt. Die zugrunde liegende Transformer-Architektur hat sich zum Stand der Technik in der Modellierung und Inferenz natürlicher Sprache entwickelt und hat sich auch in Bereichen wie Computer Vision als vielversprechend erwiesen und Verstärkungslernen. Es zeigt gute Aussichten
Die aktuelle Transformer-Architektur ist sehr groß und erfordert normalerweise viele Rechenressourcen für Training und Inferenz
Dies ist beabsichtigt, da ein Transformer offensichtlich mit mehr Parametern oder Daten trainiert wird größer als andere Modelle sind leistungsfähiger. Dennoch zeigt eine wachsende Zahl von Arbeiten, dass Transformer-basierte Modelle und neuronale Netze nicht alle angepassten Parameter benötigen, um ihre erlernten Hypothesen beizubehalten.
Im Allgemeinen scheint eine massive Überparametrisierung beim Training von Modellen hilfreich zu sein, aber Studien zeigen, dass neuronale Netze oft mehr als 90 % der Gewichte entfernen können, ohne eine gute Leistung zu erbringen erheblicher Rückgang. Dieses Phänomen veranlasste Forscher dazu, sich Bereinigungsstrategien zuzuwenden, die die Modellinferenz unterstützen
Forscher von MIT und Microsoft berichteten in einem Artikel mit dem Titel „The Truth Is Out There: Improving Improvement through Layer Selective Ranking Reduction“. Artikel „Die Argumentationsfähigkeit von Sprachmodellen“. Sie fanden heraus, dass eine Feinbereinigung auf bestimmten Ebenen des Transformer-Modells die Leistung des Modells bei bestimmten Aufgaben deutlich verbessern kann Homepage: https://pratyushasharma.github.io/laser/

- Dieser einfache Eingriff wird in der Studie LASER (LAyer SElective Rank Reduction) genannt. Es verbessert die Leistung von LLM erheblich, indem es die höherwertigen Komponenten der Lerngewichtsmatrix einer bestimmten Schicht im Transformer-Modell durch Singulärwertzerlegung selektiv reduziert. Dieser Vorgang kann nach Abschluss des Modelltrainings durchgeführt werden und erfordert keine zusätzlichen Parameter oder Daten
- Während des Vorgangs erfolgt die Reduzierung der Gewichte durch Anwenden modellspezifischer Gewichtsmatrizen und -schichten. Die Studie ergab außerdem, dass viele ähnliche Matrizen in der Lage waren, Gewichte deutlich zu reduzieren, und im Allgemeinen wurde kein Leistungsabfall beobachtet, bis mehr als 90 % der Komponenten entfernt wurden Die Studie ergab außerdem, dass die Reduzierung dieser Faktoren die Genauigkeit deutlich verbesserte. Interessanterweise gilt dieser Befund nicht nur für natürliche Sprache, sondern verbessert auch die Leistung beim Reinforcement Learning
Darüber hinaus versucht diese Studie abzuleiten, was in Komponenten höherer Ordnung gespeichert ist, um die Leistung durch Löschung zu verbessern. Die Studie ergab, dass das ursprüngliche Modell nach der Verwendung von LASER zur Beantwortung von Fragen hauptsächlich mit hochfrequenten Wörtern (wie „der“, „von“ usw.) antwortete. Diese Wörter stimmen nicht einmal mit dem semantischen Typ der richtigen Antwort überein, was bedeutet, dass diese Komponenten ohne Eingriff dazu führen, dass das Modell einige irrelevante hochfrequente Wörter generiert Die Antworten des Modells können in richtige umgewandelt werden.
Um dies zu verstehen, untersuchte die Studie auch, was die übrigen Komponenten einzeln kodierten, und sie approximierten die Gewichtsmatrix nur mithilfe ihrer singulären Vektoren höherer Ordnung. Es wurde festgestellt, dass diese Komponenten unterschiedliche Antworten oder häufig vorkommende Wörter in derselben semantischen Kategorie wie die richtige Antwort beschrieben.
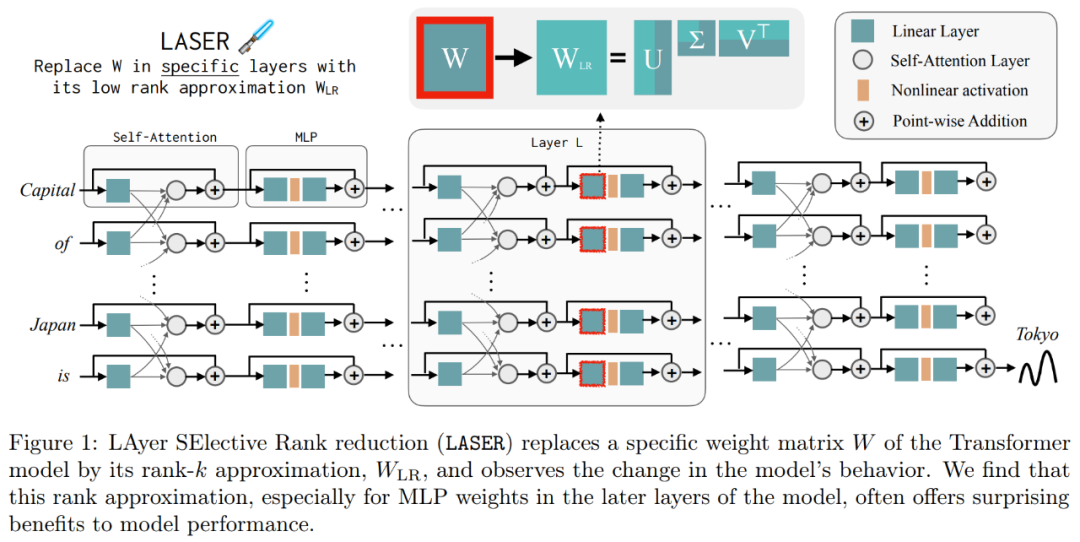
Diese Ergebnisse legen nahe, dass bei der Kombination verrauschter Komponenten höherer Ordnung mit Komponenten niedrigerer Ordnung deren widersprüchliche Antworten zu einer durchschnittlichen Antwort führen, die möglicherweise falsch ist. Abbildung 1 bietet eine visuelle Darstellung der Transformer-Architektur und des von LASER befolgten Verfahrens. Hier wird die Gewichtsmatrix einer bestimmten Schicht eines mehrschichtigen Perzeptrons (MLP) durch ihre Näherung mit niedrigem Rang ersetzt.
LASER-Übersicht
Der Forscher stellte den LASER-Eingriff im Detail vor. Der einstufige LASER-Eingriff wird durch drei Parameter (τ, ℓ und ρ) definiert. Zusammen beschreiben diese Parameter die Matrix, die durch die Näherung niedrigen Rangs ersetzt werden soll, und den Grad der Näherung. Der Forscher klassifiziert die einzugreifenden Matrizen nach Parametertypen
Der Forscher konzentriert sich auf die Matrix W = {W_q, W_k, W_v, W_o, U_in, U_out}, die aus mehrschichtigem Perzeptron (MLP) und Aufmerksamkeitsmatrix besteht Zusammensetzung in der Kraftschicht. Die Anzahl der Schichten stellt den Grad der Intervention des Forschers dar, wobei der Index der ersten Schicht 0 ist. Beispielsweise hat Llama-2 32 Stufen und wird daher als ℓ ∈ {0, 1, 2,・・・31}
ausgedrücktLetztendlich beschreibt ρ ∈ [0, 1), welcher Teil des maximalen Rangs beibehalten werden sollte, wenn Näherungen mit niedrigem Rang vorgenommen werden. Unter der Annahme 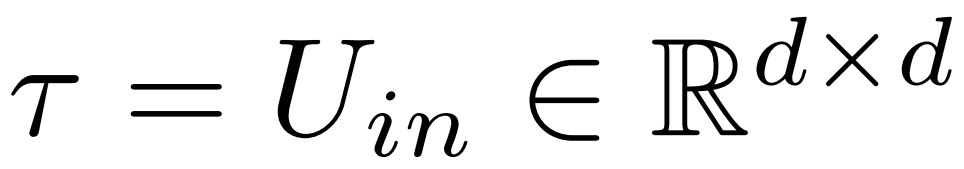 ist der maximale Rang der Matrix beispielsweise d. Die Forscher ersetzten es durch die ⌊ρ・d⌋-Näherung.
ist der maximale Rang der Matrix beispielsweise d. Die Forscher ersetzten es durch die ⌊ρ・d⌋-Näherung.
Folgendes ist erforderlich In Abbildung 1 unten ist ein Beispiel für LASER dargestellt. Die Symbole τ = U_in und ℓ = L in der Abbildung zeigen an, dass die Gewichtsmatrix der ersten Schicht des MLP im Transformer-Block der L-ten Schicht aktualisiert wird. Es gibt auch einen Parameter zur Steuerung des k-Werts in der Rang-k-Näherung
LASER kann den Fluss bestimmter Informationen im Netzwerk begrenzen und unerwartet erhebliche Leistungsvorteile bewirken. Diese Interventionen können auch problemlos kombiniert werden, beispielsweise durch die Anwendung einer Reihe von Interventionen in beliebiger Reihenfolge 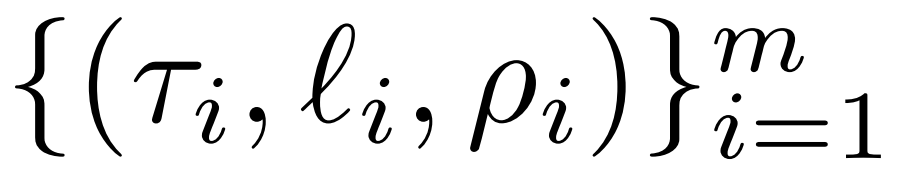 .
.
Die LASER-Methode ist nur eine einfache Suche nach dieser Art von Intervention, die so modifiziert wurde, dass sie den maximalen Nutzen bringt. Es gibt jedoch viele andere Möglichkeiten, diese Interventionen zu kombinieren, was eine Richtung für die zukünftige Arbeit darstellt.
Experimentelle Ergebnisse
Im experimentellen Teil verwendete der Forscher das GPT-J-Modell, das auf dem PILE-Datensatz vorab trainiert wurde, der 27 Schichten und 6 Milliarden Parameter enthält. Das Verhalten des Modells wird dann anhand des CounterFact-Datensatzes bewertet, der Beispiele von Tripeln (Thema, Beziehung und Antwort) enthält, wobei für jede Frage drei Paraphrasierungsaufforderungen bereitgestellt werden.
Zuerst haben wir das GPT-J-Modell anhand des CounterFact-Datensatzes analysiert. Abbildung 2 zeigt die Auswirkungen auf den Klassifizierungsverlust eines Datensatzes, nachdem auf jede Matrix in der Transformer-Architektur unterschiedliche Grade der Rangreduktion angewendet wurden. Jede Transformer-Schicht besteht aus einem zweischichtigen kleinen MLP, wobei Eingabe- und Ausgabematrizen separat angezeigt werden. Unterschiedliche Farben stellen unterschiedliche Prozentsätze der entfernten Komponenten dar.
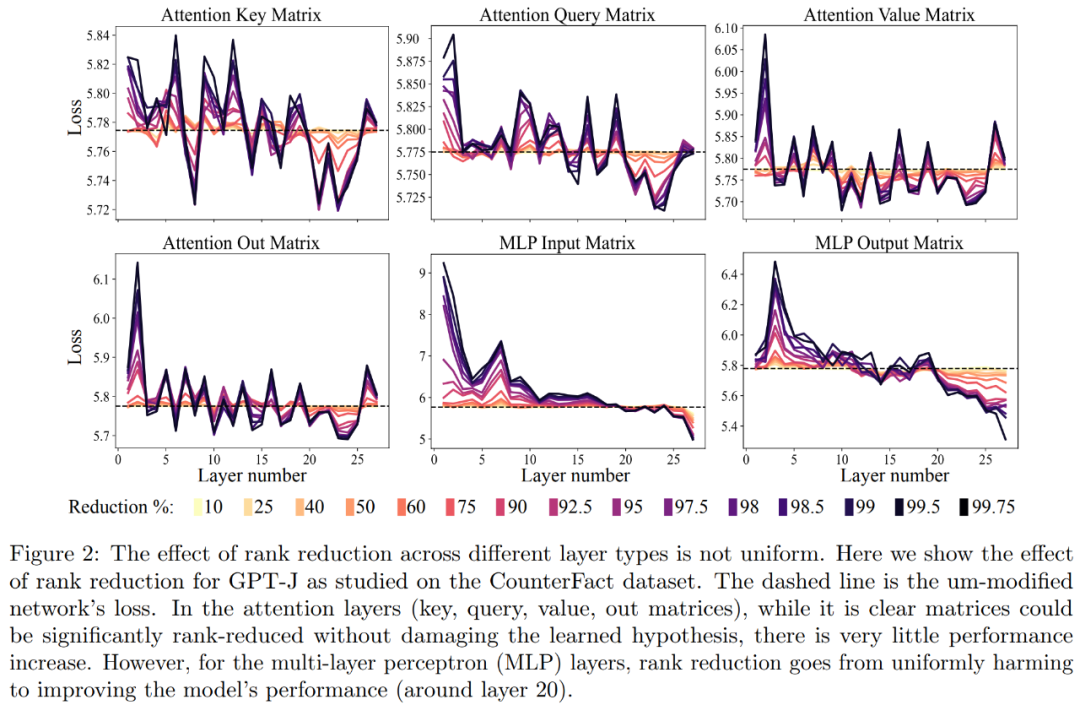
In Bezug auf die Genauigkeit und Robustheit der verbesserten Interpretation, wie in Abbildung 2 oben und Tabelle 1 unten dargestellt, stellten die Forscher fest, dass bei der Rangreduzierung auf einer einzelnen Ebene der Sachverhalt Die Genauigkeit des GPT-J-Modells für den CounterFact-Datensatz stieg von 13,1 % auf 24,0 %. Es ist wichtig zu beachten, dass diese Verbesserungen nur das Ergebnis einer Rangreduzierung sind und kein weiteres Training oder eine Feinabstimmung des Modells erfordern.
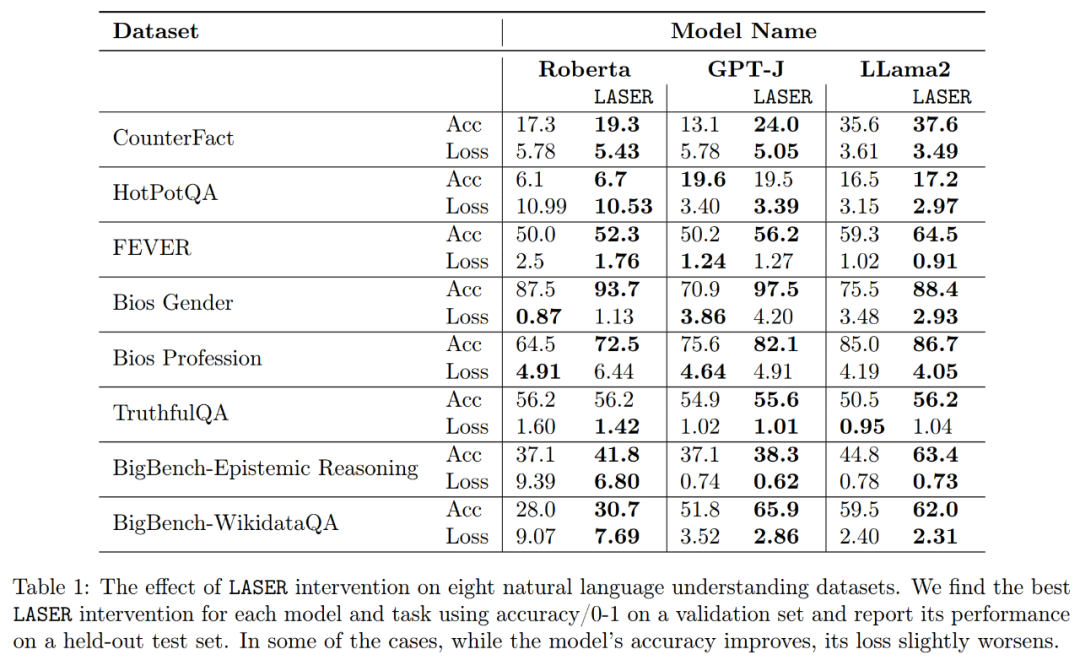
Welche Fakten werden bei der Downrank-Wiederherstellung wiederhergestellt? Die Forscher fanden heraus, dass die durch Rangreduzierungswiederherstellung gewonnenen Fakten wahrscheinlich sehr selten im Datensatz vorkommen, wie in Abbildung 3 dargestellt.
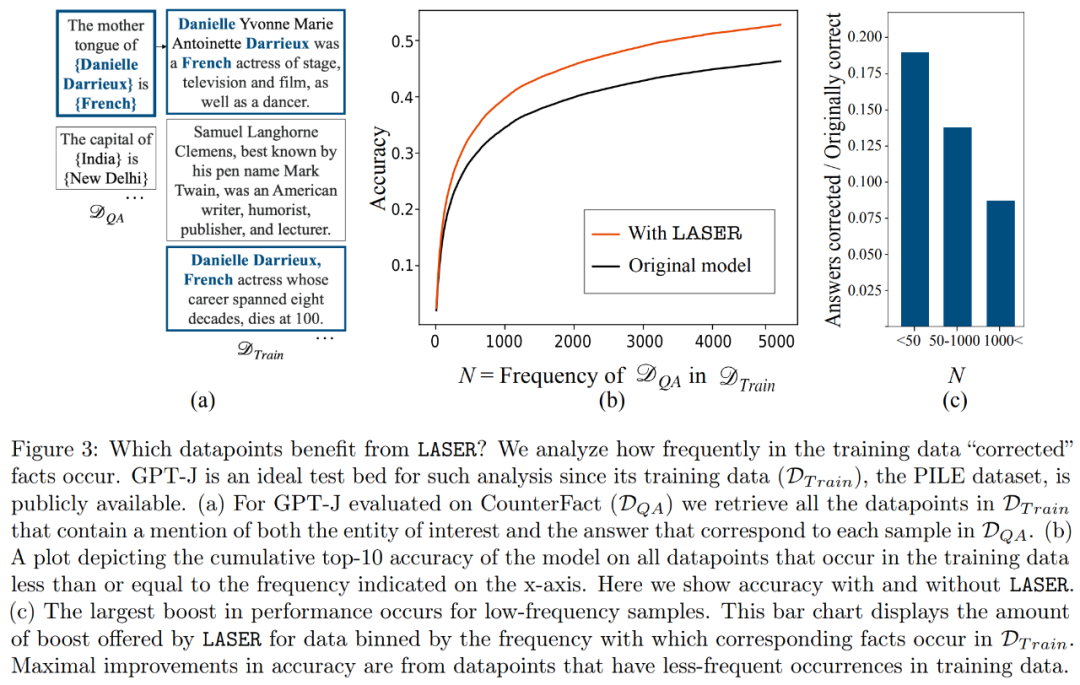
Was speichern Komponenten höherer Ordnung? Die Forscher verwenden Komponenten höherer Ordnung, um die endgültige Gewichtsmatrix anzunähern (anstatt Komponenten niedriger Ordnung wie LASER zu verwenden), wie in Abbildung 5 (a) unten dargestellt. Sie haben die durchschnittliche Kosinusähnlichkeit der wahren Antworten im Verhältnis zu den vorhergesagten Antworten gemessen, als sie die Matrix mit einer unterschiedlichen Anzahl von Komponenten höherer Ordnung approximierten, wie in Abbildung 5 (b) unten dargestellt.
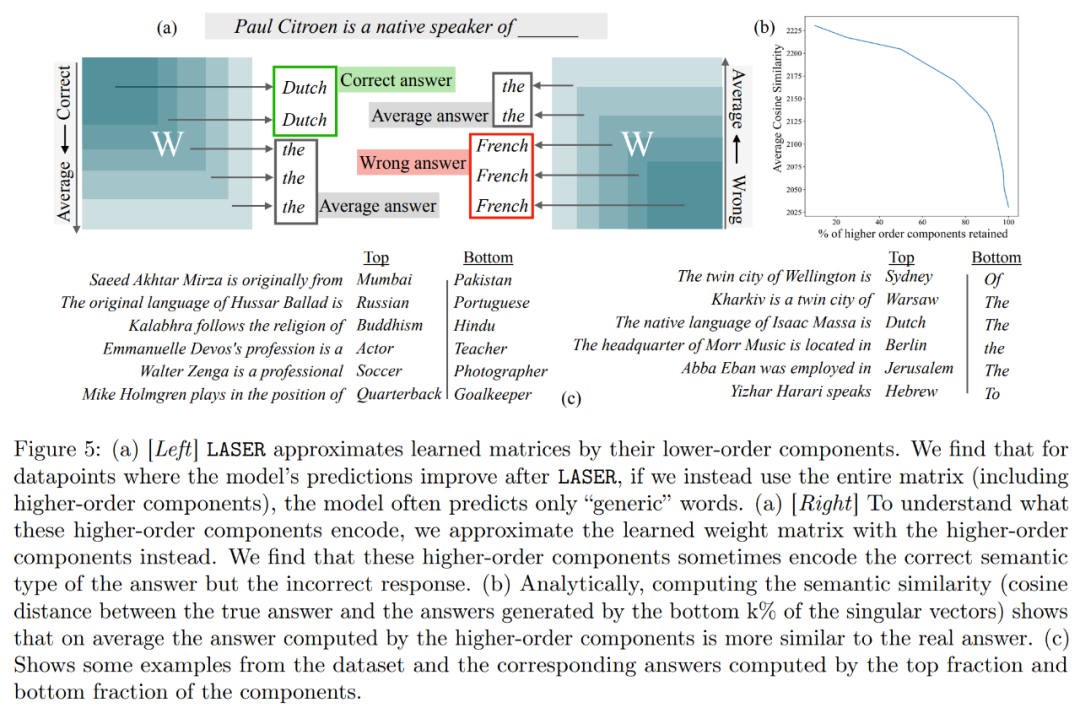
Die Forscher bewerteten schließlich die Generalisierbarkeit der drei verschiedenen LLMs, die sie bei mehreren Sprachverständnisaufgaben gefunden hatten. Für jede Aufgabe bewerteten sie die Leistung des Modells anhand von drei Metriken: Generierungsgenauigkeit, Klassifizierungsgenauigkeit und Verlust. Den Ergebnissen in Tabelle 1 zufolge führt eine starke Reduzierung des Matrixrangs nicht zu einer Verringerung der Genauigkeit des Modells, sondern kann stattdessen die Leistung des Modells verbessern
Das obige ist der detaillierte Inhalt vonDie Dimensionsreduzierung des Transformer-Modells verringert sich und die LLM-Leistung bleibt unverändert, wenn mehr als 90 % der Komponenten einer bestimmten Schicht entfernt werden.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!