Metas neues Videosynthese-Framework hat uns einige Überraschungen beschert
Im Hinblick auf den heutigen Entwicklungsstand der künstlichen Intelligenz sind textbasierte Bilder, bildbasierte Videos und die Übertragung von Bild-/Videostilen keine schwierige Angelegenheit. Generative KI ist mit der Fähigkeit ausgestattet, mühelos Inhalte zu erstellen oder zu ändern. Insbesondere die Bildbearbeitung verzeichnete ein erhebliches Wachstum, angetrieben durch Text-zu-Bild-Diffusionsmodelle, die auf Datensätzen im Milliardenmaßstab vorab trainiert wurden. Diese Welle hat eine Vielzahl von Apps zur Bildbearbeitung und Inhaltserstellung hervorgebracht. Basierend auf den Errungenschaften bildbasierter generativer Modelle muss die nächste Herausforderung darin bestehen, eine „Zeitdimension“ hinzuzufügen, um eine einfache und kreative Videobearbeitung zu erreichen. Eine einfache Strategie besteht darin, ein Bildmodell zu verwenden, um das Video Bild für Bild zu verarbeiten. Die generative Bildbearbeitung ist jedoch von Natur aus sehr variabel – es gibt unzählige Möglichkeiten, ein bestimmtes Bild sogar über dieselbe Textaufforderung zu bearbeiten. Wenn jedes Bild unabhängig bearbeitet wird, ist es schwierig, die zeitliche Konsistenz aufrechtzuerhalten. In einem aktuellen Artikel schlugen Forscher des Meta GenAI-Teams Fairy vor – eine „einfache Anpassung“ des Bildbearbeitungs-Diffusionsmodells, die die Leistung der KI bei der Videobearbeitung erheblich verbessert. Das Folgende ist die Anzeige der Bearbeitungsvideoeffekte von Fairy: 
Fairy generiert 120 Bilder von 512×384-Videos (4 Sekunden lang, 30 FPS). 14 Sekunden, Das ist mindestens 44-mal schneller als frühere Methoden. Eine umfassende Benutzerstudie mit 1000 generierten Proben bestätigte, dass die vorgeschlagene Methode eine hohe Qualität generiert und bestehende Methoden deutlich übertrifft. Dem Artikel zufolge basiert Fairy auf dem Konzept der rahmenübergreifenden Aufmerksamkeit basierend auf Ankerpunkten. Dieser Mechanismus kann Diffusionsmerkmale implizit über Rahmen hinweg verbreiten und so zeitkonsistente und hochauflösende Syntheseeffekte gewährleisten. Fairy überwindet nicht nur die Einschränkungen früherer Modelle in Bezug auf Speicher und Verarbeitungsgeschwindigkeit, sondern verbessert auch die zeitliche Konsistenz durch eine einzigartige Datenerweiterungsstrategie, die das Modell einer affinen Transformation der Quell- und Zielbilder gleichwertig macht.
- Paper-Adresse: https://arxiv.org/pdf/2312.13834.pdf
- project Homepage: https://fairy-video2video.github.io/
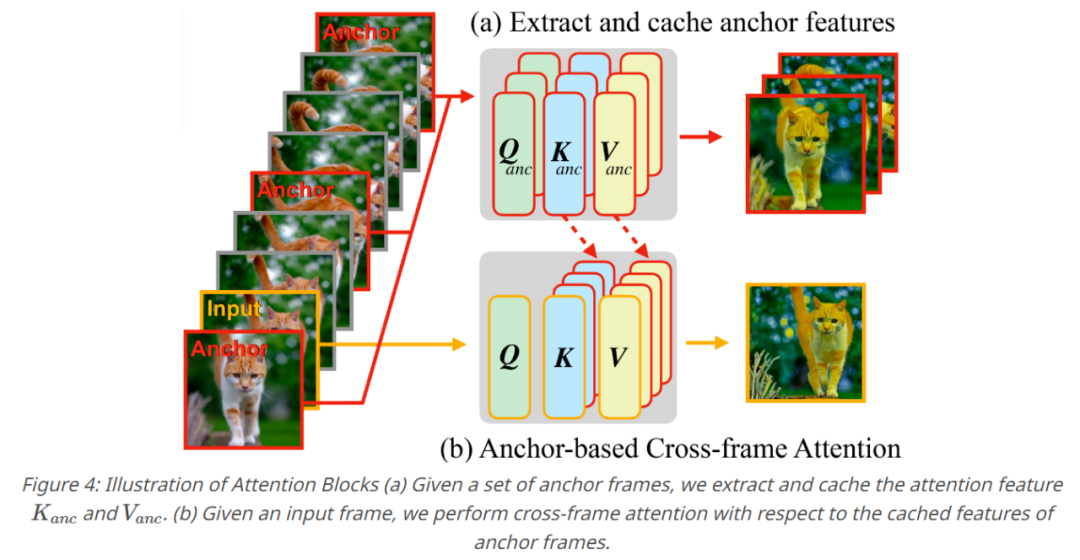
Fairy greift das bisherige Tracking-and-Propagation-Paradigma im Kontext der Eigenschaften von Diffusionsmodellen erneut auf. Insbesondere verwendet diese Studie die Korrespondenzschätzung, um die Aufmerksamkeit über mehrere Frames hinweg zu überbrücken und es dem Modell zu ermöglichen, Zwischenmerkmale innerhalb des Diffusionsmodells zu verfolgen und zu verbreiten. Die Aufmerksamkeitskarte über Frames hinweg kann als Ähnlichkeitsmaß interpretiert werden, um die Korrespondenz zwischen Token in jedem Frame zu bewerten, wobei Merkmale in einem semantischen Bereich anderen Frames mit ähnlichen semantischen Bereichen eine höhere Aufmerksamkeit zuweisen, wie in Abbildung 3 unten dargestellt . Daher wird die aktuelle Merkmalsdarstellung verfeinert und verbreitet, indem der Schwerpunkt auf der gewichteten Summe ähnlicher Bereiche zwischen Frames liegt, wodurch Merkmalsunterschiede zwischen Frames effektiv minimiert werden.
Eine Reihe von Operationen erzeugt ein ankerbasiertes Modell, das die Kernkomponente von Fairy darstellt. Um die zeitliche Konsistenz der generierten Videos sicherzustellen, wurden in dieser Studie K Ankerbilder abgetastet, um Diffusionsmerkmale zu extrahieren, und die extrahierten Merkmale wurden als eine Reihe globaler Merkmale definiert, die auf aufeinanderfolgende Bilder übertragen werden sollten. Diese Studie ersetzt die Selbstaufmerksamkeitsschicht durch rahmenübergreifende Aufmerksamkeit für die zwischengespeicherten Merkmale des Ankerrahmens, wenn jeder neue Rahmen generiert wird. Durch die rahmenübergreifende Aufmerksamkeit übernehmen Token in jedem Rahmen Merkmale, die im Ankerrahmen ähnliche semantische Inhalte aufweisen, wodurch die Konsistenz verbessert wird.
Experimentelle EvaluierungIm experimentellen Teil implementierten die Forscher Fairy hauptsächlich auf der Grundlage des instruktiven Bildbearbeitungsmodells und verwendeten Cross-Frame-Aufmerksamkeit, um die Selbstaufmerksamkeit des Modells zu ersetzen. Sie legen die Anzahl der Ankerrahmen auf 3 fest. Das Modell kann Eingaben mit unterschiedlichen Seitenverhältnissen akzeptieren und die größere Eingabeauflösung auf 512 neu skalieren, wobei das Seitenverhältnis unverändert bleibt. Die Forscher bearbeiten alle Frames des Eingabevideos ohne Downsampling. Alle Berechnungen sind auf 8 A100-GPUs verteilt. Der Forscher zeigte zunächst die qualitativen Ergebnisse von Fairy, wie in Abbildung 5 unten dargestellt. Fairy kann verschiedene Themen bearbeiten.
In Abbildung 6 unten zeigt der Forscher, dass Fairy gemäß Textanweisungen verschiedene Arten der Bearbeitung durchführen kann, einschließlich Stilisierung, Rollenwechsel, lokale Bearbeitung, Attributbearbeitung usw.
Abbildung 9 unten zeigt, dass Fairy den Quellcharakter gemäß den Anweisungen in verschiedene Zielcharaktere umwandeln kann.
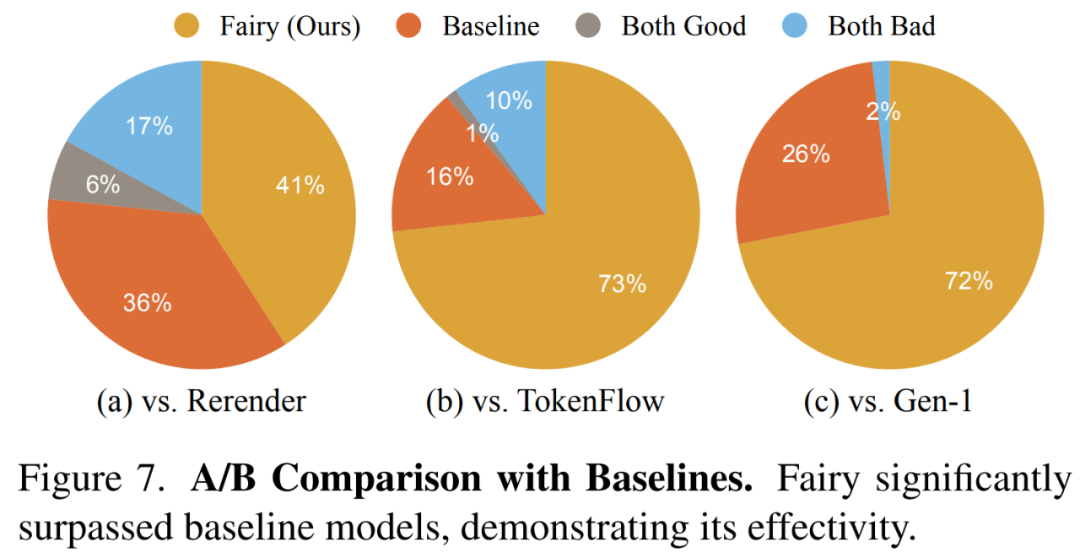
Die Forscher zeigen die Ergebnisse des Gesamtqualitätsvergleichs in Abbildung 7 unten, in der die von Fairy generierten Videos beliebter sind.
Abbildung 10 unten zeigt die visuellen Vergleichsergebnisse mit dem Basismodell.
Weitere technische Details und experimentelle Ergebnisse finden Sie im Originalpapier. Das obige ist der detaillierte Inhalt vonVideos können in 14 Sekunden rekonstruiert werden und Charaktere können geändert werden. Meta beschleunigt die Videosynthese um das 44-fache.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!