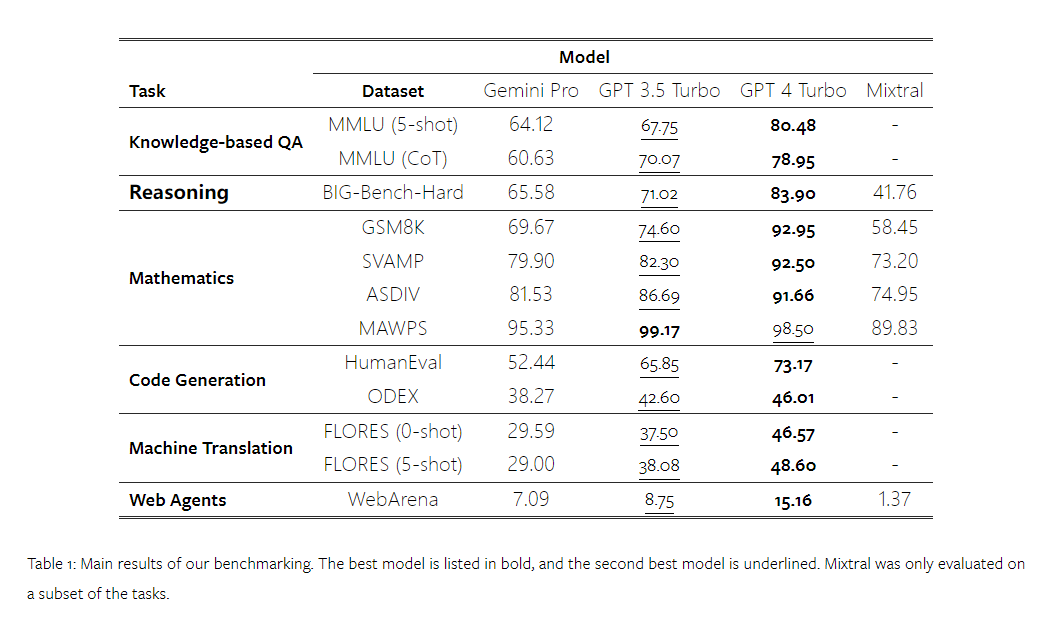
Wie viel wiegt Googles Gemini? Wie ist der Vergleich mit dem GPT-Modell von OpenAI? Dieses CMU-Papier hat eindeutige Messergebnisse
Vor einiger Zeit hat Google einen Konkurrenten zum OpenAI GPT-Modell veröffentlicht – Gemini. Dieses große Modell gibt es in drei Versionen – Ultra (die leistungsfähigste), Pro und Nano. Die vom Forschungsteam veröffentlichten Testergebnisse zeigen, dass die Ultra-Version GPT4 in vielen Aufgaben übertrifft, während die Pro-Version GPT-3.5 ebenbürtig ist. Obwohl diese Vergleichsergebnisse für die groß angelegte Sprachmodellforschung von großer Bedeutung sind, schränkt dies die Reproduktion und Erkennung der Testergebnisse ein, da die genauen Bewertungsdetails und Modellvorhersagen noch nicht veröffentlicht wurden, was sie erschwert um die impliziten Details weiter zu analysieren. Um die wahre Stärke von Zwillingen zu verstehen, führten Forscher der Carnegie Mellon University und BerriAI eine eingehende Untersuchung des Sprachverständnisses und der Sprachgenerierungsfähigkeiten des Modells durch. Sie testeten die Textverständnis- und Generierungsfunktionen von Gemini Pro, GPT 3.5 Turbo, GPT 4 Turbo und Mixtral an zehn Datensätzen. Insbesondere testeten sie die Fähigkeit des Modells, wissensbasierte Fragen auf MMLU zu beantworten, die Argumentationsfähigkeit des Modells auf BigBenchHard, die Fähigkeit des Modells, mathematische Fragen in Datensätzen wie GSM8K zu beantworten, und die Fähigkeit des Modells, mathematische Fragen in Datensätzen wie zu beantworten FLORES. Die Übersetzungsfähigkeit des Modells wurde in Datensätzen wie HumanEval getestet. Die Fähigkeit des Modells als Agent, der Anweisungen befolgt, wurde in WebArena getestet.  Tabelle 1 unten zeigt die Hauptergebnisse des Vergleichs. Insgesamt liegt Gemini Pro zum Zeitpunkt der Veröffentlichung des Artikels hinsichtlich der Genauigkeit bei allen Aufgaben nahe an OpenAI GPT 3.5 Turbo, ist aber immer noch etwas schlechter. Darüber hinaus stellten sie fest, dass Gemini und GPT besser abschneiden als das Open-Source-Konkurrenzmodell Mixtral. In der Arbeit liefert der Autor eine ausführliche Beschreibung und Analyse jeder Aufgabe. Alle Ergebnisse und reproduzierbaren Code finden Sie unter: https://github.com/neulab/gemini-benchmarkPapierlink: https://arxiv.org/pdf/2312.11444.pdf Experimentelle EinstellungenDer Autor hat vier Modelle als Testobjekte ausgewählt: Gemini Pro, GPT 3.5 Turbo, GPT 4 Turbo und Mixtral.
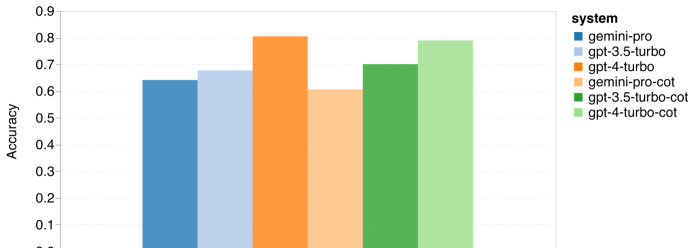
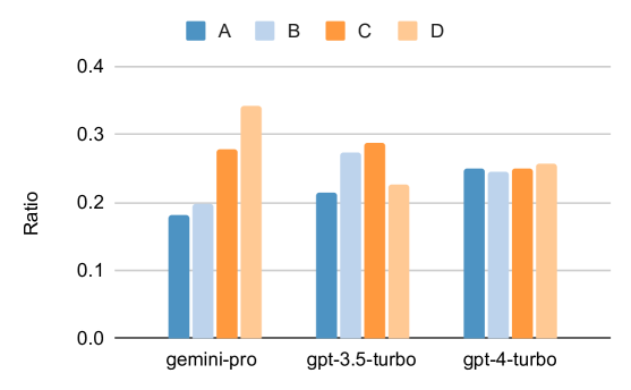
Tabelle 1 unten zeigt die Hauptergebnisse des Vergleichs. Insgesamt liegt Gemini Pro zum Zeitpunkt der Veröffentlichung des Artikels hinsichtlich der Genauigkeit bei allen Aufgaben nahe an OpenAI GPT 3.5 Turbo, ist aber immer noch etwas schlechter. Darüber hinaus stellten sie fest, dass Gemini und GPT besser abschneiden als das Open-Source-Konkurrenzmodell Mixtral. In der Arbeit liefert der Autor eine ausführliche Beschreibung und Analyse jeder Aufgabe. Alle Ergebnisse und reproduzierbaren Code finden Sie unter: https://github.com/neulab/gemini-benchmarkPapierlink: https://arxiv.org/pdf/2312.11444.pdf Experimentelle EinstellungenDer Autor hat vier Modelle als Testobjekte ausgewählt: Gemini Pro, GPT 3.5 Turbo, GPT 4 Turbo und Mixtral. 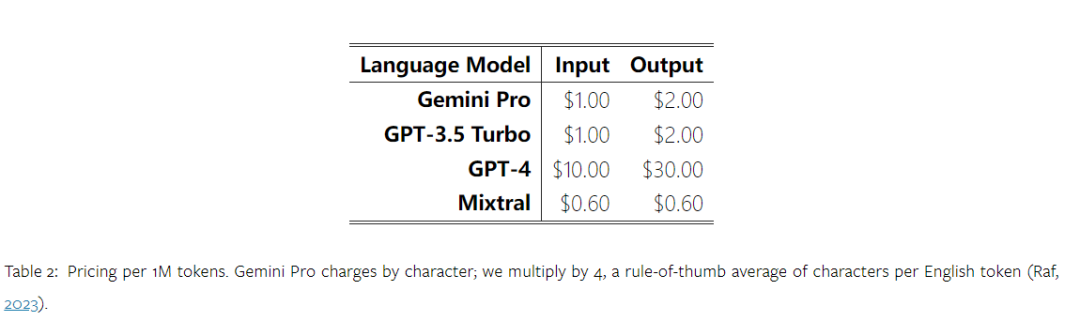 Aufgrund der Unterschiede in den experimentellen Einstellungen während der Auswertung in früheren Studien führte der Autor das Experiment erneut durch, um einen fairen Test zu gewährleisten, wobei er genau die gleichen Aufforderungswörter und das gleiche Auswertungsprotokoll verwendete. In den meisten Beurteilungen verwendeten sie Aufforderungswörter und Rubriken aus einem Standard-Repository. Diese Testressourcen stammen aus dem Datensatz, der mit der Modellfreigabe und dem Evaluierungstool Eleuther usw. geliefert wird. Zu den Aufforderungswörtern gehören normalerweise Abfragen, Eingaben, eine kleine Anzahl von Beispielen, Überlegungen zur Denkkette usw. In einigen Sondergutachten stellten die Autoren fest, dass geringfügige Anpassungen der Standardpraktiken erforderlich seien. Die Anpassung der Voreingenommenheit wurde im entsprechenden Code-Repository durchgeführt. Weitere Informationen finden Sie im Originalpapier. Die Ziele dieser Forschung sind wie folgt: 1. Bereitstellung eines objektiven Vergleichs der Fähigkeiten von OpenAI GPT- und Google Gemini-Modellen durch Dritte durch reproduzierbaren Code und vollständig transparente Ergebnisse. 2. Studieren Sie die Bewertungsergebnisse eingehend und analysieren Sie, in welchen Bereichen die beiden Modelle besser abschneiden. Wissensbasierte Qualitätssicherung Der Autor hat 57 wissensbasierte Multiple-Choice-Frage- und Antwortaufgaben aus dem MMLU-Datensatz ausgewählt, die die Themen MINT, Geistes- und Sozialwissenschaften usw. abdecken. MMLU verfügt über insgesamt 14.042 Testbeispiele und wird häufig verwendet, um eine Gesamtbewertung der Wissensfähigkeiten großer Sprachmodelle bereitzustellen. Der Autor verglich und analysierte die Gesamtleistung der vier Testobjekte auf MMLU (wie in der Abbildung unten dargestellt), die Leistung der Unteraufgaben und den Einfluss der Ausgabelänge auf die Leistung. Abbildung 1: Gesamtgenauigkeit jedes Modells auf MMLU unter Verwendung von 5 Beispiel-Eingabeaufforderungen und Gedankenketten-Eingabeaufforderungen. Wie Sie der Abbildung entnehmen können, ist die Genauigkeit von Gemini Pro geringer als die von GPT 3.5 Turbo und viel geringer als die von GPT 4 Turbo.Bei Verwendung der Denkketten-Eingabeaufforderung gibt es kaum Unterschiede in der Leistung der einzelnen Modelle. Die Autoren vermuten, dass dies auf die Tatsache zurückzuführen ist, dass MMLU in erster Linie wissensbasierte Frage- und Antwortaufgaben erfasst, die möglicherweise nicht wesentlich von stärker argumentationsorientierten Eingabeaufforderungen profitieren. Es ist erwähnenswert, dass alle Fragen in MMLU Multiple-Choice-Fragen mit vier möglichen Antworten A bis D sind, die in der richtigen Reihenfolge angeordnet sind. Die folgende Grafik zeigt den Anteil der einzelnen Antwortoptionen, die von jedem Modell ausgewählt wurden. Aus der Abbildung können Sie ersehen, dass die Antwortverteilung von Gemini stark in Richtung der Wahl der letzten D-Option tendiert. Dies steht im Gegensatz zu den ausgewogeneren Ergebnissen, die GPT-Versionen liefern. Dies kann darauf hindeuten, dass Gemini nicht die umfassenden Anpassungen der Anweisungen erhalten hat, die mit Multiple-Choice-Fragen einhergehen, was zu einer Verzerrung der Antwortrangfolge des Modells führt. Abbildung 2: Anteil der vom getesteten Modell vorhergesagten Antworten auf Multiple-Choice-Fragen.
Aufgrund der Unterschiede in den experimentellen Einstellungen während der Auswertung in früheren Studien führte der Autor das Experiment erneut durch, um einen fairen Test zu gewährleisten, wobei er genau die gleichen Aufforderungswörter und das gleiche Auswertungsprotokoll verwendete. In den meisten Beurteilungen verwendeten sie Aufforderungswörter und Rubriken aus einem Standard-Repository. Diese Testressourcen stammen aus dem Datensatz, der mit der Modellfreigabe und dem Evaluierungstool Eleuther usw. geliefert wird. Zu den Aufforderungswörtern gehören normalerweise Abfragen, Eingaben, eine kleine Anzahl von Beispielen, Überlegungen zur Denkkette usw. In einigen Sondergutachten stellten die Autoren fest, dass geringfügige Anpassungen der Standardpraktiken erforderlich seien. Die Anpassung der Voreingenommenheit wurde im entsprechenden Code-Repository durchgeführt. Weitere Informationen finden Sie im Originalpapier. Die Ziele dieser Forschung sind wie folgt: 1. Bereitstellung eines objektiven Vergleichs der Fähigkeiten von OpenAI GPT- und Google Gemini-Modellen durch Dritte durch reproduzierbaren Code und vollständig transparente Ergebnisse. 2. Studieren Sie die Bewertungsergebnisse eingehend und analysieren Sie, in welchen Bereichen die beiden Modelle besser abschneiden. Wissensbasierte Qualitätssicherung Der Autor hat 57 wissensbasierte Multiple-Choice-Frage- und Antwortaufgaben aus dem MMLU-Datensatz ausgewählt, die die Themen MINT, Geistes- und Sozialwissenschaften usw. abdecken. MMLU verfügt über insgesamt 14.042 Testbeispiele und wird häufig verwendet, um eine Gesamtbewertung der Wissensfähigkeiten großer Sprachmodelle bereitzustellen. Der Autor verglich und analysierte die Gesamtleistung der vier Testobjekte auf MMLU (wie in der Abbildung unten dargestellt), die Leistung der Unteraufgaben und den Einfluss der Ausgabelänge auf die Leistung. Abbildung 1: Gesamtgenauigkeit jedes Modells auf MMLU unter Verwendung von 5 Beispiel-Eingabeaufforderungen und Gedankenketten-Eingabeaufforderungen. Wie Sie der Abbildung entnehmen können, ist die Genauigkeit von Gemini Pro geringer als die von GPT 3.5 Turbo und viel geringer als die von GPT 4 Turbo.Bei Verwendung der Denkketten-Eingabeaufforderung gibt es kaum Unterschiede in der Leistung der einzelnen Modelle. Die Autoren vermuten, dass dies auf die Tatsache zurückzuführen ist, dass MMLU in erster Linie wissensbasierte Frage- und Antwortaufgaben erfasst, die möglicherweise nicht wesentlich von stärker argumentationsorientierten Eingabeaufforderungen profitieren. Es ist erwähnenswert, dass alle Fragen in MMLU Multiple-Choice-Fragen mit vier möglichen Antworten A bis D sind, die in der richtigen Reihenfolge angeordnet sind. Die folgende Grafik zeigt den Anteil der einzelnen Antwortoptionen, die von jedem Modell ausgewählt wurden. Aus der Abbildung können Sie ersehen, dass die Antwortverteilung von Gemini stark in Richtung der Wahl der letzten D-Option tendiert. Dies steht im Gegensatz zu den ausgewogeneren Ergebnissen, die GPT-Versionen liefern. Dies kann darauf hindeuten, dass Gemini nicht die umfassenden Anpassungen der Anweisungen erhalten hat, die mit Multiple-Choice-Fragen einhergehen, was zu einer Verzerrung der Antwortrangfolge des Modells führt. Abbildung 2: Anteil der vom getesteten Modell vorhergesagten Antworten auf Multiple-Choice-Fragen.
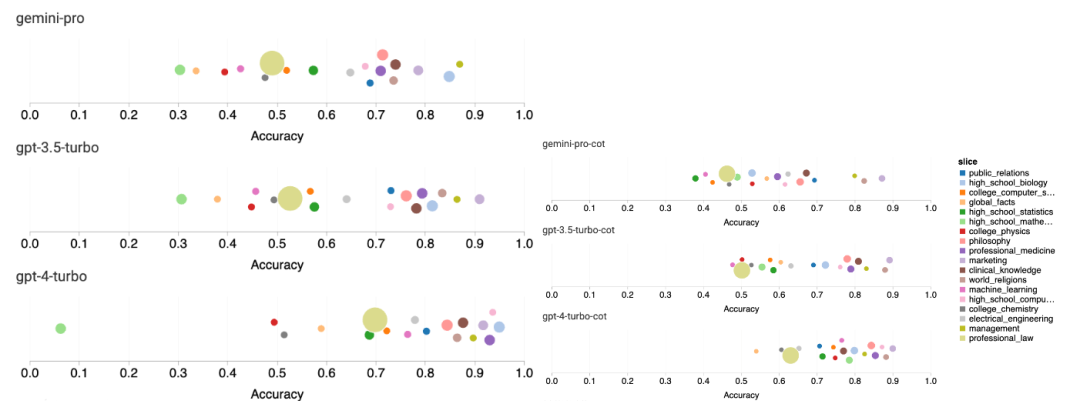
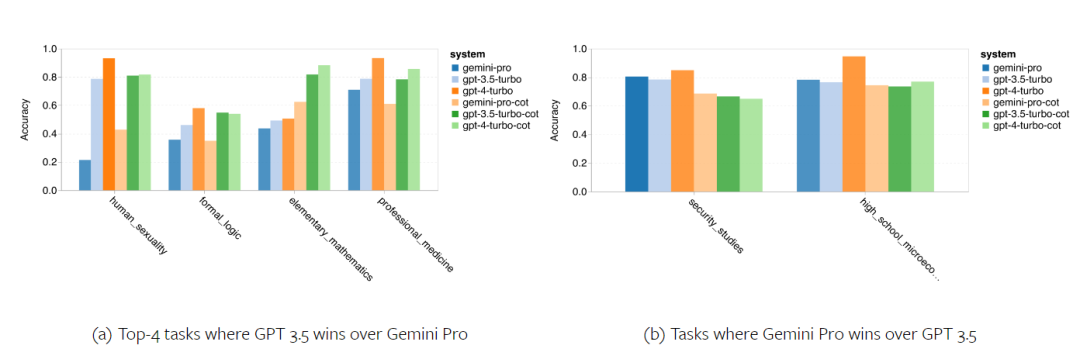
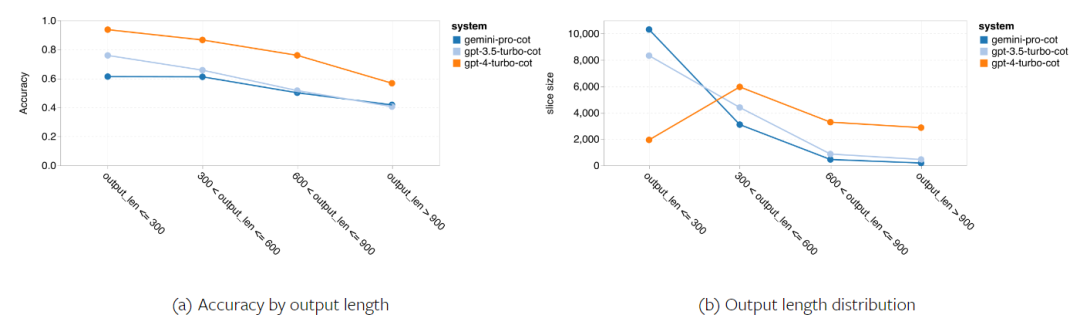
Die folgende Abbildung zeigt die Leistung des getesteten Modells bei der Unteraufgabe des MMLU-Testsatzes. Gemini Pro schneidet bei den meisten Aufgaben im Vergleich zu GPT 3.5 schlecht ab. Gedankenkettenaufforderungen verringern die Varianz zwischen Teilaufgaben. Abbildung 3: Genauigkeit des getesteten Modells bei jeder Teilaufgabe. Der Autor wirft einen detaillierten Blick auf die Stärken und Schwächen von Gemini Pro. Wie in Abbildung 4 zu sehen ist, liegt Gemini Pro in den Aufgaben Menschliches Geschlecht (Sozialwissenschaften), Formale Logik (Geisteswissenschaften), Elementare Mathematik (STEM) und Professionelle Medizin (Berufsfelder) hinter GPT 3.5 zurück. Auch bei den beiden Aufgaben, bei denen das Gemini Pro besser ist, ist der Vorsprung gering. Abbildung 4: Vorteile von Gemini Pro und GPT 3.5 bei MMLU-Aufgaben. Die schlechte Leistung des Gemini Pro bei bestimmten Aufgaben kann auf zwei Gründe zurückgeführt werden. Erstens gibt es Situationen, in denen Zwillinge keine Antwort geben können. In den meisten MMLU-Unteraufgaben liegt die API-Antwortrate über 95 %, die entsprechenden Raten sind jedoch bei den beiden Aufgaben Moral (Antwortrate 85 %) und menschliches Geschlecht (Antwortrate 28 %) deutlich niedriger. Dies deutet darauf hin, dass die geringere Leistung von Gemini bei einigen Aufgaben möglicherweise auf Eingabeinhaltsfilter zurückzuführen ist. Zweitens schneidet der Gemini Pro beim grundlegenden mathematischen Denken, das zur Lösung formaler Logik und grundlegender mathematischer Aufgaben erforderlich ist, etwas schlechter ab. Der Autor analysierte auch, wie sich die Ausgabelänge in der Eingabeaufforderung der Gedankenkette auf die Modellleistung auswirkt, wie in Abbildung 5 dargestellt. Im Allgemeinen führen leistungsfähigere Modelle tendenziell komplexere Überlegungen durch und geben daher längere Antworten aus. Der Gemini Pro hat gegenüber seinen „Gegnern“ einen bemerkenswerten Vorteil: Seine Genauigkeit wird weniger von der Ausgabelänge beeinflusst. Gemini Pro übertrifft sogar GPT 3.5, wenn die Ausgabelänge 900 überschreitet. Im Vergleich zu GPT 4 Turbo geben Gemini Pro und GPT 3.5 Turbo jedoch selten lange Inferenzketten aus. Abbildung 5: Ausgabelängenanalyse des getesteten Modells auf MMLU.
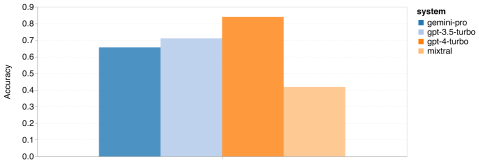
Im BIG-Bench Hard-Testset führte der Autor eine Bewertung der Fähigkeit zum allgemeinen Denken der getesteten Probanden durch. BIG-Bench Hard enthält 27 verschiedene Denkaufgaben wie arithmetisches, symbolisches und mehrsprachiges Denken, Verstehen von Faktenwissen und mehr. Die meisten Aufgaben bestehen aus 250 Frage-Antwort-Paaren, wobei einige Aufgaben etwas weniger Fragen enthalten. Abbildung 6 zeigt die Gesamtgenauigkeit des getesteten Modells. Es ist ersichtlich, dass die Genauigkeit von Gemini Pro etwas geringer ist als die von GPT 3.5 Turbo und viel geringer als die von GPT 4 Turbo. Im Vergleich dazu ist die Genauigkeit des Mixtral-Modells viel geringer. Abbildung 6: Gesamtgenauigkeit des getesteten Modells auf BIG-Bench-Hard.
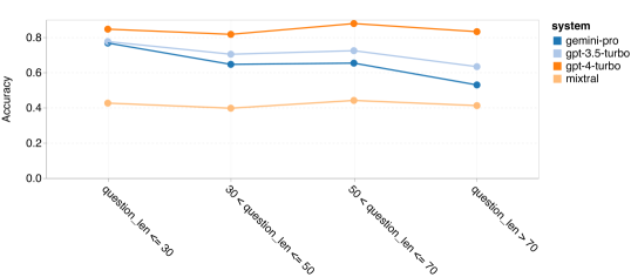
Der Autor geht näher darauf ein, warum die allgemeine Schlussfolgerung von Zwillingen insgesamt schlecht abschneidet. Zunächst untersuchten sie die Genauigkeit anhand der Fragenlänge. Wie in Abbildung 7 dargestellt, schneidet Gemini Pro bei längeren, komplexeren Problemen schlecht ab. Und das GPT-Modell, insbesondere GPT 4 Turbo, selbst bei sehr langen Problemen ist die Regression von GPT 4 Turbo sehr gering. Dies zeigt, dass es robust und in der Lage ist, längere und komplexere Fragen und Abfragen zu verstehen. Die Robustheit des GPT 3.5 Turbo ist durchschnittlich. Mixtral schnitt im Hinblick auf die Fragenlänge stabil ab, hatte jedoch insgesamt eine geringere Genauigkeit.Abbildung 7: Genauigkeit des getesteten Modells auf BIG-Bench-Hard nach Fragenlänge.
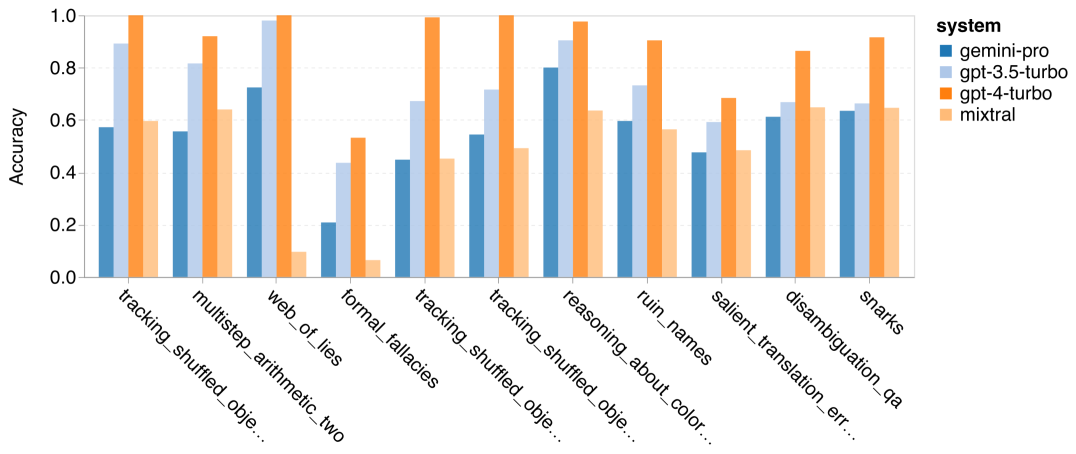
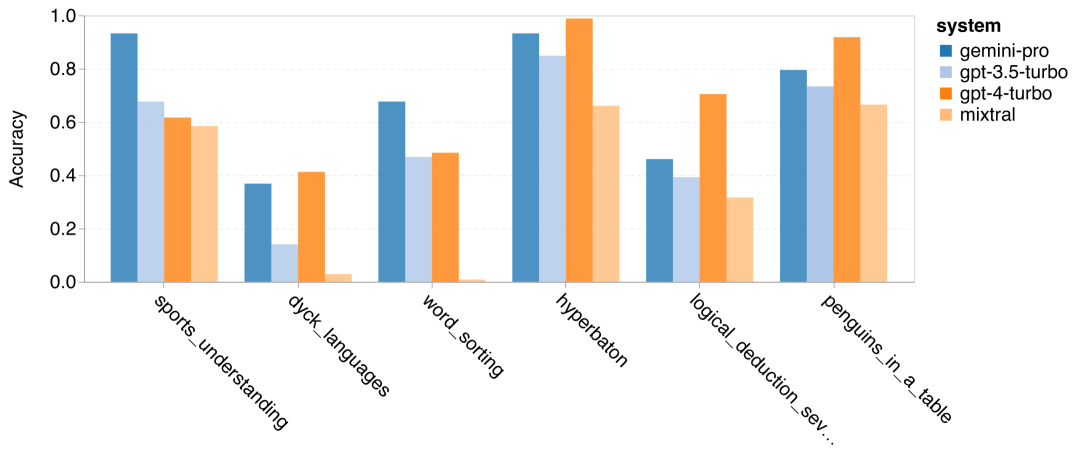
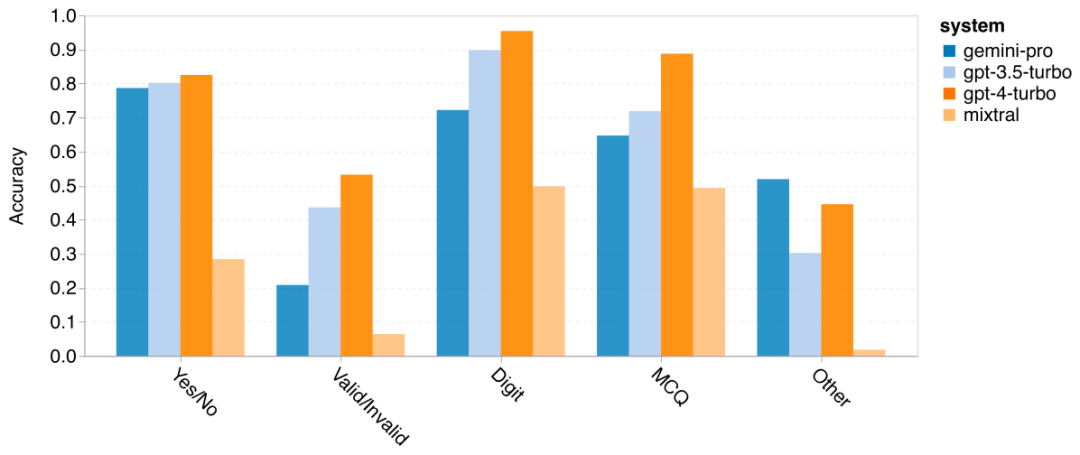
Der Autor analysierte, ob es einen Unterschied in der Genauigkeit des getesteten Modells bei der spezifischen BIG-Bench-Hard-Aufgabe gibt. Abbildung 8 zeigt, welche Aufgaben GPT 3.5 Turbo besser meistert als Gemini Pro. Bei der Aufgabe „Position transformierter Objekte verfolgen“ schnitt Gemini Pro besonders schlecht ab. Zu diesen Aufgaben gehört es, Gegenstände auszutauschen und nachzuverfolgen, wem etwas gehört, aber Gemini Pro hatte oft Schwierigkeiten, die Reihenfolge einzuhalten. Abbildung 8: GPT 3.5 Turbo übertrifft Gemini Pro bei der Unteraufgabe BIG-Bench-Hard. Gemini Pro ist Mixtral bei Aufgaben wie Rechenaufgaben, die mehrstufige Lösungen erfordern, beim Finden von Übersetzungsfehlern usw. unterlegen. Es gibt auch Aufgaben, bei denen Gemini Pro besser ist als GPT 3.5 Turbo. Abbildung 9 zeigt die sechs Aufgaben, bei denen Gemini Pro GPT 3.5 Turbo mit dem größten Vorsprung anführt. Die Aufgaben sind heterogen und umfassen solche, die Weltkenntnisse erfordern (sports_understanding), das Manipulieren von Symbolstapeln (dyck_linguals), das alphabetische Sortieren von Wörtern (word_sorting) und das Parsen von Tabellen (penguins_in_a_table). Abbildung 9: Gemini Pro übertrifft GPT 3.5 bei der Unteraufgabe BIG-Bench-Hard. Der Autor analysierte die Robustheit des getesteten Modells in verschiedenen Antworttypen weiter, wie in Abbildung 10 dargestellt. Am schlechtesten schnitt Gemini Pro beim Antworttyp „Gültig/Ungültig“ ab, der zur Aufgabe formal_fallacies gehört. Interessanterweise gab es bei dieser Aufgabe auf 68,4 % der Fragen keine Antwort. Bei anderen Antworttypen (bestehend aus Wortsortierungs- und Dyck_Language-Aufgaben) übertrifft Gemini Pro jedoch alle GPT-Modelle und Mixtral. Das heißt, Gemini Pro ist besonders gut darin, Wörter neu anzuordnen und Symbole in der richtigen Reihenfolge zu erzeugen. Darüber hinaus wurden bei MCQ-Antworten 4,39 % der Fragen von Gemini Pro für die Beantwortung blockiert. Die GPT-Modelle zeichnen sich in diesem Bereich aus, und das Gemini Pro hat Mühe, mit ihnen zu konkurrieren. Abbildung 10: Genauigkeit des getesteten Modells nach Antworttyp auf BIG-Bench-Hard.
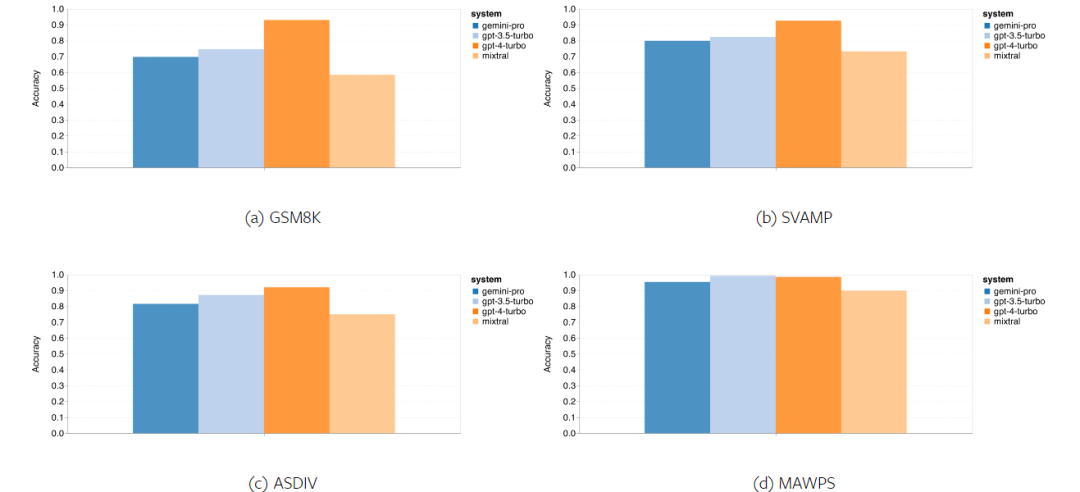
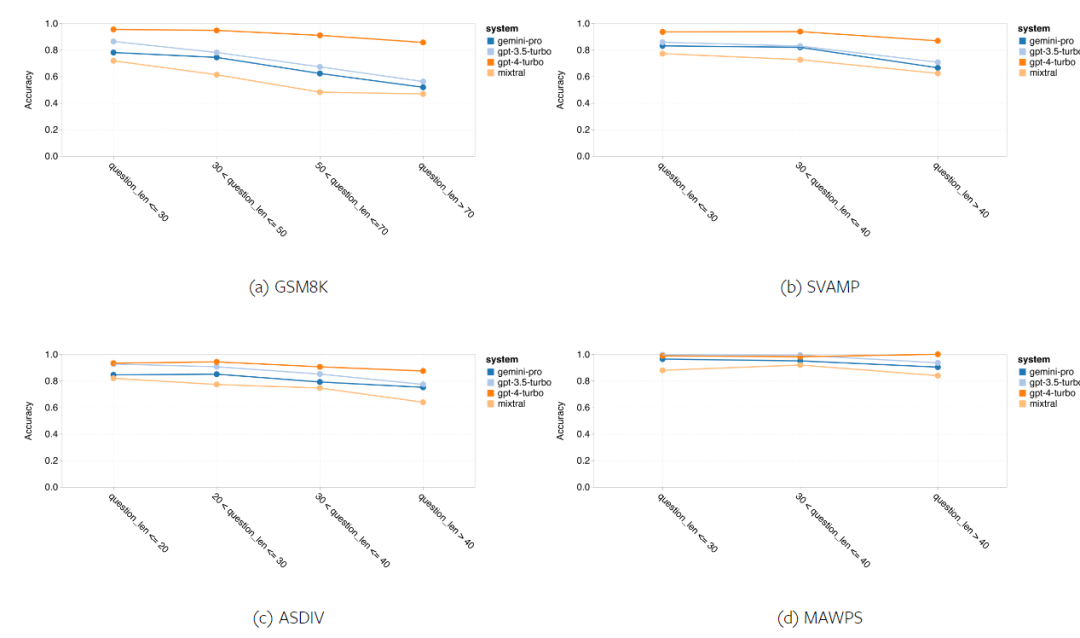
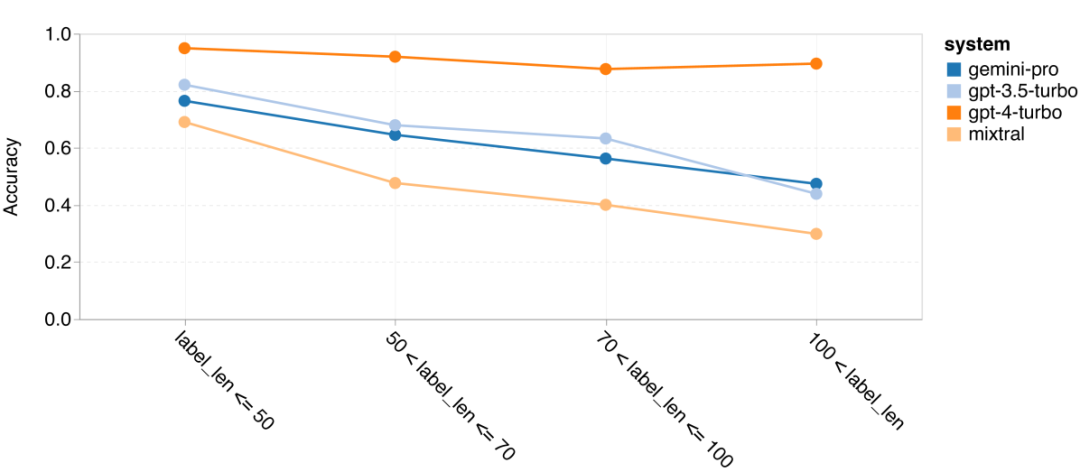
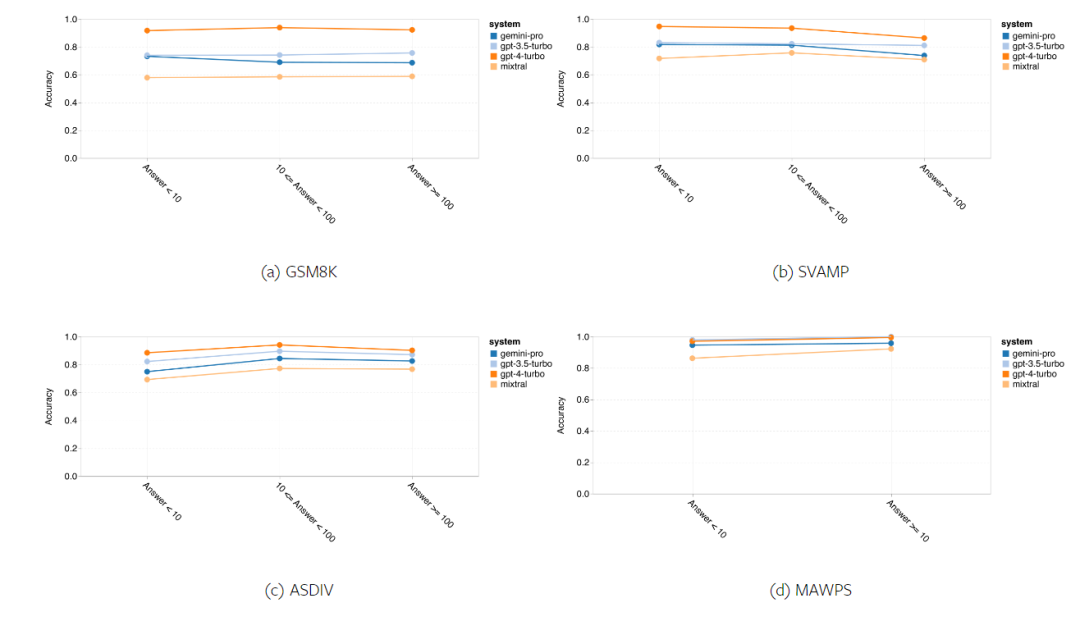
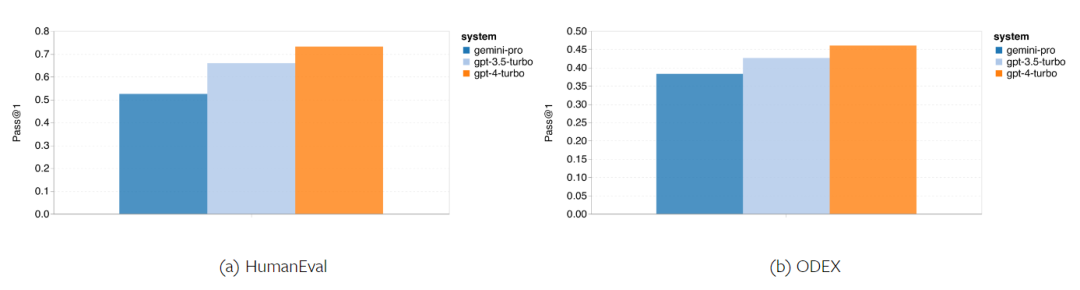
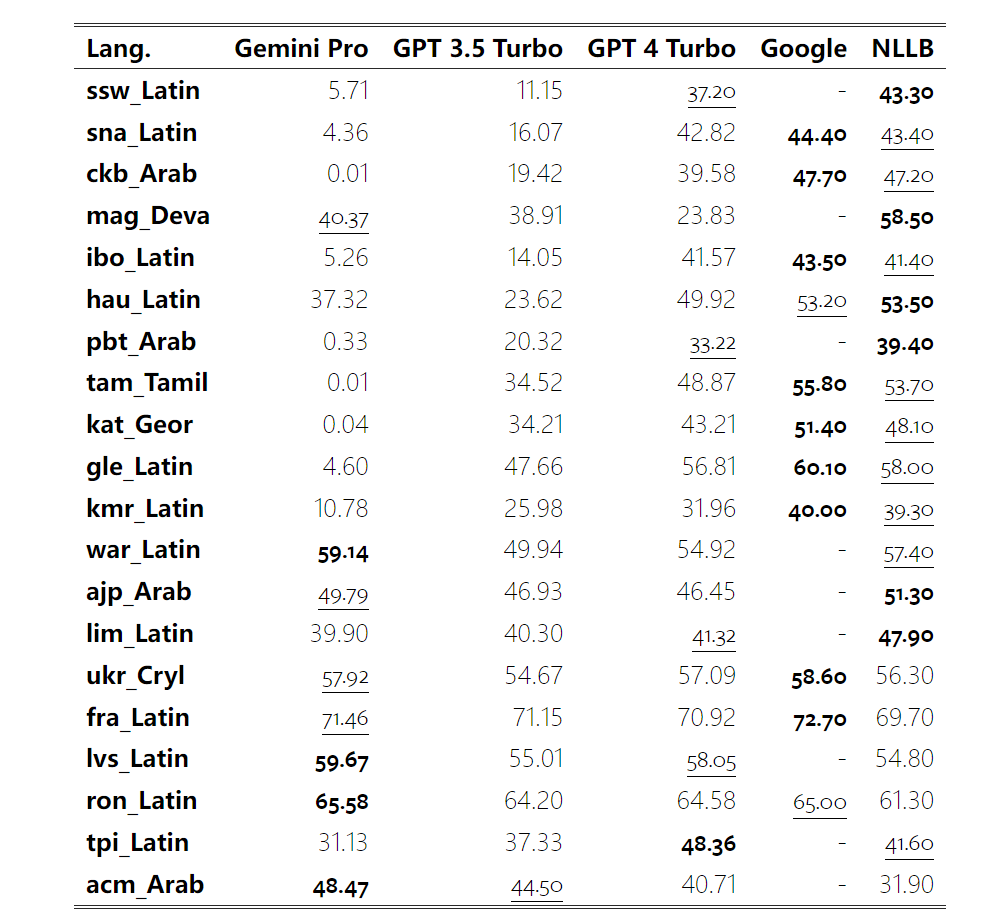
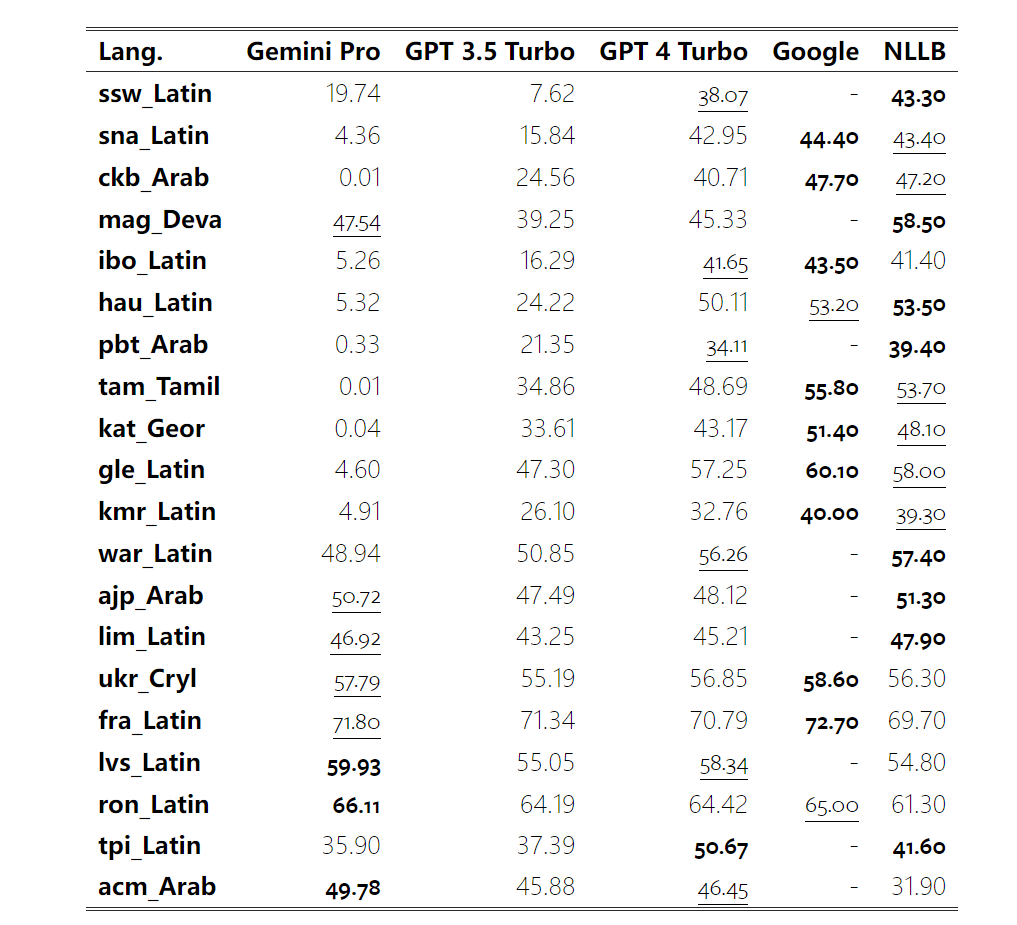
Kurz gesagt, kein Modell scheint bei einer bestimmten Aufgabe führend zu sein. Daher lohnt es sich bei der Durchführung allgemeiner Inferenzaufgaben, sowohl das Gemini- als auch das GPT-Modell auszuprobieren, bevor Sie sich für ein Modell entscheiden. Mathematische Fähigkeiten Um die mathematische Denkfähigkeit des getesteten Modells zu bewerten, wählte der Autor vier Benchmark-Sets für mathematische Probleme aus: (1) GSM8K: Mathematik-Benchmark für Grundschulen ; (2) SVAMP: Überprüfen Sie die Fähigkeit zum logischen Denken durch Ändern der Wortreihenfolge. (3) ASDIV: Mit verschiedenen Sprachmodi und Fragetypen. (4) MAWPS: Enthält arithmetische und algebraische Wortaufgaben. Der Autor verglich die Genauigkeit von Gemini Pro, GPT 3.5 Turbo, GPT 4 Turbo und Mixtral anhand von vier mathematischen Problemtestsätzen und überprüfte deren Gesamtleistung, Leistung bei unterschiedlicher Problemkomplexität und unterschiedlicher Denkketten. Leistung im Detail. Abbildung 11 zeigt die Gesamtergebnisse. Die Genauigkeit von Gemini Pro ist etwas geringer als die von GPT 3.5 Turbo und viel geringer als die von GPT 4 Turbo bei Aufgaben wie GSM8K, SVAMP und ASDIV mit verschiedenen Sprachmodi. Bei den Aufgaben in MAWPS ist Gemini Pro dem GPT-Modell noch etwas unterlegen, obwohl alle getesteten Modelle eine Genauigkeit von über 90 % erreichen. Bei dieser Aufgabe übertrifft GPT 3.5 Turbo GPT 4 Turbo knapp. Im Vergleich dazu ist die Genauigkeit des Mixtral-Modells viel geringer als die der anderen Modelle. Abbildung 11: Gesamtgenauigkeit des getesteten Modells in vier Testsatzaufgaben zum mathematischen Denken. Die Robustheit jedes Modells gegenüber der Problemlänge ist in Abbildung 12 dargestellt. Ähnlich wie bei den Inferenzaufgaben in BIG-Bench Hard zeigte das getestete Modell eine verringerte Genauigkeit bei der Beantwortung längerer Fragen.GPT 3.5 Turbo schneidet bei kürzeren Fragen besser ab als Gemini Pro, bildet sich jedoch schneller zurück, und bei längeren Fragen ist Gemini Pro hinsichtlich der Genauigkeit ähnlich wie GPT 3.5 Turbo, liegt aber immer noch leicht zurück. Abbildung 12: Die Genauigkeit des getesteten Modells bei der Generierung von Antworten für unterschiedliche Fragenlängen in vier Testsatzaufgaben zum mathematischen Denken. Darüber hinaus beobachteten die Autoren Unterschiede in der Genauigkeit der getesteten Modelle, wenn die Antwort eine längere Gedankenkette erforderte. Wie in Abbildung 13 dargestellt, ist GPT 4 Turbo selbst bei Verwendung langer Inferenzketten sehr robust, während GPT 3.5 Turbo, Gemini Pro und Mixtral Einschränkungen aufweisen, wenn die COT-Länge zunimmt. Durch die Analyse stellten die Autoren außerdem fest, dass Gemini Pro GPT 3.5 Turbo in komplexen Beispielen mit COT-Längen über 100 übertraf, in kürzeren Beispielen jedoch eine schlechte Leistung erbrachte. Abbildung 13: Genauigkeit jedes Modells auf GSM8K bei unterschiedlichen Denkkettenlängen. Abbildung 14 zeigt die Genauigkeit des getesteten Modells bei der Generierung von Antworten für unterschiedliche Anzahlen von Ziffern. Die Autoren erstellten drei „Buckets“ basierend darauf, ob die Antwort 1, 2, 3 oder mehr Ziffern enthielt (mit Ausnahme der MAWPS-Aufgabe, bei der es keine Antworten mit mehr als zwei Ziffern gab). Wie in der Abbildung gezeigt, scheint GPT 3.5 Turbo bei mehrstelligen mathematischen Problemen robuster zu sein, während Gemini Pro bei Problemen mit höheren Zahlen nachlässt. Abbildung 14: Genauigkeit jedes Modells in vier Testaufgaben zum mathematischen Denken, wenn die Anzahl der Antwortziffern unterschiedlich ist. In diesem Teil verwendet der Autor zwei Codegenerierungsdatensätze – HumanEval und ODEX –, um die Codierungsfähigkeit des Modells zu testen. Ersteres testet das grundlegende Codeverständnis eines Modells für einen begrenzten Satz von Funktionen in der Python-Standardbibliothek, und letzteres testet die Fähigkeit eines Modells, einen breiteren Satz von Bibliotheken im gesamten Python-Ökosystem zu verwenden. Der Input für beide Probleme sind Aufgabenanweisungen in englischer Sprache (normalerweise mit Testfällen). Diese Fragen werden verwendet, um das Sprachverständnis, das Algorithmusverständnis und die elementaren Mathematikfähigkeiten des Modells zu bewerten. Insgesamt verfügt HumanEval über 164 Testproben und ODEX über 439 Testproben. Erstens können wir aus den in Abbildung 15 dargestellten Gesamtergebnissen erkennen, dass die Pass@1-Werte von Gemini Pro bei beiden Aufgaben niedriger sind als bei GPT 3.5 Turbo und viel niedriger als bei GPT 4 Turbo. Diese Ergebnisse deuten darauf hin, dass die Codegenerierungsfähigkeiten von Gemini Raum für Verbesserungen bieten. Abbildung 15: Gesamtgenauigkeit jedes Modells in der Codegenerierungsaufgabe. Zweitens analysierte der Autor die Beziehung zwischen der Goldlösungslänge und der Modellleistung in Abbildung 16 (a). Die Länge der Lösung kann bis zu einem gewissen Grad Aufschluss über die Schwierigkeit der entsprechenden Codegenerierungsaufgabe geben. Die Autoren stellen fest, dass Gemini Pro Pass@1-Werte erreicht, die mit GPT 3.5 vergleichbar sind, wenn die Lösungslänge unter 100 liegt (wie im einfacheren Fall), bei längerer Lösungslänge jedoch deutlich zurückbleibt. Dies ist ein interessanter Kontrast zu den Ergebnissen der vorherigen Abschnitte, in denen die Autoren herausfanden, dass Gemini Pro im Allgemeinen robust gegenüber längeren Ein- und Ausgaben bei englischen Aufgaben war. 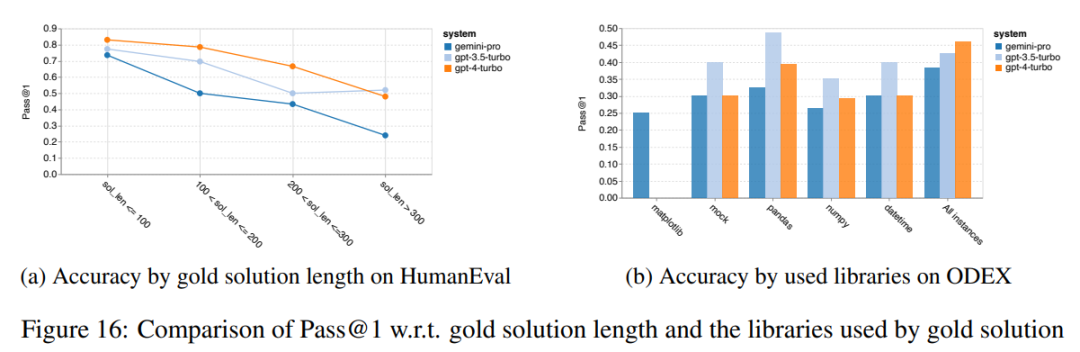 Der Autor analysierte auch die Auswirkungen der für jede Lösung erforderlichen Bibliotheken auf die Modellleistung in Abbildung 16(b). In den meisten Bibliotheksanwendungsfällen, wie Mocks, Pandas, Numpy und Datetime, schneidet Gemini Pro schlechter ab als GPT 3.5. Im Anwendungsfall von matplotlib übertrifft es jedoch GPT 3.5 und GPT 4, was auf seine größere Fähigkeit hinweist, Plotvisualisierungen durch Code durchzuführen. Abschließend zeigt der Autor mehrere konkrete Fehlerfälle, bei denen Gemini Pro bei der Codegenerierung schlechter abschneidet als GPT 3.5. Zunächst stellten sie fest, dass Gemini bei der korrekten Auswahl von Funktionen und Parametern in der Python-API etwas schlechter war.Zum Beispiel mit der folgenden Eingabeaufforderung: Gemini Pro generierte den folgenden Code, der zu einem Typkonfliktfehler führte: Im Gegensatz dazu verwendete GPT 3.5 Turbo den folgenden Code, der den gewünschten Effekt erzielte: Darüber hinaus weist Gemini Pro einen höheren Prozentsatz an Fehlern auf, bei denen der ausgeführte Code zwar syntaktisch korrekt ist, aber nicht korrekt mit komplexeren Absichten übereinstimmt. Zum Beispiel zu den folgenden Tipps: Gemini Pro hat eine Implementierung erstellt, die nur eindeutige Zahlen extrahiert, ohne mehrfach vorkommende Zahlen zu entfernen. Diese Reihe von Experimenten verwendet den FLORES-200-Benchmark für maschinelle Übersetzung, um die mehrsprachigen Fähigkeiten des Modells zu bewerten, insbesondere seine Fähigkeit, zwischen verschiedenen Sprachpaaren zu übersetzen. Die Autoren konzentrieren sich auf eine andere Teilmenge der 20 in der Analyse von Robinson et al. (2023) verwendeten Sprachen und decken unterschiedliche Grade der Ressourcenverfügbarkeit und Übersetzungsschwierigkeiten ab. Die Autoren bewerteten 1012 Sätze im Testsatz für alle ausgewählten Sprachpaare. In den Tabellen 4 und 5 führt der Autor eine vergleichende Analyse von Gemini Pro, GPT 3.5 Turbo und GPT 4 Turbo mit ausgereiften Systemen wie Google Translate durch. Darüber hinaus haben sie NLLB-MoE verglichen, ein führendes Open-Source-Modell für maschinelle Übersetzung, das für seine breite Sprachabdeckung bekannt ist. Die Ergebnisse zeigen, dass Google Translate die anderen Modelle insgesamt übertrifft und in 9 Sprachen eine gute Leistung erbringt, gefolgt von NLLB, das in 6/8 Sprachen unter der 0/5-Schuss-Einstellung eine gute Leistung erbringt. Allzweck-Sprachmodelle haben eine konkurrenzfähige Leistung gezeigt, haben jedoch spezialisierte maschinelle Übersetzungssysteme bei der Übersetzung in nicht-englische Sprachen noch nicht übertroffen. Tabelle 4: Leistung (chRF (%)-Score) jedes Modells für maschinelle Übersetzung in allen Sprachen unter Verwendung von 0-Shot-Hinweisen. Das beste Ergebnis wird fett dargestellt und das nächstbeste Ergebnis ist unterstrichen.
Der Autor analysierte auch die Auswirkungen der für jede Lösung erforderlichen Bibliotheken auf die Modellleistung in Abbildung 16(b). In den meisten Bibliotheksanwendungsfällen, wie Mocks, Pandas, Numpy und Datetime, schneidet Gemini Pro schlechter ab als GPT 3.5. Im Anwendungsfall von matplotlib übertrifft es jedoch GPT 3.5 und GPT 4, was auf seine größere Fähigkeit hinweist, Plotvisualisierungen durch Code durchzuführen. Abschließend zeigt der Autor mehrere konkrete Fehlerfälle, bei denen Gemini Pro bei der Codegenerierung schlechter abschneidet als GPT 3.5. Zunächst stellten sie fest, dass Gemini bei der korrekten Auswahl von Funktionen und Parametern in der Python-API etwas schlechter war.Zum Beispiel mit der folgenden Eingabeaufforderung: Gemini Pro generierte den folgenden Code, der zu einem Typkonfliktfehler führte: Im Gegensatz dazu verwendete GPT 3.5 Turbo den folgenden Code, der den gewünschten Effekt erzielte: Darüber hinaus weist Gemini Pro einen höheren Prozentsatz an Fehlern auf, bei denen der ausgeführte Code zwar syntaktisch korrekt ist, aber nicht korrekt mit komplexeren Absichten übereinstimmt. Zum Beispiel zu den folgenden Tipps: Gemini Pro hat eine Implementierung erstellt, die nur eindeutige Zahlen extrahiert, ohne mehrfach vorkommende Zahlen zu entfernen. Diese Reihe von Experimenten verwendet den FLORES-200-Benchmark für maschinelle Übersetzung, um die mehrsprachigen Fähigkeiten des Modells zu bewerten, insbesondere seine Fähigkeit, zwischen verschiedenen Sprachpaaren zu übersetzen. Die Autoren konzentrieren sich auf eine andere Teilmenge der 20 in der Analyse von Robinson et al. (2023) verwendeten Sprachen und decken unterschiedliche Grade der Ressourcenverfügbarkeit und Übersetzungsschwierigkeiten ab. Die Autoren bewerteten 1012 Sätze im Testsatz für alle ausgewählten Sprachpaare. In den Tabellen 4 und 5 führt der Autor eine vergleichende Analyse von Gemini Pro, GPT 3.5 Turbo und GPT 4 Turbo mit ausgereiften Systemen wie Google Translate durch. Darüber hinaus haben sie NLLB-MoE verglichen, ein führendes Open-Source-Modell für maschinelle Übersetzung, das für seine breite Sprachabdeckung bekannt ist. Die Ergebnisse zeigen, dass Google Translate die anderen Modelle insgesamt übertrifft und in 9 Sprachen eine gute Leistung erbringt, gefolgt von NLLB, das in 6/8 Sprachen unter der 0/5-Schuss-Einstellung eine gute Leistung erbringt. Allzweck-Sprachmodelle haben eine konkurrenzfähige Leistung gezeigt, haben jedoch spezialisierte maschinelle Übersetzungssysteme bei der Übersetzung in nicht-englische Sprachen noch nicht übertroffen. Tabelle 4: Leistung (chRF (%)-Score) jedes Modells für maschinelle Übersetzung in allen Sprachen unter Verwendung von 0-Shot-Hinweisen. Das beste Ergebnis wird fett dargestellt und das nächstbeste Ergebnis ist unterstrichen.
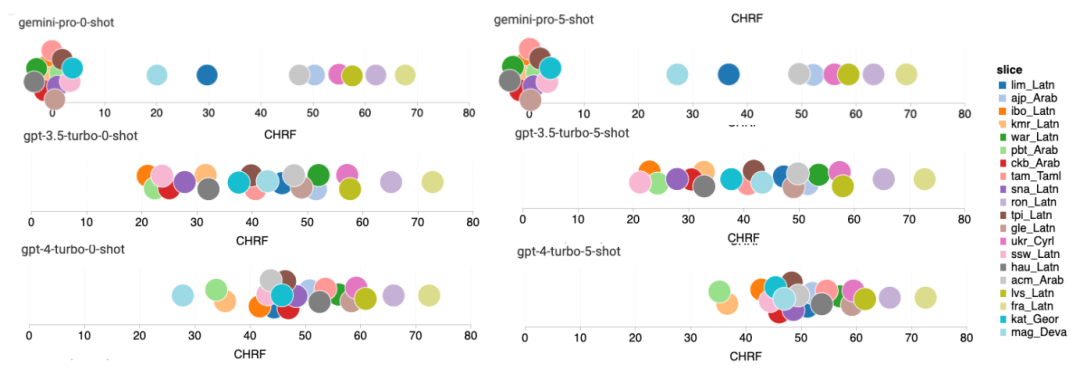
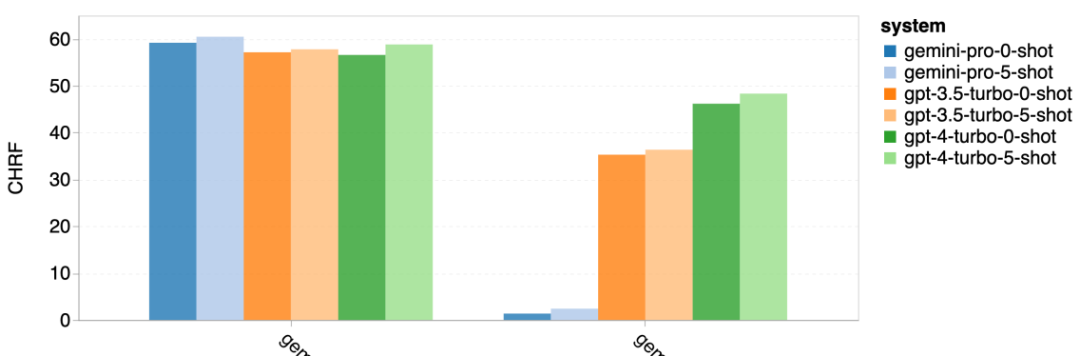
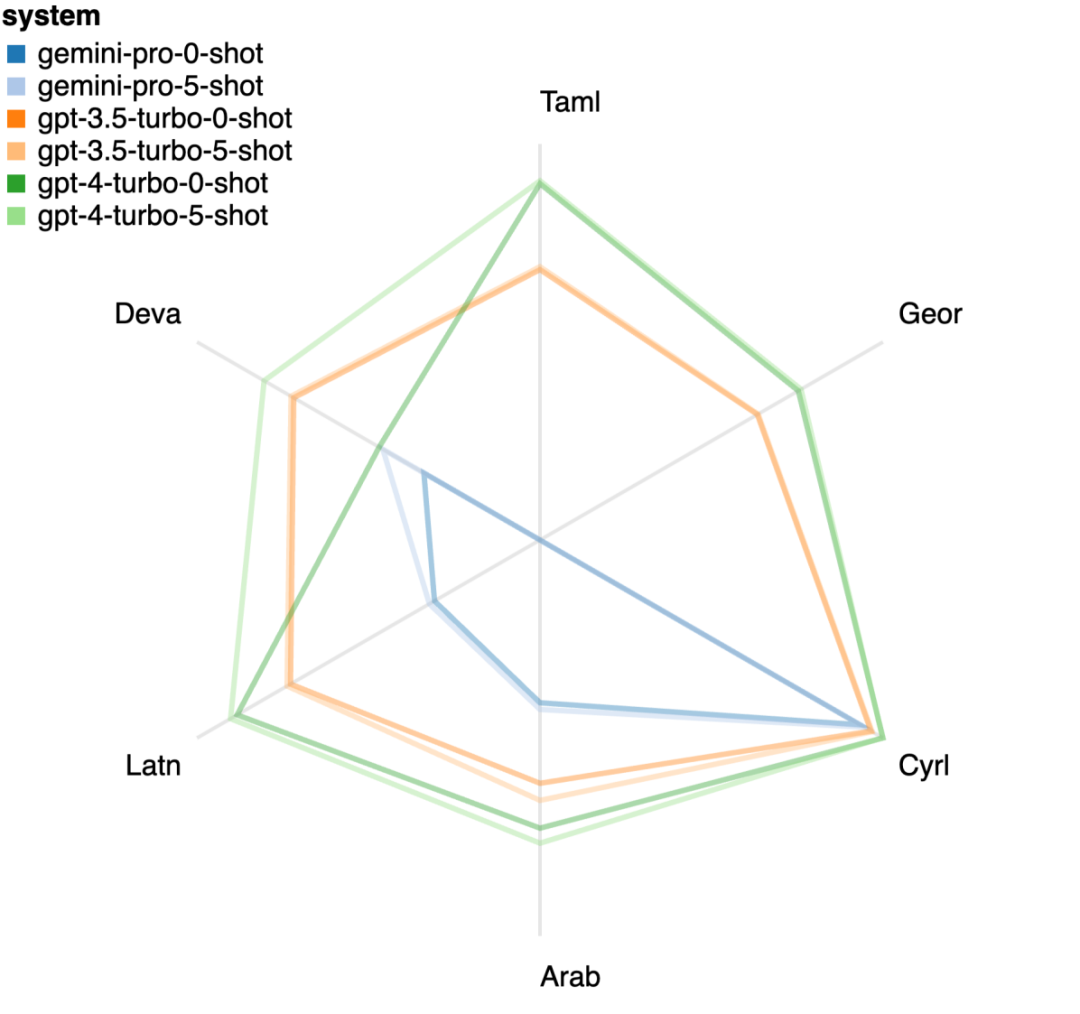
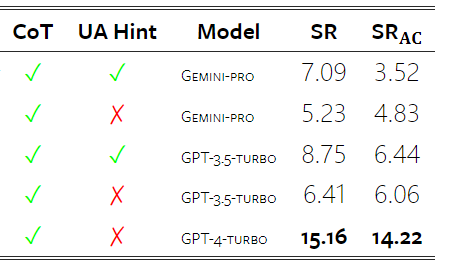
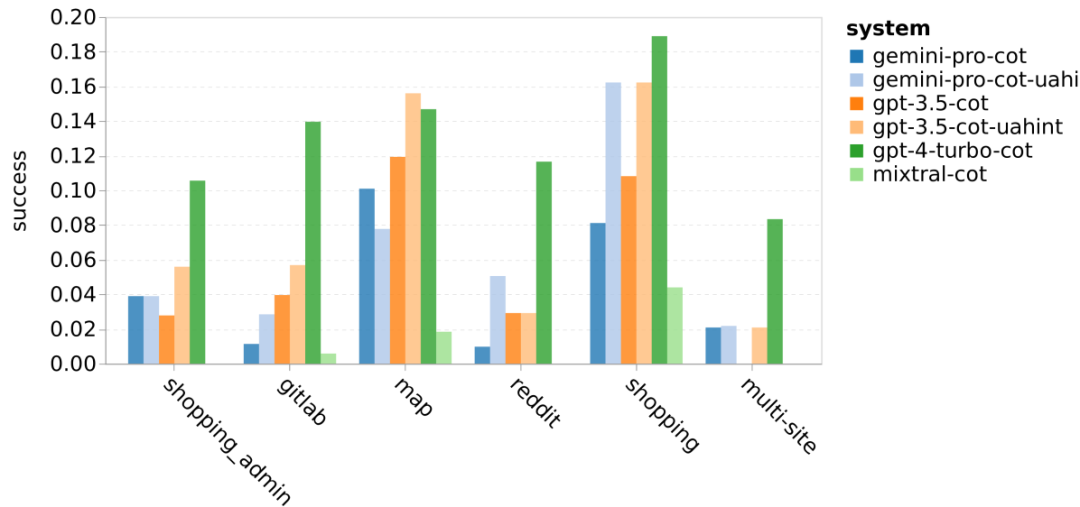
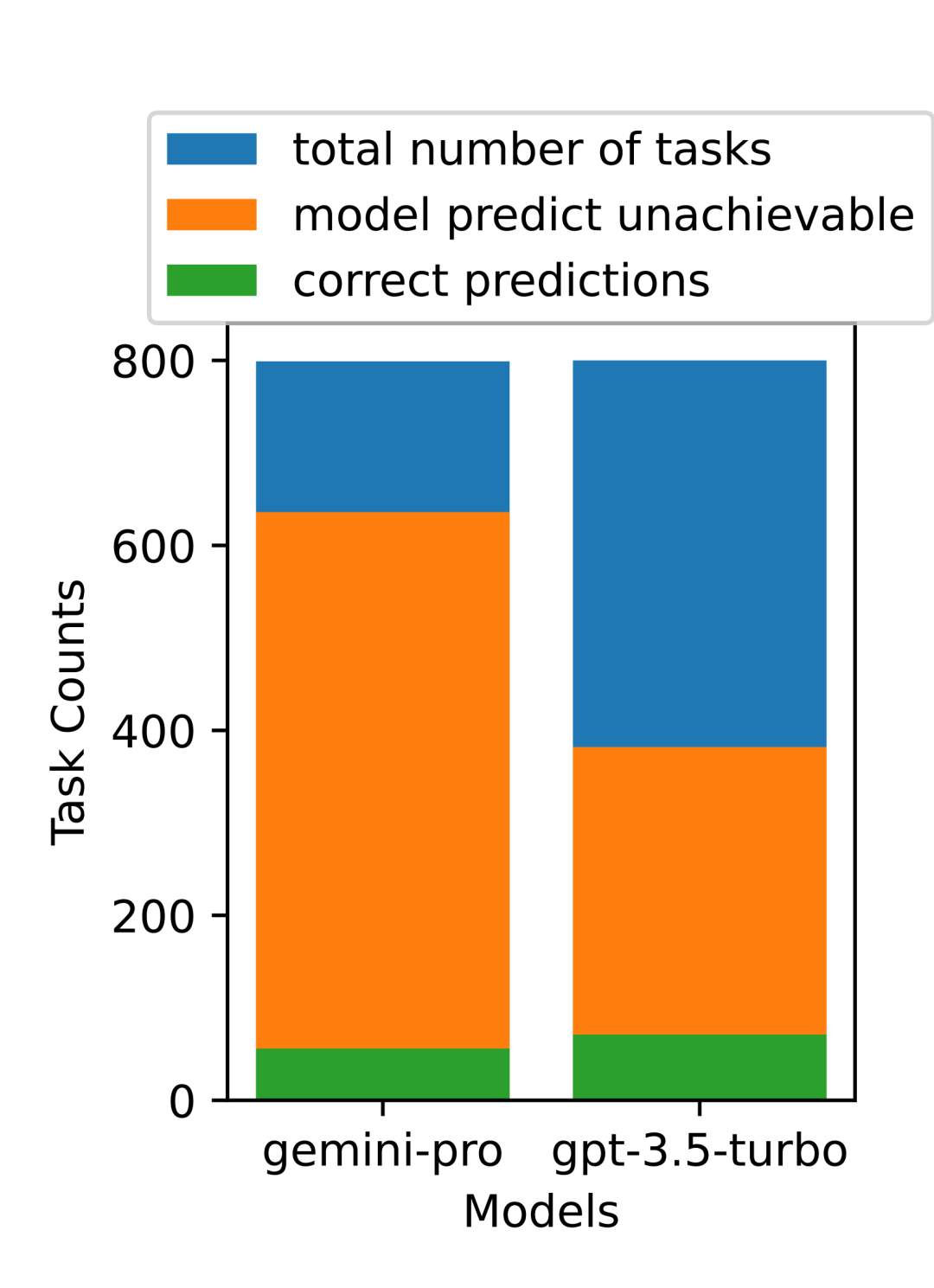
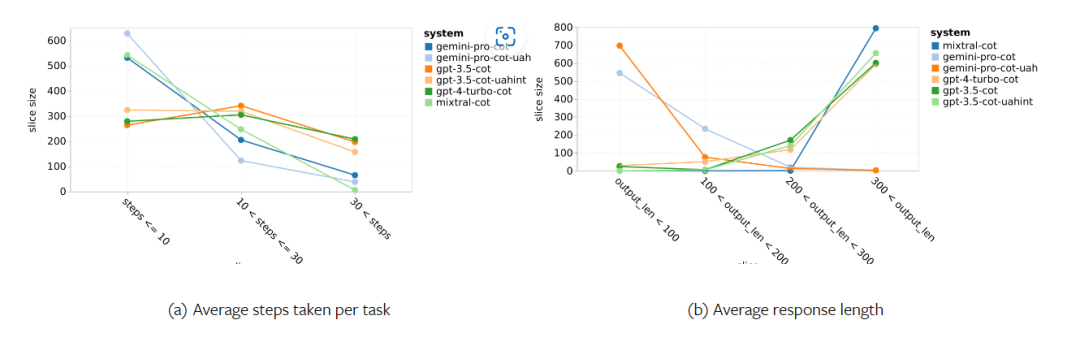
Tabelle 5: Leistung (chRF (%)-Score) jedes Modells für die maschinelle Übersetzung unter Verwendung von 5-Schuss-Hinweisen für alle Sprachen. Das beste Ergebnis wird fett dargestellt und das nächstbeste Ergebnis ist unterstrichen. Abbildung 17 zeigt den Leistungsvergleich des allgemeinen Sprachmodells über verschiedene Sprachpaare hinweg. GPT 4 Turbo weist im Vergleich zu GPT 3.5 Turbo und Gemini Pro eine konsistente Leistungsverzerrung mit NLLB auf. GPT 4 Turbo bietet auch größere Verbesserungen in ressourcenarmen Sprachen, während in ressourcenreichen Sprachen die Leistung beider LLMs ähnlich ist. Im Vergleich dazu übertraf Gemini Pro GPT 3.5 Turbo und GPT 4 Turbo in 8 von 20 Sprachen und erzielte in 4 Sprachen die Spitzenleistung. Allerdings zeigte Gemini Pro eine starke Tendenz, Antworten in etwa 10 Sprachpaaren zu blockieren. Abbildung 17: Leistung der maschinellen Übersetzung (chRF (%)-Score) nach Sprachpaaren. Abbildung 18 zeigt, dass Gemini Pro in diesen Sprachen eine geringere Leistung aufweist, da es dazu neigt, Antworten in Szenarien mit geringerem Vertrauen zu maskieren. Wenn Gemini Pro in einer 0-Schuss- oder 5-Schuss-Konfiguration den Fehler „Blockierte Antwort“ generiert, gilt die Antwort als „blockiert“. Abbildung 18: Anzahl der von Gemini Pro blockierten Proben. Ein genauerer Blick auf Abbildung 19 zeigt, dass Gemini Pro GPT 3.5 Turbo und GPT 4 Turbo im ungeschirmten Beispiel mit höherer Sicherheit leicht übertrifft.Insbesondere übertrifft es GPT 4 Turbo um 1,6 chrf bzw. 2,6 chrf bei 5-Schuss- bzw. 0-Schuss-Einstellungen und übertrifft GPT 3.5 Turbo um 2,7 chrf bzw. 2 chrf. Allerdings zeigt die vorläufige Analyse der Leistung von GPT 4 Turbo und GPT 3.5 Turbo durch die Autoren bei diesen Beispielen, dass die Übersetzung dieser Beispiele im Allgemeinen eine größere Herausforderung darstellt. Gemini Pro schneidet bei diesen spezifischen Samples schlecht ab, und es fällt besonders auf, dass der Gemini Pro 0-Schuss Reaktionen maskiert, während der 5-Schuss dies nicht tut, und umgekehrt. Abbildung 19: Chrf-Leistung (%) für maskierte und unmaskierte Proben. Während der Analyse des Modells stellte der Autor fest, dass Hinweise mit wenigen Schüssen die durchschnittliche Leistung im Allgemeinen moderat verbessern, mit zunehmenden Varianzmustern: GPT 4 Turbo Abbildung 20 zeigt klare Trends nach Sprachfamilie oder Schrift. Eine wichtige Beobachtung ist, dass der Gemini Pro mit anderen Modellen bei kyrillischer Schrift konkurrenzfähig ist, bei anderen Schriften jedoch nicht so gut. GPT-4 schneidet bei verschiedenen Skripten hervorragend ab und übertrifft andere Modelle, wobei Hinweise auf wenige Aufnahmen besonders effektiv sind. Dieser Effekt ist besonders deutlich in Sprachen, die Sanskrit verwenden. Abbildung 20: Leistung jedes Modells bei verschiedenen Skripten (chrf (%)). Abschließend untersuchen die Autoren die Fähigkeit jedes Modells als Netzwerknavigationsagent, eine Aufgabe, die langfristige Planung und komplexes Datenverständnis erfordert. Sie verwendeten eine Simulationsumgebung, WebArena, in der der Erfolg anhand der Ausführungsergebnisse gemessen wurde. Zu den dem Agenten zugewiesenen Aufgaben gehören Informationssuche, Website-Navigation sowie Inhalts- und Konfigurationsmanipulation. Die Aufgaben umfassen eine Vielzahl von Websites, darunter E-Commerce-Plattformen, soziale Foren, kollaborative Softwareentwicklungsplattformen (wie Gitlab), Content-Management-Systeme und Online-Karten. Die Autoren testeten die Gesamterfolgsquote von Gemini-Pro, die Erfolgsquote bei verschiedenen Aufgaben, die Antwortlänge, die Flugbahnschritte und die Tendenz, das Scheitern von Aufgaben vorherzusagen. Tabelle 6 listet die Gesamtleistung auf. Die Leistung von Gemini-Pro kommt der von GPT-3.5-Turbo nahe, ist aber etwas schlechter. Ähnlich wie GPT-3.5-Turbo schneidet Gemini-Pro besser ab, wenn im Hinweis erwähnt wird, dass die Aufgabe möglicherweise nicht abgeschlossen wird (UA-Hinweis). Mit UA-Hinweis hat Gemini-Pro eine Gesamterfolgsquote von 7,09 %. Tabelle 6: Leistung jedes Modells auf WebArena. Wenn Sie es nach Website-Typ aufschlüsseln, wie in Abbildung 21 dargestellt, können Sie sehen, dass Gemini-Pro auf Gitlab und Karten schlechter abschneidet als GPT-3.5-Turbo, während es bei Einkaufsverwaltung, Reddit und Einkaufen schlechter abschneidet Websites Die Leistung liegt nahe an GPT-3.5-Turbo. Gemini-Pro übertrifft GPT-3.5-Turbo bei Multi-Site-Aufgaben, was mit früheren Ergebnissen übereinstimmt, die zeigen, dass Gemini bei komplexeren Teilaufgaben in verschiedenen Benchmarks etwas besser abschneidet. Abbildung 21: Web-Agent-Erfolgsrate des Modells auf verschiedenen Arten von Websites. Wie in Abbildung 22 dargestellt, prognostiziert Gemini-Pro im Allgemeinen mehr Aufgaben als unmöglich zu erledigen, insbesondere wenn ein UA-Hinweis gegeben wird. Gemini-Pro sagte voraus, dass mehr als 80,6 % der Aufgaben angesichts des UA-Hinweises nicht erledigt werden konnten, während GPT-3.5-Turbo nur 47,7 % vorhersagte. Es ist wichtig zu beachten, dass nur 4,4 % der Aufgaben im Datensatz tatsächlich unerfüllbar sind, sodass beide die tatsächliche Anzahl unerfüllbarer Aufgaben erheblich überschätzen. Abbildung 22: UA-Prognosezahl. Gleichzeitig stellten die Autoren fest, dass Gemini Pro eher mit kürzeren Sätzen reagierte und weniger Schritte unternahm, bevor er zu einer Schlussfolgerung gelangte. Wie in Abbildung 23(a) dargestellt, weist Gemini Pro mehr als die Hälfte seiner Flugbahnen mit weniger als 10 Schritten auf, während die meisten Flugbahnen von GPT 3.5 Turbo und GPT 4 Turbo zwischen 10 und 30 Schritten umfassen.Ebenso sind die meisten Antworten von Gemini weniger als 100 Zeichen lang, während die meisten Antworten von GPT 3.5 Turbo, GPT 4 Turbo und Mixtral mehr als 300 Zeichen lang sind (Abbildung 23 (b)). Zwillinge tendieren dazu, Handlungen direkt vorherzusagen, während andere Modelle zuerst argumentieren und dann Handlungsvorhersagen abgeben. Abbildung 23: Modellverhalten auf WebArena. Weitere Einzelheiten finden Sie im Originalpapier. Das obige ist der detaillierte Inhalt vonVollständiger Testbericht zu Gemini: Von CMU zu GPT 3.5 Turbo verliert Gemini Pro. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!