
Heim >Technologie-Peripheriegeräte >KI >OpenAI stärkt das Sicherheitsteam und befähigt es, gegen gefährliche KI ein Veto einzulegen
OpenAI stärkt das Sicherheitsteam und befähigt es, gegen gefährliche KI ein Veto einzulegen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-12-19 17:30:411385Durchsuche
Modelle in Produktion werden vom Team „Sicherheitssysteme“ verwaltet. Spitzenmodelle in der Entwicklung verfügen über „Bereitschafts“-Teams, die Risiken identifizieren und quantifizieren, bevor das Modell veröffentlicht wird. Dann gibt es noch das „Super Alignment“-Team, das an theoretischen Leitlinien für „Super Intelligence“-Modelle arbeitet
Restrukturieren Sie die Sicherheitsberatungsgruppe so, dass sie über dem technischen Team sitzt, Empfehlungen an die Führung richtet und dem Vorstand ein Vetorecht einräumt
OpenAI gab bekannt, dass sie zum Schutz vor der Bedrohung durch schädliche künstliche Intelligenz ihre internen Sicherheitsprozesse stärken. Sie werden eine neue Abteilung namens „Security Advisory Group“ einrichten, die oberhalb des Technologieteams angesiedelt ist, die Führung berät und ein Vetorecht im Vorstand erhält. Diese Entscheidung wurde am 18. Dezember Ortszeit bekannt gegeben
Das Update gibt vor allem Anlass zur Sorge, weil OpenAI-CEO Sam Altman vom Vorstand entlassen wurde, was offenbar mit Sicherheitsproblemen bei großen Modellen zusammenhängt. Zwei „verlangsamte“ Vorstandsmitglieder von OpenAI, Ilya Sutskvi und Helen Toner, verloren ihre Vorstandssitze nach einer Umstrukturierung auf höchster Ebene
In diesem Beitrag bespricht OpenAI sein neuestes „Preparedness Framework“, wie OpenAI katastrophale Risiken durch immer leistungsfähigere Modelle verfolgt, bewertet, vorhersagt und davor schützt. Was ist die Definition von Katastrophenrisiko? OpenAI erklärt: „Was wir als katastrophale Risiken bezeichnen, bezieht sich auf Risiken, die zu wirtschaftlichen Verlusten in Höhe von Hunderten von Milliarden Dollar führen oder bei vielen Menschen zu schweren Verletzungen oder zum Tod führen können.“
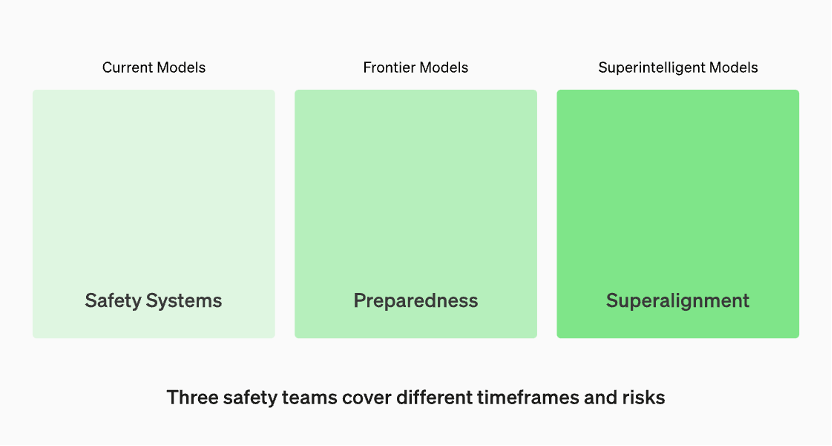
Laut der offiziellen Website von OpenAI werden Modelle in der Produktion vom „Security System“-Team verwaltet. Während der Entwicklungsphase gibt es ein Team namens „Vorbereitung“, das Risiken identifiziert und bewertet, bevor das Modell veröffentlicht wird. Darüber hinaus gibt es ein Team namens „Superalignment“, das an theoretischen Leitlinien für „superintelligente“ Modelle arbeitet
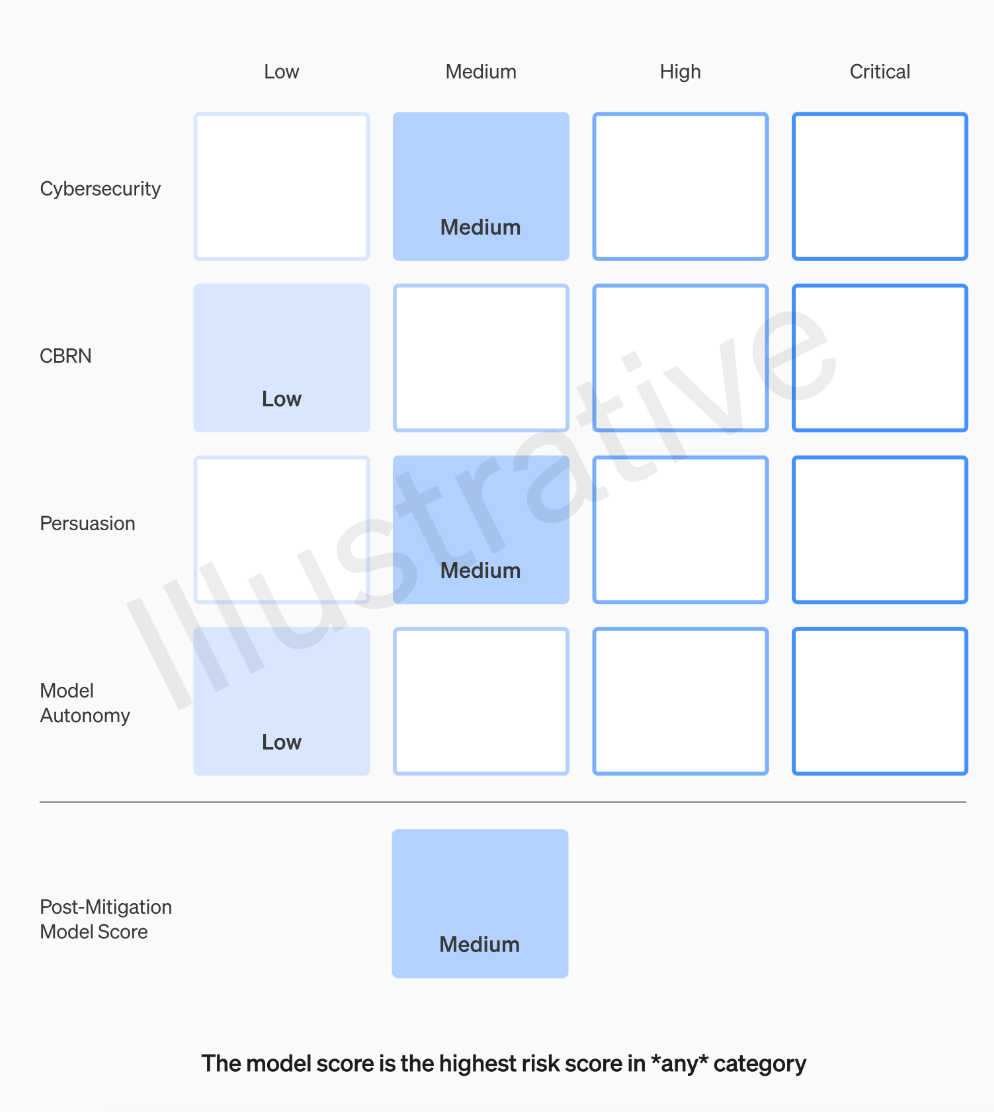
Das OpenAI-Team bewertet jedes Modell anhand von vier Risikokategorien: Cybersicherheit, Überzeugungskraft (z. B. Desinformation), Modellautonomie (die Fähigkeit, sich autonom zu verhalten) und CBRN (chemische, biologische, radiologische und nukleare Bedrohungen, z. B. die Fähigkeit dazu). neue Krankheitserreger erzeugen)
OpenAI berücksichtigt in seinen Annahmen verschiedene Abhilfemaßnahmen: Beispielsweise unterhält das Modell begründete Vorbehalte gegenüber der Beschreibung des Herstellungsprozesses von Napalm- oder Rohrbomben. Wenn ein Modell nach Berücksichtigung bekannter Abhilfemaßnahmen immer noch als „hohes“ Risiko eingestuft wird, wird es nicht eingesetzt, und wenn ein Modell „kritische“ Risiken aufweist, wird es nicht weiterentwickelt
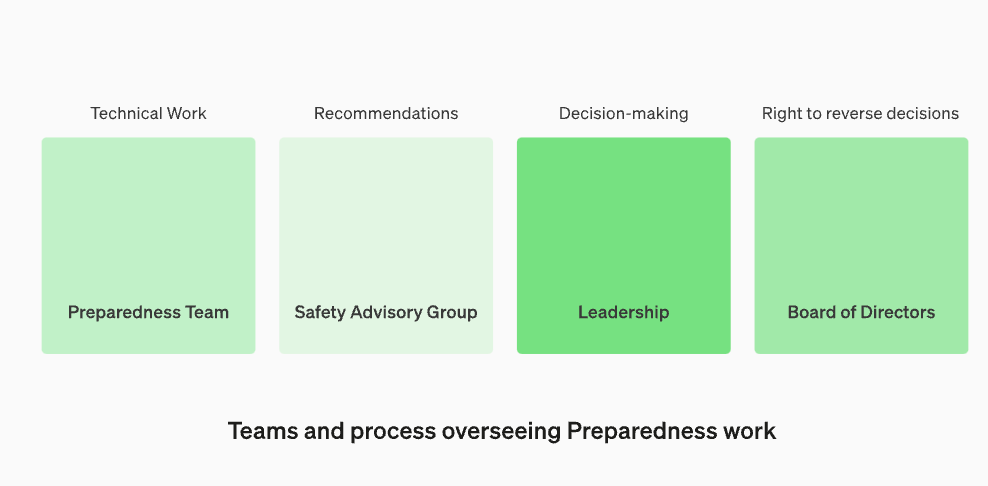
Nicht jeder, der ein Modell herstellt, ist die beste Person, um es zu bewerten und Empfehlungen auszusprechen. Aus diesem Grund richtet OpenAI ein Team namens „Cross-Functional Security Advisory Group“ ein, das die Berichte der Forscher auf technischer Ebene prüft und Empfehlungen aus einer höheren Perspektive abgibt, in der Hoffnung, einige „unbekannte Unbekannte“ aufzudecken
Dieser Prozess erfordert, dass diese Empfehlungen sowohl an den Vorstand als auch an die Führung gesendet werden, die entscheiden, ob der Betrieb fortgeführt oder eingestellt wird. Der Vorstand hat jedoch das Recht, diese Entscheidungen rückgängig zu machen. Dadurch wird vermieden, dass risikoreiche Produkte oder Prozesse ohne Wissen des Vorstands genehmigt werden
Die Außenwelt ist jedoch immer noch besorgt darüber, ob der Vorstand von OpenAI wirklich das Recht hat, dies zu widerlegen und Maßnahmen zu ergreifen, wenn das Expertengremium Empfehlungen abgibt und der CEO Entscheidungen auf der Grundlage dieser Informationen trifft. Wenn ja, würde die Öffentlichkeit davon erfahren? Abgesehen von OpenAIs Versprechen, unabhängige Prüfungen durch Dritte einzuholen, wurden ihre Transparenzprobleme derzeit nicht wirklich angegangen
Das „Readiness Framework“ von OpenAI enthält die folgenden fünf Schlüsselelemente:1. Bewertung und Bewertung
Wir werden unser Modell evaluieren und unsere „Scorecard“ kontinuierlich aktualisieren. Wir werden alle hochmodernen Modelle evaluieren, einschließlich der Verdreifachung der effektiven Berechnung während des Trainings. Wir werden die Grenzen des Modells erweitern. Diese Ergebnisse werden uns dabei helfen, die Risiken der neuesten Modelle einzuschätzen und die Wirksamkeit aller vorgeschlagenen Abhilfemaßnahmen zu messen. Unser Ziel ist es, kantenspezifische Unsicherheiten zu erkennen, um Risiken effektiv zu mindern. Um das Sicherheitsniveau unserer Modelle zu verfolgen, erstellen wir Risiko-Scorecards und detaillierte Berichte
 Zur Bewertung aller Spitzenmodelle ist eine „Scorecard“ erforderlich
Zur Bewertung aller Spitzenmodelle ist eine „Scorecard“ erforderlich
Der Zweck der Festlegung von Risikoschwellenwerten besteht darin, eine klare Grenze bei der Entscheidungsfindung und beim Risikomanagement zu schaffen. Der Risikoschwellenwert bezieht sich auf das maximale Risikoniveau, das eine Organisation oder Einzelperson unter bestimmten Umständen bereit ist, zu tragen. Durch das Festlegen von Risikoschwellenwerten können Sie einer Organisation oder Einzelperson dabei helfen, zu erkennen, wann Maßnahmen zur Minderung oder Vermeidung eines Risikos erforderlich sind. Die Festlegung von Risikoschwellenwerten sollte auf den Ergebnissen der Risikobewertung, relevanten Vorschriften und Richtlinien sowie der Risikotoleranz der Organisation oder Einzelperson basieren. Bei der Festlegung von Risikoschwellen müssen die Merkmale und Auswirkungen verschiedener Risikoarten berücksichtigt werden, um die Wirksamkeit und Anwendbarkeit von Risikomanagementmaßnahmen sicherzustellen. Schließlich sollten die festgelegten Risikoschwellen regelmäßig bewertet und angepasst werden, um mit den Risikomanagementzielen der Organisation oder Einzelperson in Einklang zu bleiben
Wir werden Risikoschwellenwerte festlegen, die Sicherheitsmaßnahmen auslösen. Wir legen Schwellenwerte für Risikostufen fest, die auf den folgenden vorläufigen Tracking-Kategorien basieren: Cybersicherheit, CBRN (chemische, biologische, radiologische, nukleare Bedrohungen), Überzeugungskraft und Modellautonomie. Wir geben vier Sicherheitsrisikostufen an und es können nur Modelle mit einem Post-Minderungs-Score von „mittel“ oder darunter eingesetzt werden. Nur Modelle mit einem Post-Minderungs-Score von „hoch“ oder darunter können weiterentwickelt werden. Bei Modellen mit hohen oder schwerwiegenden Risiken (Pre-Mitigation) werden wir außerdem zusätzliche Sicherheitsmaßnahmen implementieren

Gefahrenstufe
Neugestaltung der Betriebsstruktur für die Überwachung technischer Arbeiten und Sicherheitsentscheidungen
Wir werden ein spezielles Team zusammenstellen, das die technische Arbeit und die operative Struktur von Sicherheitsentscheidungen überwacht. Das Bereitschaftsteam wird die technische Arbeit vorantreiben, um die Leistungsgrenzen modernster Modelle zu untersuchen und Bewertungen und umfassende Berichte durchzuführen. Diese technische Arbeit ist von entscheidender Bedeutung für die Entwicklungs- und Bereitstellungsentscheidungen von OpenAI-Sicherheitsmodellen. Wir bilden eine funktionsübergreifende Sicherheitsberatungsgruppe, die alle Berichte prüft und sie sowohl an die Führung als auch an den Vorstand sendet. Obwohl die Führung der Entscheidungsträger ist, hat der Vorstand die Macht, Entscheidungen zu kippen
Überwachung neuer Änderungen in der technischen Arbeits- und Sicherheitsentscheidungs-Betriebsstruktur
Erhöhen Sie die Sicherheit und stärken Sie die externe Rechenschaftspflicht
Wir werden Protokolle entwickeln, um die Sicherheit und die externe Rechenschaftspflicht zu verbessern. Wir werden regelmäßig Sicherheitsübungen durchführen, um unser Unternehmen und unsere eigene Kultur einem Stresstest zu unterziehen. Einige Sicherheitsprobleme können schnell auftreten, daher haben wir die Möglichkeit, dringende Probleme zu kennzeichnen, um schnell reagieren zu können. Wir glauben, dass es hilfreich ist, Feedback von Personen außerhalb von OpenAI einzuholen und es von einem qualifizierten, unabhängigen Dritten überprüfen zu lassen. Wir werden weiterhin dafür sorgen, dass andere rote Teams bilden und unsere Modelle bewerten, und planen, Aktualisierungen extern zu teilen
Reduzieren Sie andere bekannte und unbekannte Sicherheitsrisiken:
Wir helfen bei der Minderung anderer bekannter und unbekannter Sicherheitsrisiken. Wir werden sowohl mit externen Parteien als auch intern mit Teams wie Sicherheitssystemen eng zusammenarbeiten, um realen Missbrauch zu verfolgen. Wir werden auch mit Super Alignment zusammenarbeiten, um dringende Fehlausrichtungsrisiken zu verfolgen. Wir leisten auch Pionierarbeit bei neuen Forschungsarbeiten, um zu messen, wie sich Risiken bei der Skalierung von Modellen entwickeln, und helfen dabei, Risiken im Voraus vorherzusagen, ähnlich wie bei unserem früheren Erfolg mit dem Gesetz der Skalierung. Schließlich werden wir in einem kontinuierlichen Prozess versuchen, alle auftretenden „unbekannten Unbekannten“ aufzuklären
Das obige ist der detaillierte Inhalt vonOpenAI stärkt das Sicherheitsteam und befähigt es, gegen gefährliche KI ein Veto einzulegen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- OpenAI-Präsident: GPT-4 ist nicht perfekt, aber es ist definitiv anders
- Es ist wirklich nicht Versailles! ChatGPT ist so erfolgreich, dass selbst OpenAI es nicht versteht
- Einführung in OpenAI und Microsoft Sentinel
- OpenAI gewinnt den ChatGPT-Wettbewerb und sorgt in der Time für Schlagzeilen
- OpenAI bringt die erste generative künstliche Intelligenz-Mobilanwendung ChatGPT auf den Markt und eröffnet damit eine neue Ära der intelligenten Kommunikation