
Heim >häufiges Problem >Einführung in OpenAI und Microsoft Sentinel
Einführung in OpenAI und Microsoft Sentinel

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-13 12:07:111764Durchsuche
Willkommen zu unserer Serie über OpenAI und Microsoft Sentinel! Große Sprachmodelle oder LLMs wie die GPT3-Familie von OpenAI erobern die öffentliche Vorstellungskraft mit innovativen Anwendungsfällen wie Textzusammenfassung, menschenähnlichen Gesprächen, Code-Analyse und -Debugging und vielen anderen Beispielen. Wir haben gesehen, wie ChatGPT Drehbücher und Gedichte schrieb, Musik komponierte, Essays schrieb und sogar Computercode von einer Sprache in eine andere übersetzte.
Was wäre, wenn wir dieses unglaubliche Potenzial nutzen könnten, um Einsatzkräfte in Sicherheitszentralen zu unterstützen? Natürlich können wir das – und es ist ganz einfach! Microsoft Sentinel enthält bereits einen integrierten Connector für OpenAI GPT3-Modelle, den wir in unseren Automatisierungs-Playbooks implementieren können, die auf Azure Logic Apps basieren. Diese leistungsstarken Workflows lassen sich einfach schreiben und in den SOC-Betrieb integrieren. Heute werfen wir einen Blick auf den OpenAI-Connector und untersuchen einige seiner konfigurierbaren Parameter anhand eines einfachen Anwendungsfalls: der Beschreibung einer MITRE ATT&CK-Richtlinie im Zusammenhang mit Sentinel-Ereignissen.
Bevor wir beginnen, besprechen wir einige Voraussetzungen:
- Wenn Sie noch keine Microsoft Sentinel-Instanz haben, können Sie eine mit Ihrem kostenlosen Azure-Konto erstellen und der Schnellstartanleitung „Erste Schritte mit Sentinel“ folgen.
- Wir werden vorab aufgezeichnete Daten aus dem Microsoft Sentinel Training Lab verwenden, um unser Playbook zu testen.
- Sie benötigen außerdem ein persönliches OpenAI-Konto mit einem API-Schlüssel für die GPT3-Verbindung.
- Ich empfehle außerdem dringend, einen Blick auf Antonio Formatos hervorragenden Blog zum Umgang mit Ereignissen mit ChatGPT und Sentinel zu werfen, in dem Antonio ein sehr nützliches Allzweckhandbuch vorstellt, das bisher zur Referenz für fast alle OpenAI-Modellimplementierungen in Sentinel geworden ist.
Wir beginnen mit einem einfachen Vorfall-Trigger-Playbook (Sentinel > Automatisierung > Erstellen > Playbook mit Vorfall-Trigger).
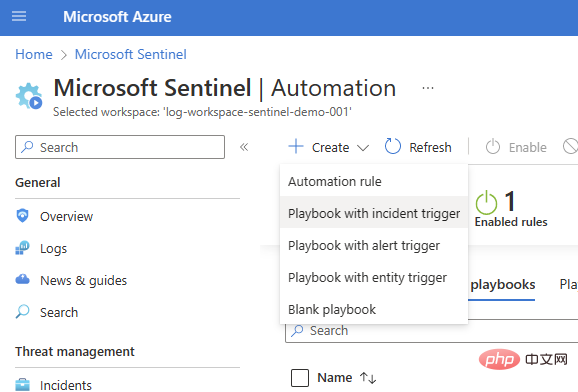
Wählen Sie Ihr Abonnement und Ihre Ressourcengruppe aus, fügen Sie einen Skriptnamen hinzu und wechseln Sie zur Registerkarte „Verbindungen“. Sie sollten Microsoft Sentinel mit einer oder zwei Authentifizierungsoptionen sehen – in diesem Beispiel verwende ich Managed Identity – aber wenn Sie noch keine Verbindungen haben, können Sie auch eine Sentinel-Verbindung im Logic Apps Designer hinzufügen.
Sehen Sie sich das Playbook an und erstellen Sie es. Nach ein paar Sekunden wird die Ressource erfolgreich bereitgestellt und führt uns zum Logic App Designer-Canvas:
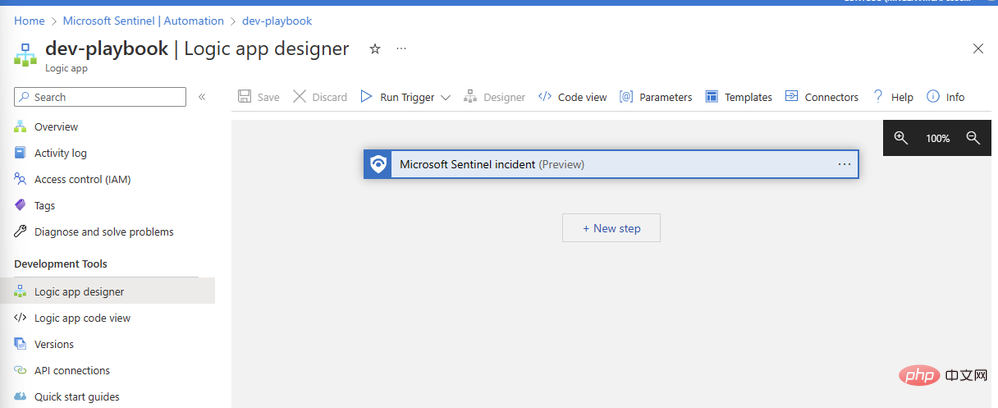
Fügen wir unseren OpenAI-Connector hinzu. Klicken Sie auf „Neuer Schritt“ und geben Sie „OpenAI“ in das Suchfeld ein. Sie sehen den Konnektor im oberen Bereich und zwei Aktionen darunter: „Bild erstellen“ und „GPT3-Tipp vervollständigen“:
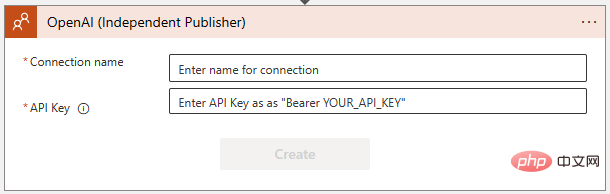
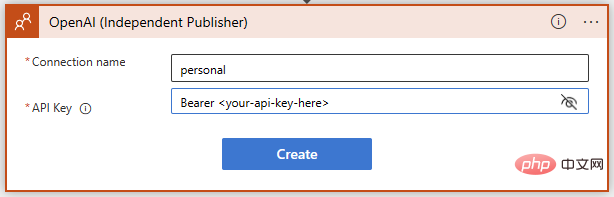
Wählen Sie „GPT3-Tipp vervollständigen“. Anschließend werden Sie im folgenden Dialog aufgefordert, eine Verbindung zur OpenAI-API herzustellen. Wenn Sie es noch nicht getan haben, erstellen Sie einen Schlüssel unter https://platform.openai.com/account/api-keys und bewahren Sie ihn an einem sicheren Ort auf!
Stellen Sie sicher, dass Sie die Anweisungen genau befolgen, wenn Sie den OpenAI-API-Schlüssel hinzufügen – er erfordert das Wort „Bearer“, gefolgt von einem Leerzeichen und dann dem Schlüssel selbst:
Erfolgreich! Wir haben jetzt die GPT3-Textvervollständigung für unsere Eingabeaufforderung bereit. Wir möchten, dass das KI-Modell MITRE ATT&CK-Strategien und -Techniken im Zusammenhang mit Sentinel-Ereignissen interpretiert. Schreiben wir also eine einfache Eingabeaufforderung mit dynamischen Inhalten, um Ereignisstrategien von Sentinel einzufügen.
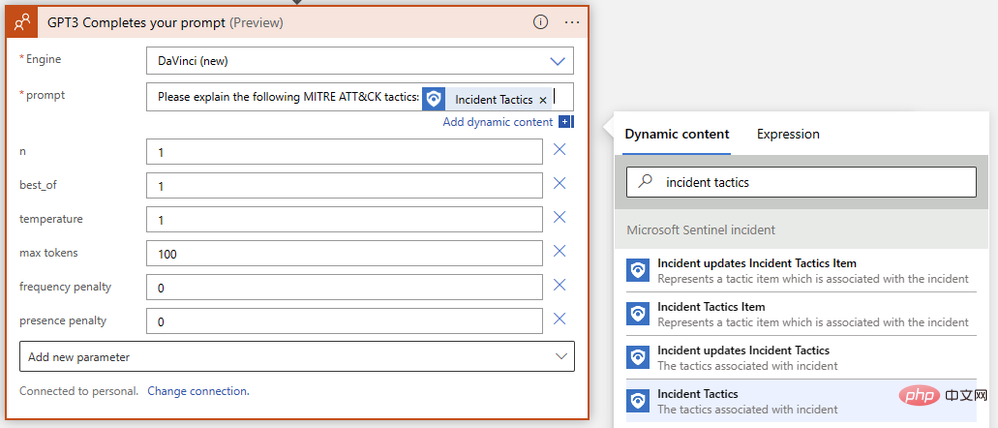
Wir sind fast fertig! Speichern Sie Ihre Logik-App und gehen Sie zu Microsoft Sentinel Events, um sie zu testen. Da ich in meiner Instanz Testdaten aus dem Microsoft Sentinel Training Lab habe, führe ich dieses Playbook gegen Ereignisse aus, die durch Warnungen böswilliger Posteingangsregeln ausgelöst werden.
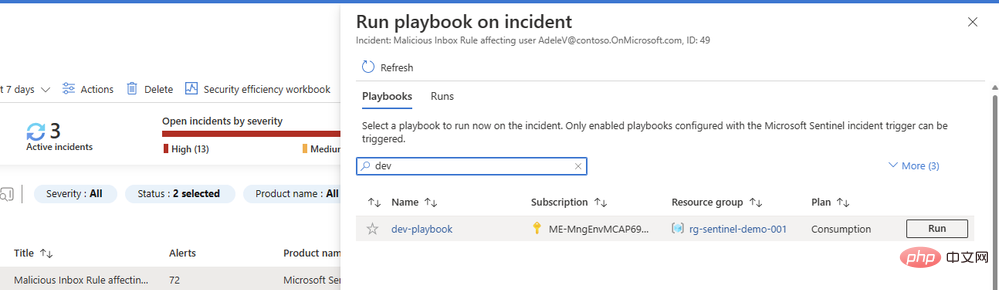
Sie fragen sich vielleicht, warum wir in unserem Playbook keine zweite Aktion konfiguriert haben, um einen Kommentar oder eine Aufgabe mit einem Ergebnis hinzuzufügen. Wir werden es schaffen – aber zuerst wollen wir sicherstellen, dass unsere Eingabeaufforderungen gute Inhalte vom KI-Modell zurückgeben. Kehren Sie zum Playbook zurück und öffnen Sie die Übersicht in einem neuen Tab. In Ihrem Laufverlauf sollte ein Element angezeigt werden, hoffentlich mit einem grünen Häkchen:
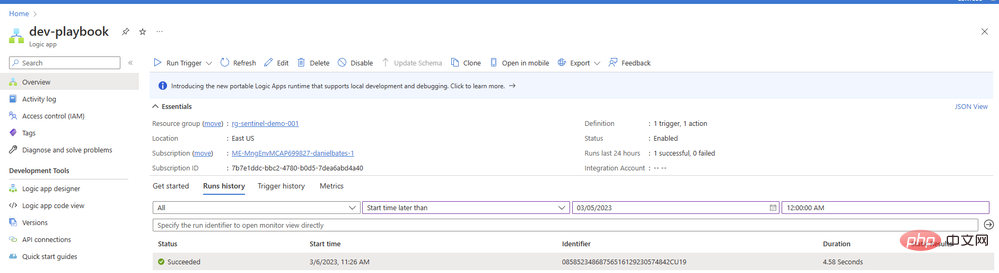
Klicken Sie auf das Element, um Details zur ausgeführten Logik-App anzuzeigen. Wir können jeden Operationsblock erweitern, um detaillierte Eingabe- und Ausgabeparameter anzuzeigen:
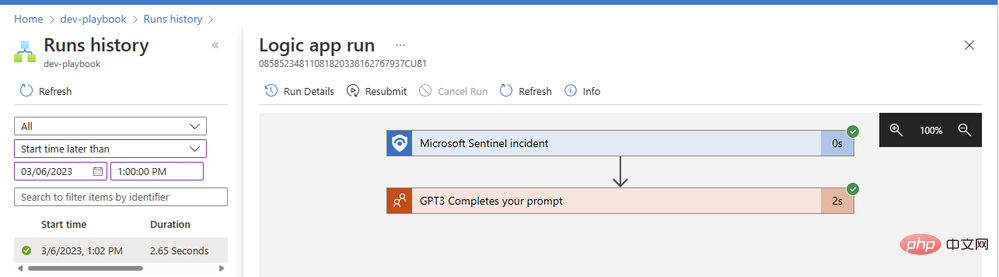
Unsere GPT3-Operation wurde in nur zwei Sekunden erfolgreich abgeschlossen. Klicken wir auf den Aktionsblock, um ihn zu erweitern und die vollständigen Details seiner Ein- und Ausgänge anzuzeigen:
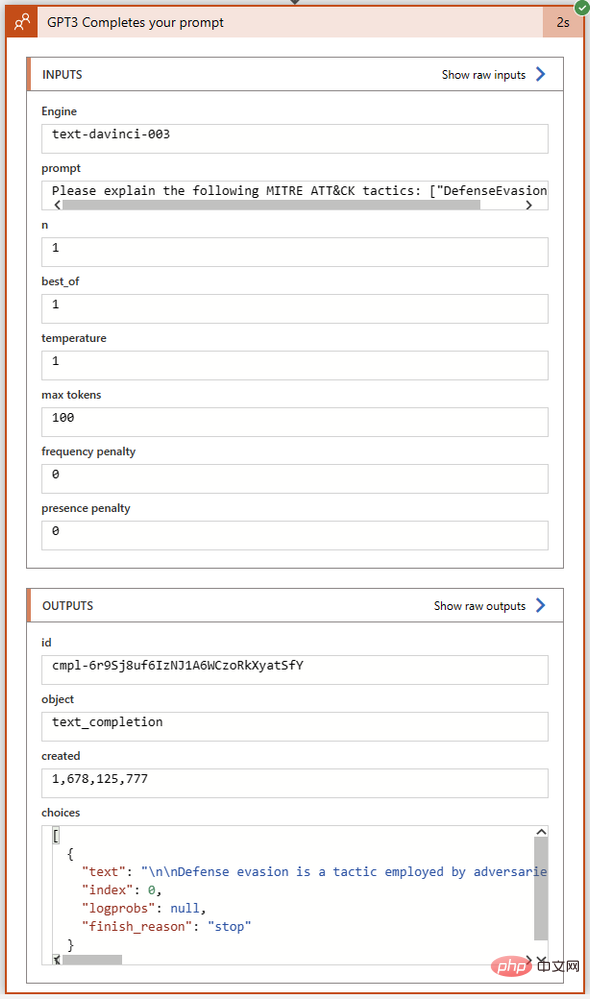
Schauen wir uns das Feld „Auswählen“ im Abschnitt „Ausgänge“ genauer an. Hier gibt GPT3 den Abschlusstext zusammen mit dem Abschlussstatus und etwaigen Fehlercodes zurück. Ich habe den vollständigen Text der Choices-Ausgabe in Visual Studio Code kopiert:
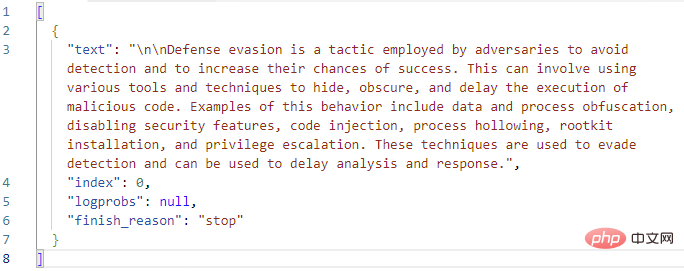
Sieht bisher gut aus! GPT3 erweitert die MITRE-Definition von „Verteidigungsumgehung“ korrekt. Bevor wir dem Playbook eine logische Aktion hinzufügen, um mit diesem Antworttext einen Ereigniskommentar zu erstellen, schauen wir uns noch einmal die Parameter der GPT3-Aktion selbst an. Es gibt insgesamt neun Parameter in der OpenAI-Textvervollständigungsaktion, Engine-Auswahl und Hinweise nicht mitgerechnet:
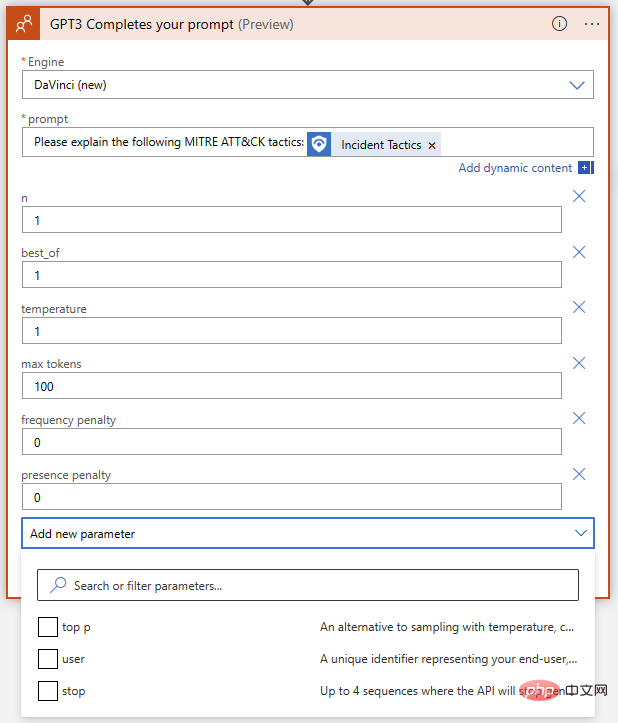
Was bedeuten diese und wie optimieren wir sie, um die besten Ergebnisse zu erzielen? Um uns zu helfen, die Auswirkungen jedes Parameters auf die Ergebnisse zu verstehen, gehen wir zum OpenAI API Playground. Wir können die genaue Eingabeaufforderung in das Eingabefeld einfügen, in dem die Logik-App ausgeführt wird. Bevor wir jedoch auf „Senden“ klicken, möchten wir sicherstellen, dass die Parameter übereinstimmen. Hier ist eine kurze Tabelle zum Vergleich der Parameternamen zwischen Azure Logic App OpenAI Connector und OpenAI Playground:
| Azure Logic App Connector | OpenAI Playground | Erklärung |
| Engine | Model | generiert das fertige Modell. Wir können im OpenAI-Connector Leonardo da Vinci (neu), Leonardo da Vinci (alt), Curie, Babbage oder Ada auswählen, entsprechend „text-davinci-003“, „text-davinci-002“, „text bzw. -curie“. -001‘, ‚text-babbage-001‘ und ‚text-ada-001‘ in Playground. |
| n | NA | Wie viele Vervollständigungen für jede Eingabeaufforderung generiert werden. Dies entspricht der mehrmaligen Eingabe der Eingabeaufforderung im Playground. |
| Best | (gleich) | Generieren Sie mehrere Vervollständigungen und geben Sie die beste zurück. Mit Vorsicht verwenden – das kostet viele Token! |
| Temperatur | (gleich) | definiert die Zufälligkeit (oder Kreativität) der Antwort. Auf 0 gesetzt, um eine hochdeterministische, wiederholte sofortige Vervollständigung zu erreichen, bei der das Modell immer seine sicherste Wahl zurückgibt. Stellen Sie den Wert auf 1 ein, um maximale kreative Reaktionen mit mehr Zufälligkeit zu erzielen, oder auf Wunsch irgendwo dazwischen. |
| Max. Tokens | Max. Länge | Maximale Länge der ChatGPT-Antwort, angegeben in Token. Ein Token besteht ungefähr aus vier Zeichen. ChatGPT verwendet Token-Preise; zum Zeitpunkt des Schreibens kosten 1000 Token 0,002 $. Die Kosten eines API-Aufrufs umfassen die angedeutete Tokenlänge zusammen mit der Antwort. Wenn Sie also die niedrigsten Kosten pro Antwort beibehalten möchten, subtrahieren Sie die angedeutete Tokenlänge von 1000, um die Antwort zu begrenzen. |
| Frequenzstrafe | (gleich) | Zahl im Bereich von 0 bis 2. Je höher der Wert, desto geringer ist die Wahrscheinlichkeit, dass das Modell die Zeile wörtlich wiederholt (es wird versuchen, Synonyme oder Neuformulierungen der Zeile zu finden). |
| Es gibt eine Strafe | (gleich) | Eine Zahl zwischen 0 und 2. Je höher der Wert, desto geringer ist die Wahrscheinlichkeit, dass das Modell Themen wiederholt, die bereits in der Antwort erwähnt wurden. |
| TOP | (gleich) | Eine andere Möglichkeit, die Antwort-„Kreativität“ einzurichten, wenn Sie die Temperatur nicht verwenden. Dieser Parameter begrenzt die möglichen Antwort-Tokens basierend auf der Wahrscheinlichkeit; wenn er auf 1 gesetzt ist, werden alle Tokens berücksichtigt, aber kleinere Werte reduzieren die Menge möglicher Antworten auf die höchsten X %. |
| Benutzer | N/A | eindeutige Kennung. Wir müssen diesen Parameter nicht festlegen, da unser API-Schlüssel bereits als unsere Kennungszeichenfolge verwendet wird. |
| Stop | Sequenz stoppen | Bis zu vier Sequenzen beenden die Reaktion des Modells. |
Lassen Sie uns die folgenden OpenAI API Playground-Einstellungen verwenden, um sie an unsere Logikanwendungsoperationen anzupassen:
- Modell: text-davinci-003
- Temperatur: 1
- Maximale Länge: 100
Das erhalten wir aus dem GPT3-Engine-Ergebnis .
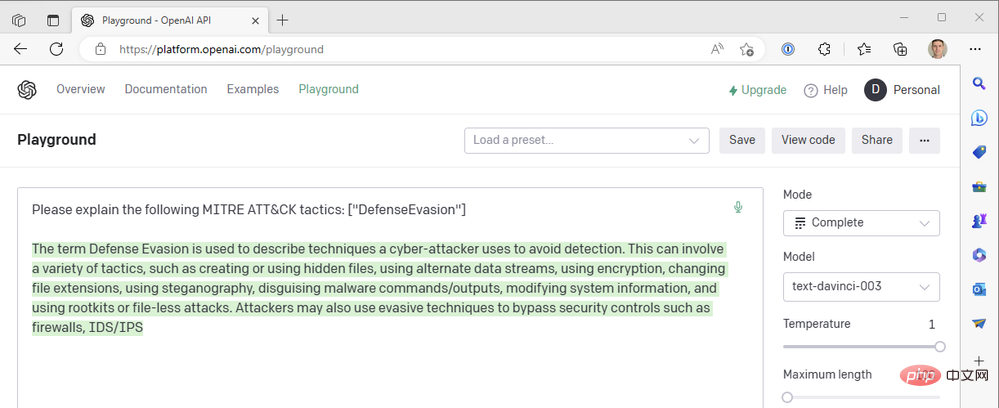
Es sieht so aus, als wäre die Antwort in der Mitte des Satzes abgeschnitten, daher sollten wir den Parameter für die maximale Länge erhöhen. Ansonsten sieht diese Antwort ziemlich gut aus. Wir verwenden den höchstmöglichen Temperaturwert – was passiert, wenn wir die Temperatur senken, um eine sicherere Reaktion zu erhalten? Nehmen wir zum Beispiel eine Temperatur von Null:
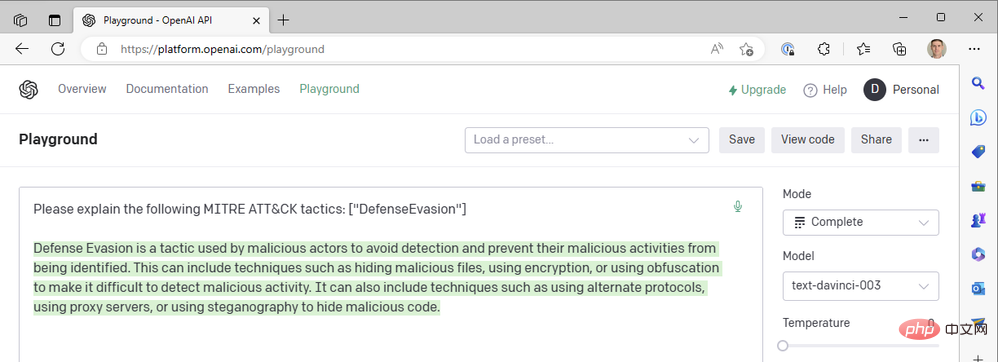
Bei Temperatur = 0 erhalten wir fast das exakt gleiche Ergebnis, egal wie oft wir diese Eingabeaufforderung erneut generieren. Dies funktioniert gut, wenn wir GPT3 bitten, technische Begriffe zu definieren. Es sollte keinen großen Unterschied darin geben, was „defensive Umgehung“ als MITRE ATT&CK-Taktik bedeutet. Wir können die Lesbarkeit von Antworten verbessern, indem wir eine Häufigkeitsstrafe hinzufügen, um die Tendenz des Modells zur Wiederverwendung derselben Wörter („technisches Like“) zu verringern. Erhöhen wir den Häufigkeitsabzug auf maximal 2:
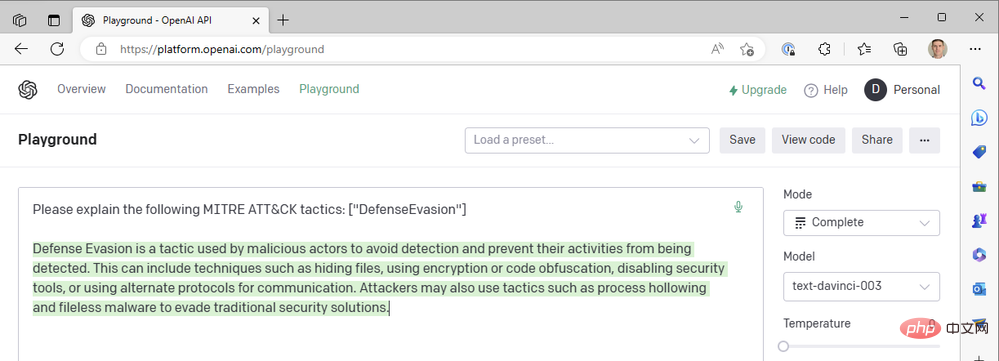
Wir haben bisher nur die neuesten da Vinci-Modelle verwendet, um Dinge schnell zu erledigen. Was passiert, wenn wir auf eines der schnelleren und günstigeren OpenAI-Modelle wie Curie, Babbage oder Ada umsteigen? Ändern wir das Modell in „text-ada-001“ und vergleichen die Ergebnisse:
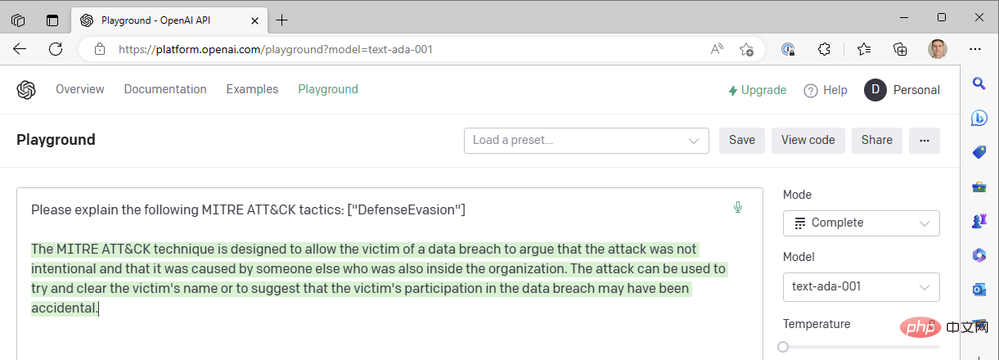
Naja… nicht ganz. Versuchen wir es mit Babbage:
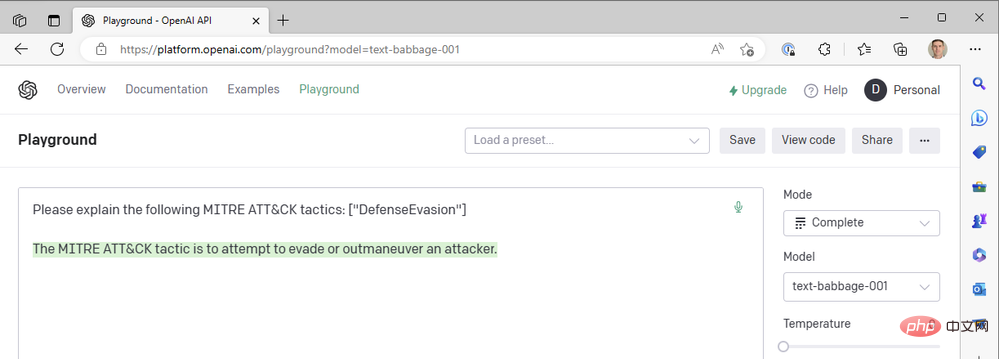
Babbage scheint auch nicht die gewünschten Ergebnisse zu liefern. Vielleicht wäre Curie besser dran?
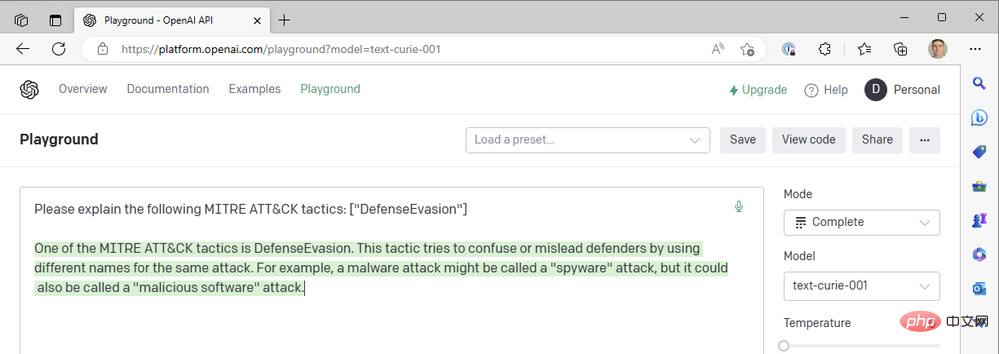
Leider erfüllte Curie auch nicht die von Leonardo da Vinci festgelegten Standards. Sie sind sicherlich schnell, aber unser Anwendungsfall, Kontext zu Sicherheitsereignissen hinzuzufügen, basiert nicht auf Reaktionszeiten von weniger als einer Sekunde – die Genauigkeit der Zusammenfassung ist wichtiger. Wir nutzen weiterhin die erfolgreiche Kombination aus Da-Vinci-Modellen, Niedertemperatur- und Hochfrequenz-Bestrafung.
Zurück zu unserer Logik-App. Übertragen wir die Einstellungen, die wir vom Playground entdeckt haben, auf den OpenAI-Aktionsblock:
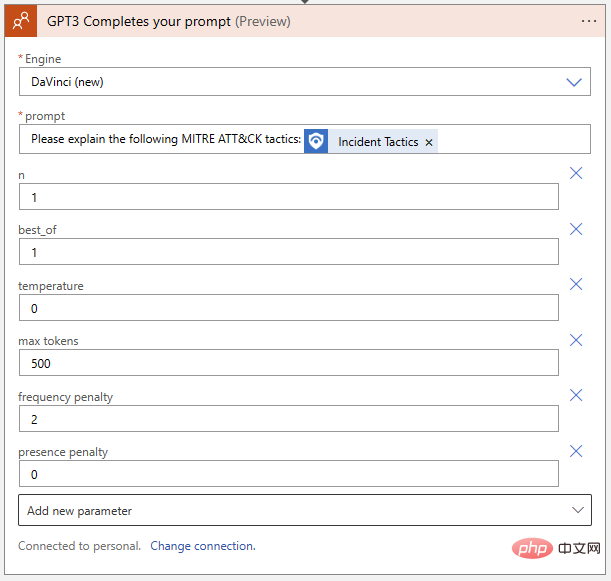
Unsere Logik-App muss auch in der Lage sein, Kommentare für unsere Veranstaltungen zu schreiben. Klicken Sie auf „Neuer Schritt“ und wählen Sie „Kommentar zum Ereignis hinzufügen“ aus dem Microsoft Sentinel-Connector:
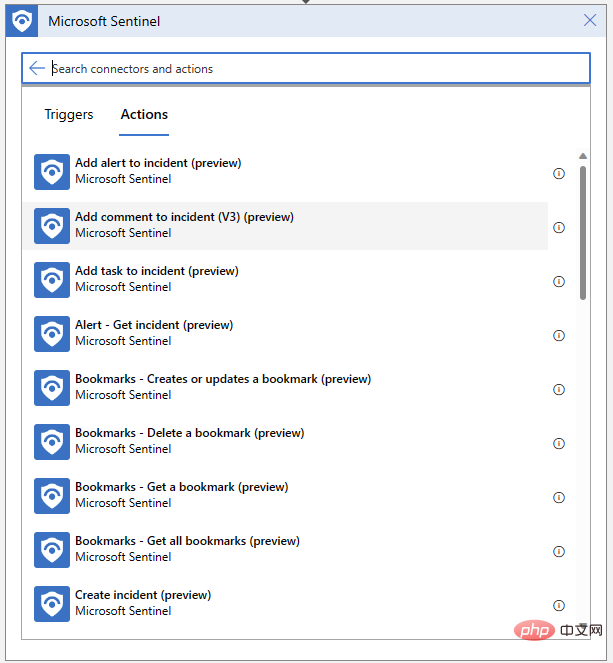
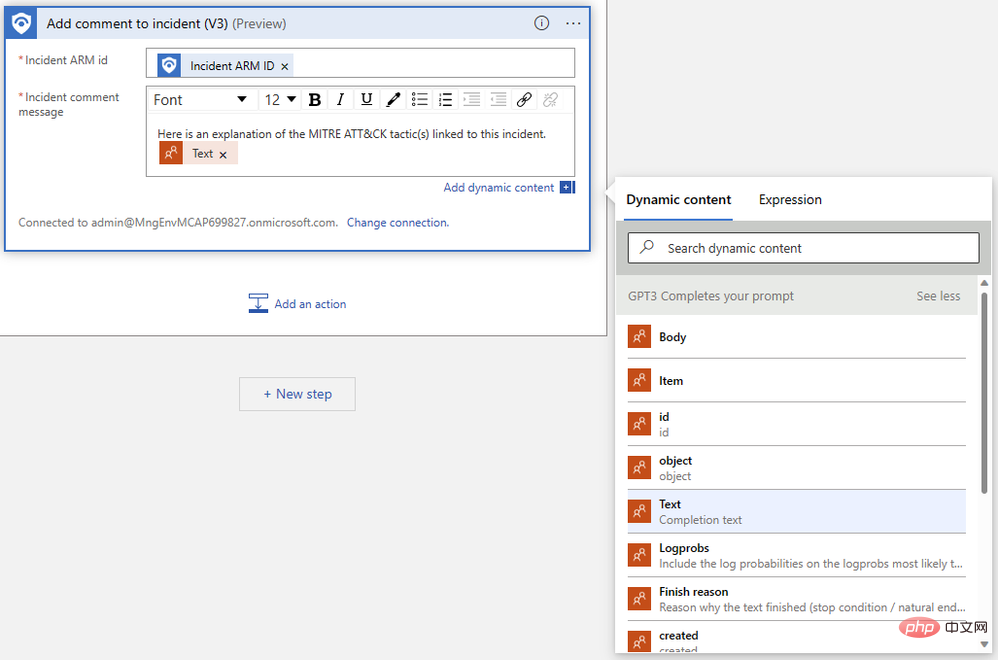
Wir müssen nur die ARM-ID des Ereignisses angeben und unsere Kommentarnachricht verfassen. Suchen Sie zunächst im Popup-Menü für dynamische Inhalte nach „Event ARM ID“:
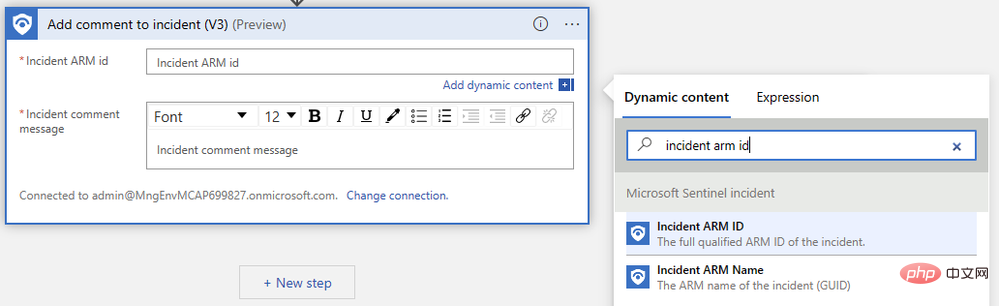
Als nächstes suchen Sie den „Text“, den wir im vorherigen Schritt ausgegeben haben. Möglicherweise müssen Sie auf „Mehr anzeigen“ klicken, um die Ausgabe anzuzeigen. Der Logic App Designer verpackt unsere Kommentaraktion automatisch in einen „Für jeden“-Logikblock, um Fälle zu verarbeiten, in denen mehrere Vervollständigungen für dieselbe Eingabeaufforderung generiert werden.
Unsere fertige Logik-App sollte in etwa so aussehen:
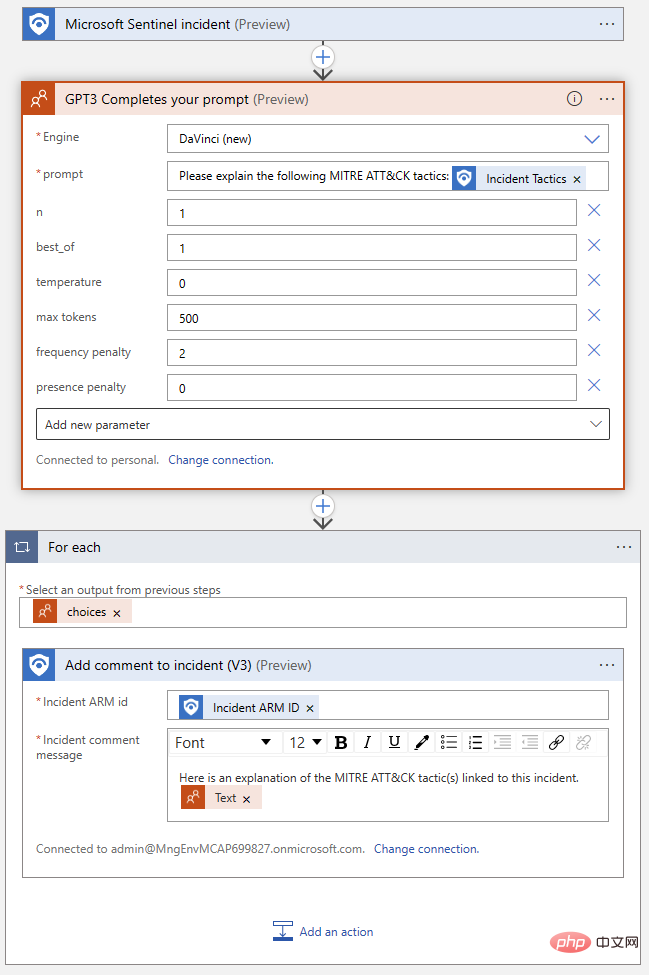
Lass es uns noch einmal testen! Gehen Sie zurück zu diesem Microsoft Sentinel-Ereignis und führen Sie das Playbook aus. Wir sollten einen weiteren erfolgreichen Abschluss in unserem Logik-App-Ausführungsverlauf und einen neuen Kommentar in unserem Ereignisaktivitätsprotokoll erhalten.
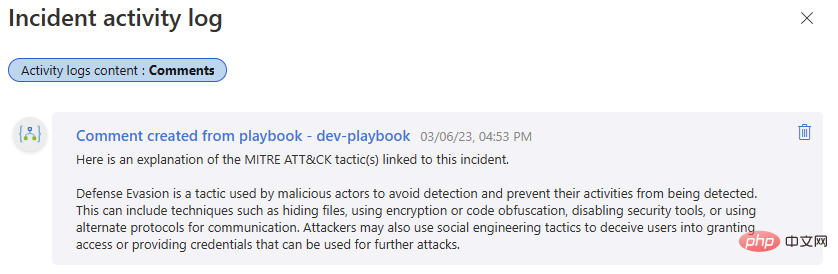
Wenn Sie bisher mit uns in Kontakt geblieben sind, können Sie jetzt OpenAI GPT3 mit Microsoft Sentinel integrieren, was Ihren Sicherheitsuntersuchungen einen Mehrwert verleihen kann. Seien Sie gespannt auf unsere nächste Ausgabe, in der wir weitere Möglichkeiten zur Integration von OpenAI-Modellen in Sentinel besprechen und so Workflows freischalten, die Ihnen dabei helfen können, das Beste aus Ihrer Sicherheitsplattform herauszuholen!
Das obige ist der detaillierte Inhalt vonEinführung in OpenAI und Microsoft Sentinel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!