
Heim >Technologie-Peripheriegeräte >KI >Ein tieferes Verständnis des visuellen Transformators, Analyse des visuellen Transformators
Ein tieferes Verständnis des visuellen Transformators, Analyse des visuellen Transformators

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-12-15 11:17:371210Durchsuche
Dieser Artikel wurde mit Genehmigung des öffentlichen Kontos von Autonomous Driving Heart nachgedruckt. Bitte wenden Sie sich beim Nachdruck an die Quelle Der Bereich Computer Vision (CV) hat große Auswirkungen gehabt. Sie übertreffen frühere CNN-Algorithmusmodelle (Convolutional Neural Network) bei vielen grundlegenden Computer-Vision-Aufgaben. Das Folgende ist die neueste Rangliste der verschiedenen grundlegenden Computer-Vision-Aufgaben, die ich gefunden habe. Mithilfe von LeaderBoard können wir die Dominanz des Transformer-Algorithmusmodells bei verschiedenen Computer-Vision-Aufgaben erkennen. Aus der Liste ist ersichtlich, dass unter den Top 5 jedes Modell die Transformer-Struktur verwendet, während die CNN-Struktur nur teilweise verwendet oder mit dem Transformer kombiniert wird.
LeaderBoard für Bildklassifizierungsaufgabe
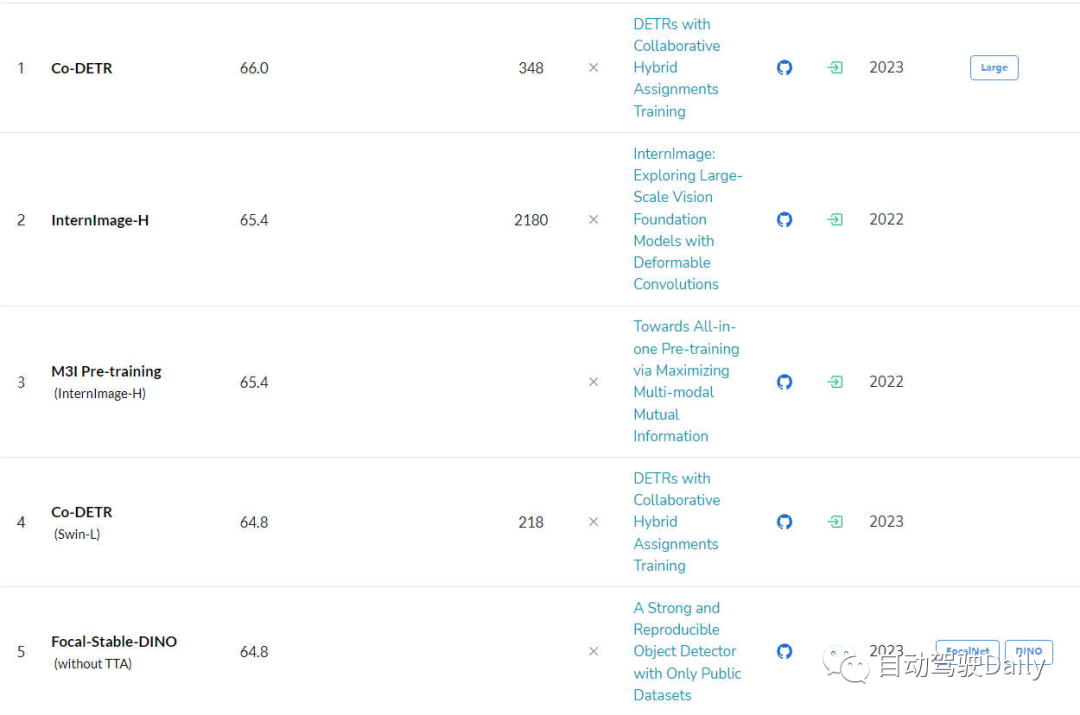
Zielerkennungsaufgabe- Die nächste ist LeaderBoard für COCO-Testentwickler. Aus der Liste ist ersichtlich, dass mehr als die Hälfte der Top 5 auf DETR basiert algorithmische Struktur wird erweitert.

- Die letzte ist LeaderBoard auf ADE20K-Wert. Aus der Liste ist auch ersichtlich, dass die Transformer-Struktur unter den ersten auf der Liste immer noch den aktuellen Platz einnimmt Position. Die Hauptkraft.
 Der Hauptzweck dieses Artikels besteht darin, verschiedene Interpretierbarkeitsmethoden von Vision Transformer zu untersuchen und auf den Forschungsmotivationen verschiedener Algorithmen, Strukturtypen usw. zu basieren Anwendungsszenarien werden in einem Übersichtsartikel klassifiziert
Der Hauptzweck dieses Artikels besteht darin, verschiedene Interpretierbarkeitsmethoden von Vision Transformer zu untersuchen und auf den Forschungsmotivationen verschiedener Algorithmen, Strukturtypen usw. zu basieren Anwendungsszenarien werden in einem Übersichtsartikel klassifiziert
- Analyse von Vision Transformer
Denn wie bereits erwähnt, hat die Struktur von Vision Transformer bei verschiedenen grundlegenden Computer-Vision-Aufgaben sehr gute Ergebnisse erzielt. In der Computer-Vision-Community sind so viele Methoden entstanden, um die Interpretierbarkeit zu verbessern. In diesem Artikel konzentrieren wir uns hauptsächlich auf Klassifizierungsaufgaben und wählen die neuesten und aktuellsten aus fünf Aspekten aus:
Gemeinsame Attributionsmethoden, 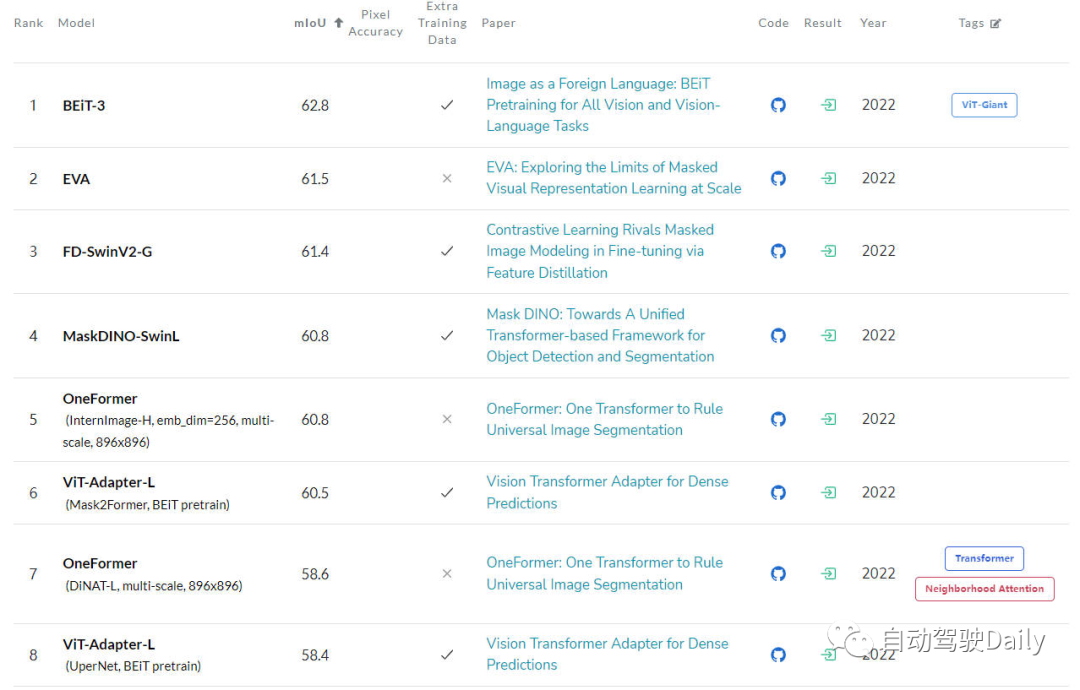 Aufmerksamkeitsbasierte Methoden
Aufmerksamkeitsbasierte Methoden
Beschneidungsbasierte Methoden
,Inhärent erklärbare Methoden
,Andere Aufgaben Klassische Arbeiten werden vorgestellt. Hier ist die Mindmap, die in der Arbeit erscheint. Sie können sie basierend auf Ihren Interessen detaillierter lesen Aus dem Modell beginnen wir mit der Erläuterung des Prozesses, wie die Eingabemerkmale nach und nach das endgültige Ausgabeergebnis erhalten. Diese Art von Methode wird hauptsächlich verwendet, um die Korrelation zwischen den Vorhersageergebnissen des Modells und den Eingabemerkmalen zu messen. Zu diesen Methoden gehören die Algorithmen „Grad-CAM“ und „Integrierte Gradienten“, die direkt auf Algorithmen angewendet werden, die auf visuellen Transformatoren basieren. Einige andere Methoden wie SHAP und Layer-Wise Relevance Propagation (LRP)
wurden verwendet, um ViT-basierte Architekturen zu untersuchen. Aufgrund des sehr hohen Rechenaufwands von Methoden wie SHAP wurde der aktuelleViT Shapely-Algorithmus jedoch so konzipiert, dass er sich an die ViT-bezogene Anwendungsforschung anpasst. Aufmerksamkeitsbasierte MethodenVision Transformer verfügt über leistungsstarke Funktionen zur Merkmalsextraktion durch seinen Aufmerksamkeitsmechanismus. Unter den aufmerksamkeitsbasierten Interpretierbarkeitsmethoden ist die Visualisierung der Ergebnisse der Aufmerksamkeitsgewichtung eine sehr effektive Methode. In diesem Artikel werden verschiedene Visualisierungstechniken vorgestellt
- Raw Attention: Wie der Name schon sagt, besteht diese Methode darin, die aus der mittleren Schicht des Netzwerkmodells erhaltene Aufmerksamkeitsgewichtskarte zu visualisieren, um die Wirkung des Modells zu analysieren.
- Aufmerksamkeits-Rollout: Diese Technologie verfolgt die Übertragung von Informationen von Eingabe-Tokens zu Zwischeneinbettungen, indem sie die Aufmerksamkeitsgewichte in verschiedenen Schichten des Netzwerks erhöht.
- Aufmerksamkeitsfluss: Diese Methode behandelt die Aufmerksamkeitskarte als Flussnetzwerk und verwendet den Maximalflussalgorithmus, um den maximalen Flusswert von der Zwischeneinbettung bis zum Eingabetoken zu berechnen.
- partialLRP: Diese Methode wird zur Visualisierung des Multi-Head-Aufmerksamkeitsmechanismus in Vision Transformer vorgeschlagen, wobei auch die Bedeutung jedes Aufmerksamkeitskopfes berücksichtigt wird.
- Grad-SAM: Diese Methode wird verwendet, um die Einschränkungen zu mildern, die dadurch entstehen, dass man sich zur Erklärung von Modellvorhersagen ausschließlich auf die ursprüngliche Aufmerksamkeitsmatrix verlässt, und veranlasst Forscher, Gradienten in den ursprünglichen Aufmerksamkeitsgewichten zu verwenden.
- Jenseits der Intuition: Diese Methode ist auch eine Methode zur Erklärung von Aufmerksamkeit, einschließlich zwei Stufen der Aufmerksamkeitswahrnehmung und des Argumentationsfeedbacks.
Abschließend finden Sie hier ein Aufmerksamkeitsvisualisierungsdiagramm verschiedener Interpretierbarkeitsmethoden. Sie können den Unterschied zwischen verschiedenen Visualisierungsmethoden selbst spüren.

Vergleich von Aufmerksamkeitskarten verschiedener Visualisierungsmethoden
Pruning-basierte Methoden
Pruning ist eine sehr effektive Methode, die häufig zur Optimierung der Effizienz und Komplexität der Transformatorstruktur eingesetzt wird. Die Bereinigungsmethode reduziert die Anzahl der Parameter und die Rechenkomplexität des Modells, indem redundante oder nutzlose Informationen gelöscht werden. Obwohl sich Bereinigungsalgorithmen auf die Verbesserung der Recheneffizienz des Modells konzentrieren, kann diese Art von Algorithmus dennoch eine Interpretierbarkeit des Modells erreichen.
Die auf Vision-Transformer basierenden Bereinigungsmethoden in diesem Artikel lassen sich grob in drei Kategorien einteilen: explizit erklärbar (explizit erklärbar), implizit erklärbar (implizit erklärbar), möglicherweise erklärbar (möglicherweise erklärbar) erklären).
-
Explizit erklärbar
Unter den auf Beschneidung basierenden Methoden gibt es mehrere Arten von Methoden, die einfachere und besser erklärbare Modelle liefern können.
- IA-RED^2: Ziel dieser Methode ist es, ein optimales Gleichgewicht zwischen Recheneffizienz und Interpretierbarkeit des Algorithmusmodells zu erreichen. Dabei bleibt die Flexibilität des ursprünglichen ViT-Algorithmusmodells erhalten.
- X-Pruner: Bei dieser Methode handelt es sich um eine Methode zum Bereinigen von Salienzeinheiten durch Erstellen einer interpretierbaren Wahrnehmungsmaske, die den Beitrag jeder vorhersagbaren Einheit bei der Vorhersage einer bestimmten Klasse misst.
- Vision DiffMask: Diese Beschneidungsmethode umfasst das Hinzufügen eines Gating-Mechanismus zu jeder ViT-Schicht. Durch den Gating-Mechanismus kann die Ausgabe des Modells beibehalten und gleichzeitig die Eingabe abgeschirmt werden. Darüber hinaus kann das algorithmische Modell eindeutig eine Teilmenge der verbleibenden Bilder auslösen, was ein besseres Verständnis der Vorhersagen des Modells ermöglicht.
-
Implizit erklärbar
Unter den Pruning-basierten Methoden gibt es auch einige klassische Methoden, die in die Kategorie der impliziten Erklärbarkeitsmodelle eingeteilt werden können. - Dynamic ViT: Diese Methode verwendet ein leichtes Vorhersagemodul, um die Bedeutung jedes Tokens basierend auf den aktuellen Eigenschaften abzuschätzen. Dieses leichtgewichtige Modul wird dann zu verschiedenen Ebenen von ViT hinzugefügt, um redundante Token hierarchisch zu bereinigen. Am wichtigsten ist, dass diese Methode die Interpretierbarkeit verbessert, indem nach und nach wichtige Bildteile lokalisiert werden, die am meisten zur Klassifizierung beitragen.
- Efficient Vision Transformer (EViT): Die Kernidee dieser Methode besteht darin, EViT durch die Neuorganisation von Token zu beschleunigen. Durch die Berechnung der Aufmerksamkeitswerte behält EViT die relevantesten Tokens bei, während weniger relevante Tokens zu zusätzlichen Tokens zusammengeführt werden. Um die Interpretierbarkeit von EViT zu bewerten, visualisierte der Autor des Papiers gleichzeitig den Token-Erkennungsprozess auf mehreren Eingabebildern.
-
Möglicherweise erklärbar
Obwohl diese Art von Methode ursprünglich nicht dazu gedacht war, die Interpretierbarkeit von ViT zu verbessern, bietet diese Art von Methode großes Potenzial für weitere Forschung zur Interpretierbarkeit des Modells.
- Patch-Verschlankung: Beschleunigen Sie ViT, indem Sie sich durch einen Top-Down-Ansatz auf redundante Patches in Bildern konzentrieren. Der Algorithmus behält selektiv die Fähigkeit wichtiger Patches bei, wichtige visuelle Merkmale hervorzuheben und dadurch die Interpretierbarkeit zu verbessern.
- Hierarchical Visual Transformer (HVT): Diese Methode wird eingeführt, um die Skalierbarkeit und Leistung von ViT zu verbessern. Mit zunehmender Modelltiefe nimmt die Sequenzlänge allmählich ab. Darüber hinaus wird die Recheneffizienz durch die Aufteilung von ViT-Blöcken in mehrere Phasen und die Anwendung von Pooling-Operationen in jeder Phase erheblich verbessert. Angesichts der fortschreitenden Konzentration auf die wichtigsten Komponenten des Modells besteht die Möglichkeit, seine möglichen Auswirkungen auf die Verbesserung der Interpretierbarkeit und Interpretierbarkeit zu untersuchen.
Inhärent erklärbare Methoden
Unter den verschiedenen interpretierbaren Methoden gibt es eine Klasse von Methoden, die hauptsächlich algorithmische Modelle entwickeln, die sie intrinsisch erklären können. Diese Modelle haben jedoch oft Schwierigkeiten, das gleiche Maß an Genauigkeit zu erreichen wie komplexere Black-Box-Methoden Modelle. Daher muss ein sorgfältiges Gleichgewicht zwischen Interpretierbarkeit und Leistung berücksichtigt werden. Als nächstes werden einige klassische Werke kurz vorgestellt.
- ViT-CX: Diese Methode ist eine maskenbasierte Interpretationsmethode, die für das ViT-Modell angepasst ist. Dieser Ansatz basiert auf der Patch-Einbettung und deren Auswirkungen auf die Modellausgabe, anstatt sich darauf zu konzentrieren. Diese Methode besteht aus zwei Phasen: Maskengenerierung und Maskenaggregation, wodurch eine aussagekräftigere Ausprägungskarte bereitgestellt wird.
- ViT-NeT: Bei dieser Methode handelt es sich um einen neuen neuronalen Baumdecoder, der den Entscheidungsprozess durch Baumstrukturen und Prototypen beschreibt. Gleichzeitig ermöglicht der Algorithmus auch eine visuelle Interpretation der Ergebnisse.
- R-Cut: Diese Methode verbessert die Interpretierbarkeit von ViT durch Relationship Weighted Out und Cut. Diese Methode umfasst zwei Module, nämlich die Module „Relationship Weighted Out“ und „Cut“. Ersteres konzentriert sich auf das Extrahieren spezifischer Informationsklassen aus der mittleren Schicht und hebt relevante Merkmale hervor. Letzteres führt eine feinkörnige Merkmalszerlegung durch. Durch die Integration beider Module können dichte klassenspezifische Interpretierbarkeitskarten generiert werden.
Andere Aufgaben
Die ViT-basierte Architektur muss für andere Computer-Vision-Aufgaben in der Erkundung noch erklärt werden. Einige Interpretierbarkeitsmethoden wurden speziell für andere Aufgaben vorgeschlagen, und die neuesten Arbeiten in verwandten Bereichen werden im Folgenden vorgestellt
- eX-ViT: Dieser Algorithmus ist ein neuer interpretierbarer visueller Transformator, der auf einer schwach überwachten semantischen Segmentierung basiert. Um die Interpretierbarkeit zu verbessern, wird außerdem ein attributorientiertes Verlustmodul eingeführt, das drei Verluste enthält: attributorientierter Verlust auf globaler Ebene, Attributunterscheidbarkeitsverlust auf lokaler Ebene und Attributdiversitätsverlust. Ersteres verwendet Aufmerksamkeitskarten, um interpretierbare Merkmale zu erstellen, während die beiden letzteren das Lernen von Attributen verbessern.
- DINO: Diese Methode ist eine einfache selbstüberwachte Methode und eine Selbstdestillationsmethode ohne Etiketten. Die endgültig erlernte Aufmerksamkeitskarte kann die semantischen Bereiche des Bildes effektiv beibehalten und so interpretierbare Zwecke erreichen.
- Generisches Aufmerksamkeitsmodell: Diese Methode ist ein Algorithmusmodell zur Vorhersage basierend auf der Transformer-Architektur. Die Methode wird auf die drei am häufigsten verwendeten Architekturen angewendet, nämlich reine Selbstaufmerksamkeit, Selbstaufmerksamkeit kombiniert mit gemeinsamer Aufmerksamkeit und Encoder-Decoder-Aufmerksamkeit. Um die Interpretierbarkeit des Modells zu testen, verwendeten die Autoren eine visuelle Frage-Antwort-Aufgabe, sie ist jedoch auch auf andere CV-Aufgaben wie Objekterkennung und Bildsegmentierung anwendbar.
- ATMAN: Dies ist eine modalitätsunabhängige Störungsmethode, die einen Aufmerksamkeitsmechanismus verwendet, um eine Korrelationskarte der Eingabe relativ zur Ausgabevorhersage zu erstellen. Dieser Ansatz versucht, die Deformationsvorhersage durch gedächtniseffiziente Aufmerksamkeitsoperationen zu verstehen.
- Concept-Transformer: Dieser Algorithmus generiert Erklärungen zu Modellausgaben, indem er Aufmerksamkeitswerte für benutzerdefinierte Konzepte auf hoher Ebene hervorhebt und so Vertrauenswürdigkeit und Zuverlässigkeit gewährleistet.
Zukunftsausblick
Derzeit haben auf der Transformer-Architektur basierende Algorithmusmodelle bei verschiedenen Computer-Vision-Aufgaben hervorragende Ergebnisse erzielt. Derzeit mangelt es jedoch an offensichtlicher Forschung darüber, wie mithilfe von Interpretierbarkeitsmethoden das Debuggen und Verbessern von Modellen gefördert und die Modellgerechtigkeit und -zuverlässigkeit verbessert werden kann, insbesondere in ViT-Anwendungen
Dieser Artikel zielt darauf ab, eine Bildklassifizierung basierend auf den Interpretierbarkeitsalgorithmusmodellen von durchzuführen Vision Transformer sind klassifiziert und organisiert, um den Lesern ein besseres Verständnis der Architektur solcher Modelle zu ermöglichen.

Was neu geschrieben werden muss, ist: Originallink: https://mp.weixin.qq. com/s/URkobeRNB8dEYzrECaC7tQ
Das obige ist der detaillierte Inhalt vonEin tieferes Verständnis des visuellen Transformators, Analyse des visuellen Transformators. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!