
Heim >Technologie-Peripheriegeräte >KI >Zhiyuan und andere Institutionen haben die Multi-Skill-Governance-Strategie für große Modelle des LM-Cocktail-Modells veröffentlicht
Zhiyuan und andere Institutionen haben die Multi-Skill-Governance-Strategie für große Modelle des LM-Cocktail-Modells veröffentlicht

- PHPznach vorne
- 2023-12-14 18:31:021033Durchsuche
Mit der Entwicklung und Implementierung großer Modelltechnologie ist „Model Governance“ zu einem Thema geworden, das derzeit große Aufmerksamkeit erhält. In der Praxis stehen Forscher jedoch häufig vor mehreren Herausforderungen.
Um die Leistung bei der Zielaufgabe zu verbessern, sammeln und erstellen Forscher einerseits Zielaufgabendatensätze und optimieren das große Sprachmodell (LLM), aber dieser Ansatz führt normalerweise zu anderen Problemen als Die Leistung allgemeiner Aufgaben wird erheblich reduziert, wodurch die ursprünglichen allgemeinen Fähigkeiten von LLM beeinträchtigt werden.
Andererseits nimmt die Anzahl der Modelle in der Open-Source-Community allmählich zu, und große Modellentwickler sammeln möglicherweise immer mehr Modelle in mehreren Schulungen an. Jedes Modell hat seine eigenen Vorteile für die Ausführung? Aufgabe oder weitere Feinabstimmung wird stattdessen zum Problem.
Kürzlich veröffentlichte die Information Retrieval and Knowledge Computing Group des Intelligent Source Research Institute die „LM-Cocktail-Modell-Governance-Strategie“ mit dem Ziel, großen Modellentwicklern eine kostengünstige Möglichkeit zur kontinuierlichen Verbesserung der Modellleistung zu bieten: Computing Fusion durch Eine kleine Anzahl von Proben Gewicht, verwenden Sie die Modellfusionstechnologie, um die Vorteile des fein abgestimmten Modells und des Originalmodells zu kombinieren und eine effiziente Nutzung der „Modellressourcen“ zu erreichen.

- Technischer Bericht: https://arxiv.org/abs/2311.13534
- Code: https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail
Die LM-Cocktail-Strategie ähnelt der Zubereitung eines Cocktails. Sie kann die Vorteile und Fähigkeiten jedes Modells zusammenfassen und durch den Einsatz verschiedener Modelle ein „Multitalent“-Modell mit mehreren Spezialitäten schaffen Innovation
Konkret kann LM-Cocktail vorhandene Modelle fusionieren, um ein neues Modell zu generieren, indem das Modellverhältnis manuell ausgewählt oder eine kleine Anzahl von Stichproben eingegeben wird, um Gewichte automatisch zu berechnen Modelle, die sich an verschiedene Strukturen anpassen können, wie z. B. das große Sprachmodell Llama, das semantische Vektormodell BGE usw.
Wenn Entwicklern Etikettendaten für bestimmte Zielaufgaben oder Rechenressourcen für die Modellfeinabstimmung fehlen, können sie die LM-Cocktail-Strategie verwenden, um den Schritt der Modellfeinabstimmung zu eliminieren. Sie müssen nur eine sehr kleine Menge an Datenbeispielen erstellen und können vorhandene große Sprachmodelle in der Open-Source-Community zusammenführen, um Ihren eigenen „LM-Cocktail“ zuzubereiten
Wie in der Abbildung oben gezeigt, Die Feinabstimmung von Llama auf eine bestimmte Zielaufgabe kann die Genauigkeit bei der Zielaufgabe erheblich verbessern, beeinträchtigt jedoch die allgemeinen Fähigkeiten bei anderen Aufgaben. Die Einführung von LM-Cocktail kann dieses Problem lösen.
Der Kern von LM-Cocktail besteht darin, das fein abgestimmte Modell mit den Parametern mehrerer anderer Modelle zu verschmelzen, die Vorteile mehrerer Modelle zu integrieren, die Genauigkeit bei der Zielaufgabe zu verbessern und gleichzeitig die allgemeinen Fähigkeiten bei anderen Aufgaben beizubehalten. Die spezifische Form ist wie folgt: Geben Sie eine Zielaufgabe, ein Basismodell und ein Modell an, das durch Feinabstimmung des Basismodells für die Aufgabe erhalten wird, und sammeln Sie gleichzeitig Modelle aus der Open-Source-Community oder zuvor trainierte Modelle, um eine Sammlung zu bilden. Berechnen Sie das Fusionsgewicht jedes Modells anhand einer kleinen Anzahl von Stichproben für die Zielaufgabe und führen Sie eine gewichtete Summe der Parameter dieser Modelle durch, um ein neues Modell zu erhalten (den spezifischen Prozess finden Sie im Papier oder im Open-Source-Code). . Wenn es in der Open-Source-Community keine anderen Modelle gibt, können das Basismodell und das fein abgestimmte Modell auch direkt integriert werden, um die Leistung nachgelagerter Aufgaben zu verbessern, ohne die allgemeinen Fähigkeiten einzuschränken. 
In tatsächlichen Anwendungsszenarien sind Benutzer aufgrund von Daten- und Ressourcenbeschränkungen möglicherweise nicht in der Lage, nachgelagerte Aufgaben zu optimieren, d. h. es gibt kein Modell, das für die Zielaufgabe optimiert wurde. In diesem Fall können Benutzer eine sehr kleine Menge an Datenproben erstellen und vorhandene große Sprachmodelle in die Community integrieren, um ein Modell für neue Aufgaben zu generieren und die Genauigkeit der Zielaufgabe zu verbessern, ohne das Modell trainieren zu müssen.
Experimentelle Ergebnisse
1. Flexible Feinabstimmung zur Aufrechterhaltung der allgemeinen Fähigkeiten

Wie Sie der obigen Abbildung entnehmen können, hat das optimierte Modell nach der Feinabstimmung einer bestimmten Zielaufgabe die Genauigkeit bei dieser Aufgabe erheblich verbessert, bei anderen allgemeinen Aufgaben ist die Genauigkeit jedoch zurückgegangen. Nach der Feinabstimmung des AG News-Trainingssatzes stieg beispielsweise die Genauigkeit von Llama beim AG News-Testsatz von 40,80 % auf 94,42 %, während die Genauigkeit bei anderen Aufgaben von 46,80 % auf 38,58 % sank.
Durch die einfache Verschmelzung der Parameter des feinabgestimmten Modells und des Originalmodells wird jedoch eine wettbewerbsfähige Leistung von 94,46 % bei der Zielaufgabe erreicht, was mit dem feinabgestimmten Modell vergleichbar ist, während die Genauigkeit 47,73 beträgt % bei anderen Aufgaben, sogar etwas stärker als die Leistung des Originalmodells. Bei bestimmten Aufgaben, wie z. B. Helleswag, kann das Fusionsmodell das fein abgestimmte Modell bei dieser Feinabstimmungsaufgabe sogar übertreffen und das ursprüngliche allgemeine Modell bei anderen Aufgaben übertreffen, während es die Vorteile des fein abgestimmten Modells erbt Das Originalmodell übertrifft es, was ich bekommen habe. Es ist ersichtlich, dass die Berechnung des Fusionsverhältnisses durch LM-Cocktail und die weitere Integration anderer fein abgestimmter Modelle die allgemeine Leistung bei anderen Aufgaben weiter verbessern und gleichzeitig die Genauigkeit der Zielaufgabe sicherstellen kann.
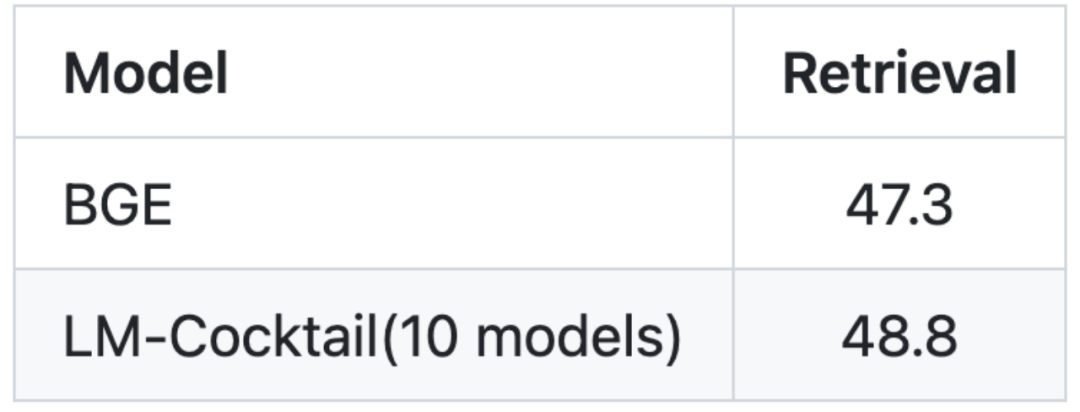
2. Mischen Sie vorhandene Modelle, um neue Aufgaben zu bewältigen. Der Inhalt nach dem Umschreiben: Das Diagramm zeigt die Zielaufgabe des Sprachmodells MMLU. Der Inhalt nach dem Umschreiben: Bild: Die Zielaufgabe des Vektormodells ist das Abrufen (Informationsabruf)
Die Feinabstimmung des Modells erfordert eine große Datenmenge und eine große Menge an Rechenressourcen, insbesondere die Feinabstimmung großer Sprachmodelle, die möglicherweise nicht möglich ist tatsächliche Situationen. Wenn die Zielaufgabe nicht feinabgestimmt werden kann, kann LM-Cocktail neue Fähigkeiten durch die Mischung bestehender Modelle (aus der Open-Source-Community oder seiner eigenen historischen Trainingssammlung) erreichen.
Durch die Angabe von nur 5 Beispieldaten berechnet LM-Cocktail automatisch die Fusionsgewichte, filtert vorhandene Modelle und fusioniert sie dann, um ein neues Modell zu erhalten, ohne große Datenmengen für das Training zu verwenden. Experimente haben ergeben, dass das generierte neue Modell bei neuen Aufgaben eine höhere Genauigkeit erreichen kann. Beispielsweise wird LM-Cocktail für Llama verwendet, um 10 vorhandene Modelle zu verschmelzen (deren Trainingsaufgaben nicht mit der MMLU-Liste zusammenhängen), wodurch erhebliche Verbesserungen erzielt werden können, und ist höher als das Llama-Modell, das 5 Beispieldaten verwendet Kontextlernen.
Bitte versuchen Sie es mit LM-Cocktail. Wir freuen uns über Ihr Feedback und Ihre Vorschläge über die GitHub-Ausgabe: https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail


 Bitte versuchen Sie es mit LM-Cocktail. Wir freuen uns über Ihr Feedback und Ihre Vorschläge über die GitHub-Ausgabe: https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail
Bitte versuchen Sie es mit LM-Cocktail. Wir freuen uns über Ihr Feedback und Ihre Vorschläge über die GitHub-Ausgabe: https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_CocktailDas obige ist der detaillierte Inhalt vonZhiyuan und andere Institutionen haben die Multi-Skill-Governance-Strategie für große Modelle des LM-Cocktail-Modells veröffentlicht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!