
Heim >Technologie-Peripheriegeräte >KI >Alles verbreiten? 3DifFusionDet: Diffusionsmodell tritt in die 3D-Zielerkennung der LV-Fusion ein!
Alles verbreiten? 3DifFusionDet: Diffusionsmodell tritt in die 3D-Zielerkennung der LV-Fusion ein!

- 王林nach vorne
- 2023-12-14 16:51:58850Durchsuche
Das persönliche Verständnis des Autors
In den letzten Jahren war das Diffusionsmodell bei Generierungsaufgaben sehr erfolgreich und wurde natürlich auf Zielerkennungsaufgaben ausgeweitet. Es modelliert die Zielerkennung als Übergang von Rauschboxen zu Objektboxen und entrauscht den Diffusionsprozess . Während der Trainingsphase werden Zielboxen von Ground-Truth-Boxen auf Zufallsverteilungen verteilt, und das Modell lernt, diesen Prozess des Hinzufügens von Rauschen zu Ground-Truth-Boxen umzukehren. Während der Inferenzphase verfeinert das Modell eine Reihe zufällig generierter Zielfelder schrittweise zu Ausgabeergebnissen. Im Vergleich zu herkömmlichen Objekterkennungsmethoden, die auf einem festen Satz lernbarer Abfragen basieren, erfordert 3DifFusionDet keine lernbaren Abfragen zur Objekterkennung.
Die Hauptidee von 3DifFusionDet
Das 3DifFusionDet-Framework stellt die 3D-Zielerkennung als einen rauschunterdrückenden Diffusionsprozess von einer verrauschten 3D-Box zu einer Zielbox dar. In diesem Rahmen werden Ground-Truth-Boxen mit Zufallsverteilungsdiffusion trainiert und das Modell lernt den inversen Rauschprozess. Während der Inferenz verfeinert das Modell nach und nach eine Reihe zufällig generierter Kästchen. Im Rahmen der Feature-Alignment-Strategie kann die progressive Verfeinerungsmethode einen wichtigen Beitrag zur Lidar-Kamera-Fusion leisten. Der iterative Verfeinerungsprozess zeigt auch eine große Anpassungsfähigkeit, indem das Framework auf verschiedene Erkennungsumgebungen angewendet wird, die unterschiedliche Genauigkeits- und Geschwindigkeitsniveaus erfordern. KITTI ist ein Maßstab für die Erkennung realer Verkehrsziele. Es wurden zahlreiche Experimente mit KITTI durchgeführt, die zeigen, dass KITTI im Vergleich zu Frühdetektoren eine gute Leistung erzielen kann. Die Hauptbeiträge von 3DifFusionDet sind wie folgt:
Darstellung von 3D-Zielerkennung Für den generativen Rauschunterdrückungsprozess wird 3DifFusionDet vorgeschlagen, die erste Forschung, die das Diffusionsmodell auf die 3D-Zielerkennung anwendet.- Untersuchen Sie die optimale Kamera-LiDAR-Fusionsausrichtungsstrategie im Rahmen des generativen Rauschunterdrückungsprozesses und schlagen Sie zwei Zweigfusionsausrichtungsstrategien vor, um die von den beiden Modalitäten bereitgestellten komplementären Informationen zu nutzen.
- Ausführliche Experimente zum KITTI-Benchmark durchgeführt. Im Vergleich zu bestehenden, gut konzipierten Methoden erzielt 3DifFusionDet wettbewerbsfähige Ergebnisse und zeigt, dass Diffusionsmodelle bei 3D-Objekterkennungsaufgaben vielversprechend sind.
Für die 3D-Objekterkennung sind Kamera und LiDAR zwei komplementäre Sensortypen. LiDAR-Sensoren konzentrieren sich auf die 3D-Lokalisierung und liefern umfassende Informationen über 3D-Strukturen, während die Kamera Farbinformationen bereitstellt, aus denen umfangreiche semantische Merkmale abgeleitet werden können. Es wurden viele Anstrengungen unternommen, um 3D-Objekte durch die Zusammenführung von Daten von Kameras und LiDAR genau zu erkennen. Moderne Methoden basieren hauptsächlich auf LiDAR-basierten 3D-Objektdetektoren und streben danach, Bildinformationen in verschiedene Phasen des LiDAR-Erkennungsprozesses einzubeziehen, da die Leistung von LiDAR-basierten Erkennungsmethoden deutlich besser ist als die von Kamera- basierte Methoden. Aufgrund der Komplexität von Lidar- und Kamera-basierten Erkennungssystemen führt die Kombination der beiden Modi zwangsläufig zu höheren Rechenkosten und Verzögerungen bei der Inferenzzeit. Daher bleibt das Problem der effektiven Zusammenführung multimodaler Informationen bestehen.
DiffusionsmodellDas Diffusionsmodell ist ein generatives Modell, das die beobachteten Daten durch Einführung von Rauschen schrittweise dekonstruiert und die ursprünglichen Daten durch Umkehrung des Prozesses wiederherstellt. Diffusionsmodelle und Entrauschungs-Score-Matching sind durch das Entrauschungs-Diffusions-Wahrscheinlichkeitsmodell (Ho, Jain und Abbeel 2020a) verbunden, das kürzlich Interesse an Computer-Vision-Anwendungen geweckt hat. Es wurde in vielen Bereichen angewendet, beispielsweise bei der Diagrammerstellung, beim Sprachverständnis, beim robusten Lernen und bei der Modellierung zeitlicher Daten.
Diffusionsmodelle haben große Erfolge bei der Bilderzeugung und -synthese erzielt. Einige Pionierarbeiten übernehmen Diffusionsmodelle für Bildsegmentierungsaufgaben. Im Vergleich zu diesen Feldern ist ihr Potenzial zur Objekterkennung noch nicht vollständig ausgeschöpft. Bisherige Ansätze zur Objekterkennung mithilfe von Diffusionsmodellen waren auf 2D-Begrenzungsrahmen beschränkt. Im Vergleich zur 2D-Erkennung liefert die 3D-Erkennung umfassendere Zielrauminformationen und kann eine genaue Tiefenwahrnehmung und ein Volumenverständnis erreichen, was für Anwendungen wie das autonome Fahren von entscheidender Bedeutung ist, bei denen die genaue Ermittlung der Entfernung zu umgebenden Fahrzeugen und der Richtung wichtige Aspekte sind für Anwendungen wie autonomes Fahren.Abbildung 1 zeigt die Gesamtarchitektur von 3DifFusionDet. Es akzeptiert multimodale Eingaben, einschließlich RGB-Bildern und Punktwolken. Wenn das gesamte Modell wie bei DiffusionDet in Teile zur Merkmalsextraktion und zur Merkmalsdekodierung unterteilt wird, wäre es schwierig,
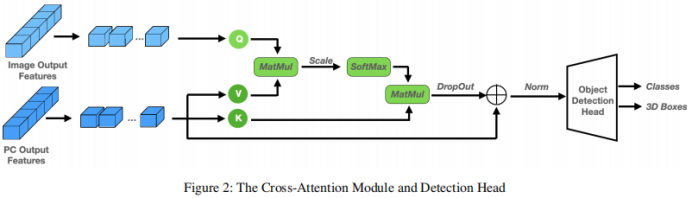
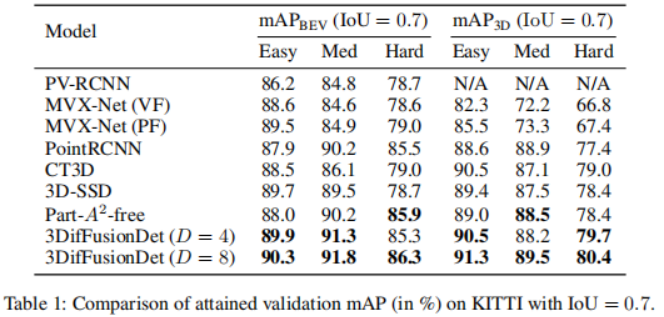
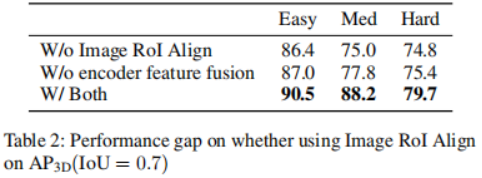
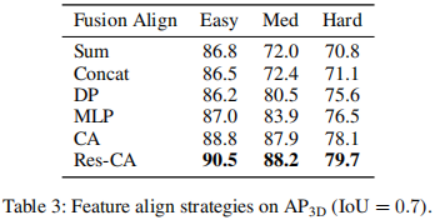
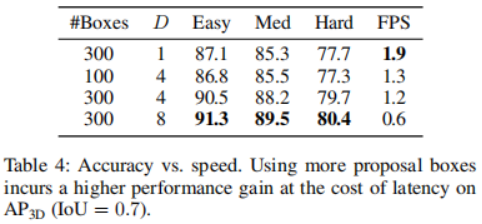
in jedem Iterationsschritt direkt auf die ursprünglichen 3D-Merkmale anzuwenden. Der Merkmalsextraktionsteil wird nur einmal ausgeführt, um tiefe Merkmalsdarstellungen aus der ursprünglichen Eingabe Um die komplementären Informationen der beiden Modalitäten vollständig zu nutzen, sind Encoder und Decoder jeder Modalität getrennt. Darüber hinaus werden der Bilddecoder und der Punktwolkendecoder separat trainiert, um 2D- und 3D-Merkmale mithilfe eines Diffusionsmodells zu verfeinern, um jeweils Rauschboxen zu erzeugen. Was die Verbindung dieser beiden Funktionszweige betrifft, führt eine einfache Verbindung zu einer Informationsscherung, was zu einer Leistungsverschlechterung führt. Zu diesem Zweck wird ein Multi-Head-Cross-Attention-Mechanismus eingeführt, um diese Merkmale tiefgreifend auszurichten. Diese ausgerichteten Merkmale werden in den Erkennungskopf eingegeben, um den endgültigen wahren Wert vorherzusagen, ohne Rauschen zu erzeugen. Für den Punktwolken-Encoder werden voxelbasierte Methoden zur Extraktion und spärliche Methoden zur Verarbeitung verwendet. Voxelbasierte Methoden wandeln LiDAR-Punkte in Voxel um. Im Vergleich zu anderen Methoden zur Punktmerkmalsextraktion (z. B. punktbasierten Methoden) diskretisieren diese Methoden Punktwolken in gleichmäßig verteilte 3D-Gitter, wodurch der Speicherbedarf reduziert wird und gleichzeitig die ursprünglichen 3D-Forminformationen so weit wie möglich erhalten bleiben. Die auf Sparsity basierende Verarbeitungsmethode hilft dem Netzwerk außerdem, die Recheneffizienz zu verbessern. Diese Vorteile gleichen den relativ hohen Rechenaufwand von Diffusionsmodellen aus. Im Vergleich zu 2D-Features enthalten 3D-Features zusätzliche Dimensionen, was das Lernen schwieriger macht. Vor diesem Hintergrund wird zusätzlich zum Extrahieren von Merkmalen aus der ursprünglichen Modalität ein Fusionspfad hinzugefügt, der die extrahierten Bildmerkmale als weitere Eingabe zum Punktencoder hinzufügt, was den Informationsaustausch erleichtert und das Lernen aus vielfältigeren Quellen nutzt. Es kommt eine PointFusion-Strategie zum Einsatz, bei der Punkte vom LiDAR-Sensor auf die Bildebene projiziert werden. Die Verkettung von Bildmerkmalen und entsprechenden Punkten wird dann gemeinsam von der VoxelNet-Architektur verarbeitet. Feature-Decoder. Die extrahierten Bildmerkmale und extrahierten Punktmerkmale werden als Eingaben für die entsprechenden Bild- und Punktdecoder verwendet. Jeder Decoder kombiniert auch Eingaben von einer einzigartig erstellten Noise-Box oder und lernt, zusätzlich zu den entsprechenden extrahierten Features 2D- bzw. 3D-Features zu verfeinern. Inspiriert von Sparse RCNN empfängt der Bilddecoder Eingaben aus einer Sammlung von 2D-Vorschlagsfeldern und schneidet RoI-Features aus der vom Bildencoder erstellten Feature-Map aus. Der Punktdecoder empfängt Eingaben aus einer Sammlung von 3D-Vorschlagsfeldern und schneidet die RoI-Features aus der vom Bildencoder erstellten Feature-Map aus. Für den Punktdecoder ist die Eingabe ein Satz von 3D-Vorschlagsfeldern zum Zuschneiden von 3D-RoI-Features aus der vom Punktencoder generierten Feature-Map Cross Attention Module. Nach der Dekodierung der beiden Feature-Zweige muss eine Möglichkeit gefunden werden, diese zu kombinieren. Ein unkomplizierter Ansatz besteht darin, die beiden Feature-Branches einfach durch Verbinden zu verbinden. Diese Methode erscheint zu grob und kann dazu führen, dass das Modell unter Informationsscherung leidet, was zu Leistungseinbußen führt. Daher wird ein Multi-Head-Cross-Attention-Mechanismus eingeführt, um diese Merkmale genau auszurichten und zu verfeinern, wie in Abbildung 1 dargestellt. Insbesondere wird die Ausgabe des Punktdecoders als Quelle von k und v behandelt, während die Ausgabe des Bilddecoders auf q projiziert wird. Experimente, die mit dem KITTI 3D-Objekterkennungs-Benchmark durchgeführt wurden. In Anlehnung an das Standard-KITTI-Bewertungsprotokoll zur Messung der Erkennungsleistung (IoU = 0,7) zeigt Tabelle 1 den mittleren Präzisionswert (mAP) der 3DifFusionDet-Methode im Vergleich zu den modernsten Methoden des KITTI-Validierungssatzes. Meldet die Leistung von , folgt [diffusionDet, difficileist] und markiert die beiden Modelle mit der besten Leistung für jede Aufgabe. Den Ergebnissen in Tabelle 1 zufolge zeigt die Methode dieser Studie eine deutliche Leistungsverbesserung im Vergleich zum Ausgangswert. Bei D=4 ist die Methode in der Lage, die meisten Basismodelle in kürzerer Inferenzzeit zu übertreffen. Bei einer weiteren Erhöhung von D auf 8 wird die beste Leistung aller Modelle erreicht, obwohl die Inferenzzeit länger ist. Diese Flexibilität zeigt, dass diese Methode ein breites Spektrum potenzieller Anwendungen bietet. Um einen 3D-Objektdetektor aus Kamera und LiDAR unter Verwendung von Diffusionsmodellen zu entwerfen, sollte der einfachste Ansatz darin bestehen, die generierten verrauschten 3D-Boxen direkt als Eingabe für fusionierte 3D-Features anzuwenden. Dieser Ansatz kann jedoch durch Informationsscherung beeinträchtigt werden, was zu Leistungseinbußen führt, wie in Tabelle 2 dargestellt. Auf diese Weise erstellen wir nicht nur die Punktwolke RoIAlign unter den codierten 3D-Features, sondern erstellen auch einen zweiten Zweig, der das Bild RoIAlign unter den codierten 2D-Features platziert. Die deutlich verbesserte Leistung lässt darauf schließen, dass die komplementären Informationen beider Modi besser genutzt werden können. Dann analysieren wir die Auswirkungen verschiedener Fusionsstrategien: Wie können wir sie angesichts der erlernten 2D- und 3D-Darstellungsfunktionen effektiver kombinieren? Im Vergleich zu 2D-Features haben 3D-Features eine zusätzliche Dimension, was den Lernprozess anspruchsvoller macht. Wir fügen einen Informationsflusspfad von Bildmerkmalen zu Punktmerkmalen hinzu, indem wir Punkte vom LiDAR-Sensor auf Bildmerkmale projizieren und sie mit entsprechenden Punkten zur gemeinsamen Verarbeitung verketten. Dies ist die VoxelNet-Architektur. Wie aus Tabelle 3 ersichtlich ist, hat diese Fusionsstrategie große Vorteile für die ErkennungsgenauigkeitDer andere Teil, der fusioniert werden muss, ist die Verbindung der beiden Merkmalszweige nach der Dekodierung. Hier wird ein Multi-Head-Cross-Attention-Mechanismus angewendet, um diese Merkmale genau auszurichten und zu verfeinern. Darüber hinaus wurden auch direktere Methoden wie die Verwendung von Verkettungsoperationen, Summationsoperationen, direkten Produktoperationen und die Verwendung von Multilayer-Perzeptronen (MLP) untersucht. Die Ergebnisse sind in Tabelle 4 dargestellt. Unter diesen zeigt der Kreuzaufmerksamkeitsmechanismus die beste Leistung bei nahezu gleicher Trainings- und Inferenzgeschwindigkeit. Untersuchen Sie den Kompromiss zwischen Genauigkeit und Inferenzgeschwindigkeit. Die Auswirkung der Auswahl verschiedener Vorschlagsboxen und D wird durch den Vergleich der 3D-Erkennungsgenauigkeit und der Bilder pro Sekunde (FPS) gezeigt. Die Anzahl der Vorschlagsboxen wird aus 100, 300 gewählt, während D aus 1, 4, 8 gewählt wird. Die Laufzeit wird auf einer einzelnen NVIDIA RTX A6000 GPU mit einer Stapelgröße von 1 ausgewertet. Es wurde festgestellt, dass die Erhöhung der Anzahl der Vorschlagsboxen von 100 auf 300 zu erheblichen Genauigkeitsgewinnen bei vernachlässigbaren Latenzkosten führte (1,3 FPS gegenüber 1,2 FPS). Andererseits führt eine bessere Erkennungsgenauigkeit zu einer längeren Inferenzzeit. Beim Ändern von D von 1 auf 8 erhöht sich die 3D-Erkennungsgenauigkeit von scharf (einfach: 87,1 mAP auf 90,5 mAP) auf relativ langsam (einfach: 90,5 AP auf 91,3 mAP), während die FPS weiter abnimmt. Fallforschung und zukünftige ArbeitBasierend auf seinen einzigartigen Eigenschaften werden in diesem Artikel die möglichen Einsatzmöglichkeiten von 3DifFusionDet erörtert. Im Allgemeinen sind genaue, robuste und Echtzeit-Inferenz drei Anforderungen für Objekterkennungsaufgaben. Im Bereich der Wahrnehmung autonomer Fahrzeuge reagieren Wahrnehmungsmodelle besonders empfindlich auf Echtzeitanforderungen, da Autos, die mit hoher Geschwindigkeit fahren, aufgrund der Trägheit zusätzliche Zeit und Distanz aufwenden müssen, um langsamer zu werden oder die Richtung zu ändern. Noch wichtiger: Um ein komfortables Fahrerlebnis zu gewährleisten, sollte das Auto unter der Prämisse der Sicherheit so ruhig wie möglich mit dem kleinsten absoluten Beschleunigungswert fahren. Einer der Hauptvorteile ist ein angenehmeres Fahrerlebnis im Vergleich zu anderen ähnlichen Produkten für selbstfahrende Autos. Dazu müssen selbstfahrende Autos schnell reagieren, egal ob sie beschleunigen, abbremsen oder abbiegen. Je schneller das Auto reagiert, desto mehr Spielraum hat es für nachfolgende Manöver und Anpassungen. Dies ist wichtiger, als zunächst die genaueste Klassifizierung oder Position des erkannten Ziels zu ermitteln: Wenn das Auto anfängt zu reagieren, bleibt noch Zeit und Distanz, um sein Verhalten anzupassen, was für genauere weitere Entscheidungen genutzt werden kann Die hochgerechneten Ergebnisse werden dann zur Feinabstimmung des Fahrverhaltens des Autos verwendet. Der umgeschriebene Inhalt lautet wie folgt: Gemäß den Ergebnissen in Tabelle 4 kann unser 3DifFusionDet-Modell bei kleiner Inferenzschrittgröße eine Inferenz schnell durchführen und eine relativ hohe Genauigkeit erzielen. Diese anfängliche Wahrnehmung ist präzise genug, um dem selbstfahrenden Auto die Entwicklung neuer Reaktionen zu ermöglichen. Mit zunehmender Anzahl der Inferenzschritte können wir genauere Objekterkennungen generieren und unsere Antworten weiter verfeinern. Dieser fortschrittliche Erkennungsansatz ist für unsere Aufgabe ideal geeignet. Da unser Modell außerdem die Anzahl der Vorschlagsfelder während der Inferenz anpassen kann, können wir die aus kleinen Schritten gewonnenen Vorinformationen nutzen, um die Anzahl der Echtzeit-Vorschlagsfelder zu optimieren. Den Ergebnissen in Tabelle 4 zufolge ist auch die Leistung unter verschiedenen A-priori-Vorschlagsrahmen unterschiedlich. Daher ist die Entwicklung solcher adaptiven Detektoren eine vielversprechende Arbeit Mit Ausnahme selbstfahrender Autos entspricht das Modell dieser Arbeit im Wesentlichen jedem realen Szenario, das eine kurze Inferenzzeit in einem kontinuierlichen Reaktionsraum erfordert, insbesondere wenn der Detektor auf In basiert die Szene, in der sich die Erkennungsergebnisse bewegen. Dank der Eigenschaften des Diffusionsmodells kann 3DifFusionDet schnell einen nahezu genauen realen Interessenbereich finden und die Maschine dazu veranlassen, neue Vorgänge und Selbstoptimierungen zu starten. Nachfolgende Perzeptrone mit höherer Präzision optimieren den Betrieb der Maschine weiter. Um Modelle in diese Bewegungsmelder einzusetzen, sind Strategien zum Kombinieren von Inferenzinformationen zwischen früheren Inferenzen in größeren Schritten und neueren Inferenzen in kleineren Schritten eine offene Frage, und dies ist eine weitere offene Frage. In diesem Artikel wird ein neuer 3D-Objektdetektor namens 3DifFusionDet vorgestellt, der über leistungsstarke LiDAR- und Kamerafusionsfunktionen verfügt. Dies ist die erste Arbeit, die die 3D-Objekterkennung als generativen Rauschunterdrückungsprozess formuliert und Diffusionsmodelle auf die 3D-Objekterkennung anwendet. Im Zusammenhang mit der Generierung eines Entrauschungsprozess-Frameworks untersucht diese Studie die effektivste Strategie zur Kamera-Lidar-Fusionsausrichtung und schlägt eine Fusionsausrichtungsstrategie vor, um die von beiden Modi bereitgestellten komplementären Informationen vollständig auszunutzen. Im Vergleich zu ausgereiften Detektoren schneidet 3DifFusionDet gut ab und demonstriert die breiten Anwendungsaussichten von Diffusionsmodellen bei Objekterkennungsaufgaben. Seine leistungsstarken Lernergebnisse und sein flexibles Argumentationsmodell ermöglichen ein breites Einsatzpotenzial Originallink: https://mp.weixin.qq.com/s/0Fya4RYelNUU5OdAQp9DVA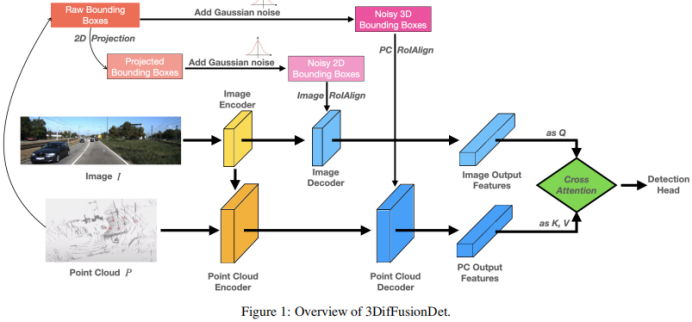
Experimentelle Ergebnisse
Zusammenfassung

Das obige ist der detaillierte Inhalt vonAlles verbreiten? 3DifFusionDet: Diffusionsmodell tritt in die 3D-Zielerkennung der LV-Fusion ein!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierte Einführung in den Grafik- und Textcode zum Erstellen von 3D-Szenen basierend auf der HTML5-WebGL-Technologie (1)
- So exportieren Sie ein Modell in Navicat
- Was sind in der Datenbanktechnologie die vier wichtigsten Datenmodelle?
- Eine weitere Revolution im Reinforcement Learning! DeepMind schlägt eine „Algorithmus-Destillation' vor: einen erforschbaren, vorab trainierten Reinforcement-Learning-Transformer
- So verwenden Sie PyTorch für das Training neuronaler Netzwerke