Das sind die Erfahrungen des Autors Sebastian Raschka nach Hunderten von Experimenten. Es lohnt sich, sie zu lesen.
Die Erhöhung der Datenmenge und Modellparameter gilt als der direkteste Weg, die Leistung neuronaler Netze zu verbessern. Gegenwärtig hat sich die Anzahl der Parameter großer Mainstream-Modelle auf Hunderte Milliarden erhöht, und der Trend, dass „große Modelle“ immer größer werden, wird immer intensiver. Dieser Trend hat viele Herausforderungen bei der Rechenleistung mit sich gebracht. Wenn Sie ein großes Sprachmodell mit Hunderten von Milliarden Parametern verfeinern möchten, dauert das Training nicht nur lange, sondern erfordert auch viele leistungsstarke Speicherressourcen. Um die Kosten für die Feinabstimmung großer Modelle zu „senken“, haben Microsoft-Forscher die Low-Rank-Adaptive-Technologie (LoRA) entwickelt. Die Feinheit von LoRA besteht darin, dass es dem Hinzufügen eines abnehmbaren Plug-Ins zum ursprünglichen großen Modell entspricht und der Hauptkörper des Modells unverändert bleibt. LoRA ist Plug-and-Play, leicht und praktisch. Für die effiziente Feinabstimmung einer benutzerdefinierten Version eines großen Sprachmodells ist LoRA eine der am weitesten verbreiteten und auch effektivsten Methoden. Wenn Sie sich für Open-Source-LLM interessieren, ist LoRA eine grundlegende Technologie, die es wert ist, erlernt zu werden und die Sie sich nicht entgehen lassen sollten. Sebastian Raschka, Professor für Datenwissenschaft an der University of Wisconsin-Madison, führte ebenfalls eine umfassende Untersuchung von LoRA durch. Da er sich seit vielen Jahren mit dem Gebiet des maschinellen Lernens beschäftigt, liegt ihm die Zerlegung komplexer technischer Konzepte sehr am Herzen. Nach Hunderten von Experimenten fasste Sebastian Raschka seine Erfahrungen beim Einsatz von LoRA zur Feinabstimmung großer Modelle zusammen und veröffentlichte sie im Magazin Ahead of AI. 
Auf der Grundlage der Beibehaltung der ursprünglichen Absicht des Autors hat diese Website diesen Artikel zusammengestellt: Letzten Monat habe ich einen Artikel über das LoRA-Experiment geteilt, der hauptsächlich auf dem Artikel basierte, den meine Kollegen und ich bei Lightning gepflegt haben AI Open-Source-Lit-GPT-Bibliothek, in der die wichtigsten Erfahrungen und Lehren aus meinen Experimenten besprochen werden. Darüber hinaus werde ich einige häufig gestellte Fragen zur LoRA-Technologie beantworten. Wenn Sie an der Feinabstimmung benutzerdefinierter großer Sprachmodelle interessiert sind, hoffe ich, dass Ihnen diese Erkenntnisse dabei helfen, schnell loszulegen. Kurz gesagt, die wichtigsten Punkte, die ich in diesem Artikel bespreche, sind:
- Obwohl das LLM-Training (oder alle auf der GPU trainierten Modelle) unvermeidlich Zufälligkeit aufweist, sind die Ergebnisse des Multi-Lun-Trainings immer noch sehr konsistent.
- Wenn Sie durch den GPU-Speicher begrenzt sind, bietet QLoRA einen kostengünstigen Kompromiss. Es spart 33 % Speicher auf Kosten einer 39 % längeren Laufzeit.
- Bei der Feinabstimmung von LLM ist die Wahl des Optimierers nicht der Hauptfaktor, der die Ergebnisse beeinflusst. Ob AdamW, SGD mit Scheduler oder AdamW mit Scheduler, die Auswirkungen auf die Ergebnisse sind minimal.
- Während Adam oft als speicherintensiver Optimierer angesehen wird, weil er für jeden Modellparameter zwei neue Parameter einführt, hat dies keinen wesentlichen Einfluss auf den Spitzenspeicherbedarf von LLM. Dies liegt daran, dass der größte Teil des Speichers für die Multiplikation großer Matrizen reserviert wird und nicht für die Speicherung zusätzlicher Parameter.
- Bei statischen Datensätzen funktionieren mehrere Iterationen wie mehrere Trainingsrunden möglicherweise nicht gut. Dies führt häufig zu einer Überanpassung und einer Verschlechterung der Trainingsergebnisse.
- Wenn Sie LoRA kombinieren möchten, stellen Sie sicher, dass es auf allen Ebenen angewendet wird, nicht nur auf der Schlüssel- und Wertmatrix, um die Leistung des Modells zu maximieren.
- Es ist wichtig, den LoRA-Rang anzupassen und den geeigneten α-Wert zu wählen. Als Tipp: Versuchen Sie, den α-Wert auf das Doppelte des Rangwerts festzulegen.
- Eine einzelne GPU mit 14 GB RAM kann große Modelle mit 7 Milliarden Parametern in wenigen Stunden effizient optimieren. Bei statischen Datensätzen ist es unmöglich, LLM zu einem „Allrounder“ zu machen und bei allen Basisaufgaben gute Leistungen zu erbringen. Um dieses Problem zu lösen, müssen die Datenquellen diversifiziert oder andere Technologien als LoRA verwendet werden.
Außerdem beantworte ich zehn häufig gestellte Fragen zu LoRA. Wenn Leser interessiert sind, werde ich eine weitere umfassendere Einführung in LoRA schreiben, einschließlich detaillierten Codes zur Implementierung von LoRA von Grund auf. Der heutige Artikel befasst sich hauptsächlich mit Schlüsselthemen bei der Verwendung von LoRA. Bevor wir offiziell beginnen, wollen wir noch einige Grundkenntnisse hinzufügen. Das Aktualisieren der Modellgewichte während des Trainings ist aufgrund von GPU-Speicherbeschränkungen teuer. Angenommen, wir haben ein 7B-Parameter-Sprachmodell, dargestellt durch eine Gewichtsmatrix W. Während der Backpropagation muss das Modell eine ΔW-Matrix lernen, mit dem Ziel, die ursprünglichen Gewichte zu aktualisieren, um den Verlustfunktionswert zu minimieren. Das Gewicht wird wie folgt aktualisiert: W_updated = W + ΔW. Wenn die Gewichtsmatrix W 7B-Parameter enthält, enthält die Gewichtsaktualisierungsmatrix ΔW auch 7B-Parameter. Die Berechnung der Matrix ΔW ist sehr rechenintensiv und speicherintensiv. LoRA, vorgeschlagen von Edward Hu et al., zerlegt den Teil ΔW der Gewichtsänderungen in eine Darstellung mit niedrigem Rang. Insbesondere ist keine explizite Berechnung von ΔW erforderlich. Stattdessen lernt LoRA während des Trainings die zerlegte Darstellung von ΔW, wie in der folgenden Abbildung dargestellt. Dies ist das Geheimnis der Einsparung von Rechenressourcen durch LoRA. 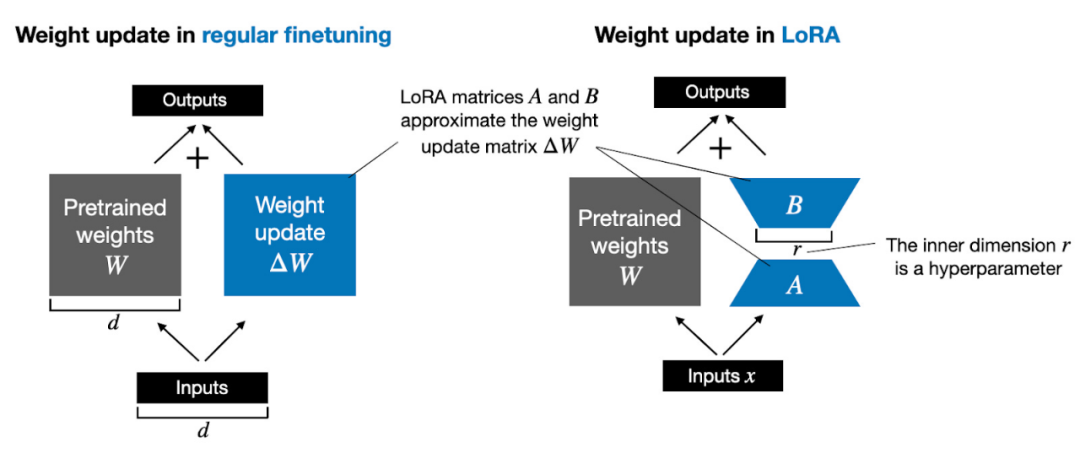
Wie oben gezeigt, bedeutet die Zerlegung von ΔW, dass wir zwei kleinere LoRA-Matrizen A und B verwenden müssen, um die größere Matrix ΔW darzustellen. Wenn A die gleiche Anzahl an Zeilen wie ΔW und B die gleiche Anzahl an Spalten wie ΔW hat, können wir die obige Zerlegung als ΔW = AB schreiben. (AB ist das Ergebnis der Matrixmultiplikation zwischen den Matrizen A und B.) Wie viel Speicher spart diese Methode? Es hängt auch vom Rang r ab, der ein Hyperparameter ist. Wenn ΔW beispielsweise 10.000 Zeilen und 20.000 Spalten hat, müssen 200.000.000 Parameter gespeichert werden. Wenn wir A und B mit r=8 wählen, dann hat A 10.000 Zeilen und 8 Spalten und B hat 8 Zeilen und 20.000 Spalten, was 10.000 × 8 + 8 × 20.000 = 240.000 Parametern entspricht, was etwa 830-mal weniger als 200.000.000 ist Parameter. Natürlich können A und B nicht alle von ΔW abgedeckten Informationen erfassen, aber dies wird durch das Design von LoRA bestimmt. Bei der Verwendung von LoRA gehen wir davon aus, dass das Modell W eine große Matrix mit vollem Rang ist, um das gesamte Wissen im Datensatz vor dem Training zu sammeln. Wenn wir LLM optimieren, müssen wir nicht alle Gewichte aktualisieren, sondern nur weniger Gewichte als ΔW aktualisieren, um die Kerninformationen zu erfassen. Auf diese Weise wird die Aktualisierung mit niedrigem Rang über die AB-Matrix implementiert. Obwohl die Zufälligkeit von LLM oder dem auf der GPU trainierten Modell unvermeidlich ist, wurde LoRA zur Durchführung mehrerer Experimente verwendet und die endgültigen Benchmark-Ergebnisse von LLM wurden getestet Verschiedene Tests Die Konzentration zeigte eine erstaunliche Konsistenz. Dies ist eine gute Grundlage für die Durchführung weiterer vergleichender Studien. 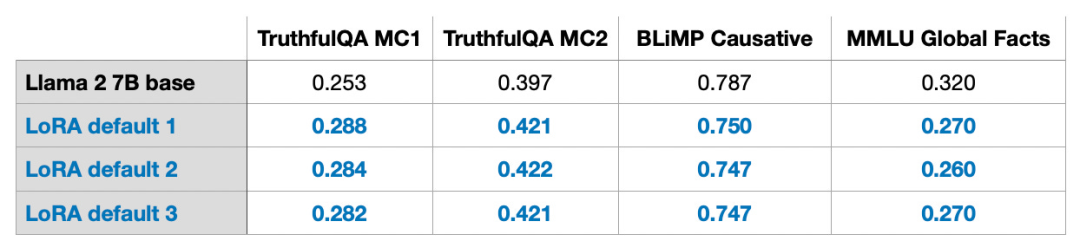
Bitte beachten Sie, dass diese Ergebnisse mit Standardeinstellungen und einem kleinen Wert von r=8 ermittelt wurden. Experimentelle Details finden Sie in meinem anderen Artikel. Artikellink: https://lightning.ai/pages/community/lora-insights/QLoRA-Berechnung – SpeicherkompromissQLoRA wurde von Tim Dettmers et al. vorgeschlagen. Abkürzung für quantitative LoRA. QLoRA ist eine Technik zur weiteren Reduzierung des Speicherbedarfs bei der Feinabstimmung. Während der Backpropagation quantisiert QLoRA die vorab trainierten Gewichte in 4-Bit und verwendet einen Paging-Optimierer, um Speicherspitzen zu bewältigen. Ich habe festgestellt, dass ich mit LoRA 33 % des GPU-Speichers einsparen kann. Aufgrund der zusätzlichen Quantisierung und Dequantisierung vorab trainierter Modellgewichte in QLoRA erhöht sich die Trainingszeit jedoch um 39 %. Standardmäßig hat LoRA eine 16-Bit-Gleitkommagenauigkeit:
- Trainingszeit: 1,85 Stunden
- Speicherverbrauch: 21,33 GB
QLoRA mit 4-stelligem normalen Gleitkomma Zahlen
- Die Trainingszeit beträgt: 2,79 Stunden
- Die Speichernutzung beträgt: 14,18 GB
Außerdem habe ich festgestellt, dass die Leistung des Modells nahezu unbeeinflusst bleibt, was sich zeigt dass QLoRA als LoRA-Alternativlösung trainiert werden kann, die einen Schritt weiter geht, um häufige GPU-Speicherengpässe zu beheben. 
Der Lernratenplaner reduziert die Lernrate während des gesamten Trainingsprozesses, um die Konvergenz des Modells zu optimieren und übermäßige Verlustwerte zu vermeiden. Cosine Annealing ist ein Scheduler, der einer Kosinuskurve folgt, um die Lernrate anzupassen. Sie beginnt mit einer höheren Lernrate, nimmt dann sanft ab und nähert sich in einem kosinusähnlichen Muster allmählich 0 an. Eine gängige Variante des Cosinus-Annealings ist die Halbperiodenvariante, bei der während des Trainings nur ein halber Cosinuszyklus abgeschlossen wird, wie in der Abbildung unten dargestellt. 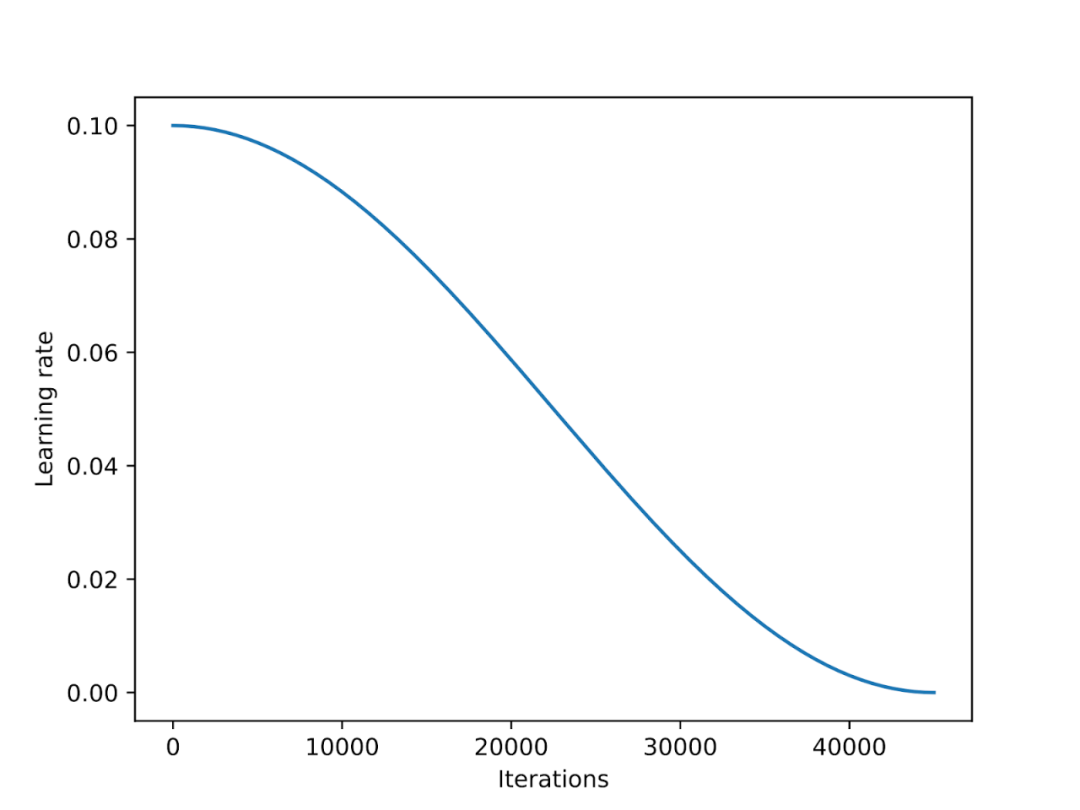
In Experimenten habe ich dem LoRA-Feinabstimmungsskript einen Cosinus-Annealing-Scheduler hinzugefügt, der die Leistung von SGD erheblich verbesserte. Der Nutzen für die Adam- und AdamW-Optimierer ist jedoch gering und es gibt fast keine Änderung nach dem Hinzufügen. 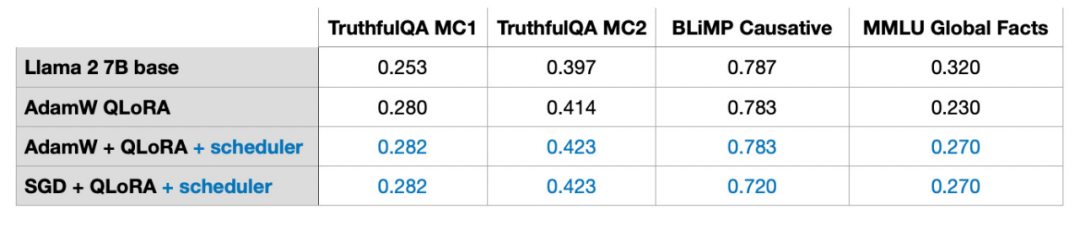
Im nächsten Abschnitt werden die potenziellen Vorteile von SGD gegenüber Adam besprochen. Adam- und AdamW-Optimierer sind beim Deep Learning beliebt. Wenn wir ein 7B-Parametermodell trainieren, kann Adam während des Trainingsprozesses weitere 14B-Parameter verfolgen, was einer Verdoppelung der Anzahl der Parameter des Modells entspricht, wenn andere Bedingungen unverändert bleiben. SGD kann während des Trainings keine zusätzlichen Parameter verfolgen. Was ist also der Vorteil von SGD in Bezug auf das Spitzengedächtnis im Vergleich zu Adam? In meinen Experimenten erforderte das Training eines 7B-Parameter-Llama-2-Modells mit AdamW und LoRA (Standardeinstellung r=8) 14,18 GB GPU-Speicher. Für das Training desselben Modells mit SGD sind 14,15 GB GPU-Speicher erforderlich. Im Vergleich zu AdamW spart SGD nur 0,03 GB Speicher, was einen vernachlässigbaren Effekt hat. Warum nur so viel Speicher sparen? Dies liegt daran, dass LoRA die Anzahl der Parameter im Modell bei der Verwendung von LoRA stark reduziert hat. Wenn beispielsweise r=8, gibt es von allen 6.738.415.616 Parametern des Llama 2-Modells bei 7B nur 4.194.304 trainierbare LoRA-Parameter. Wenn man sich nur die Zahlen ansieht, sind 4.194.304 Parameter zwar immer noch viel, aber tatsächlich belegen diese vielen Parameter nur 4.194.304 × 2 × 16 Bit = 134,22 Megabit = 16,78 Megabyte. (Wir haben aufgrund des zusätzlichen Overheads beim Speichern und Kopieren des Optimiererstatus einen Unterschied von 0,03 GB = 30 MB festgestellt.) 2 stellt die Anzahl der von Adam gespeicherten zusätzlichen Parameter dar, während sich 16 Bit auf die Standardgenauigkeit der Modellgewichte bezieht. 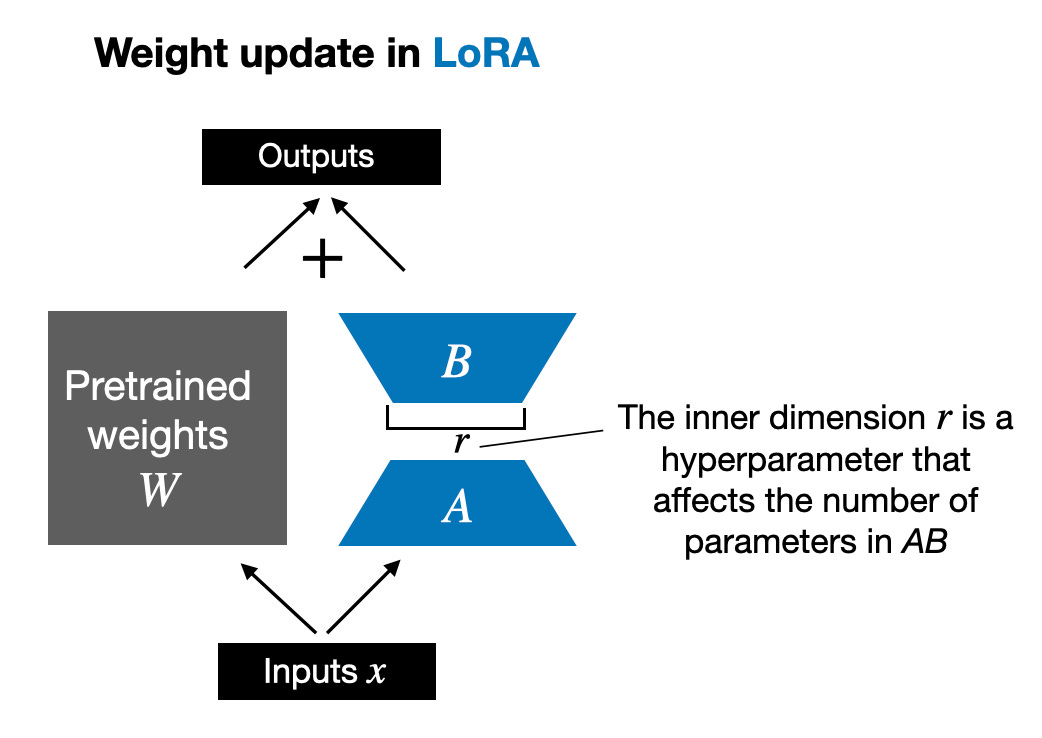
Wenn wir das r der LoRA-Matrix von 8 auf 256 erweitern, werden die Vorteile von SGD gegenüber AdamW sichtbar:
- Die Verwendung von AdamW belegt 17,86 GB Speicher.
- Die Verwendung von SGD Wird 14,46 GB belegen
Daher spielt der durch SGD eingesparte Speicher bei zunehmender Matrixgröße eine wichtige Rolle. Da SGD keine zusätzlichen Optimierungsparameter speichern muss, kann SGD bei der Verarbeitung großer Modelle mehr Speicher einsparen als andere Optimierer wie Adam. Dies ist ein sehr wichtiger Vorteil für Trainingsaufgaben mit begrenztem Speicher. Beim traditionellen Deep Learning iterieren wir den Trainingssatz oft mehrmals, und jede Iteration wird als Epoche bezeichnet. Wenn Sie beispielsweise ein Faltungs-Neuronales Netzwerk trainieren, führen Sie es normalerweise über Hunderte von Epochen aus. Haben mehrere Runden iterativen Trainings also auch einen Einfluss auf die Feinabstimmung des Unterrichts? Die Antwort lautet: Nein. Als ich die Anzahl der Iterationen für den Feinabstimmungsdatensatz der Alpaca-Beispielanweisung mit 50.000 Daten verdoppelte, sank die Leistung des Modells. 
Daher kam ich zu dem Schluss, dass mehrere Iterationsrunden der Feinabstimmung des Unterrichts möglicherweise nicht förderlich sind. Ich habe das gleiche Verhalten im 1k-Beispiel-LIMA-Anweisungs-Feinabstimmungssatz beobachtet. Der Rückgang der Modellleistung kann durch Überanpassung verursacht werden, und die spezifischen Gründe müssen noch weiter untersucht werden. LoRA in mehreren Ebenen verwendenDie folgende Tabelle zeigt Experimente, bei denen LoRA nur mit ausgewählten Matrizen funktioniert (d. h. Schlüssel- und Wertmatrizen in jedem Transformer). Darüber hinaus können wir LoRA in der Abfragegewichtsmatrix, der Projektionsschicht, anderen linearen Schichten zwischen den Multi-Head-Aufmerksamkeitsmodulen und der Ausgabeschicht aktivieren. 
Wenn wir LoRA auf diesen zusätzlichen Ebenen hinzufügen, verfünffacht sich die Anzahl der trainierbaren Parameter von 4.194.304 auf 20.277.248 für das Llama 2-Modell bei 7B. Die Anwendung von LoRA auf mehr Ebenen kann die Modellleistung deutlich verbessern, erfordert aber auch mehr Speicherplatz. Außerdem habe ich nur diese beiden Einstellungen untersucht: (1) LoRA mit nur aktivierten Abfrage- und Gewichtsmatrizen, (2) LoRA mit aktivierten allen Ebenen, die Verwendung von LoRA in Kombination mit mehreren Ebenen ergibt, welche Art von Effekt würdig ist weiteres Studium. Wenn wir wissen, ob sich die Verwendung von LoRA in der Projektionsschicht positiv auf die Trainingsergebnisse auswirkt, können wir das Modell besser optimieren und seine Leistung verbessern. 
Ausgewogene LoRA-Hyperparameter: R und Alpha Wie in dem Papier erwähnt, in dem LoRA vorgeschlagen wurde, führt LoRA einen zusätzlichen Skalierungsfaktor ein. Dieser Koeffizient wird verwendet, um LoRA-Gewichte auf das Vortraining während der Vorwärtsausbreitung anzuwenden. Die Erweiterung umfasst den zuvor besprochenen Rangparameter r sowie einen weiteren Hyperparameter α (Alpha), der wie folgt angewendet wird: 
Wie die Formel im Bild oben zeigt, gilt: Je größer der Wert des LoRA-Gewichts, desto größer größer die Wirkung. Im vorherigen Experiment waren die Parameter, die ich verwendet habe, r=8, Alpha=16, was zu einer 2-fachen Erweiterung führte. Bei der Gewichtsreduzierung für große Modelle mit LoRA ist es eine gängige Faustregel, Alpha auf das Doppelte von r festzulegen. Aber ich bin gespannt, ob diese Regel auch für größere Werte von r gilt. 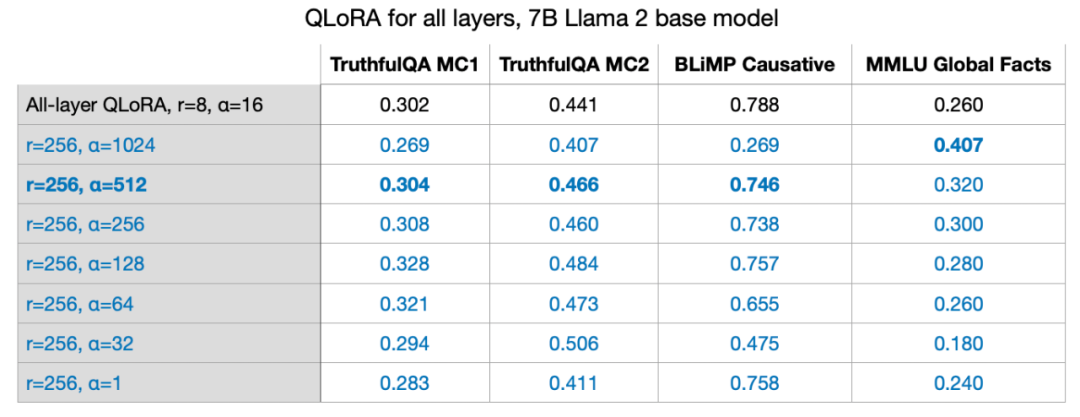
Ich habe es auch mit r=32, r=64, r=128 und r=512 versucht, habe diesen Vorgang aber der Übersichtlichkeit halber weggelassen, aber r=256 hat am besten funktioniert. Tatsächlich liefert die Wahl von Alpha=2r optimale Ergebnisse. 7B-Parametermodell auf einer einzelnen GPU trainieren LoRA ermöglicht uns die Feinabstimmung großer Sprachmodelle im 7B-Parametermaßstab auf einer einzelnen GPU. In diesem speziellen Fall dauerte die Verarbeitung von 17,86 GB (50.000 Trainingsbeispiele) Daten mit dem AdamW-Optimierer auf dem A100 mit den besten Einstellungen für QLoRA (r=256, Alpha=512) (hier Alpaca-Datensatz) etwa 3 Stunden. 
Im Rest dieses Artikels werde ich weitere Fragen beantworten, die Sie möglicherweise haben. F1: Wie wichtig ist der Datensatz? Datensätze sind entscheidend. Ich verwende den Alpaca-Datensatz mit 50.000 Trainingsbeispielen. Ich habe mich für Alpaka entschieden, weil es so beliebt ist. Da dieser Artikel bereits sehr lang ist, werden die Testergebnisse zu weiteren Datensätzen in diesem Artikel nicht besprochen. Alpaka ist ein synthetischer Datensatz, der nach heutigen Maßstäben etwas veraltet sein kann. Die Datenqualität ist entscheidend. Im Juni schrieb ich beispielsweise einen Beitrag über den LIMA-Datensatz, einen kuratierten Datensatz, der nur aus tausend Beispielen besteht. Artikellink: https://magazine.sebastianraschka.com/p/ahead-of-ai-9-llm-tuning-and-datasetWie der Titel des Artikels, der LIMA vorschlägt, schon sagt: Für die Ausrichtung gilt: Weniger ist mehr. Obwohl die Datenmenge in LIMA geringer ist als die von Alpaca, ist das auf LIMA basierende 65B-Llama-Modell besser als die Ergebnisse von Alpaca. Mit der gleichen Konfiguration (r=256, Alpha=512) habe ich auf LIMA eine ähnliche Modellleistung erzielt wie auf Alpaca, wo die Daten 50-mal so groß sind. F2: Ist LoRA für die Domain-Anpassung geeignet? Auf diese Frage habe ich noch keine klare Antwort. Als Faustregel gilt, dass Wissen normalerweise aus Datensätzen vor dem Training extrahiert wird. Normalerweise absorbieren Sprachmodelle Wissen aus Datensätzen vor dem Training, und die Feinabstimmung der Anweisungen besteht hauptsächlich darin, LLM dabei zu helfen, Anweisungen besser zu befolgen. Da die Rechenleistung ein Schlüsselfaktor ist, der das Training großer Sprachmodelle einschränkt, kann LoRA auch verwendet werden, um bestehende vorab trainierte LLM anhand spezieller Datensätze in bestimmten Bereichen weiter vorab zu trainieren. Außerdem ist es erwähnenswert, dass meine Experimente zwei arithmetische Benchmarks beinhalteten. In beiden Benchmarks schnitt das mit LoRA feinabgestimmte Modell deutlich schlechter ab als das vorab trainierte Basismodell. Ich vermute, dass dies daran liegt, dass dem Alpaca-Datensatz keine entsprechenden Rechenbeispiele fehlen, was dazu führt, dass das Modell die Rechenkenntnisse „vergisst“. Es bedarf weiterer Untersuchungen, um festzustellen, ob das Modell das Rechenwissen „vergessen“ hat oder ob es nicht mehr auf die entsprechenden Anweisungen reagiert hat. Hier kann jedoch eine Schlussfolgerung gezogen werden: „Bei der Feinabstimmung eines LLM ist es eine gute Idee, dass der Datensatz Beispiele für jede Aufgabe enthält, die uns am Herzen liegt.“ Wert? Für dieses Problem habe ich noch keine bessere Lösung. Die Bestimmung des optimalen r-Werts erfordert eine spezifische Analyse spezifischer Probleme basierend auf den spezifischen Umständen jedes LLM und jedes Datensatzes. Ich vermute, dass ein zu großer Wert von r zu einer Überanpassung führt, während ein zu kleiner Wert von r möglicherweise nicht die verschiedenen Aufgaben im Datensatz erfasst. Ich vermute, je mehr Aufgabentypen es im Datensatz gibt, desto größer ist der erforderliche r-Wert. Wenn ich das Modell beispielsweise nur für die Ausführung grundlegender zweistelliger Rechenoperationen benötige, kann ein kleiner Wert von r ausreichend sein. Dies ist jedoch nur meine Hypothese und bedarf weiterer Forschung, um sie zu überprüfen. F4: Muss LoRA für alle Ebenen aktiviert werden? Ich habe nur zwei Einstellungen untersucht: (1) LoRA mit nur aktivierten Abfrage- und Gewichtsmatrizen und (2) LoRA mit aktivierten Ebenen. Die Auswirkungen der Verwendung von LoRA in Kombination mit mehreren Schichten sind einer weiteren Untersuchung wert. Wenn wir wissen, ob sich die Verwendung von LoRA in der Projektionsschicht positiv auf die Trainingsergebnisse auswirkt, können wir das Modell besser optimieren und seine Leistung verbessern. Wenn wir die verschiedenen Einstellungen berücksichtigen (lora_query, lora_key, lora_value, lora_projection, lora_mlp, lora_head), gibt es 64 Kombinationen zu erkunden.
F5: Wie vermeide ich eine Überanpassung? Im Allgemeinen führt ein größeres r eher zu einer Überanpassung, da r die Anzahl der trainierbaren Parameter bestimmt. Wenn Ihr Modell überangepasst ist, sollten Sie zunächst erwägen, den r-Wert zu verringern oder die Datensatzgröße zu erhöhen. Darüber hinaus können Sie versuchen, die Gewichtsabnahmerate des AdamW- oder SGD-Optimierers zu erhöhen oder den Dropout-Wert der LoRA-Ebene zu erhöhen. Ich habe den Dropout-Parameter von LoRA im Experiment nicht untersucht (ich habe eine feste Dropout-Rate von 0,05 verwendet). Der Dropout-Parameter von LoRA ist ebenfalls eine Frage, die eine Untersuchung wert ist.
F6: Gibt es noch andere Optimierer zur Auswahl? Sophia wurde im Mai dieses Jahres veröffentlicht und ist einen skalierbaren stochastischen Optimierer zweiter Ordnung für das Vortraining von Sprachmodellen wert.Laut dem folgenden Artikel: „Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training“ ist Sophia im Vergleich zu Adam doppelt so schnell und kann eine bessere Leistung erzielen. Kurz gesagt, Sophia implementiert wie Adam die Normalisierung über die Gradientenkrümmung und nicht über die Gradientenvarianz. Link zum Papier: https://arxiv.org/abs/2305.14342F7: Gibt es andere Faktoren, die die Speichernutzung beeinflussen? Neben Präzisions- und Quantisierungseinstellungen, Modellgröße, Batchgröße und Anzahl der trainierbaren LoRA-Parameter beeinflusst der Datensatz auch die Speichernutzung. Die Blockgröße von Llama 2 beträgt 4048 Token, was bedeutet, dass Llama eine Sequenz mit 4048 Token gleichzeitig verarbeiten kann. Wenn Masken zu nachfolgenden Token hinzugefügt werden, wird die Trainingssequenz kürzer, was viel Speicher sparen kann. Beispielsweise ist der Alpaca-Datensatz relativ klein, wobei die längste Sequenzlänge 1304 Token beträgt. Wenn ich versuche, andere Datensätze mit der längsten Sequenzlänge von 2048 Token zu verwenden, springt die Speichernutzung von 17,86 GB auf 26,96 GB. F8: Was sind die Vorteile von LoRA im Vergleich zur vollständigen Feinabstimmung und RLHF? Ich habe nicht mit RLHF experimentiert, aber ich habe es mit Vollschnitt versucht. Die vollständige Feinabstimmung erforderte mindestens 2 GPUs, beanspruchte jeweils 36,66 GB und dauerte 3,5 Stunden. Die schlechten Basistestergebnisse können jedoch durch eine Überanpassung oder suboptimale Parameter verursacht werden. F9: Können die Gewichtungen von LoRA kombiniert werden? Die Antwort ist ja. Während des Trainings trennen wir die LoRA-Gewichte und die vortrainierten Gewichte und verbinden sie bei jedem Vorwärtsdurchlauf. Angenommen, dass es in der realen Welt eine Anwendung mit mehreren Sätzen von LoRA-Gewichtungen gibt und jeder Satz von Gewichtungen einem Benutzer der Anwendung entspricht, dann ist es sinnvoll, diese Gewichte separat zu speichern, um Speicherplatz zu sparen. Außerdem können vorab trainierte Gewichte und LoRA-Gewichte nach dem Training zusammengeführt werden, um ein einziges Modell zu erstellen. Auf diese Weise müssen wir nicht bei jedem Vorwärtsdurchlauf LoRA-Gewichte anwenden. weight += (lora_B @ lora_A) * scaling
Wir können die Gewichte mit der oben gezeigten Methode aktualisieren und die kombinierten Gewichte speichern. 🔜 schon möglich. Skript-Link: https://github.com/Lightning-AI/lit-gpt/blob/main/scripts/merge_lora.pyF10: Wie ist die Leistung von Layer-by- Schicht optimale Ranganpassung?
Der Einfachheit halber werden wir in tiefen neuronalen Netzen normalerweise für jede Schicht die gleiche Lernrate festlegen. Die Lernrate ist ein Hyperparameter, den wir optimieren müssen, und außerdem können wir für jede Ebene eine andere Lernrate wählen (in PyTorch ist das keine sehr komplizierte Sache). In der Praxis wird dies jedoch selten durchgeführt, da dieser Ansatz zusätzliche Kosten verursacht und es viele andere Parameter gibt, die in tiefen neuronalen Netzen einstellbar sind. Ähnlich wie bei der Auswahl unterschiedlicher Lernraten für verschiedene Schichten können wir auch unterschiedliche LoRA-r-Werte für verschiedene Schichten auswählen. Ich habe es noch nicht ausprobiert, aber es gibt ein Dokument, das diese Methode detailliert beschreibt: „LLM Optimization: Layer-wise Optimal Rank Adaptation (LORA)“. Theoretisch klingt dieser Ansatz vielversprechend und bietet viel Spielraum für die Optimierung von Hyperparametern.
Papierlink: https://medium.com/@tom_21755/llm-optimization-layer-wise-optimal-rank-adaptation-lora-1444dfbc8e6aOriginallink: https:// magazine.sebastianraschka.com/p/practical-tips-for-finetuning-llms?continueFlag=0c2e38ff6893fba31f1492d815bf928bDas obige ist der detaillierte Inhalt vonEs ist nicht so, dass sich große Modelle eine globale Feinabstimmung nicht leisten können, es ist nur so, dass LoRA kostengünstiger ist und das Tutorial fertig ist.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

