
Heim >Technologie-Peripheriegeräte >KI >SDXL Turbo und LCM läuten die Ära der Echtzeitgenerierung von KI-Zeichnungen ein: So schnell wie das Tippen, werden Bilder sofort präsentiert
SDXL Turbo und LCM läuten die Ära der Echtzeitgenerierung von KI-Zeichnungen ein: So schnell wie das Tippen, werden Bilder sofort präsentiert

- PHPznach vorne
- 2023-11-30 14:14:501700Durchsuche
Stability AI hat am Dienstag eine neue Generation von Bildsynthesemodellen auf den Markt gebracht – Stable Diffusion XL Turbo, die bei den Menschen begeisterte Resonanz hervorgerufen hat. Viele Leute sagten, dass die Verwendung dieses Modells für die Bild-zu-Text-Generierung noch nie so einfach war.
Geben Sie Ihre Ideen in das Eingabefeld ein. SDXL Turbo reagiert schnell und generiert den entsprechenden Inhalt ohne weitere Vorgänge. Unabhängig davon, ob Sie mehr oder weniger Inhalte eingeben, hat dies keinen Einfluss auf die Geschwindigkeit.


Sie können vorhandene Bilder verwenden, um Ihre Kreation detaillierter zu vervollständigen. Nehmen Sie einfach ein weißes Blatt Papier und sagen Sie SDXL Turbo, dass Sie eine weiße Katze möchten. Bevor Sie mit dem Tippen fertig sind, ist die kleine weiße Katze bereits in Ihren Händen erschienen. Die Geschwindigkeit des SDXL Turbo-Modells erreicht fast „in Echtzeit“, und die Leute kommen nicht umhin, sich zu fragen: Kann das Bilderzeugungsmodell für andere Zwecke verwendet werden? Jemand hat sich direkt mit dem Spiel verbunden und einen Übertragungsbildschirm im 2-fps-Stil erhalten: Dem offiziellen Blog zufolge kann SDXL Turbo auf dem A100 ein 512x512-Bild in 207 Millisekunden erzeugen (On-the-Fly-Kodierung + einzelner Entrauschungsschritt + Dekodierung, fp16), wovon eine einzelne UNet-Vorwärtsauswertung 67 Millisekunden dauert.
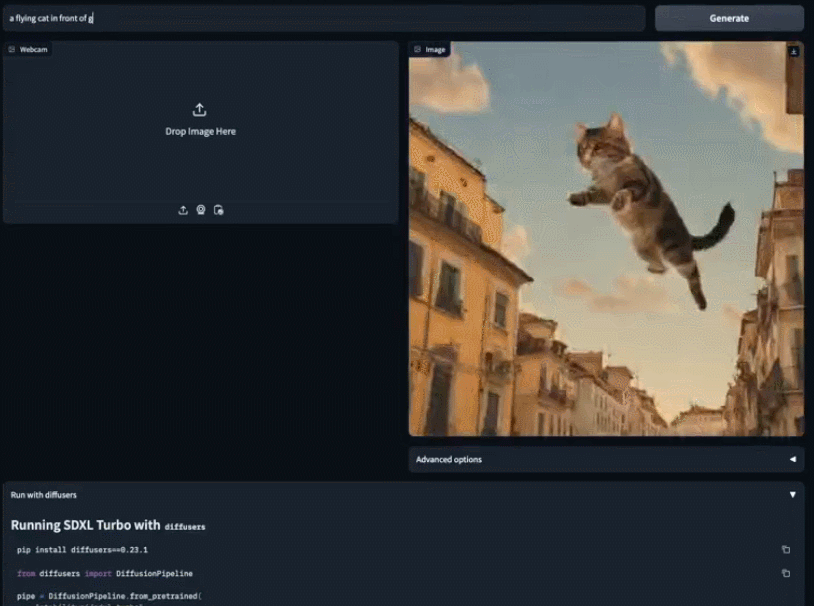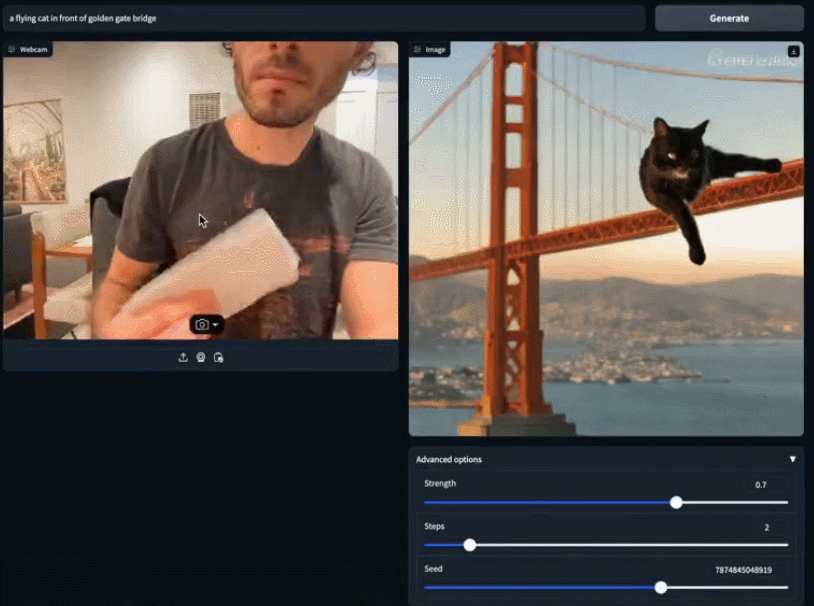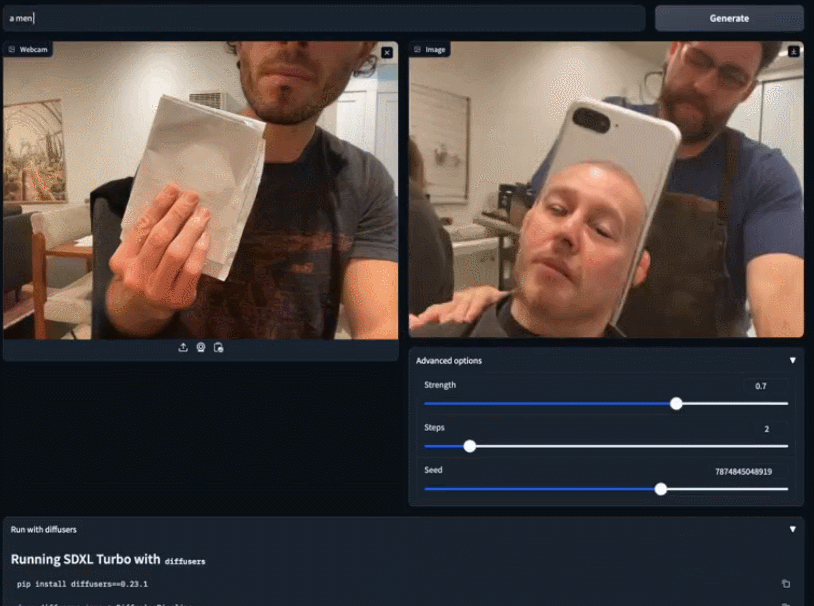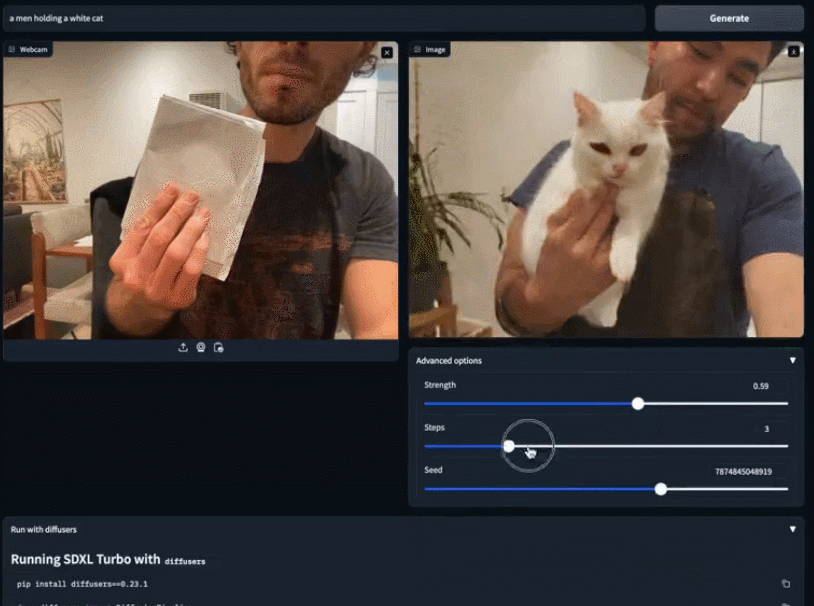 Auf diese Weise können wir beurteilen, dass Vincent Picture in die „Echtzeit“-Ära eingetreten ist.
Auf diese Weise können wir beurteilen, dass Vincent Picture in die „Echtzeit“-Ära eingetreten ist.
Eine solche „Instant Generation“-Effizienz ähnelt in gewisser Weise dem Tsinghua LCM-Modell, das vor nicht allzu langer Zeit populär wurde, aber der technische Inhalt dahinter ist anders. In einem gleichzeitig veröffentlichten Forschungsbericht erläuterte Stability das Innenleben des Modells detailliert. Die Forschung konzentriert sich auf eine Technologie namens Adversarial Diffusion Distillation (ADD). Einer der behaupteten Vorteile von SDXL Turbo ist seine Ähnlichkeit mit generativen kontradiktorischen Netzwerken (GANs), insbesondere bei der Generierung einstufiger Bildausgaben.
Papieradresse: https://static1.squarespace.com/static/6213c340453c3f502425776e/t/65663480a92fba51d0e1023f/1701197769659/adversarial_diffusion_distillation. pdf

Details zum Papier
Kurz gesagt, kontradiktorische Diffusionsdestillation ist Eine allgemeine Methode, die die Anzahl der Inferenzschritte eines vorab trainierten Diffusionsmodells auf 1–4 Stichprobenschritte reduzieren kann, während gleichzeitig eine hohe Stichprobentreue erhalten bleibt und die Gesamtleistung des Modells möglicherweise weiter verbessert wird.
Zu diesem Zweck führten die Forscher eine Kombination aus zwei Trainingszielen ein: (i) gegnerischer Verlust und (ii) Destillationsverlust entsprechend SDS. Der gegnerische Verlust zwingt das Modell dazu, bei jedem Vorwärtsdurchlauf direkt Proben zu generieren, die auf der realen Bildmannigfaltigkeit liegen, wodurch Unschärfen und andere Artefakte vermieden werden, die bei anderen Destillationsmethoden häufig auftreten. Der Destillationsverlust nutzt ein anderes vorab trainiertes (und festes) Diffusionsmodell als Lehrer, nutzt dessen umfangreiches Wissen effektiv und behält die starke Zusammensetzung bei, die in großen Diffusionsmodellen beobachtet wird. Während des Inferenzprozesses verwendeten die Forscher keine klassifikatorfreie Führung, was den Speicherbedarf weiter reduzierte. Sie behalten die Fähigkeit des Modells bei, Ergebnisse durch iterative Verfeinerung zu verbessern, ein Vorteil gegenüber früheren GAN-basierten Einzelschrittansätzen.
Die Trainingsschritte sind in Abbildung 2 dargestellt: 
Tabelle 1 zeigt die Ergebnisse des Ablationsexperiments:
Der nächste Schritt ist ein Vergleich mit anderen SOTA-Modellen. Hier verwendeten die Forscher keine automatisierten Indikatoren, sondern wählten eine zuverlässigere Methode zur Bewertung der Benutzerpräferenzen.
Um mehrere verschiedene Modellvarianten (StyleGAN-T++, OpenMUSE, IF-XL, SDXL und LCM-XL) zu vergleichen, verwendet das Experiment dieselbe Eingabeaufforderung, um die Ausgabe zu generieren. In Blindtests schlug der SDXL Turbo die 4-Stufen-Konfiguration des LCM-XL in einem einzigen Schritt und die 50-Stufen-Konfiguration des SDXL in nur 4 Schritten. Aus diesen Ergebnissen ist ersichtlich, dass SDXL Turbo modernste mehrstufige Modelle übertrifft und gleichzeitig den Rechenaufwand ohne Einbußen bei der Bildqualität deutlich reduziert Diagramm der Ergebnisse
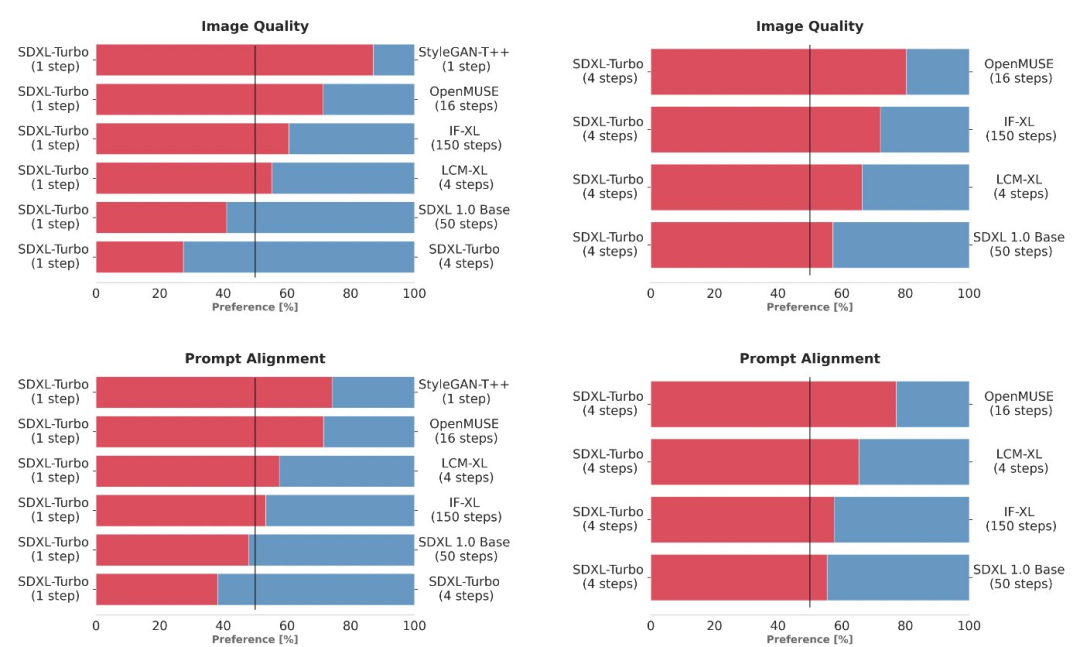
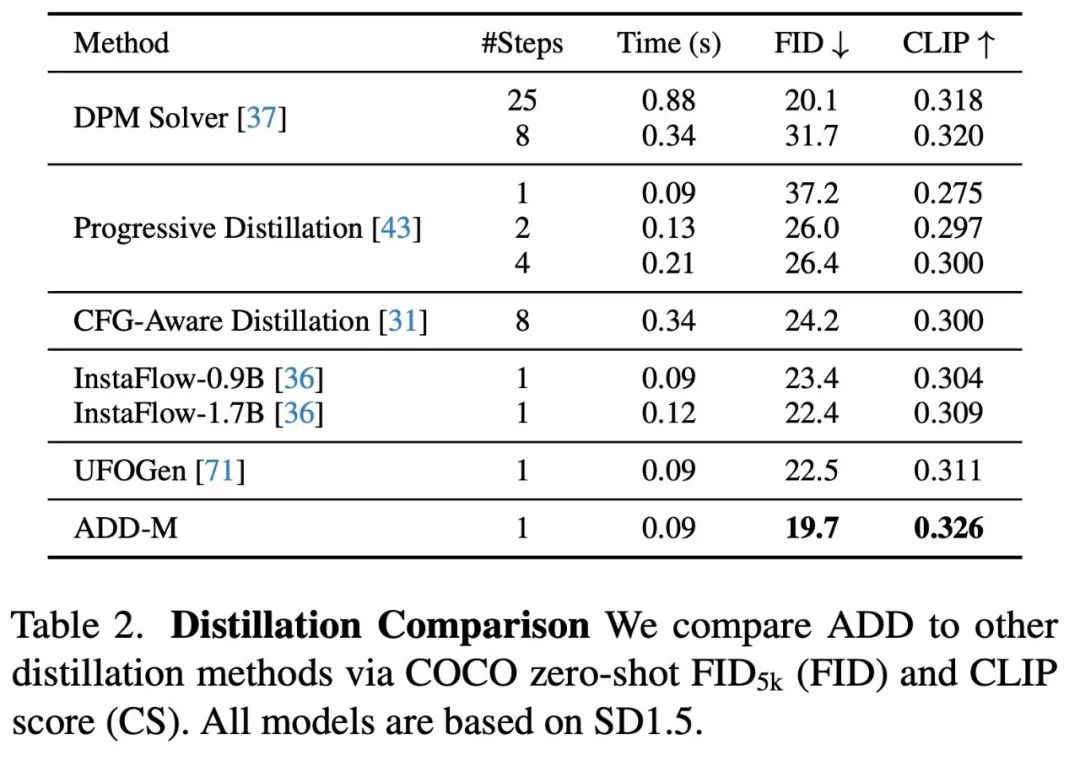
In Tabelle 2 wird ein Vergleich verschiedener Methoden zur Probenahme und Destillation in wenigen Schritten unter Verwendung desselben Basismodells durchgeführt. Die Ergebnisse zeigen, dass die ADD-Methode alle anderen Methoden übertrifft, einschließlich des 8-stufigen Standard-DPM-Lösers. Die Fähigkeit von XL, die Erstmuster zu verbessern. Abbildung 3 vergleicht ADD-XL (1 Schritt) mit der derzeit besten Basislinie in Schemata mit wenigen Schritten. Abbildung 4 beschreibt den iterativen Sampling-Prozess von ADD-XL. Abbildung 8 bietet einen direkten Vergleich von ADD-XL mit seinem Lehrermodell SDXL-Base. Wie Benutzerstudien zeigen, übertrifft ADD-XL das Lehrermodell sowohl in der Qualität als auch in der schnellen Ausrichtung.

Weitere Forschungsdetails finden Sie im Originalpapier
Das obige ist der detaillierte Inhalt vonSDXL Turbo und LCM läuten die Ära der Echtzeitgenerierung von KI-Zeichnungen ein: So schnell wie das Tippen, werden Bilder sofort präsentiert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Das CSS-Box-Modell verstehen: In 5 Minuten verstehen, was das CSS-Box-Modell ist?
- So löschen Sie eine Tabelle in der Datenbank in MySQL
- So löschen Sie überflüssige Modelle in ZBrush
- Beschreiben Sie kurz, was die Speichereinheit für Daten in einem Computer ist.
- Wie läuft die Konvertierung eines E-R-Diagramms in ein relationales Datenmodell ab?