
Heim >Technologie-Peripheriegeräte >KI >Überwachtes vs. unüberwachtes Lernen: Experten definieren die Lücke
Überwachtes vs. unüberwachtes Lernen: Experten definieren die Lücke

- 王林nach vorne
- 2023-11-23 18:09:221025Durchsuche
Was neu geschrieben werden muss, ist: Verstehen Sie die Merkmale des überwachten Lernens, des unüberwachten Lernens und des halbüberwachten Lernens und wie sie in maschinellen Lernprojekten angewendet werden.

Bei der Erörterung der Technologie der künstlichen Intelligenz wird häufig überwachtes Lernen verwendet ist die Methode, die die meiste Aufmerksamkeit erhält, da sie oft der letzte Schritt bei der Erstellung eines KI-Modells ist und für Dinge wie Bilderkennung, bessere Vorhersagen, Produktempfehlungen und Lead-Scoring verwendet werden kann
Im Gegensatz dazu tendiert kein überwachtes Lernen um zu Beginn des KI-Entwicklungslebenszyklus hinter den Kulissen zu arbeiten: Es wird oft verwendet, um den Grundstein für die Entfaltung der Magie des überwachten Lernens zu legen, genau wie die Routinearbeit, die es Managern ermöglicht, zu glänzen. Wie später erläutert wird, können beide Modelle des maschinellen Lernens effektiv auf Geschäftsprobleme angewendet werden.
Auf technischer Ebene besteht der Unterschied zwischen überwachtem und unüberwachtem Lernen darin, ob die zur Erstellung des Algorithmus verwendeten Rohdaten vorab gekennzeichnet sind (überwachtes Lernen) oder nicht (unüberwachtes Lernen).
Lass uns anfangen
Was ist überwachtes Lernen?
Beim überwachten Lernen stellen Datenwissenschaftler dem Algorithmus gekennzeichnete Trainingsdaten zur Verfügung und definieren die Variablen, die der Algorithmus auf Relevanz auswerten soll.
Die Eingabedaten und Ausgabevariablen des Algorithmus werden durch die Trainingsdaten spezifiziert. Wenn Sie beispielsweise überwachtes Lernen verwenden möchten, um einen Algorithmus zu trainieren, um zu bestimmen, ob ein Bild eine Katze enthält, können Sie für jedes in den Trainingsdaten verwendete Bild eine Beschriftung erstellen, um anzugeben, ob das Bild eine Katze enthält
Wie wir Erklären Sie in unserer Definition des überwachten Lernens: „[Ein] Computeralgorithmus wird auf Eingabedaten trainiert, die für eine bestimmte Ausgabe gekennzeichnet sind. Das Modell wird trainiert, bis es in der Lage ist, die grundlegenden Muster und Beziehungen zwischen ihnen zu erkennen.“ Sie liefern genaue Kennzeichnungsergebnisse, wenn sie mit noch nie dagewesenen Daten präsentiert werden, darunter Klassifizierung, Entscheidungsbäume, Regression und Vorhersagemodellierung. Erfahren Sie mehr über sie im Tutorial
Überwachte maschinelle Lerntechniken werden in einer Vielzahl von Geschäftsanwendungen eingesetzt, darunter:
- Personalisiertes Marketing
- Versicherungs-/Kreditversicherungsentscheidungen Aud-Erkennung.
- Spam-Filterung
- Was ist unüberwachtes Lernen? Für diese Methode gibt es einen Algorithmus, der auf unbeschrifteten Daten trainiert Durchsucht den Datensatz nach sinnvollen Zusammenhängen. Mit anderen Worten: Unüberwachtes Lernen identifiziert Muster in den Daten, anstatt sie mit einem externen Maß in Beziehung zu setzen.
Dieser Ansatz ist nützlich, wenn Sie nicht wissen, was Sie sind Auf der Suche nach, aber nicht so nützlich, wenn Sie dies tun. Sie zeigen einem unbeaufsichtigten Algorithmus Tausende oder Millionen von Bildern an, und er klassifiziert möglicherweise eine Teilmenge der Bilder als solche, die Menschen als Katzen erkennen, verglichen mit den gekennzeichneten Daten zu Katzen und Hunden Algorithmen, auf denen trainiert wird, sind in der Lage, Bilder von Katzen mit einem hohen Maß an Sicherheit zu identifizieren, aber dieser Ansatz bringt einen Kompromiss mit sich: Wenn ein überwachtes Lernprojekt Millionen von beschrifteten Bildern erfordert, um ein Modell zu entwickeln, sind für maschinell generierte Vorhersagen viele davon erforderlich menschliche Anstrengung
Es gibt einen Mittelweg: halbüberwachtes Lernen
Was ist halbüberwachtes Lernen?
Halbüberwachtes Lernen ist eine effektive Methode, die unüberwachtes Lernen und überwachtes Lernen durch eine bestimmte Methode kombiniert Arbeitsablauf Der unüberwachte Lernalgorithmus generiert automatisch Beschriftungen, die dann in den überwachten Lernalgorithmus eingespeist werden. Bei dieser Methode beschriften Menschen manuell einige Bilder, während der unüberwachte Lernalgorithmus die Beschriftungen für andere Bilder errät und schließlich alle Beschriftungen und Bilder einspeist hinein. in überwachte Lernalgorithmen, um KI-Modelle zu erstellen
Ein Vorteil des halbüberwachten Lernens besteht darin, dass es die Kosten für die Verwendung großer Datensätze beim maschinellen Lernen senken kann, so Aaron, Mitbegründer und Chefinnovator Laut Kalb können Computer, wenn sie 0,01 % von Millionen Proben kennzeichnen können, ihre Vorhersagegenauigkeit deutlich verbessern
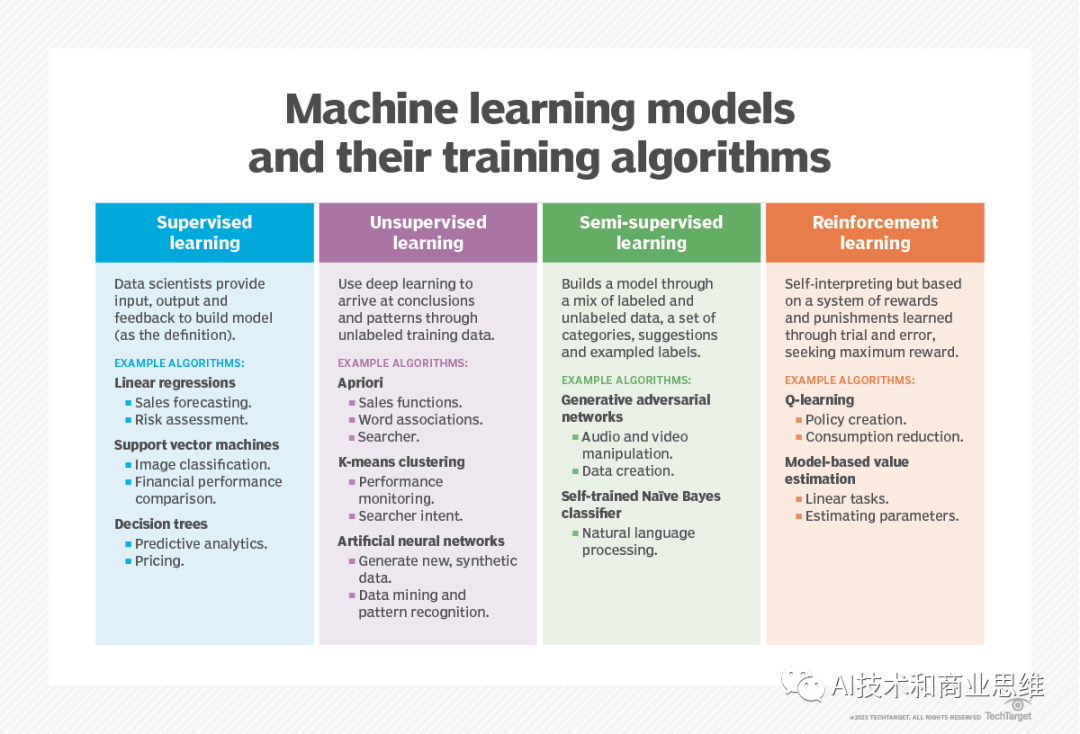
Was ist Reinforcement Learning?
Eine weitere Methode des maschinellen Lernens ist das Reinforcement Learning. Reinforcement Learning wird typischerweise verwendet, um einer Maschine beizubringen, eine Abfolge von Schritten abzuschließen, und unterscheidet sich vom überwachten und unbeaufsichtigten Lernen. Datenwissenschaftler programmieren Algorithmen zur Ausführung von Aufgaben und geben positive oder negative Hinweise oder Verstärkungen, wenn sie bestimmen, wie Aufgaben erledigt werden sollen. Der Programmierer legt die Regeln für die Belohnung fest, lässt aber den Algorithmus entscheiden, welche Schritte er unternehmen muss, um die Belohnung für die Erledigung der Aufgabe zu maximieren.
Wann sollten Sie überwachtes Lernen im Vergleich zu unüberwachtem Lernen verwenden?
Shivani Rao, Machine Learning Manager bei LinkedIn, sagte, dass Best Practices für einen überwachten oder unbeaufsichtigten Ansatz des maschinellen Lernens oft von der Umgebung, den Annahmen, die man über die Daten und die Anwendung treffen kann, abhängen.
Rao sagte, dass sich auch die Wahl zwischen überwachten und unbeaufsichtigten Algorithmen für maschinelles Lernen im Laufe der Zeit ändern werde. In den frühen Phasen des Modellbildungsprozesses sind die Daten oft unbeschriftet, während in späteren Phasen der Modellierung beschriftete Daten entstehen können.
Für das Problem der Vorhersage, ob LinkedIn-Mitglieder Kursvideos ansehen werden, verwendet das erste Modell beispielsweise unbeaufsichtigte Techniken. Nachdem diese Vorschläge bereitgestellt wurden, liefert eine Metrik, die aufzeichnet, ob jemand auf den Vorschlag klickt, neue Daten zur Generierung von Labels
LinkedIn verwendet diese Technik auch, um Online-Kurse mit Fähigkeiten zu versehen, die Studenten möglicherweise erwerben möchten. Menschliche Tagger wie Autoren, Verleger oder Studenten können eine präzise und genaue Liste der in einem Kurs vermittelten Fähigkeiten bereitstellen, es ist jedoch unwahrscheinlich, dass sie eine vollständige Liste dieser Fähigkeiten bereitstellen. Daher können diese Datenetiketten als unvollständig angesehen werden. Für diese Art von Problemen können halbüberwachte Techniken verwendet werden, um einen umfassenderen Satz von Etiketten zu erstellen.
Bharath Thota, ein Experte für Datenwissenschaft und Advanced Analytics und Partner des Beratungsunternehmens Kearney, sagte, dass sein Team bei der Entscheidung für überwachtes oder unbeaufsichtigtes Lernen auch praktische Faktoren berücksichtigt.
Thota sagte: „Wenn beschriftete Daten verfügbar sind, wählen wir überwachtes Lernen als Anwendung mit dem Ziel, zukünftige Beobachtungen vorherzusagen oder zu klassifizieren. Wenn keine beschrifteten Daten verfügbar sind, verwenden wir unüberwachtes Lernen mit dem Ziel der Entwicklung.“ Strategien durch die Identifizierung von Mustern oder Ausschnitten aus Daten.“
Kalb sagte, Alation-Datenwissenschaftler nutzen intern unüberwachtes Lernen für eine Vielzahl von Anwendungen. Sie entwickelten beispielsweise einen kollaborativen Mensch-Maschine-Prozess zur Übersetzung obskurer Datenobjektnamen in menschliche Sprache – zum Beispiel „na_gr_rvnu_ps“ in „North American total professional Services yield“. In diesem Fall maschinelle Vermutungen, Menschen bestätigen, maschinelles Lernen
„Man kann es sich als halbüberwachtes Lernen in einer iterativen Schleife vorstellen, wodurch ein positiver Kreislauf verbesserter Genauigkeit entsteht“, sagte Kalb. 5 unüberwachte Lerntechniken ?
Unüberwachte Lerntechniken ergänzen die Arbeit des überwachten Lernens häufig, indem sie Rohdatensätze auf verschiedene Weise aufteilen, einschließlich:
Datenclusterung von Datenpunkten mit ähnlichen Merkmalen, um das Verständnis zu erleichtern Um Daten effektiver zu untersuchen, könnte ein Unternehmen beispielsweise Daten-Clustering-Methoden verwenden, um Kunden anhand ihrer Demografie, Interessen, Kaufverhalten und anderen Faktoren in Gruppen einzuteilen.
Jede Variable in einem Datensatz wird als separate Dimension behandelt. Viele Modelle funktionieren jedoch besser, wenn sie bestimmte Beziehungen zwischen Variablen analysieren. Ein einfaches Beispiel für die Dimensionsreduktion ist die Verwendung von Gewinn als einer einzigen Dimension, die Einnahmen abzüglich Ausgaben darstellt. Allerdings können mithilfe davon neue, komplexere Variablentypen generiert werden Algorithmen wie Hauptkomponentenanalyse, Autoencoder, Algorithmen, die Text in Vektoren umwandeln, oder T-verteilte stochastische NachbarschaftseinbettungDimensionalitätsreduktion kann dazu beitragen, das Problem der Überanpassung zu reduzieren, bei der ein Modell für kleine Datensätze gut funktioniert, aber nicht verallgemeinert Die Technik ermöglicht es Unternehmen auch, hochdimensionale Daten zu visualisieren, die für Menschen leicht verständlich sind. Unüberwachtes Lernen kann dabei helfen, Anomalien als Datenvorbereitungsschritt zu erkennen das kann die Modelle des maschinellen Lernens verbessern
Lernen übertragen. Diese Algorithmen nutzen Modelle, die für verwandte, aber unterschiedliche Aufgaben trainiert wurden. Transfer-Learning-Techniken erleichtern beispielsweise die Feinabstimmung eines auf Wikipedia-Artikeln trainierten Klassifikators, um jede Art von neuem Text mit den richtigen Themen zu kennzeichnen. Laut Rao von LinkedIn ist dies eine der effektivsten und schnellsten Möglichkeiten, das Problem der unbeschrifteten Daten zu lösen.
Graphbasierter Algorithmus. Rao sagte, dass diese Techniken versuchen, ein Diagramm zu erstellen, das die Beziehung zwischen Datenpunkten erfasst. Wenn beispielsweise jeder Datenpunkt ein LinkedIn-Mitglied mit einer Fertigkeit darstellt, können Sie die Mitglieder mithilfe eines Diagramms darstellen, in dem Kanten die Fertigkeitsüberlappung zwischen Mitgliedern darstellen. Diagrammalgorithmen können auch dabei helfen, Beschriftungen von bekannten Datenpunkten auf unbekannte, aber eng verwandte Datenpunkte zu übertragen. Unüberwachtes Lernen kann auch zum Erstellen von Diagrammen zwischen verschiedenen Arten von Entitäten (Quellen und Zielen) verwendet werden. Je stärker die Kante, desto höher ist die Affinität des Quellknotens zum Zielknoten. LinkedIn verwendet sie beispielsweise, um Mitgliedern kompetenzbasierte Kurse zuzuordnen.
Das obige ist der detaillierte Inhalt vonÜberwachtes vs. unüberwachtes Lernen: Experten definieren die Lücke. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!