
Heim >Technologie-Peripheriegeräte >KI >Code-Datenerweiterung im Deep Learning: Ein Rückblick auf 89 Forschungen in 5 Jahren
Code-Datenerweiterung im Deep Learning: Ein Rückblick auf 89 Forschungen in 5 Jahren

- 王林nach vorne
- 2023-11-23 14:33:441210Durchsuche
Mit der rasanten Entwicklung von Deep Learning und Großmodellen nimmt das Streben nach innovativen Technologien weiter zu. In diesem Prozess hat die Datenerweiterungstechnologie einen Wert gezeigt, der nicht ignoriert werden kann
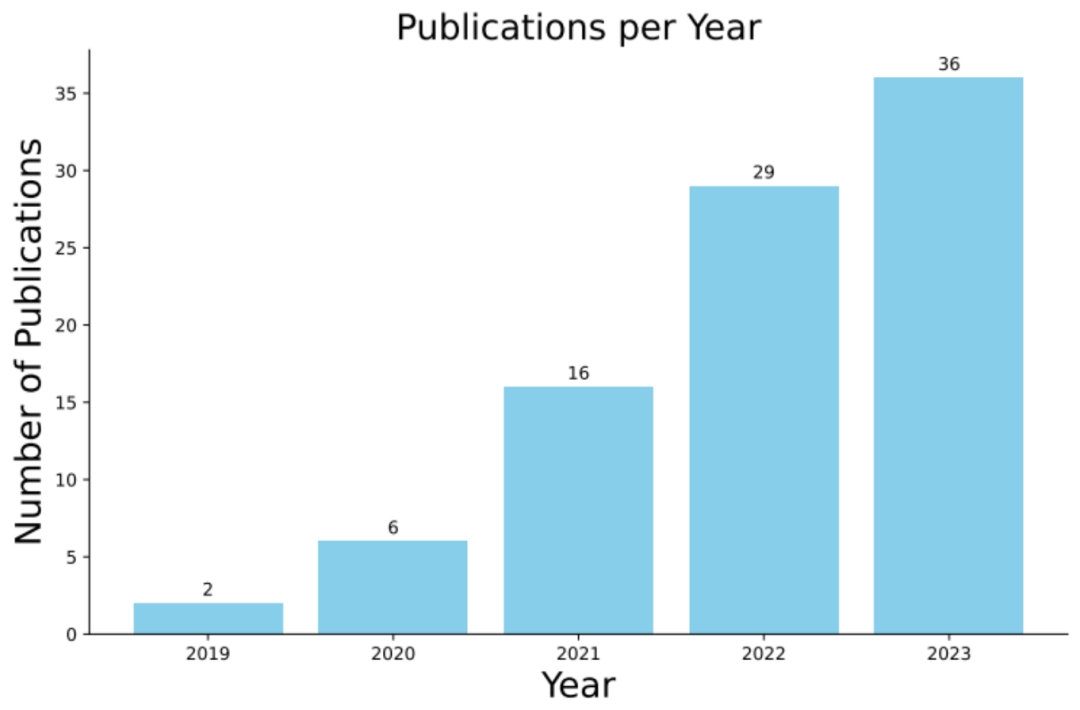
Kürzlich wurde eine gemeinsam von der Monash University, der Singapore Management University, dem Huawei Noah's Ark Laboratory, der Beihang University und der Australian National University durchgeführte Studie basierend auf 89 verwandten Forschungsumfragen durchgeführt In den letzten fünf Jahren wurde ein umfassender Überblick über die Anwendung der Codedatenverbesserung beim Deep Learning veröffentlicht.

- Papieradresse: https://arxiv.org/abs/2305.19915
- Projektadresse: https://github.com/terryyz/DataAug4Code
Dieser Überprüfungsbericht wird gemeinsam von mehreren führenden akademischen und industriellen Institutionen veröffentlicht. Es werden nicht nur Techniken zur Verbesserung von Codedaten ausführlich erläutert, sondern auch Leitlinien für zukünftige Forschungen und Anwendungen bereitgestellt. Wir glauben, dass diese Rezension mehr Forscher dazu inspirieren wird, sich für die Anwendung der Code-Datenerweiterung im Deep Learning zu interessieren und die weitere Erforschung und Entwicklung in diesem Bereich voranzutreiben Entwicklung
: Das Codemodell wird auf Basis eines großen Quellcodekorpus trainiert und kann den Kontext von Codeausschnitten genau simulieren. Von der frühen Einführung von Deep-Learning-Architekturen wie LSTM und Seq2Seq bis zur späteren Integration vorab trainierter Sprachmodelle haben diese Modelle bei nachgelagerten Aufgaben über mehrere Quellen hinweg eine hervorragende Leistung gezeigt. Einige Modelle berücksichtigen beispielsweise den Datenfluss des Programms während der Vortrainingsphase, bei dem es sich um die Struktur der semantischen Ebene des Codes handelt, die zur Erfassung der Beziehung zwischen Variablen verwendet wird.
Die Bedeutung der Datenerweiterungstechnologie
: Die Datenerweiterungstechnologie erhöht die Vielfalt der Trainingsmuster durch Datensynthese und verbessert dadurch die Leistung des Modells in verschiedenen Aspekten (z. B. Genauigkeit und Robustheit). Im Bereich Computer Vision beispielsweise gehören zu den häufig verwendeten Methoden zur Datenerweiterung das Zuschneiden, Spiegeln und Farbanpassung von Bildern. Bei der Verarbeitung natürlicher Sprache stützt sich die Datenerweiterung stark auf Sprachmodelle, die den Kontext durch Ersetzen von Wörtern oder Umschreiben von Sätzen neu schreiben können.
Besonderheit der Codedatenerweiterung: Im Gegensatz zu Bildern und reinem Text ist Quellcode durch die strengen Syntaxregeln der Programmiersprache eingeschränkt, sodass die Flexibilität der Erweiterung geringer ist. Die meisten Datenerweiterungsmethoden für Code müssen bestimmte Transformationsregeln einhalten, um die Funktionalität und Syntax des ursprünglichen Codeausschnitts beizubehalten. Eine gängige Praxis besteht darin, einen Parser zu verwenden, um einen konkreten Syntaxbaum des Quellcodes zu erstellen und ihn dann in einen abstrakten Syntaxbaum umzuwandeln, wodurch die Darstellung vereinfacht wird und gleichzeitig wichtige Informationen wie Bezeichner und Kontrollflussanweisungen erhalten bleiben. Diese Transformationen bilden die Grundlage regelbasierter Datenerweiterungsmethoden und helfen dabei, vielfältigere Codedarstellungen in der realen Welt zu simulieren, wodurch die Robustheit von Codemodellen verbessert wird, die mit erweiterten Daten trainiert werden. Eine ausführliche Untersuchung der Methoden zur Codedatenerweiterung
In einem tiefen Einblick in die Welt der Codedatenerweiterung unterteilt der Autor diese Techniken in drei Hauptkategorien: regelbasierte Techniken, modellbasierte Techniken, und beispielhafte Interpolationstechniken. Diese verschiedenen Zweige werden im Folgenden kurz beschrieben.
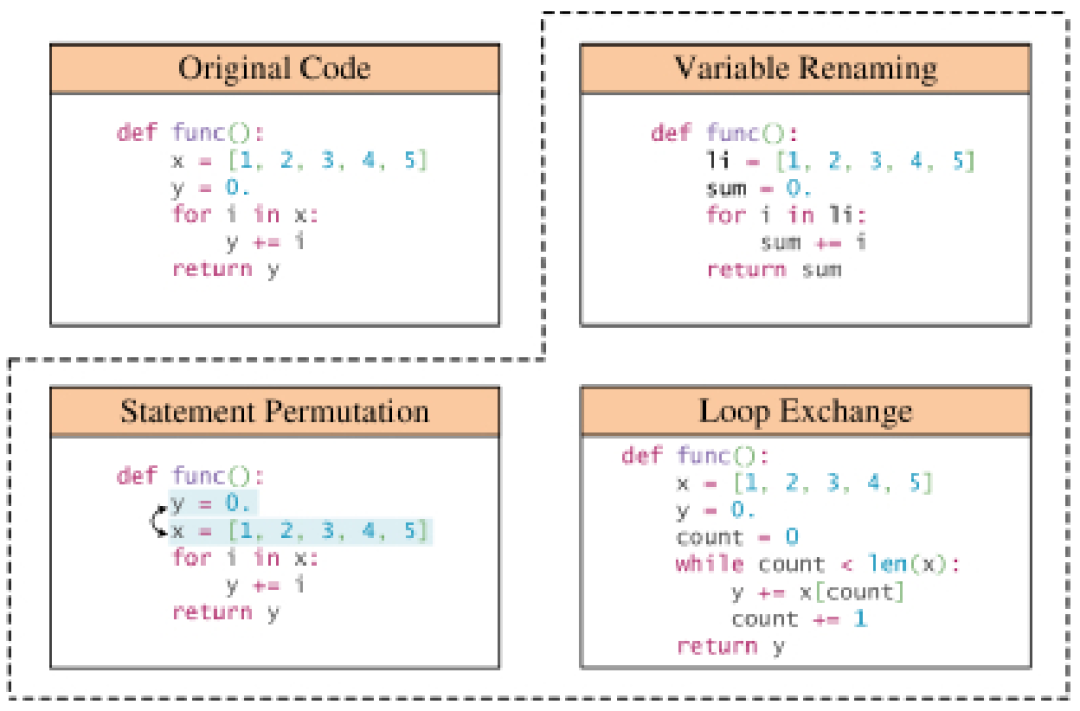
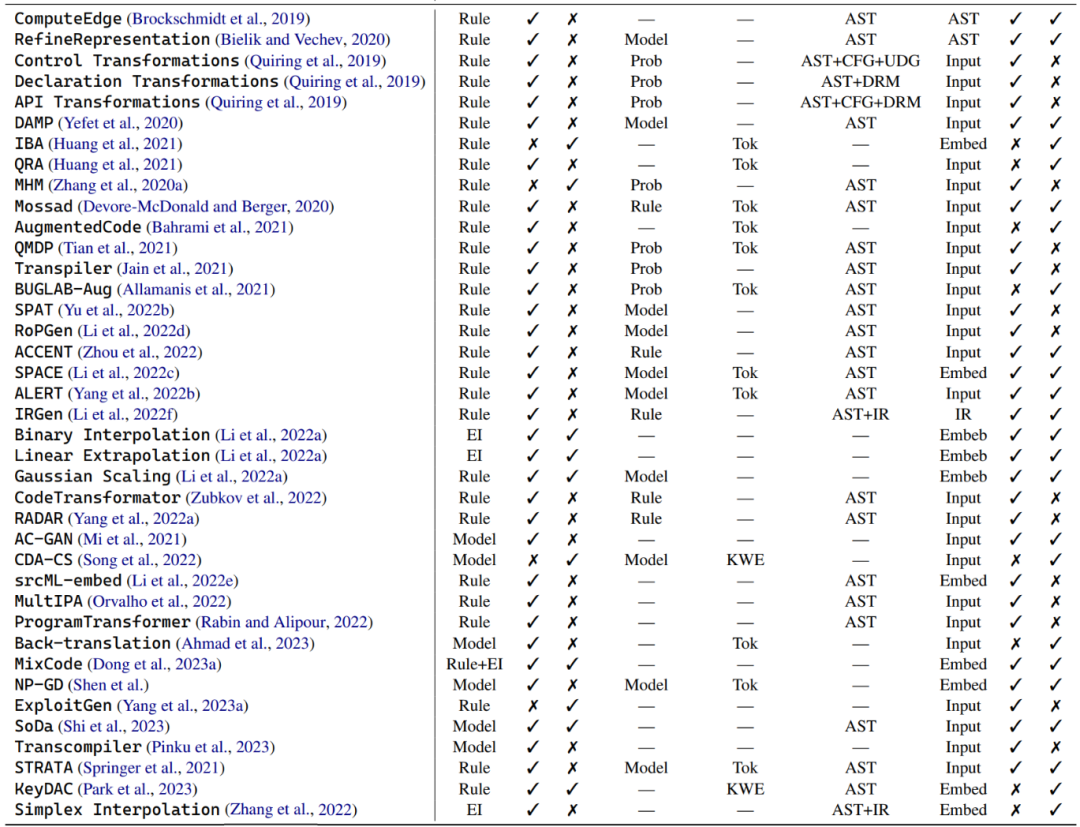
Regelbasierte Technologie: Viele Datenerweiterungsmethoden nutzen vorgegebene Regeln, um Programme zu transformieren und dabei sicherzustellen, dass grammatikalische Regeln und Semantik nicht verletzt werden. Zu diesen Transformationen gehören Vorgänge wie das Ersetzen von Variablennamen, das Umbenennen von Methodennamen und das Einfügen ungültigen Codes. Zusätzlich zur grundlegenden Programmsyntax berücksichtigen einige Transformationen auch tiefere Strukturinformationen, wie beispielsweise Kontrollflussdiagramme und Verwendungsdefinitionsketten. Es gibt eine Untergruppe regelbasierter Datenverbesserungstechniken, die sich auf die Verbesserung des natürlichen Sprachkontexts in Codeausschnitten, einschließlich Dokumentzeichenfolgen und Kommentaren, konzentrieren.
Modellbasierte Techniken : Eine Reihe von Datenerweiterungstechniken für Codemodelle, mit denen verschiedene Modelle trainiert werden sollen, um Daten zu verbessern. Einige Studien nutzen beispielsweise Auxiliary Classification Generative Adversarial Networks (ACGAN), um Erweiterungen zu generieren. Andere Studien haben generative gegnerische Netzwerke trainiert, um sowohl die Codegenerierung als auch die Codesuchfunktionen zu verbessern. Diese Methoden sind hauptsächlich speziell für Codemodelle konzipiert und zielen darauf ab, die Darstellung und das Kontextverständnis von Code auf unterschiedliche Weise zu verbessern.
Beispielhafte Interpolationstechniken: Diese Art der Datenerweiterungstechnik stammt von Mixup, das durch Interpolation der Eingaben und Beschriftungen von zwei oder mehr realen Stichproben arbeitet. Bei einer binären Klassifizierungsaufgabe in Computer Vision und zwei Bildern eines Hundes und einer Katze können diese Datenerweiterungsmethoden beispielsweise die Eingaben der beiden Bilder und ihrer entsprechenden Beschriftungen nach zufällig ausgewählten Gewichtungen zusammenführen. In der Codewelt ist die Anwendung dieser Methoden jedoch durch die einzigartige Programmsyntax und -funktionalität begrenzt. Im Vergleich zur Interpolation auf Oberflächenebene verschmelzen die meisten Methoden zur Erweiterung der Beispielinterpolationsdaten durch Modelleinbettung mehrere reale Beispiele zu einer einzigen Eingabe. Es gibt beispielsweise Untersuchungen zur Kombination regelbasierter Techniken mit Mixup, um Originalcodeschnipsel und ihre transformierten Darstellungen zu mischen.

Strategie und Technologie
In praktischen Anwendungen werden das Design und die Wirksamkeit von Datenerweiterungstechniken für Codemodelle von vielen Faktoren beeinflusst, wie z. B. Rechenkosten, Probenvielfalt und Modell Robustheit. In diesem Abschnitt werden diese Faktoren hervorgehoben und Einblicke und Tipps zum Entwerfen und Optimieren geeigneter Methoden zur Datenerweiterung gegeben.
Methodenstapelung: In der vorherigen Diskussion wurden viele Datenerweiterungsstrategien gleichzeitig in einer einzigen Arbeit vorgeschlagen, mit dem Ziel, die Leistung des Modells zu verbessern. Typischerweise umfasst diese Kombination zwei Arten: die gleiche Art der Datenerweiterung oder eine Mischung verschiedener Datenerweiterungsmethoden. Ersteres wird normalerweise auf regelbasierte Datenerweiterungstechniken angewendet, bei denen der Ausgangspunkt darin besteht, dass eine einzelne Codetransformation die verschiedenen Codierungsstile und -implementierungen in der realen Welt nicht vollständig abbilden kann. Mehrere Arbeiten haben gezeigt, dass die Kombination mehrerer Arten von Datenerweiterungstechniken die Leistung von Codemodellen verbessern kann. Beispielsweise werden ein regelbasiertes Transkodierungsschema und eine modellbasierte Datenerweiterung kombiniert, um einen erweiterten Korpus für das Modelltraining zu erstellen. Andere Forschungsarbeiten konzentrieren sich auf Programmiersprachen, darunter zwei Datenverbesserungstechniken: regelbasierte Nicht-Schlüsselwort-Extraktion und modellbasierte Nicht-Schlüsselwort-Ersetzung.
Optimierung: In einigen Szenarien, wie z. B. der Verbesserung der Robustheit und der Minimierung der Rechenkosten, ist es entscheidend, bestimmte Verbesserungsbeispielkandidaten auszuwählen. Die Autoren bezeichnen diese zielgerichtete Kandidatenauswahl als Optimierung in der Datenerweiterung. Der Artikel stellt hauptsächlich drei Strategien vor: probabilistische Auswahl, modellbasierte Auswahl und regelbasierte Auswahl. Die probabilistische Auswahl optimiert durch Stichproben aus einer Wahrscheinlichkeitsverteilung, während sich die modellbasierte Auswahl bei der Auswahl der am besten geeigneten Beispiele am Modell orientiert. Bei der regelbasierten Auswahl werden bestimmte vorgegebene Regeln oder Heuristiken verwendet, um die am besten geeigneten Beispiele auszuwählen.
Probabilistische Auswahl: Der Autor hat speziell drei repräsentative probabilistische Auswahlstrategien ausgewählt, darunter MHM, QMDP und BUGLAB-Aug. MHM verwendet die probabilistische Stichprobenmethode Metropolis-Hastings, eine Markov-Ketten-Monte-Carlo-Technik zur Auswahl gegnerischer Beispiele mit Identifikatorersatz. QMDP nutzt Q-Learning-Methoden, um regelbasierte Strukturtransformationen strategisch auszuwählen und durchzuführen.
Modellbasierte Auswahl: Einige Datenerweiterungstechniken, die diese Strategie anwenden, nutzen die Gradienteninformationen des Modells, um die Auswahl von Erweiterungsbeispielen zu steuern. Eine typische Methode ist die Datenerweiterungs-MP-Methode, die auf der Grundlage von Modellverlusten optimiert, kontradiktorische Beispiele auswählt und durch Variablenumbenennung generiert. SPACE wählt und stört Einbettungen von Code-Identifikatoren mittels Gradientenaufstieg, mit dem Ziel, die Leistungsauswirkungen des Modells zu maximieren und gleichzeitig die semantische und syntaktische Korrektheit der Programmiersprache aufrechtzuerhalten.
Regelbasierte Auswahl : Die regelbasierte Auswahl ist eine leistungsstarke Methode, die vorgegebene Fitnessfunktionen oder -regeln verwendet. Dieser Ansatz basiert häufig auf Entscheidungsindikatoren. Beispielsweise verwendet IRGen eine auf einem genetischen Algorithmus basierende Optimierungstechnik und eine Fitnessfunktion, die auf IR-Ähnlichkeit basiert. Während ACCENT und RA Data Augmentation R Bewertungsmetriken wie BLEU bzw. CodeBLEU verwenden, um den Auswahl- und Ersetzungsprozess zu steuern und eine maximale gegnerische Wirkung zu erzielen.
Anwendungsszenarien
Datenerweiterungsmethoden können direkt in mehreren gängigen Codeszenarien angewendet werden
Gegnerische Beispiele für Robustheit: Robustheit ist ein Schlüssel und eine Dimension der Komplexität. Die Entwicklung effektiver Datenerweiterungstechniken zur Generierung kontroverser Beispiele zur Identifizierung und Behebung von Schwachstellen in Codemodellen ist in den letzten Jahren zu einem Forschungsschwerpunkt geworden. Mehrere Studien haben die Robustheit des Codemodells weiter gestärkt, indem sie die Robustheit des Modells mithilfe verschiedener Methoden zur Datenerweiterung getestet und verbessert haben.
Ressourcenarmer Bereich: Im Bereich der Softwareentwicklung sind die Programmiersprachenressourcen stark unausgewogen. Beliebte Programmiersprachen wie Python und Java spielen in Open-Source-Repositories eine große Rolle, während viele Sprachen wie Rust sehr ressourcenarm sind. Codemodelle werden oft auf der Grundlage von Open-Source-Repositories und -Foren trainiert, und Ungleichgewichte bei den Programmiersprachenressourcen können sich negativ auf ihre Leistung in ressourcenarmen Programmiersprachen auswirken. Die Anwendung von Datenerweiterungsmethoden in ressourcenarmen Domänen ist ein wiederkehrendes Thema.
Abrufverbesserung: In den Bereichen der Verarbeitung und Codierung natürlicher Sprache erregen Datenverbesserungsanwendungen der Abrufverbesserung immer mehr Aufmerksamkeit. Diese Abruferweiterungs-Frameworks für Codemodelle integrieren Beispiele zur Abrufverbesserung aus dem Trainingssatz beim Vortraining oder bei der Feinabstimmung des Codemodells. Diese Erweiterungsmethode verbessert die Parametereffizienz des Modells.
Kontrastives Lernen: Kontrastives Lernen ist ein weiterer Anwendungsbereich, in dem Datenerweiterungsmethoden in Codeszenarien eingesetzt werden. Dadurch kann das Modell einen Einbettungsraum erlernen, in dem ähnliche Proben nahe beieinander liegen und unterschiedliche Proben weiter voneinander entfernt sind. Datenerweiterungsmethoden werden verwendet, um Stichproben zu erstellen, die positiven Stichproben ähneln, um die Modellleistung bei Aufgaben wie Fehlererkennung, Klonerkennung und Codesuche zu verbessern.
Der folgende Artikel bespricht mehrere gängige Codierungsaufgaben und die Anwendung von Datenerweiterungsbemühungen auf Bewertungsdatensätze, einschließlich Klonerkennung, Fehlererkennung und -reparatur, Codezusammenfassung, Codesuche, Codegenerierung und Codeübersetzung
Herausforderungen und Chancen
In Bezug auf die Codedatenverbesserung gibt es nach Ansicht des Autors viele große Herausforderungen. Es sind jedoch diese Herausforderungen, die dem Fachgebiet neue Möglichkeiten und spannende Chancen eröffnen. Die meisten vorhandenen Forschungsarbeiten konzentrieren sich auf die Bereiche Bildverarbeitung und natürliche Sprache und betrachten die Datenerweiterung als eine Methode zur Anwendung bereits vorhandenen Wissens über Daten oder Aufgabeninvarianz. Bei der Hinwendung zum Code führten frühere Arbeiten zwar neue Methoden ein oder demonstrierten, wie Techniken zur Datenerweiterung effektiv sein können, übersahen jedoch häufig das Warum und Wie, insbesondere aus mathematischer Sicht. Die diskrete Natur des Codes macht theoretische Diskussionen noch wichtiger. Theoretische Diskussionen ermöglichen es jedem, die Datenerweiterung aus einer breiteren Perspektive als nur im Hinblick auf experimentelle Ergebnisse zu verstehen.
Mehr Forschung zu vorab trainierten Modellen: In den letzten Jahren wurden vorab trainierte Codemodelle im Codierungsbereich häufig eingesetzt, und durch die Selbstüberwachung großer Korpora wurde umfangreiches Wissen angesammelt. Obwohl in vielen Studien vorab trainierte Codemodelle zur Datenerweiterung verwendet wurden, beschränken sich die meisten Versuche immer noch auf den Ersatz von Maskentokens oder die direkte Generierung nach der Feinabstimmung. Die Nutzung des Datenerweiterungspotenzials groß angelegter Sprachmodelle ist eine neue Forschungsmöglichkeit in der Welt der Codierung.
Anders als die bisherige Verwendung vorab trainierter Modelle zur Datenverbesserung haben diese Arbeiten die Ära der „hinweisbasierten Datenverbesserung“ eröffnet. Die auf Hinweisen basierende Erforschung der Datenerweiterung bleibt jedoch ein relativ unberührter Forschungsbereich in der Codewelt. Umgeschriebener Inhalt: Anders als die bisherige Verwendung vorab trainierter Modelle bei der Datenverbesserung läuten diese Arbeiten die Ära der „hinweisbasierten Datenverbesserung“ ein. Es gibt jedoch noch relativ wenige Studien zur hinweisbasierten Datenerweiterung in der Codedomäne. Die Autoren sind sich jedoch darüber im Klaren, dass es noch wenig Forschung zu anderen aufgabenspezifischen Daten im Codierungsbereich gibt. Beispielsweise können API-Empfehlungen und API-Sequenzgenerierung als Teil der Codierungsaufgaben betrachtet werden. Die Autoren stellten eine Lücke in den Datenerweiterungstechniken zwischen diesen beiden verschiedenen Ebenen fest, die Möglichkeiten für zukünftige Arbeiten zur Erkundung bietet.
Weitere Erforschung von Code auf Projektebene und ressourcenarmen Programmiersprachen: Bestehende Methoden haben ausreichende Fortschritte bei Codefragmenten auf Funktionsebene und gängigen Programmiersprachen gemacht. Gleichzeitig sind Verbesserungsmethoden für ressourcenarme Sprachen zwar stärker nachgefragt, aber relativ selten. Die Erforschung dieser beiden Richtungen ist noch begrenzt und die Autoren glauben, dass es sich dabei möglicherweise um vielversprechende Richtungen handelt.
Milderung sozialer Vorurteile : Da Codemodelle in der Softwareentwicklung voranschreiten, können sie zur Entwicklung menschenzentrierter Anwendungen wie Personalwesen und Bildung verwendet werden, bei denen voreingenommene Verfahren zu Bedenken hinsichtlich der Repräsentation unterrepräsentierter Bevölkerungsgruppen führen können und unethische Entscheidungen. Während soziale Vorurteile im NLP gut untersucht sind und durch Datenerweiterung gemildert werden können, wurde sozialen Vorurteilen im Code noch keine Aufmerksamkeit geschenkt.
Lernen mit kleinen Beispielen: In einem Szenario mit kleinen Beispielen muss das Modell eine Leistung erzielen, die mit herkömmlichen Modellen für maschinelles Lernen vergleichbar ist, die Trainingsdaten sind jedoch äußerst begrenzt. Datenerweiterungsmethoden bieten eine einfache Lösung für dieses Problem. Allerdings gibt es nur begrenzte Arbeiten zum Einsatz von Datenerweiterungsmethoden in kleinen Stichprobenszenarien. In einigen Beispielszenarien hält der Autor dies für eine interessante Frage, wie das Modell durch die Generierung hochwertiger erweiterter Daten mit schnellen Generalisierungs- und Problemlösungsfähigkeiten ausgestattet werden kann.
Multimodale Anwendungen: Es ist wichtig zu beachten, dass die ausschließliche Konzentration auf Codeausschnitte auf Funktionsebene die Komplexität und Nuancen realer Programmiersituationen nicht genau wiedergibt. In diesem Fall arbeiten Entwickler normalerweise an mehreren Dateien und Ordnern gleichzeitig. Obwohl diese multimodalen Anwendungen immer beliebter werden, hat keine Forschung Methoden zur Datenerweiterung auf sie angewendet. Eine der Herausforderungen besteht darin, die eingebetteten Darstellungen jeder Modalität in Codemodellen effektiv zu überbrücken, was in visuell-linguistischen multimodalen Aufgaben untersucht wurde.
Mangelnde Einheitlichkeit : Die aktuelle Literatur zur Codedatenerweiterung stellt eine herausfordernde Landschaft dar, in der die beliebtesten Ansätze oft als unterstützend bezeichnet werden. In einigen empirischen Studien wurde versucht, Datenerweiterungsmethoden für Codemodelle zu vergleichen. Diese Arbeiten nutzen jedoch nicht die meisten vorhandenen fortgeschrittenen Datenerweiterungsmethoden. Während für Computer Vision (wie die Standard-Erweiterungsbibliothek in PyTorch) und NLP (wie NL-Augmenter) gut etablierte Datenerweiterungs-Frameworks existieren, fehlen auffälligerweise entsprechende Bibliotheken für allgemeine Datenerweiterungstechniken für Codemodelle. Da bestehende Methoden zur Datenerweiterung häufig anhand verschiedener Datensätze evaluiert werden, ist es außerdem schwierig, ihre Wirksamkeit zu bestimmen. Daher glauben die Autoren, dass der Fortschritt der Datenerweiterungsforschung durch die Etablierung standardisierter und einheitlicher Benchmark-Aufgaben sowie Datensätze zum Vergleich und zur Bewertung der Wirksamkeit verschiedener Erweiterungsmethoden erheblich gefördert wird. Dies wird den Weg für ein systematischeres und vergleichenderes Verständnis der Stärken und Grenzen dieser Methoden ebnen.
Das obige ist der detaillierte Inhalt vonCode-Datenerweiterung im Deep Learning: Ein Rückblick auf 89 Forschungen in 5 Jahren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!