Wie sollten wir Metas „Alles aufteilen“-Modell optimieren? Dieser vom PyTorch-Team verfasste Blog hilft Ihnen dabei, die Frage von einfach bis tief zu beantworten.
Von Anfang des Jahres bis heute hat sich die generative KI rasant entwickelt. Aber oft stehen wir vor einem schwierigen Problem: Wie können wir das Training, die Argumentation usw. der generativen KI beschleunigen, insbesondere bei Verwendung von PyTorch? In diesem Artikel liefern uns Forscher des PyTorch-Teams eine Lösung. Der Artikel konzentriert sich auf die Verwendung von reinem nativem PyTorch zur Beschleunigung generativer KI-Modelle. Außerdem werden neue PyTorch-Funktionen und praktische Beispiele für deren Kombination vorgestellt. Was war das Ergebnis? Das PyTorch-Team gab an, das „Split Everything“ (SAM)-Modell von Meta neu geschrieben zu haben, was zu einem Code führte, der achtmal schneller als die ursprüngliche Implementierung ist, ohne an Genauigkeit zu verlieren, alles mit nativem PyTorch optimiert. 
Blog-Adresse: https://pytorch.org/blog/accelerating-generative-ai/Nachdem Sie diesen Artikel gelesen haben, erfahren Sie:
- Torch.compile: PyTorch Der Modell-Compiler PyTorch 2.0 fügt eine neue Funktion namens Torch.compile () hinzu, die vorhandene Modelle mit einer Codezeile beschleunigen kann.
- GPU-Quantisierung: Beschleunigen Sie das Modell durch Reduzierung der Berechnungsgenauigkeit; Dot Product Attention): speichereffiziente Aufmerksamkeitsimplementierung;
- Halbstrukturierte (2:4) Sparsity: ein für GPU optimiertes Sparse-Speicherformat; Stapeln Sie Daten uneinheitlicher Größe in einen einzigen Tensor, z. B. Bilder unterschiedlicher Größe.
- Benutzerdefinierte Triton-Operationen: Verwenden Sie Triton Python DSL, um GPU-Operationen zu schreiben und anzupassen. Durch die Operatorregistrierung können Sie sie einfach in verschiedene Komponenten von PyTorch integrieren .
-
Erhöhter Durchsatz und geringerer Speicheraufwand durch die nativen Funktionen von PyTorch.
SAM wurde von Meta vorgeschlagen. Weitere Informationen zu dieser Forschung finden Sie unter „CV existiert nicht mehr? Meta veröffentlicht „Alles aufteilen“-KI-Modell, CV könnte den GPT-3-Moment einleiten
“ . Als nächstes stellt der Artikel den SAM-Optimierungsprozess vor, einschließlich Leistungsanalyse, Engpasserkennung und wie man diese neuen Funktionen in PyTorch integriert, um diese Probleme zu lösen, mit denen SAM konfrontiert ist. Darüber hinaus werden in diesem Artikel auch einige neue Funktionen von PyTorch vorgestellt: Torch.compile, SDPA, Triton-Kernel, Nested Tensor und halbstrukturierte Sparsity (halbstrukturierte Sparsity).
Der Inhalt dieses Artikels wird Schritt für Schritt ausführlich vorgestellt. Interessierte Freunde können ihn außerdem auf GitHub herunterladen Daten über die Perfetto-Benutzeroberfläche, um den Anwendungswert jedes Merkmals zu erläutern.
GitHub-Adresse: https://github.com/pytorch-labs/segment-anything-fast
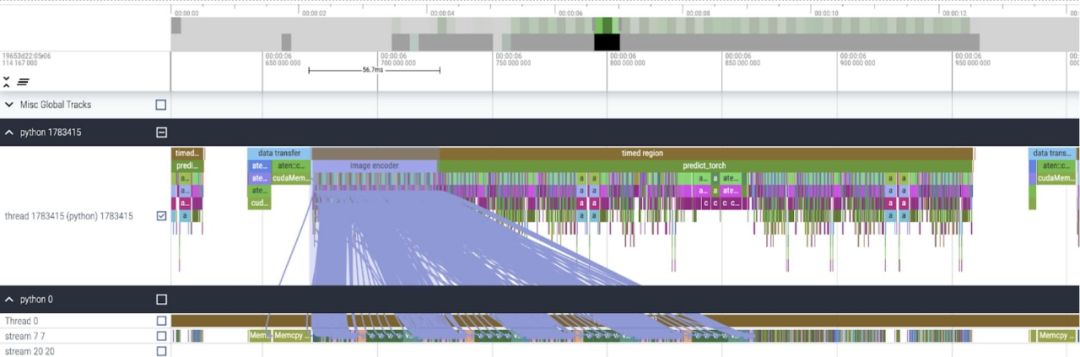
Neuschreiben des Segmentierungs-Alles-Modells SAMDiese Studie besagt, dass dieser Artikel Der verwendete SAM-Basisdatentyp ist float32 dtype und die Stapelgröße beträgt 1. Die Ergebnisse der Verwendung von PyTorch Profiler zum Anzeigen des Kernel-Trace sind wie folgt:
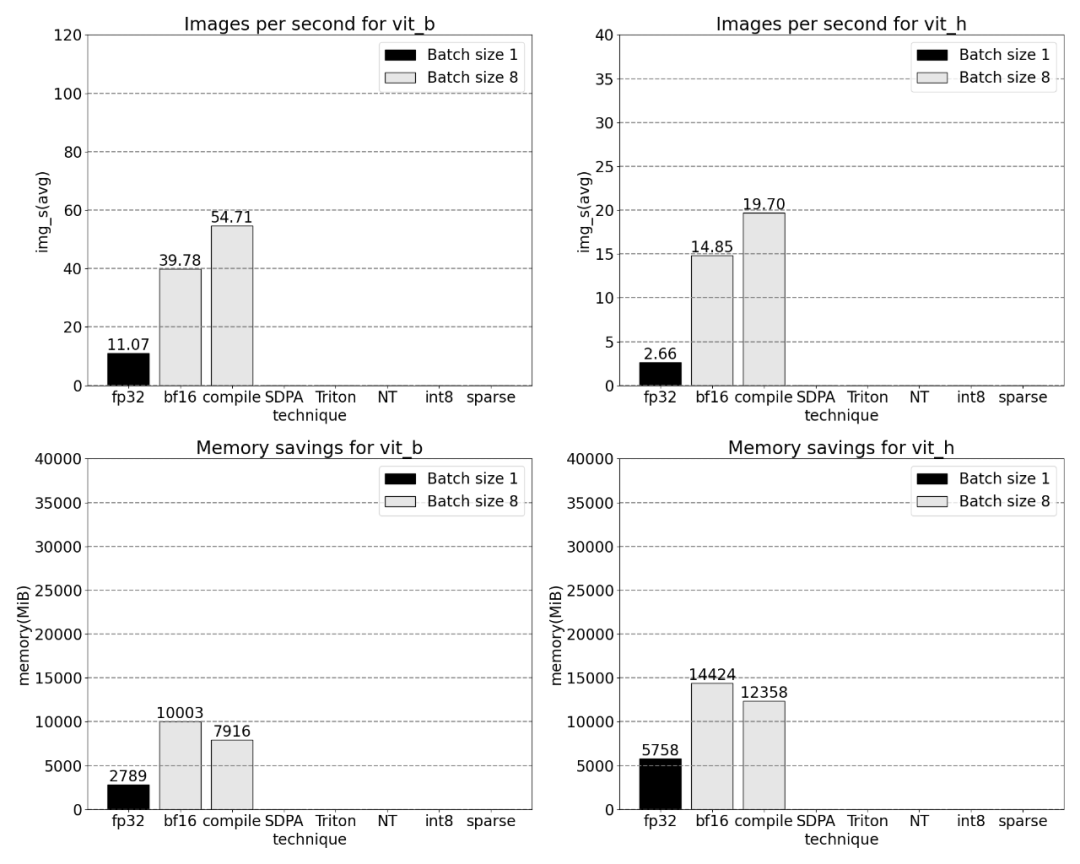
In diesem Artikel wurde festgestellt, dass es zwei Stellen gibt, an denen SAM optimiert werden kann: Der erste ist ein langer Aufruf von aten::index, der durch den zugrunde liegenden Aufruf verursacht wird, der durch Tensorindexoperationen (z. B. []) generiert wird. . Die tatsächliche Zeit, die die GPU für aten::index aufwendet, ist jedoch relativ gering. Der Grund dafür ist, dass aten::index beim Starten von zwei Kernen cudaStreamSynchronize zwischen den beiden blockiert. Das bedeutet, dass die CPU darauf wartet, dass die GPU die Verarbeitung beendet, bis der zweite Kern gestartet wird. Um SAM zu optimieren, ist dieses Papier daher der Ansicht, dass man sich bemühen sollte, die blockierende GPU-Synchronisierung zu beseitigen, die Leerlaufzeiten verursacht. Der zweite Grund ist, dass SAM viel GPU-Zeit mit der Matrixmultiplikation verbringt (dunkelgrün im Bild oben), was in Transformers üblich ist. Wenn wir die GPU-Zeit reduzieren können, die ein SAM-Modell für Matrixmultiplikationen aufwendet, können wir SAM erheblich beschleunigen. Als Nächstes verwendet dieser Artikel den Durchsatz (img/s) und den Speicher-Overhead (GiB) von SAM, um eine Basislinie festzulegen. Danach folgt der Optimierungsprozess.
Bfloat16 mit halber Präzision (plus GPU-Synchronisierung und Stapelverarbeitung) Um das oben genannte Problem zu lösen, d. h. dafür zu sorgen, dass die Matrixmultiplikation weniger Zeit in Anspruch nimmt, wendet sich dieser Artikel an bfloat16. Bfloat16 ist ein häufig verwendeter Typ mit halber Genauigkeit, der viel Rechenzeit und Speicher sparen kann, indem er die Präzision jedes Parameters und jeder Aktivierung verringert. 1 Verwenden Sie BFLOAT16, um den Padding-Typ zu ersetzen. Um die GPU-Synchronisierung zu entfernen, stellt dieser Artikel außerdem fest, dass es zwei Positionen gibt, die optimiert werden können.
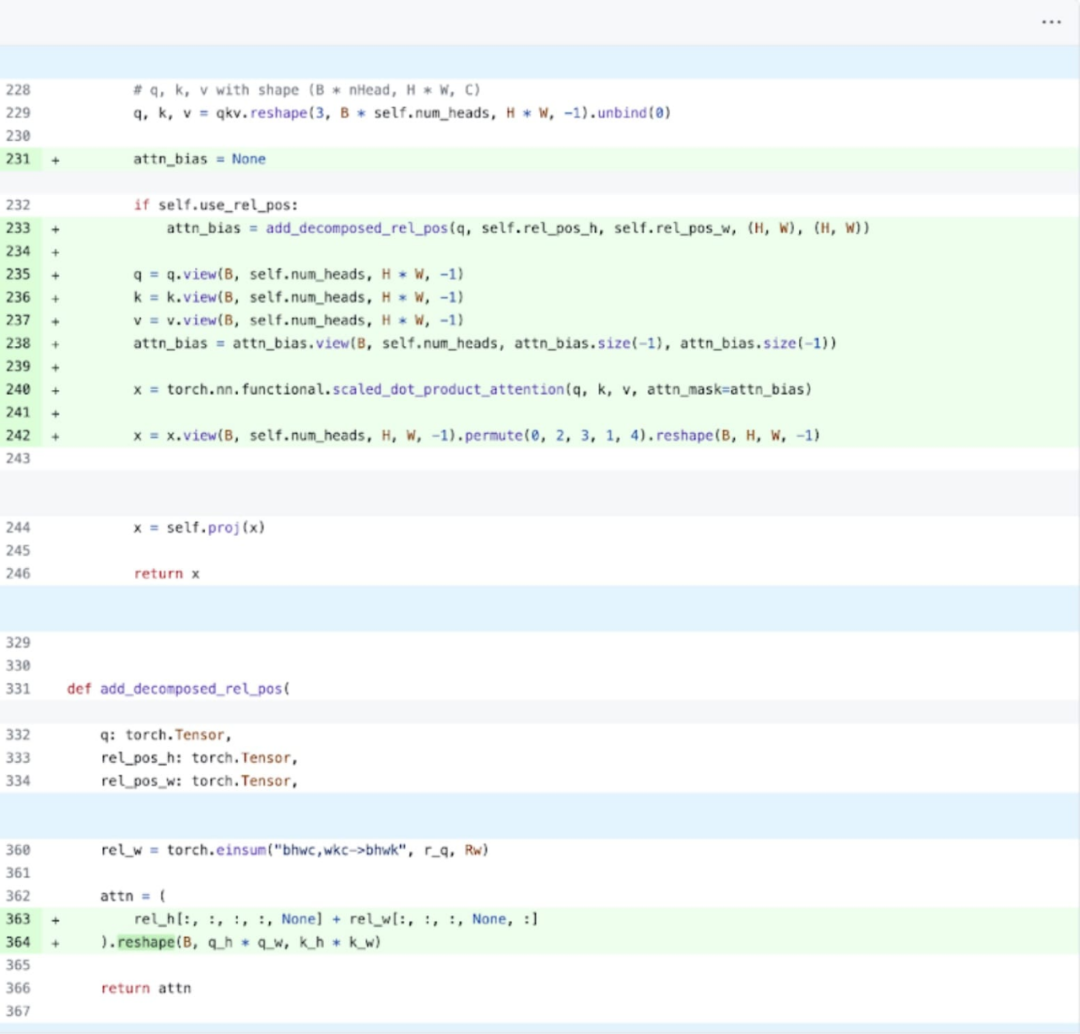
Insbesondere (anhand des Bildes oben ist es einfacher zu verstehen, dass die angezeigten Variablennamen alle im Code enthalten sind) ergab die Studie, dass es im SAM-Bildencoder Koordinatenskalierer gibt und k_coords, diese Variablen werden auf der CPU zugewiesen und verarbeitet. Sobald diese Variablen jedoch zur Indizierung in rel_pos_resized verwendet werden, werden diese Variablen durch diese Indizierungsvorgänge automatisch auf die GPU verschoben, und diese Kopie führt zu einer GPU-Synchronisierung. Um das obige Problem zu lösen, wurde in der Studie festgestellt, dass dieser Teil gelöst werden kann, indem man ihn wie oben gezeigt mit Torch.where umschreibt.
Nach der Anwendung dieser Änderungen wurde in diesem Artikel festgestellt, dass zwischen einzelnen Kernel-Aufrufen eine erhebliche Zeitlücke besteht, insbesondere bei kleinen Chargen (hier 1). Um ein tieferes Verständnis dieses Phänomens zu erlangen, beginnt dieser Artikel mit einer Leistungsanalyse der SAM-Inferenz mit einer Stapelgröße von 8:
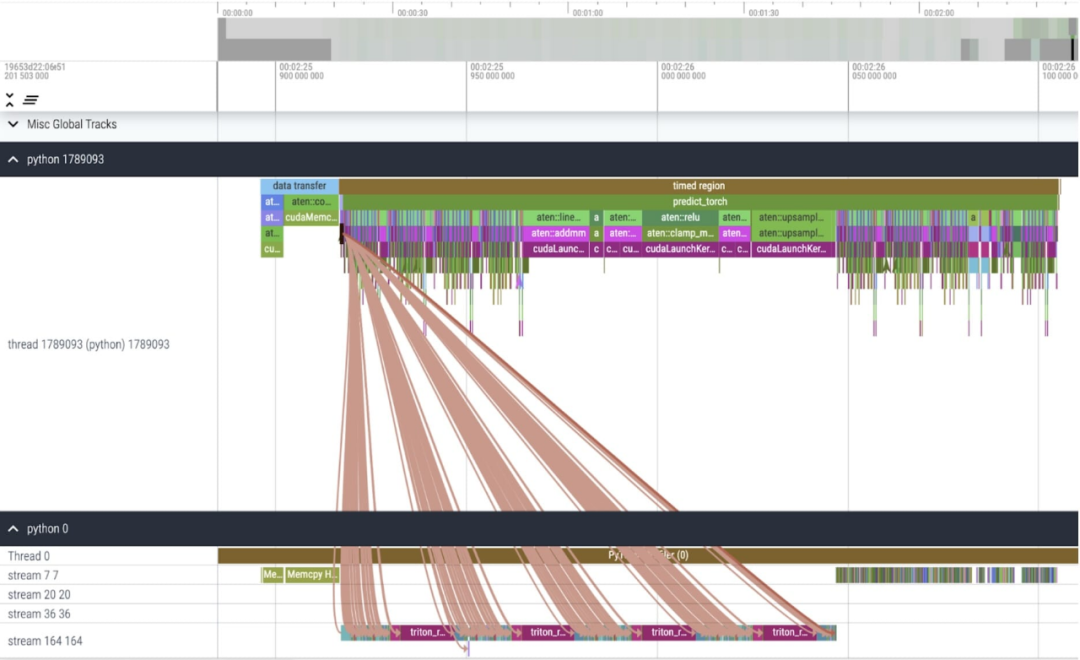
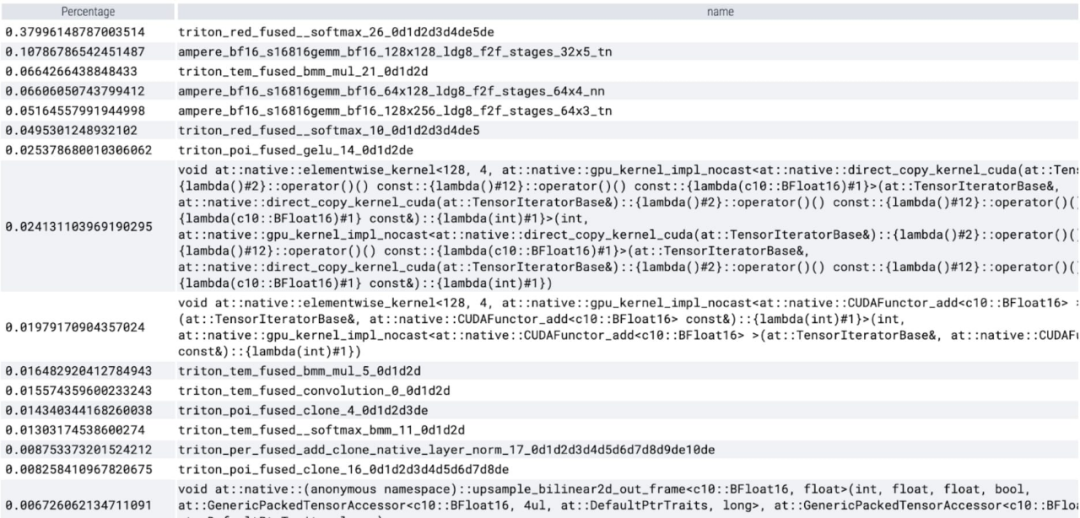
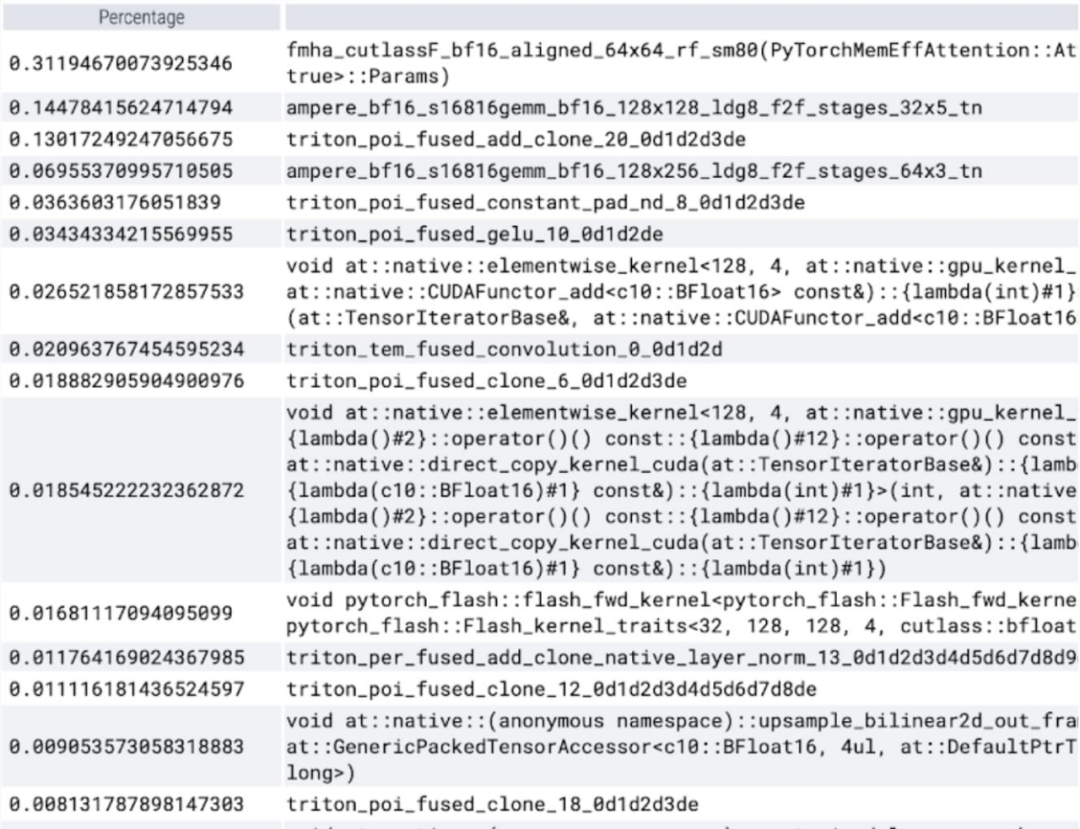
Bei der Betrachtung der pro Kern aufgewendeten Zeit stellt dieser Artikel fest, dass SAM den größten Teil seiner GPU verbraucht Zeit Auf elementweisen Kerneln und Softmax-Operationen. Jetzt können Sie sehen, dass die relativen Kosten der Matrixmultiplikation viel geringer sind.
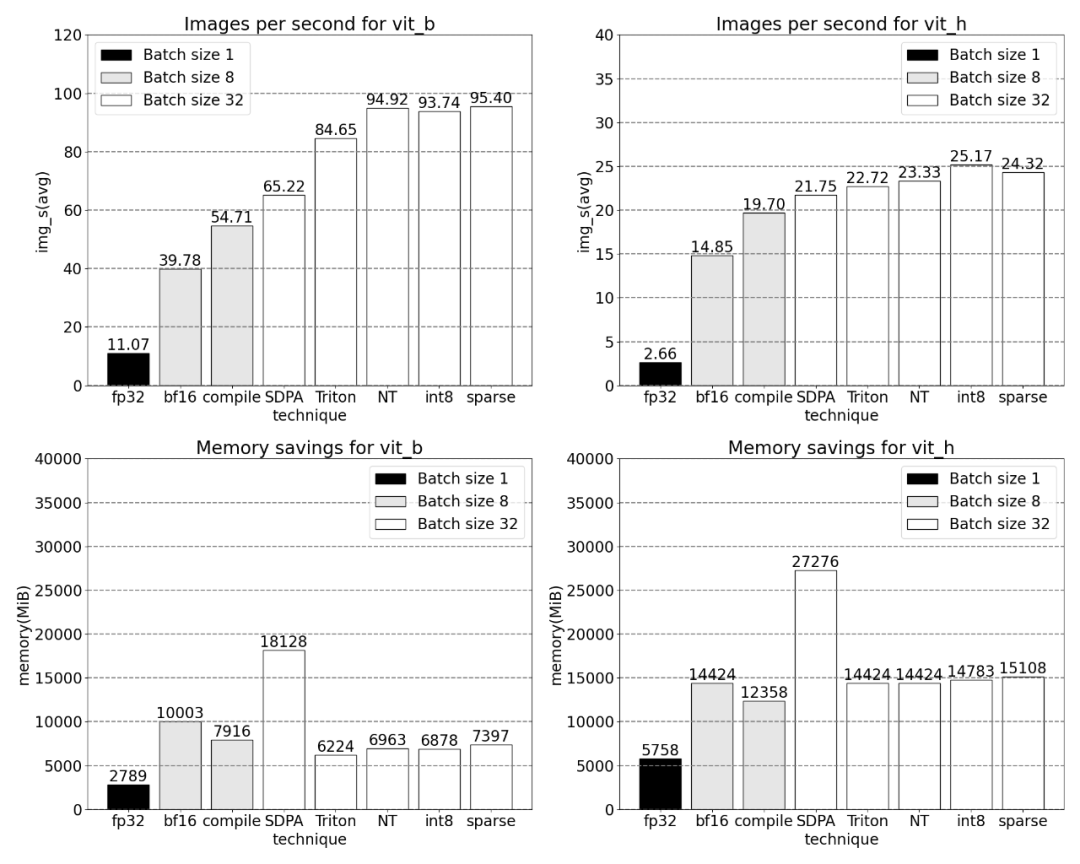
Durch die Kombination von GPU-Synchronisierung und bfloat16-Optimierung wird die SAM-Leistung um das Dreifache verbessert.
Torch.compile (+Graph Breaks und CUDA Graphs)In diesem Artikel wurde festgestellt, dass es im Prozess der eingehenden Untersuchung von SAM viele kleine Operationen gibt. Sie glauben, dass die Verwendung eines Compilers zum Zusammenführen von Operationen großartig ist Vorteile, also PyTorch Die folgenden Optimierungen wurden an Torch.compile vorgenommen:
- Fusion von Operationssequenzen wie nn.LayerNorm oder nn.GELU in einen einzigen GPU-Kernel;
- Fusion von Operationen direkt im Anschluss der Matrixmultiplikationskernel, um die Anzahl der GPU-Kernelaufrufe zu reduzieren.
Durch diese Optimierungen reduzierte die Forschung die Anzahl der globalen GPU-Speicher-Roundtrips und beschleunigte so die Schlussfolgerung. Wir können Torch.compile jetzt auf dem Bildencoder von SAM ausprobieren. Um die Leistung zu maximieren, verwendet dieser Artikel einige erweiterte Kompilierungstechniken:
Die Ergebnisse zeigen, dass Torch.compile sehr gut funktioniert.
Es ist zu beobachten, dass Softmax einen großen Teil der Zeit einnimmt, gefolgt von verschiedenen GEMM-Varianten. Die folgenden Maße gelten für Losgrößen ab 8 Stück.
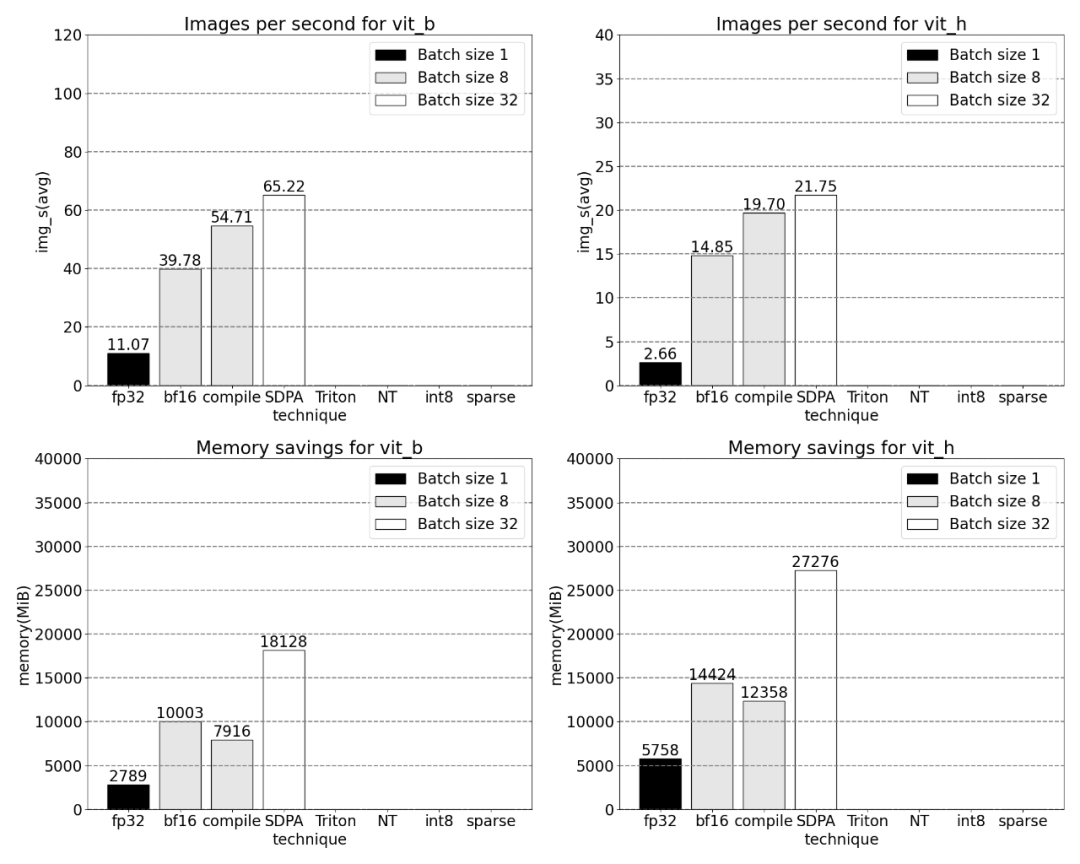
SDPA:scaled_dot_product_attentionAls nächstes führte dieser Artikel Experimente zu SDPA (scaled_dot_product_attention) durch, wobei der Schwerpunkt auf dem Aufmerksamkeitsmechanismus lag. Im Allgemeinen skalieren native Aufmerksamkeitsmechanismen quadratisch mit der Sequenzlänge in Zeit und Gedächtnis. Die SDPA-Operationen von PyTorch basieren auf den speichereffizienten Aufmerksamkeitsprinzipien von Flash Attention, FlashAttentionV2 und xFormer, die die GPU-Aufmerksamkeit erheblich beschleunigen können. In Kombination mit Torch.compile ermöglicht dieser Vorgang den Ausdruck und die Fusion eines gemeinsamen Musters in Varianten von MultiheadAttention. Nach einer kleinen Änderung kann das Modell nun Scaled_dot_product_attention verwenden.
Jetzt können Sie sehen, dass der speichereffiziente Attention-Kernel viel Rechenzeit auf der GPU beansprucht:
Mit PyTorchs nativem Scaled_dot_product_attention können Sie dies erheblich erhöhen die Losgröße. Die folgende Grafik zeigt die Änderungen für Losgrößen ab 32.
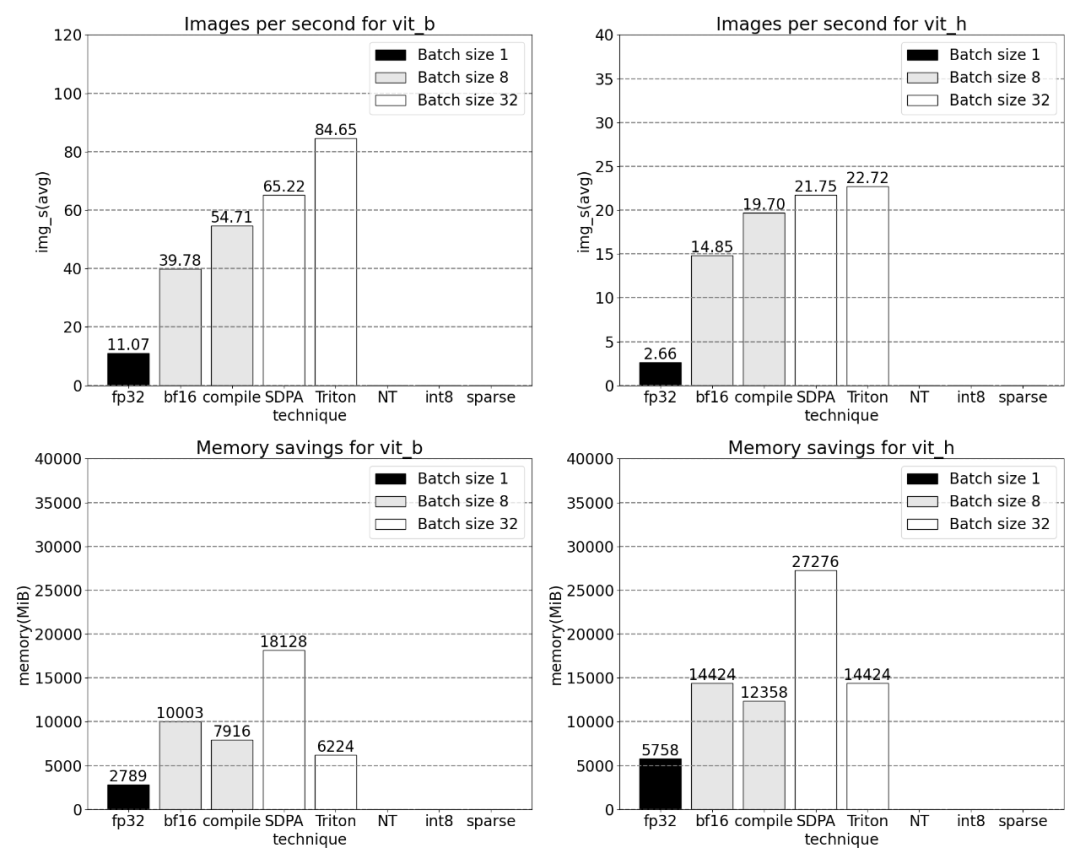
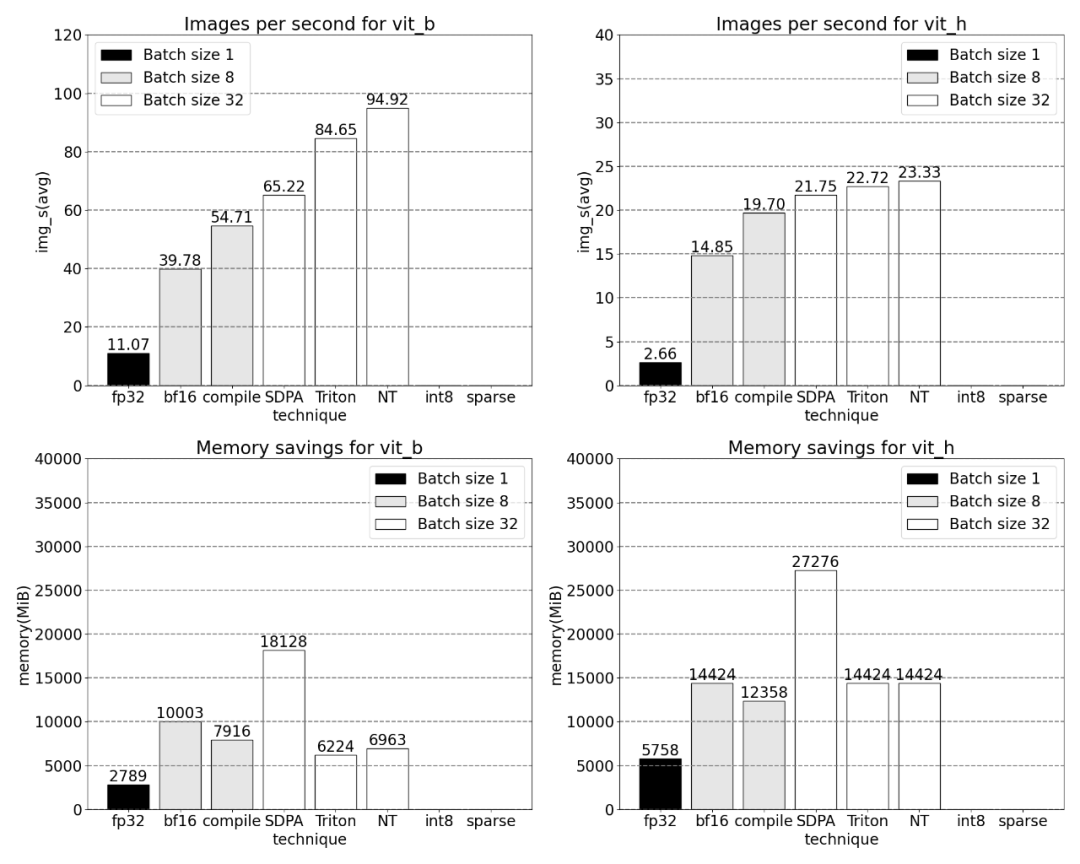
Danach experimentierte die Forschung auch mit Triton, NestedTensor, Stapelverarbeitung Predict_torch, int8-Quantisierung, halbstrukturierter (2:4) Sparsity und anderen Operationen. In diesem Artikel wird beispielsweise ein benutzerdefinierter positioneller Triton-Kernel verwendet und Messergebnisse mit einer Chargengröße von 32 beobachtet.
Bei Verwendung von Nested Tensor variieren die Stapelgrößen von 32 und mehr.
Messungen für Losgrößen ab 32 nach Hinzufügung der Quantisierung.
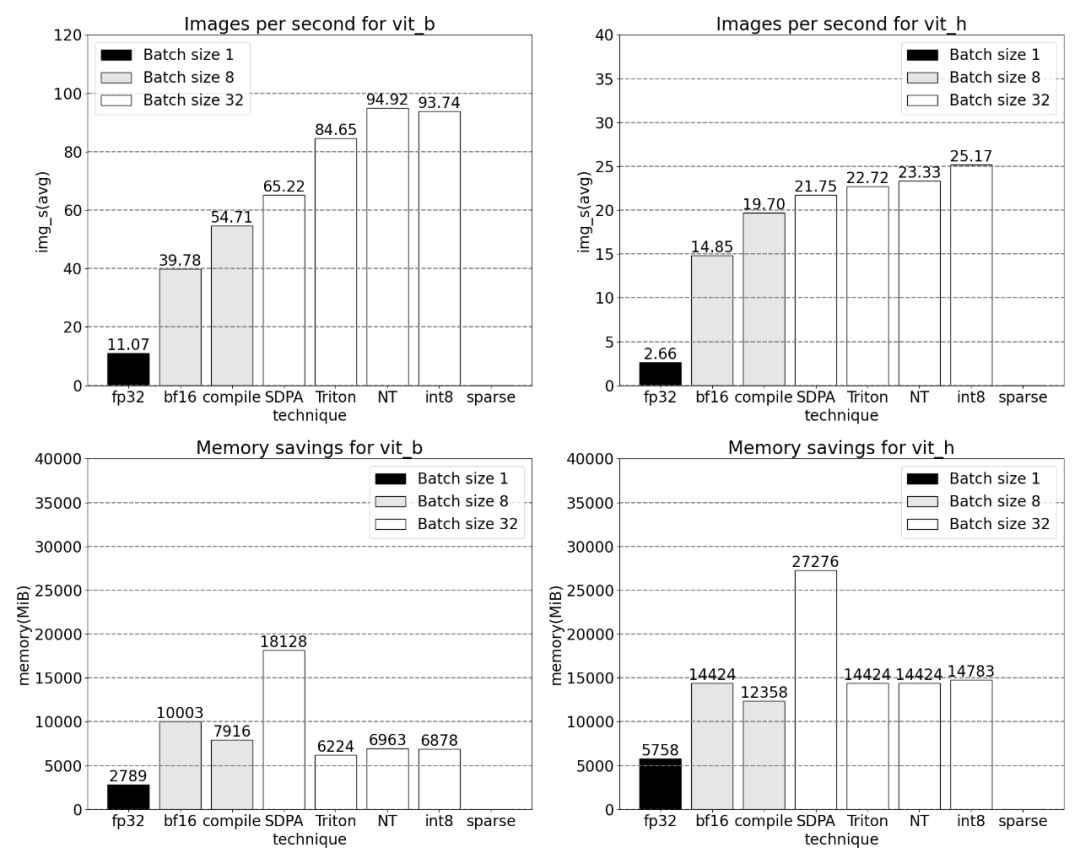
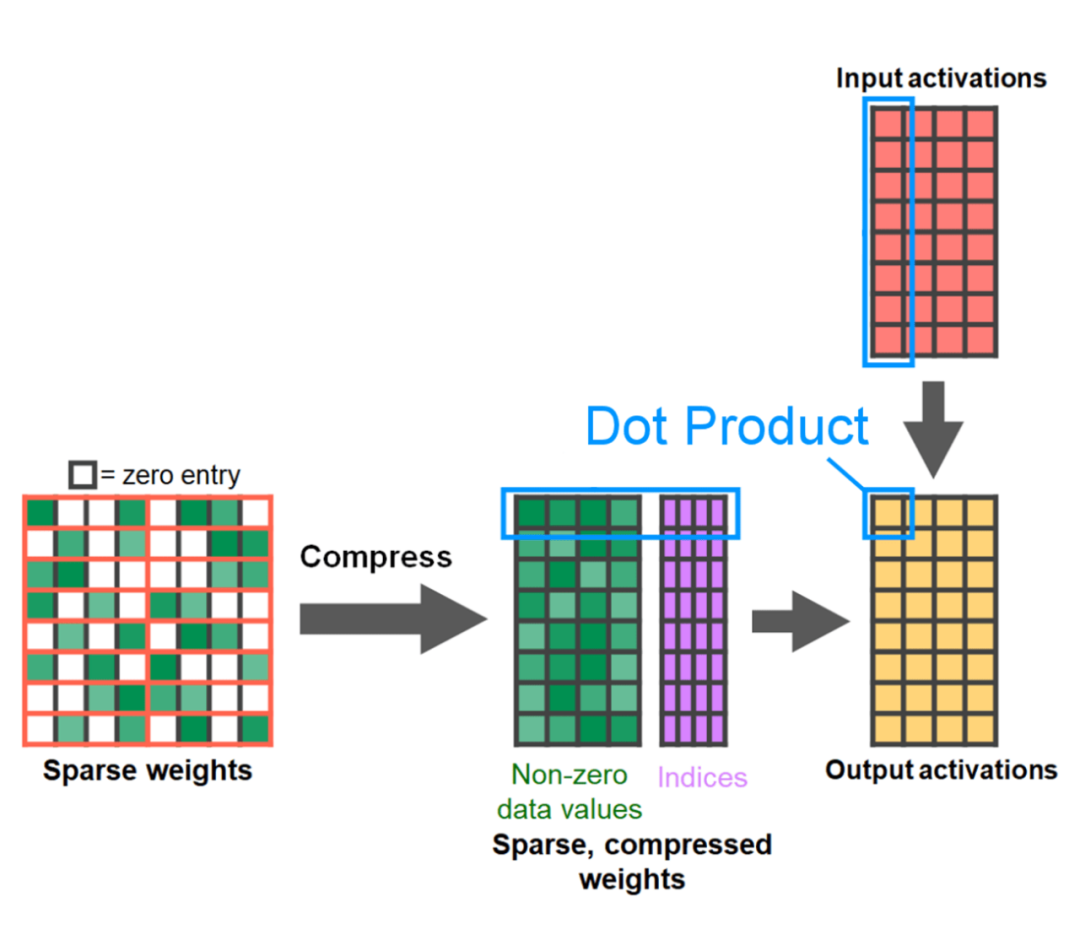
Das Ende des Artikels ist halbstrukturierte Sparsity. Die Studie zeigt, dass die Matrixmultiplikation immer noch einen Engpass darstellt, der angegangen werden muss. Die Lösung besteht darin, die Sparsifizierung zur Annäherung an die Matrixmultiplikation zu verwenden. Durch dünn besetzte Matrizen (d. h. das Nullen der Werte) können weniger Bits zum Speichern von Gewichten und Aktivierungstensoren verwendet werden. Der Vorgang, bei dem festgelegt wird, welche Gewichte in einem Tensor auf Null gesetzt werden, wird als Pruning bezeichnet. Durch das Weglassen kleinerer Gewichte kann die Modellgröße möglicherweise ohne nennenswerten Genauigkeitsverlust verringert werden. Es gibt viele Möglichkeiten zum Beschneiden, von völlig unstrukturiert bis stark strukturiert. Während unstrukturiertes Bereinigen theoretisch nur minimale Auswirkungen auf die Genauigkeit hat, können GPUs, obwohl sie bei der Durchführung großer Multiplikationen mit dichter Matrix sehr effizient sind, in spärlichen Fällen erhebliche Leistungseinbußen erleiden. Eine kürzlich von PyTorch unterstützte Bereinigungsmethode zielt darauf ab, ein Gleichgewicht zu erreichen, das als halbstrukturierte (oder 2:4) Sparsity bezeichnet wird. Diese spärliche Speicherung reduziert den ursprünglichen Tensor um 50 % und erzeugt gleichzeitig eine dichte Tensorausgabe. Siehe Abbildung unten.
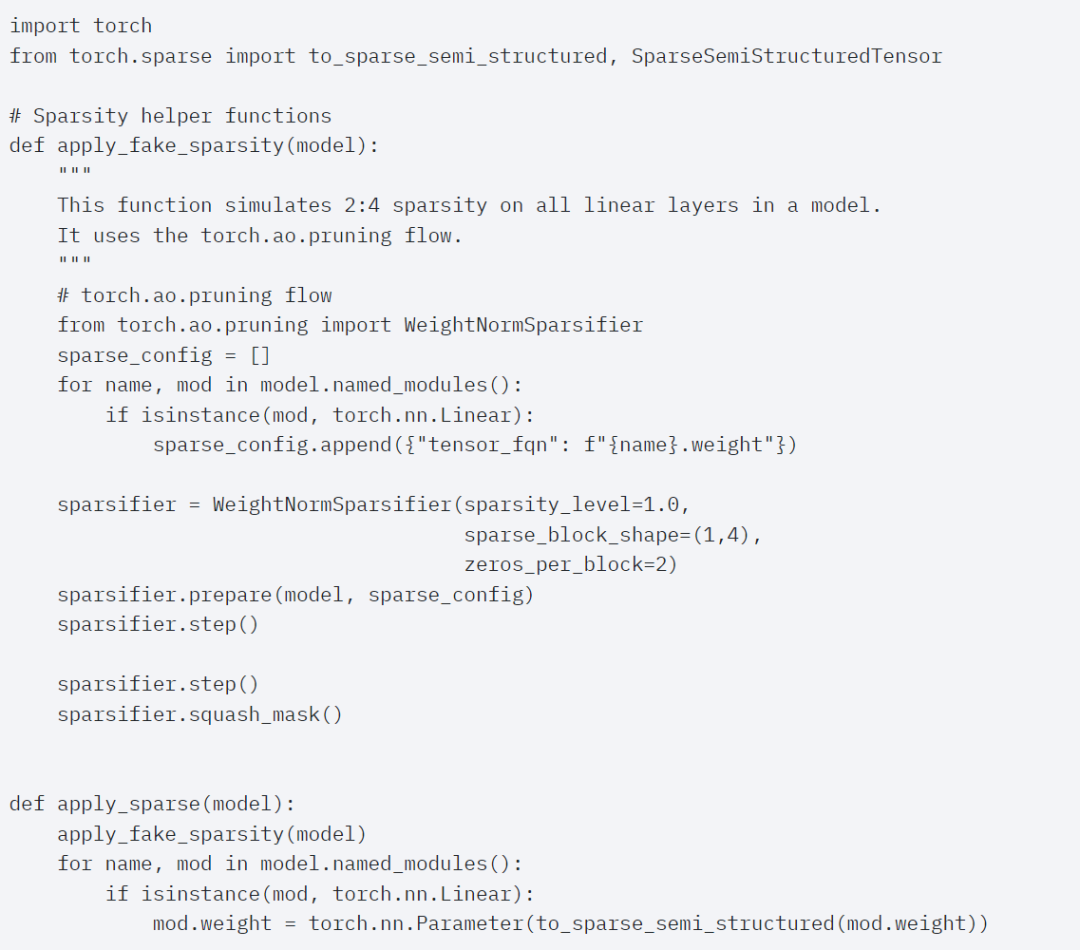
Um dieses spärliche Speicherformat und die damit verbundenen schnellen Kernel nutzen zu können, müssen als nächstes die Gewichte beschnitten werden. In diesem Artikel werden die kleinsten zwei Gewichte zum Bereinigen bei einer Sparse von 2:4 ausgewählt. Das Ändern der Gewichte vom standardmäßigen PyTorch-Layout („gestrided“) in dieses neue halbstrukturierte Sparse-Layout ist einfach. Um apply_sparse (Modell) zu implementieren, sind nur 32 Zeilen Python-Code erforderlich:
Bei einer Sparsity von 2:4 beobachtet dieses Papier die SAM-Spitzenleistung, wenn vit_b und die Batchgröße 32 sind:
Abschließend Um diesen Artikel in einem Satz zusammenzufassen: Dieser Artikel stellt die bisher schnellste Segment Anything-Implementierung auf PyTorch vor. Mit einer Reihe offiziell veröffentlichter neuer Funktionen schreibt dieser Artikel das ursprüngliche SAM in reinem PyTorch neu, ohne an Genauigkeit zu verlieren. Interessierte Leser können sich für weitere Informationen den Originalblog ansehen. Referenzlink: https://pytorch.org/blog/accelerating-generative-ai/Das obige ist der detaillierte Inhalt vonDas PyTorch-Team hat das „Split Everything'-Modell neu geschrieben, das achtmal schneller ist als die ursprüngliche Implementierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!






 Nach der Anwendung dieser Änderungen wurde in diesem Artikel festgestellt, dass zwischen einzelnen Kernel-Aufrufen eine erhebliche Zeitlücke besteht, insbesondere bei kleinen Chargen (hier 1). Um ein tieferes Verständnis dieses Phänomens zu erlangen, beginnt dieser Artikel mit einer Leistungsanalyse der SAM-Inferenz mit einer Stapelgröße von 8:
Nach der Anwendung dieser Änderungen wurde in diesem Artikel festgestellt, dass zwischen einzelnen Kernel-Aufrufen eine erhebliche Zeitlücke besteht, insbesondere bei kleinen Chargen (hier 1). Um ein tieferes Verständnis dieses Phänomens zu erlangen, beginnt dieser Artikel mit einer Leistungsanalyse der SAM-Inferenz mit einer Stapelgröße von 8: