
Heim >Technologie-Peripheriegeräte >KI >Beispiel für einen Link-Vorhersagecode mit Pytorch Geometric
Beispiel für einen Link-Vorhersagecode mit Pytorch Geometric

- 王林nach vorne
- 2023-10-20 19:33:081170Durchsuche
PyTorch Geometric (PyG) ist das Hauptwerkzeug zum Erstellen von graphischen neuronalen Netzwerkmodellen und zum Experimentieren mit verschiedenen Graphenfaltungen. In diesem Artikel werden wir es durch Linkvorhersage vorstellen.

Link-Vorhersage beantwortet die Frage: Welche zwei Knoten sollen miteinander verknüpft werden? Wir bereiten die Daten für die Modellierung vor, indem wir einen „Transformationssplit“ durchführen. Bereiten Sie einen speziellen Grafikdatenlader für die Stapelverarbeitung vor. Erstellen Sie ein Modell in Torch Geometric, trainieren Sie es mit PyTorch Lightning und überprüfen Sie die Leistung des Modells. Vorbereitung der Bibliothek Es vereinfacht den Trainingsablauf.
Sklearn Metrics und Torchmetrics werden verwendet, um die Leistung des Modells zu überprüfen.
- PyTorch Geometric weist einige spezifische Abhängigkeiten auf. Wenn Sie Probleme bei der Installation haben, lesen Sie bitte die offizielle Dokumentation.
- Datenvorbereitung
- Wir werden den Cora ML-Zitierdatensatz verwenden. Auf den Datensatz kann über Torch Geometric zugegriffen werden.
data = tg.datasets.CitationFull(root="data", name="Cora_ML")
data[0] > Data(x=[2995, 2879], edge_index=[2, 16316], y=[2995])
link_splitter = tg.transforms.RandomLinkSplit(num_val=0.2, num_test=0.1, add_negative_train_samples=False,disjoint_train_ratio=0.8)
disjoint_train_ratio passt an, wie viele Kanten als Trainingsinformationen in der „Supervision“-Phase verwendet werden. Die verbleibenden Kanten werden für die Nachrichtenübermittlung (die Informationsübertragungsphase im Netzwerk) verwendet.
Es gibt mindestens zwei Methoden zur Segmentierung von Kanten in graphischen neuronalen Netzen: induktive Segmentierung und leitende Segmentierung. Die Transformationsmethode geht davon aus, dass GNN Strukturmuster aus Graphstrukturen lernen muss. In einer induktiven Umgebung können Knoten-/Kantenbezeichnungen zum Lernen verwendet werden. Am Ende dieses Dokuments befinden sich zwei Artikel, die diese Konzepte im Detail diskutieren und eine zusätzliche Formalisierung bieten: ([1], [3]).train_g, val_g, test_g = link_splitter(data[0]) > Data(x=[2995, 2879], edge_index=[2, 2285], y=[2995], edge_label=[9137], edge_label_index=[2, 9137])Nach dieser Operation haben wir einige neue Attribute: edge_label: beschreibt, ob die Kante wahr/falsch ist. Das wollen wir vorhersagen.
edge_label_index ist eine 2 x NUM EDGES-Matrix, die zum Speichern von Knotenverknüpfungen verwendet wird.
Schauen wir uns die Verteilung der Stichproben anth.unique(train_g.edge_label, return_counts=True) > (tensor([1.]), tensor([9137])) th.unique(val_g.edge_label, return_counts=True) > (tensor([0., 1.]), tensor([3263, 3263])) th.unique(val_g.edge_label, return_counts=True) > (tensor([0., 1.]), tensor([3263, 3263]))Für die Trainingsdaten gibt es keine negativen Kanten (wir werden sie während des Trainings erstellen), für den Val/Test-Satz gibt es bereits einige „falsche“ Links in einer 50: Verhältnis 50. ModellJetzt können wir ein Modell mit GNN erstellen, indem wir eine Klasse GNN(nn.Module) erstellen:
def __init__(self, dim_in: int, conv_sizes: Tuple[int, ...], act_f: nn.Module = th.relu, dropout: float = 0.1,*args, **kwargs):super().__init__()self.dim_in = dim_inself.dim_out = conv_sizes[-1]self.dropout = dropoutself.act_f = act_flast_in = dim_inlayers = [] # Here we build subsequent graph convolutions.for conv_sz in conv_sizes:# Single graph convolution layerconv = tgnn.SAGEConv(in_channels=last_in, out_channels=conv_sz, *args, **kwargs)last_in = conv_szlayers.append(conv)self.layers = nn.ModuleList(layers) def forward(self, x: th.Tensor, edge_index: th.Tensor) -> th.Tensor:h = x# For every graph convolution in the network...for conv in self.layers:# ... perform node embedding via message passingh = conv(h, edge_index)h = self.act_f(h)if self.dropout:h = nn.functional.dropout(h, p=self.dropout, training=self.training)return hDer bemerkenswerte Teil dieses Modells ist eine Reihe von Graphfaltungen – in unserem Fall ist es SAGEConv. Die formale Definition der SAGE-Faltung lautet: å¾ç
v ist der aktuelle Knoten, die N(v) Nachbarn von Knoten v. Um mehr über diese Art der Faltung zu erfahren, schauen Sie sich das Originalpapier von GraphSAGE[1] an.
Lassen Sie uns prüfen, ob das Modell anhand der vorbereiteten Daten Vorhersagen treffen kann. Die Eingabe für das PyG-Modell ist hier die Matrix der Knotenmerkmale X und der Link, der den Kantenindex definiert.
gnn = GNN(train_g.x.size()[1], conv_sizes=[512, 256, 128]) with th.no_grad():out = gnn(train_g.x, train_g.edge_index) out > tensor([[0.0000, 0.0000, 0.0051, ..., 0.0997, 0.0000, 0.0000],[0.0107, 0.0000, 0.0576, ..., 0.0651, 0.0000, 0.0000],[0.0000, 0.0000, 0.0102, ..., 0.0973, 0.0000, 0.0000],...,[0.0000, 0.0000, 0.0549, ..., 0.0671, 0.0000, 0.0000],[0.0000, 0.0000, 0.0166, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.0034, ..., 0.1111, 0.0000, 0.0000]])
Die Ausgabe unseres Modells ist eine Knoteneinbettungsmatrix mit den Abmessungen: N Knoten x Einbettungsgröße. 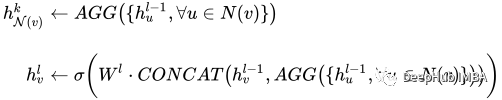 PyTorch Lightning
PyTorch Lightning
def __init__(self,dim_in: int,conv_sizes: Tuple[int, ...], act_f: nn.Module = th.relu, dropout: float = 0.1,lr: float = 0.01,*args, **kwargs):super().__init__() # Our inner GNN modelself.gnn = GNN(dim_in, conv_sizes=conv_sizes, act_f=act_f, dropout=dropout) # Final prediction model on links.self.lin_pred = nn.Linear(self.gnn.dim_out, 1)self.lr = lr def forward(self, x: th.Tensor, edge_index: th.Tensor) -> th.Tensor:# Step 1: make node embeddings using GNN.h = self.gnn(x, edge_index) # Take source nodes embeddings- sendersh_src = h[edge_index[0, :]]# Take target node embeddings - receiversh_dst = h[edge_index[1, :]] # Calculate the product between themsrc_dst_mult = h_src * h_dst# Apply non-linearityout = self.lin_pred(src_dst_mult)return out def _step(self, batch: th.Tensor, phase: str='train') -> th.Tensor:yhat_edge = self(batch.x, batch.edge_label_index).squeeze()y = batch.edge_labelloss = nn.functional.binary_cross_entropy_with_logits(input=yhat_edge, target=y)f1 = tm.functional.f1_score(preds=yhat_edge, target=y, task='binary')prec = tm.functional.precision(preds=yhat_edge, target=y, task='binary')recall = tm.functional.recall(preds=yhat_edge, target=y, task='binary') # Watch for logging here - we need to provide batch_size, as (at the time of this implementation)# PL cannot understand the batch size.self.log(f"{phase}_f1", f1, batch_size=batch.edge_label_index.shape[1])self.log(f"{phase}_loss", loss, batch_size=batch.edge_label_index.shape[1])self.log(f"{phase}_precision", prec, batch_size=batch.edge_label_index.shape[1])self.log(f"{phase}_recall", recall, batch_size=batch.edge_label_index.shape[1])return loss def training_step(self, batch, batch_idx):return self._step(batch) def validation_step(self, batch, batch_idx):return self._step(batch, "val") def test_step(self, batch, batch_idx):return self._step(batch, "test") def predict_step(self, batch):x, edge_index = batchreturn self(x, edge_index) def configure_optimizers(self):return th.optim.Adam(self.parameters(), lr=self.lr)Die Rolle von PyTorch Lightning besteht darin, uns bei der Vereinfachung der Trainingsschritte zu helfen. Wir müssen nur den folgenden Befehl verwenden, um zu testen, ob das Modell verfügbar ist Training
Für den Trainingsschritt benötigt der Datenlader eine spezielle Verarbeitung.
Grafikdaten erfordern eine spezielle Verarbeitung – insbesondere die Linkvorhersage. PyG verfügt über einige spezielle Datenladeklassen, die für die korrekte Generierung von Stapeln verantwortlich sind. Wir verwenden: tg.loader.LinkNeighborLoader, der die folgende Eingabe akzeptiert:
Daten, die in großen Mengen geladen werden sollen (Bild). num_neighbors Maximale Anzahl von Nachbarn, die pro Knoten während eines „Hops“ geladen werden sollen. Eine Liste mit der Anzahl der Nachbarn 1 - 2 - 3 -…-K. Besonders nützlich für sehr große Grafiken.
edge_label_index, dessen Attribut bereits Wahr/Falsch-Links anzeigt.
neg_sampling_ratio – das Verhältnis von negativen Proben zu echten Proben.
model = LinkPredModel(val_g.x.size()[1], conv_sizes=[512, 256, 128]) with th.no_grad():out = model.predict_step((val_g.x, val_g.edge_label_index))
Das Folgende ist das Trainingsmodell
train_loader = tg.loader.LinkNeighborLoader(train_g,num_neighbors=[-1, 10, 5],batch_size=128,edge_label_index=train_g.edge_label_index, # "on the fly" negative sampling creation for batchneg_sampling_ratio=0.5 ) val_loader = tg.loader.LinkNeighborLoader(val_g,num_neighbors=[-1, 10, 5],batch_size=128,edge_label_index=val_g.edge_label_index,edge_label=val_g.edge_label, # negative samples for val set are done already as ground-truthneg_sampling_ratio=0.0 ) test_loader = tg.loader.LinkNeighborLoader(test_g,num_neighbors=[-1, 10, 5],batch_size=128,edge_label_index=test_g.edge_label_index,edge_label=test_g.edge_label, # negative samples for test set are done already as ground-truthneg_sampling_ratio=0.0 )
Testen Sie die Datenüberprüfung, sehen Sie sich den Klassifizierungsbericht und die ROC-Kurve an.
model = LinkPredModel(val_g.x.size()[1], conv_sizes=[512, 256, 128]) trainer = pl.Trainer(max_epochs=20, log_every_n_steps=5) # Validate before training - we will see results of untrained model. trainer.validate(model, val_loader) # Train the model trainer.fit(model=model, train_dataloaders=train_loader, val_dataloaders=val_loader)
Die Ergebnisse sehen ziemlich gut aus:
precision recall f1-score support0.0 0.68 0.70 0.69 16311.0 0.69 0.66 0.68 1631accuracy 0.68 3262macro avg 0.68 0.68 0.68 3262
ROC曲线也不错
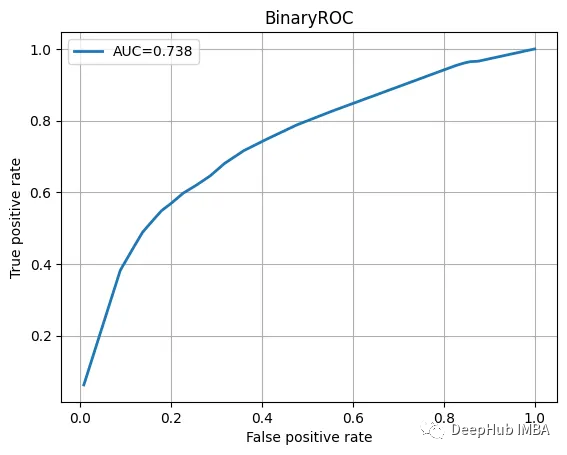
我们训练的模型并不特别复杂,也没有经过精心调整,但它完成了工作。当然这只是一个为了演示使用的小型数据集。
总结
图神经网络尽管看起来很复杂,但是PyTorch Geometric为我们提供了一个很好的解决方案。我们可以直接使用其中内置的模型实现,这方便了我们使用和简化了入门的门槛。
本文代码:https://github.com/maddataanalyst/blogposts_code/blob/main/graph_nns_series/pyg_pyl_perfect_match/pytorch-geometric-lightning-perfect-match.ipynb
Das obige ist der detaillierte Inhalt vonBeispiel für einen Link-Vorhersagecode mit Pytorch Geometric. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!