
Heim >Technologie-Peripheriegeräte >KI >iFLYTEK ICDAR 2023: Die Bild- und Texterkennung erreicht erneut größeren Ruhm und gewinnt vier Meisterschaften
iFLYTEK ICDAR 2023: Die Bild- und Texterkennung erreicht erneut größeren Ruhm und gewinnt vier Meisterschaften

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-11-08 08:17:28743Durchsuche
ICDAR 2023 (International Conference on Document Analysis and Recognition), als eine der wichtigsten internationalen Konferenzen im Bereich der Dokumentbildanalyse und -erkennung, hat kürzlich spannende Neuigkeiten erhalten:
iFlytek Research Institute of USTC and the National Institute of Speech und Sprachinformationsverarbeitung des USTC Das Engineering Research Center (im Folgenden als Forschungszentrum bezeichnet) gewann vier Meisterschaften in drei Wettbewerben: Erkennung mehrzeiliger Formeln, Lokalisierung und Extraktion von Dokumentinformationen sowie Extraktion strukturierter Textinformationen.
MLHMEOben: Der Schwerpunkt liegt auf „mehrzeiligem Schreiben“, einem weiteren Durchbruch in Sachen Komplexität.
MLHME (Multi-line Formula Recognition Competition) testet die Genauigkeit der Algorithmusausgabe, die der LaTex-Zeichenfolge entspricht, nachdem ein Bild eingegeben wurde, das Folgendes enthält Handschriftliche mathematische Formeln. Es ist erwähnenswert, dass dieser Wettbewerb im Vergleich zu früheren Wettbewerben zur Erkennung mathematischer Formeln zum ersten Mal in der Branche das „mehrzeilige Schreiben“ als Hauptherausforderung festgelegt hat, und zwar diesmal im Gegensatz zu den vorherigen Formeln zur Erkennung gescannter und Online-Handschriften erkennt fotografierte Handschriften. Hauptsächlich mehrzeilige Formeln.

Das Bild- und Texterkennungsteam des iFlytek Research Institute gewann die Meisterschaft mit einer Punktzahl von 67,9 % und übertraf die anderen teilnehmenden Teams im Hauptbewertungsindikator – Formelrückrufrate – bei weitem Entsprechend den Einsendeergebnissen in
Mehrzeilige Formeln sind komplexer als einzeilige Strukturen, und die Größe ändert sich, wenn das gleiche Zeichen mehrmals gleichzeitig in der Formel vorkommt Bei handschriftlich fotografierten Formula-Bildern aus realen Szenen treten sogar Probleme wie schlechte Qualität, Hintergrundinterferenzen, Textinterferenzen, Verschmierungen und Anmerkungsinterferenzen auf. Diese Faktoren machen das Spiel schwieriger. 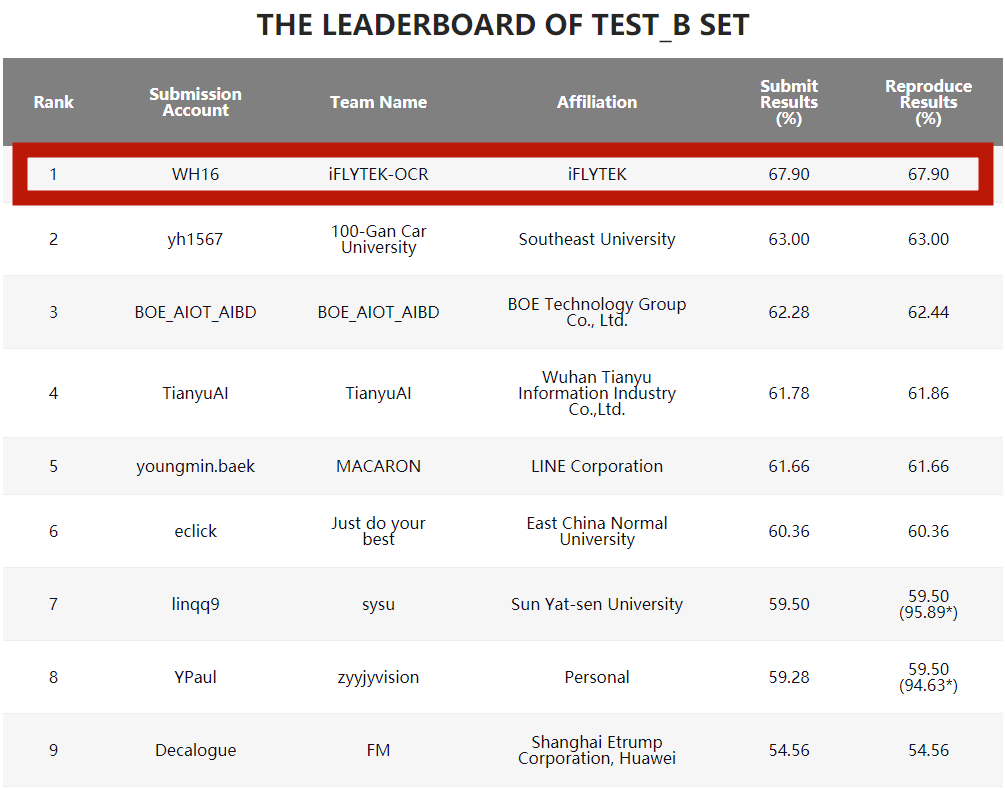
Die Formel hat eine komplexe Struktur und belegt mehrere Zeilen
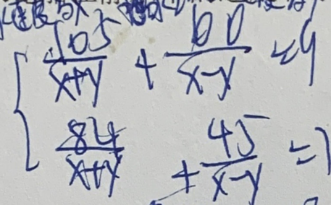
Die Bildqualität ist nicht hoch und die Korrektur stört
Als Reaktion auf das Problem, dass die Formel eine komplexe Struktur hat und mehrere Zeilen belegt, wird die Das Team verwendet Conv2former mit einem großen Faltungskern als Encoderstruktur, um das Sichtfeld des Modells zu erweitern und die strukturellen Eigenschaften mehrzeiliger Formeln besser zu erfassen. Es schlägt innovativ einen transformatorbasierten strukturierten Sequenzdecoder SSD vor, der die hierarchischen Beziehungen explizit modelliert innerhalb mehrzeiliger Formeln, was die Verallgemeinerung komplexer Strukturen erheblich verbessert und die strukturierte Semantik besser modelliert. 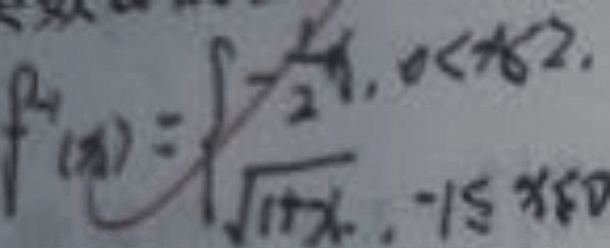
DocILE
Top: „Wählen Sie eines aus der Reihe“, der zweigleisige Wettbewerb zur Lokalisierung und Extraktion von Dokumentinformationen führte die Liste an
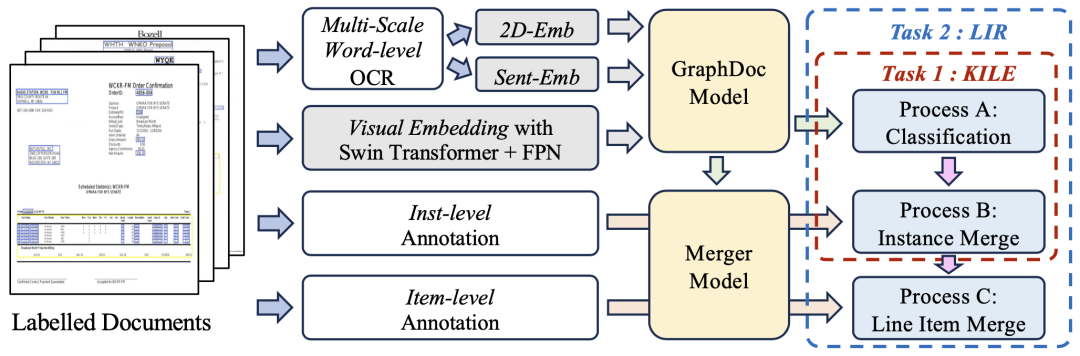
DocILE (Document Information Location and Extraction Competition) bewertet Methoden des maschinellen Lernens in halbstrukturierten Unternehmen Leistung beim Auffinden, Extrahieren und Identifizieren von Einzelposten wichtiger Informationen in Dokumenten. Das Spiel ist in zwei Streckenaufgaben unterteilt: KILE und LIR. Die KILE-Aufgabe muss den Speicherort der Schlüsselinformationen vordefinierter Kategorien im Dokument lokalisieren. Auf dieser Grundlage gruppiert die LIR-Aufgabe jede Schlüsselinformation weiter in verschiedene Einzelposten (Einzelposten), beispielsweise ein einzelnes Objekt (Menge, Preis). Zeile in der Tabelle)warte. iFlytek und das Forschungszentrum haben schließlich die Meisterschaft auf zwei Strecken gewonnen Anhand des vom Veranstaltungsbeauftragten angegebenen Aufgabensymbols sind die aus dem Dokument zu extrahierenden Arten von Informationen sehr komplex. Unter anderem muss die KILE-Aufgabe nicht nur Schlüsselinformationen vordefinierter Kategorien extrahieren, sondern auch den spezifischen Speicherort der Schlüsselinformationen in der LIR-Aufgabe ermitteln. Ein Zeilenelement kann mehrere Textzeilen in einer einzelnen Tabelle enthalten. Darüber hinaus enthält der Datensatz dieses Wettbewerbs viele Arten von Informationen sowie komplexe und unterschiedliche Dokumentformate, was die Herausforderung erheblich erhöht.
Das gemeinsame Team schlug zwei technologische Innovationslösungen auf Algorithmusebene vor:In der Vorschulungsphase haben wir einen Dokumentenfilter entwickelt, der auf OCR-Qualität basiert, indem wir 2,74 Millionen Seiten Dokumentbilder aus nicht kommentierten Dokumenten extrahiert haben, die vom Veranstalter bereitgestellt wurden. Anschließend verwenden wir ein vorab trainiertes Sprachmodell, um die semantische Darstellung jeder Textzeile im Dokument zu erhalten, und verwenden die Aufgabe zur Wiederherstellung der maskierten Satzdarstellung, die unter verschiedenen Top-K-Konfigurationen (Aufmerksamkeitsspanne des Dokuments im GraphDoc) vorab trainiert wurde Modell (ein Hyperparameter)
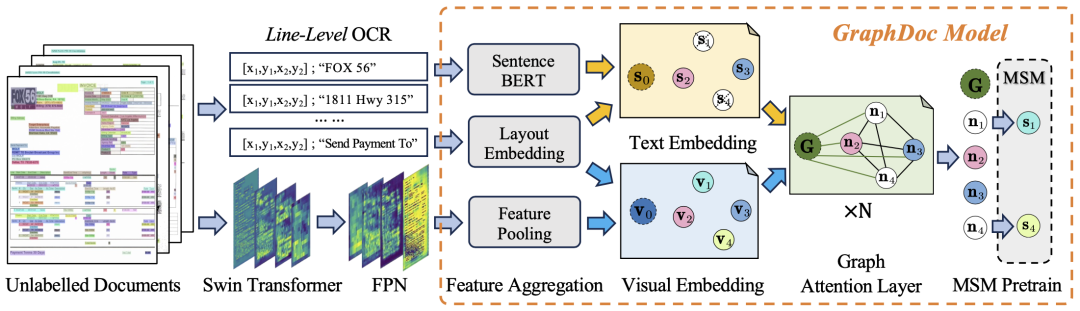
In der Feinabstimmungsphase des Datensatzes nutzte das Team den vorab trainierten GraphDoc, um die multimodale Darstellung des Textfelds zu extrahieren und Klassifizierungsoperationen durchzuführen. Auf der Grundlage der Klassifizierungsergebnisse werden multimodale Darstellungen an das Low-Level-Attention-Fusion-Modul zur Instanzaggregation gesendet. Basierend auf der Instanzaggregation wird das High-Level-Attention-Fusion-Modul verwendet, um die Aggregation von Werbebuchungsinstanzen zu realisieren. Die vorgeschlagene Aufmerksamkeitsfusion Die Module haben die gleiche Struktur, teilen jedoch keine Parameter miteinander. Sie können sowohl für KILE- als auch für LIR-Aufgaben mit guten Ergebnissen verwendet werden.
SVRDOben: Zuerst in der Zero-Sample-Ticket-Aufgabe zur strukturierten Informationsextraktion, einem großen Test des Pre-Training-Modells
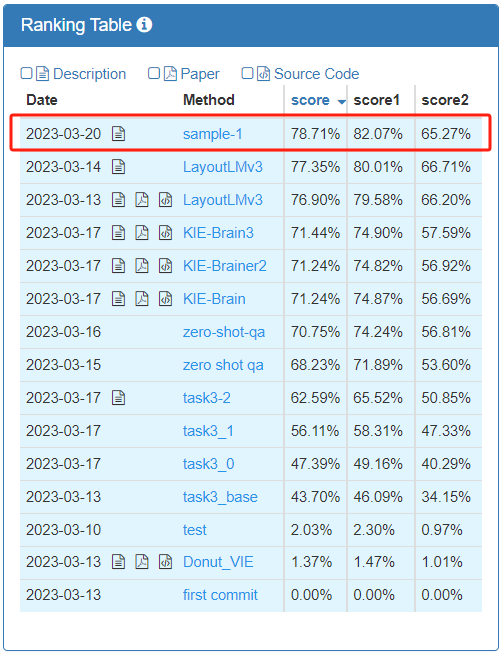
Der SVRD-Wettbewerb (Structured Text Information Extraction) ist in 4-Track-Untergruppen unterteilt. Aufgaben, iFlytek gewann den ersten Platz im äußerst schwierigen Teiltrack zur Extraktion strukturierter Informationen ohne Stichprobe (Aufgabe 3: E2E-Extraktion strukturierter Texte ohne Stichprobe) mit dem Forschungszentrum
Rangfolge
in den offiziell benannten verschiedenen Arten von Rechnungen, die extrahiert werden müssen Im Kontext von Schlüsselelementen erfordert der Track, dass die teilnehmenden Teams das Modell verwenden, um den entsprechenden Inhalt dieser Schlüsselelemente im Bild auszugeben. „Nullstichprobe“ bedeutet, dass es keine Überschneidung zwischen den Rechnungstypen gibt Der Trainingssatz und der Testsatz untersuchen die End-to-End-Vorhersage des Modells. Für die Genauigkeit wird der gewichtete Durchschnitt von Punktzahl1 und Punktzahl2 als endgültiger Bewertungsindex verwendet.
Für vorab trainierte Modelle stellen Nullproben höhere Anforderungen. Gleichzeitig werden im Wettbewerb verschiedene Rechnungsformate verwendet, und die Namen der Haltestellen, Abfahrtszeiten und andere Elemente in jedem Format sind unterschiedlich. Darüber hinaus weisen Rechnungsfotos Probleme wie Hintergrundstörungen, Reflexionen und Textüberlappungen auf, was die Identifizierung und Extraktion weiter erschwert. Rechnungen in verschiedenen Formaten werden durch gestreifte Hintergründe beeinträchtigt Das Team verwendete zunächst die Copy-Generate-Dual-Branch-Dekodierungsstrategie, um Merkmalsextraktionsmodelle durchzuführen. Wenn die Zuverlässigkeit des Front-End-OCR-Ergebnisses hoch ist, wird das OCR-Ergebnis direkt kopiert , wird ein neues Vorhersageergebnis generiert, um die durch das OCR-Modell verursachten Front-End-Erkennungsfehler zu verringern. Darüber hinaus extrahierte das Team auch Graphdoc-Merkmale auf Satzebene basierend auf den OCR-Ergebnissen als Eingabe in das Merkmalsextraktionsmodell Multimodale Merkmale von Bild, Text, Ort und Layout Im Vergleich zu Einzelmodalität weist die Klartexteingabe eine stärkere Merkmalsdarstellung auf.
Auf dieser Grundlage kombinierte das Team auch mehrere Elementextraktionsmodelle wie UniLM, LiLT, DocPrompt usw., um den endgültigen Elementextraktionseffekt weiter zu verbessern und so bessere Leistungsvorteile in verschiedenen Szenarien und Sprachen zu erzielen 
Anwendungen wurden in den Bereichen Bildung, Finanzen, medizinische Versorgung usw. implementiert, um großen Modellen dabei zu helfen, multimodale Fähigkeiten zu verbessern. Die Auswahl relevanter Ereignisse von ICDAR 2023 für die Herausforderung ergibt sich aus den realen Szenarioanforderungen von iFlytek im tatsächlichen Geschäft -bezogene Technologien Es ist auch in Bereiche wie Bildung, Finanzen, medizinische Versorgung, Justiz und intelligente Hardware vorgedrungen und hat zahlreiche Unternehmen und Produkte gestärkt.
Im Bildungsbereich wird häufig die technische Fähigkeit der handschriftlichen Formelerkennung genutzt, und Maschinen können eine genaue Identifizierung, Beurteilung und Korrektur ermöglichen. Beispielsweise haben das personalisierte Präzisionslernen und die KI-Diagnose in der KI-Lernmaschine von iFlytek, der von Lehrern im Unterricht verwendete „iFlytek Smart Window“ und die personalisierten Lernhandbücher der Schüler usw. großartige Ergebnisse erzielt  Vor nicht allzu langer Zeit wurde der Spark Scientific Research Assistant im Hauptforum des iFlytek Global 1024 Developer Festival veröffentlicht. Eine der drei Kernfunktionen des Papierlesens kann eine intelligente Interpretation von Papieren ermöglichen und verwandte Fragen schnell beantworten. Anschließend wird auf der Grundlage der hochpräzisen Formelerkennung die Wirkung organischer chemischer Strukturformeln, Grafiken, Symbole, Flussdiagramme, Tabellen und anderer strukturierter Szenenerkennung weiterentwickelt. Diese Funktion wird auch wissenschaftlichen Forschern helfen, ihre Effizienz zu verbessern
Vor nicht allzu langer Zeit wurde der Spark Scientific Research Assistant im Hauptforum des iFlytek Global 1024 Developer Festival veröffentlicht. Eine der drei Kernfunktionen des Papierlesens kann eine intelligente Interpretation von Papieren ermöglichen und verwandte Fragen schnell beantworten. Anschließend wird auf der Grundlage der hochpräzisen Formelerkennung die Wirkung organischer chemischer Strukturformeln, Grafiken, Symbole, Flussdiagramme, Tabellen und anderer strukturierter Szenenerkennung weiterentwickelt. Diese Funktion wird auch wissenschaftlichen Forschern helfen, ihre Effizienz zu verbessern
Technologie zur Positionierung und Extraktion von Dokumentinformationen wird im Finanzbereich häufig eingesetzt, z. B. zur Extraktion und Überprüfung von Vertragselementen, zur Extraktion von Bankrechnungselementen, zur Überprüfung von Marketinginhalten und zum Verbraucherschutz und in anderen Szenarien. Diese Technologien können Funktionen wie Datenanalyse, Informationsextraktion und Vergleichsprüfung von Dokumenten oder Dateien realisieren und dabei helfen, Geschäftsdaten schnell einzugeben, zu extrahieren und zu vergleichen, wodurch die Effizienz des Überprüfungsprozesses verbessert und die Kosten gesenkt werden Dieses 1024-Hauptereignis Der im Forum veröffentlichte persönliche KI-Gesundheitsassistent ist iFlytek Xiaoyi. Es kann nicht nur Checklisten und Testanordnungen scannen sowie Analysen und Vorschläge machen, sondern auch Pillendosen scannen, weitere Anfragen stellen und Vorschläge für Hilfsmedikamente machen. Für körperliche Untersuchungsberichte können Benutzer Fotos aufnehmen und hochladen, und iFlytek Xiaoyi kann wichtige Informationen identifizieren, abnormale Indikatoren umfassend interpretieren, proaktiv nachfragen und weitere Hilfe leisten. Diese Funktion basiert auf der Unterstützung der Technologie zur Positionierung und Extraktion von Dokumentinformationen.
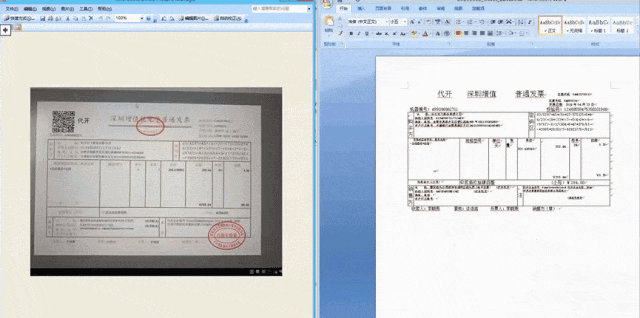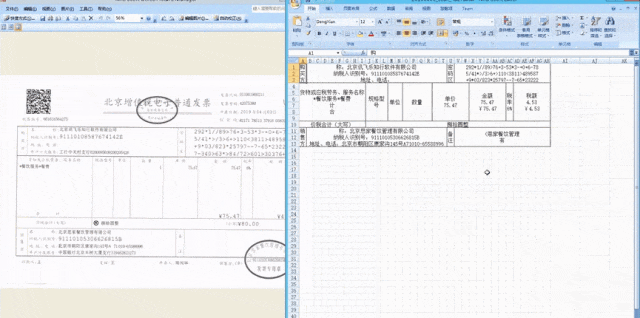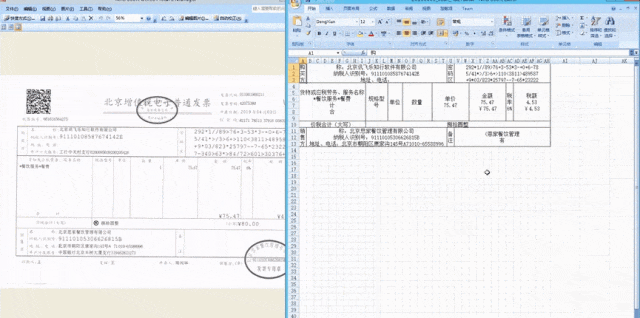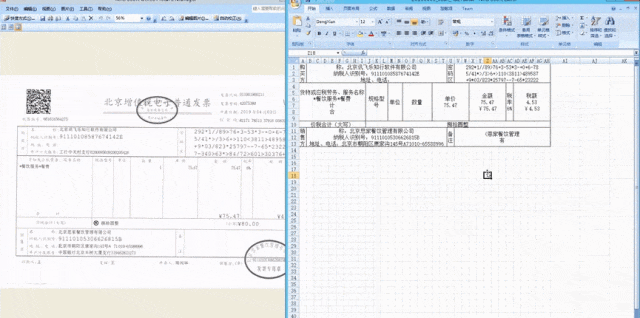
Die Bild- und Texterkennungstechnologie von iFlytek erzielt weiterhin Durchbrüche bei Algorithmen, von der Einzelworterkennung und Textzeilenerkennung bis hin zu komplexeren zweidimensionalen Strukturerkennungen und Kapitelerkennungen . Ebenenidentifikation. Eine leistungsfähigere Bild- und Texterkennungstechnologie kann die Wirkung und das Potenzial multimodaler großer Modelle in den Bereichen Bildbeschreibung, Bildfrage und -antwort, Bilderkennungserstellung, Dokumentverständnis und -verarbeitung usw. verbessern. Gleichzeitig kann auch die Bild- und Texterkennungstechnologie verbessert werden Die Kombination von Spracherkennung, Sprachsynthese, maschineller Übersetzung und anderen Technologien hat zu systematischen Innovationen geführt, und leistungsstarke Produkte haben nach der Anwendung leistungsfähigere Funktionen und offensichtlichere Wertvorteile gezeigt. Verwandte Projekte gewannen auch den ersten Preis des Wu Wenjun Artificial Intelligence Technology Progress Award . Auf der neuen Reise sind „mehr Blüten“ in mehreren ICDAR 2023-Wettbewerben nicht nur ein Feedback zu iFlyteks kontinuierlichen Fortschritten in der Tiefe der Bild- und Texterkennungs- und -verständnistechnologie, sondern auch eine Bestätigung seiner kontinuierlichen Erweiterung in der Breite.
Das obige ist der detaillierte Inhalt voniFLYTEK ICDAR 2023: Die Bild- und Texterkennung erreicht erneut größeren Ruhm und gewinnt vier Meisterschaften. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Ein langer Artikel mit 10.000 Wörtern: Dekonstruktion der Kette, Lösungen und unternehmerischen Möglichkeiten der KI-Sicherheitsbranche
- China Mobile übernahm die Führung bei der Gründung der Yuanverse Industry Alliance mit insgesamt 24 Mitgliedern, darunter iFlytek, Mango TV usw.
- [Trend Weekly] Globaler Entwicklungstrend der Künstliche-Intelligenz-Branche: OpenAI reichte beim US-Patentamt eine „GPT-5'-Markenanmeldung ein
- Die KI-Lernmaschine von iFLYTEK wurde neu aktualisiert und führt das große Modell V2.0 ein, um personalisierten Unterricht entsprechend der Eignung zu ermöglichen.
- Dieses Unternehmen in Changning hat auf der World VR Industry Conference neue Produkte vorgestellt!