
Heim >Technologie-Peripheriegeräte >KI >Microsoft führt die Modelltrainingsmethode „Learn from Mistakes' ein und behauptet, „den menschlichen Lernprozess nachzuahmen und die Denkfähigkeiten der KI zu verbessern'.
Microsoft führt die Modelltrainingsmethode „Learn from Mistakes' ein und behauptet, „den menschlichen Lernprozess nachzuahmen und die Denkfähigkeiten der KI zu verbessern'.

- 王林nach vorne
- 2023-11-07 17:13:04924Durchsuche
Microsoft Research Asia hat kürzlich in Zusammenarbeit mit der Peking-Universität, der Xi'an Jiaotong-Universität und anderen Universitäten eine Trainingsmethode für künstliche Intelligenz namens „Learning from Mistakes (LeMA)“ vorgeschlagen. Diese Methode behauptet, die Denkfähigkeit künstlicher Intelligenz verbessern zu können, indem sie den menschlichen Lernprozess nachahmt. Derzeit werden große Sprachmodelle wie OpenAI GPT-4 und Google aLM-2 für Aufgaben der Verarbeitung natürlicher Sprache (NLP) und des Denkens verwendet Ketten (Chain-of-Thinking (CoT)) Mathematische Denkaufgaben haben eine gute Leistung.
Allerdings müssen große Open-Source-Modelle wie LLaMA-2 und Baichuan-2 bei der Behandlung verwandter Probleme gestärkt werden. Um die Denkketten-Argumentationsfähigkeiten dieser großen Open-Source-Sprachmodelle zu verbessern, schlug das Forschungsteam die LeMA-Methode vor. Diese Methode imitiert hauptsächlich den menschlichen Lernprozess und verbessert die Denkfähigkeit des Modells durch „Lernen aus Fehlern“ .
.
▲ Bildquelle Verwandte Artikel
Diese Website stellte fest, dassdie Methode der Forscher darin besteht, ein Datenpaar mit „falschen Antworten“ und „korrigierten richtigen Antworten“ zu verwenden, um das relevante Modell zu verfeinern 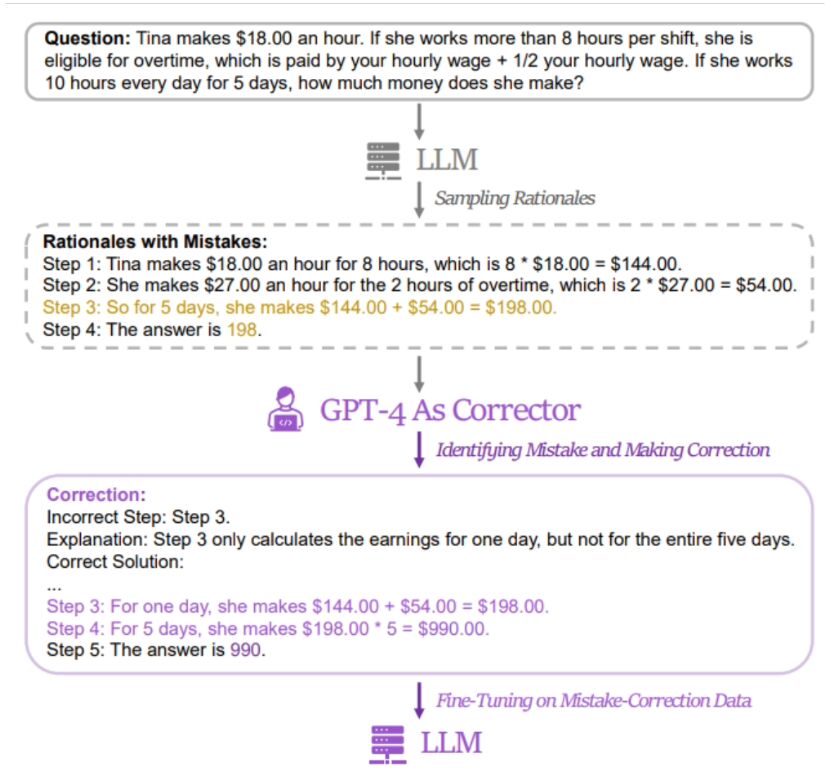 . Um relevante Daten zu erhalten, sammelten die Forscher die falschen Antworten und Argumentationsprozesse von fünf verschiedenen großen Sprachmodellen (einschließlich LLaMA- und GPT-Reihen) und verwendeten dann GPT-4 als „Revisor“, um korrigierte Antworten bereitzustellen.
. Um relevante Daten zu erhalten, sammelten die Forscher die falschen Antworten und Argumentationsprozesse von fünf verschiedenen großen Sprachmodellen (einschließlich LLaMA- und GPT-Reihen) und verwendeten dann GPT-4 als „Revisor“, um korrigierte Antworten bereitzustellen.
Es wird berichtet, dass die überarbeitete richtige Antwort drei Arten von Informationen enthält, nämlich die fehlerhaften Fragmente im ursprünglichen Argumentationsprozess, die Gründe für die Fehler im ursprünglichen Argumentationsprozess und wie die ursprüngliche Methode geändert werden kann, um die richtige Antwort zu erhalten.
Forscher verwendeten GSM8K und MATH, um die Wirkung der LeMa-Trainingsmethode an 5 großen Open-Source-Modellen zu testen. Die Ergebnisse zeigen, dass im verbesserten LLaMA-2-70B-Modell die Genauigkeitsraten von GSM8K 83,5 % bzw. 81,4 % betragen, während die Genauigkeitsraten von MATH 25,0 % bzw. 23,6 % betragen. Derzeit haben Forscher relevante Informationen darüber gesammelt LeMA Es ist öffentlich auf GitHub. Interessierte Freunde können
hier klicken, um zu springen.
Das obige ist der detaillierte Inhalt vonMicrosoft führt die Modelltrainingsmethode „Learn from Mistakes' ein und behauptet, „den menschlichen Lernprozess nachzuahmen und die Denkfähigkeiten der KI zu verbessern'.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Bitte bewahren Sie diese Zusammenfassung von GPT-4 auf
- ChatGPT hat plötzlich die APP gestartet! iPhone ist verfügbar und schneller, GPT-4-Nutzungslimit soll vermutlich aufgehoben werden
- Carrefour bringt Hopla-Einkaufsinformationsroboter mit dem GPT-4-Modell auf den Markt
- Je mehr Wörter das Dokument enthält, desto aufgeregter wird das Model sein! KOSMOS-2.5: Multimodales großes Sprachmodell zum Lesen von „textdichten Bildern'
- Der Roboter hat gelernt, Stifte zu drehen und Walnüsse zu tellern! GPT-4-Segen: Je komplexer die Aufgabe, desto besser die Leistung