
Heim >Technologie-Peripheriegeräte >KI >Ist die Ära der Objekterkennung und -kennzeichnung vorbei?
Ist die Ära der Objekterkennung und -kennzeichnung vorbei?

- 王林nach vorne
- 2023-11-07 14:17:011020Durchsuche
Im sich schnell entwickelnden Bereich des maschinellen Lernens ist ein Aspekt konstant geblieben: die mühsame und zeitaufwändige Aufgabe der Datenkennzeichnung. Ob für die Bildklassifizierung, Objekterkennung oder semantische Segmentierung: Von Menschen beschriftete Datensätze bilden seit langem die Grundlage des überwachten Lernens.

Dank eines innovativen Tools namens AutoDistill könnte sich dies jedoch bald ändern.
Der Github-Code-Link lautet wie folgt: https://github.com/autodistill/autodistill?source=post_page.
AutoDistill ist ein bahnbrechendes Open-Source-Projekt mit dem Ziel, den Prozess des überwachten Lernens zu revolutionieren. Das Tool nutzt große, langsamere Basismodelle, um kleinere, schnellere überwachte Modelle zu trainieren, sodass Benutzer ohne menschliches Eingreifen direkt von unbeschrifteten Bildern zu benutzerdefinierten Modellen wechseln können, die am Rand ausgeführt werden, um Rückschlüsse zu ziehen.
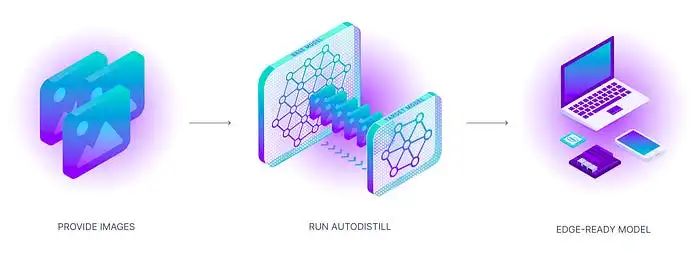
Wie funktioniert AutoDistill?
Der Prozess der Verwendung von AutoDistill ist so einfach und leistungsstark wie seine Funktionalität. Unbeschriftete Daten werden zunächst in das Basismodell eingespeist. Das Basismodell verwendet dann die Ontologie, um den Datensatz zu kommentieren und das Zielmodell zu trainieren. Die Ausgabe ist ein destilliertes Modell, das eine bestimmte Aufgabe ausführt.
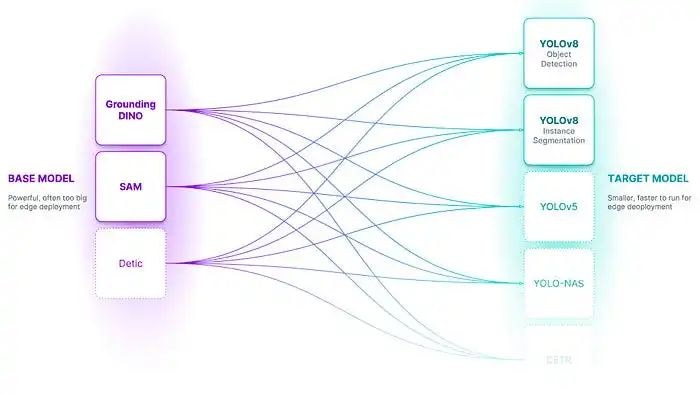
Erklären wir diese Komponenten:
- Basismodell: Ein Basismodell ist ein großes Basismodell wie Grounding DINO. Diese Modelle sind oft multimodal und können viele Aufgaben erfüllen, obwohl sie oft groß, langsam und teuer sind.
- Ontologie: Die Ontologie definiert, wie das Basismodell aufgefordert wird, beschreibt den Inhalt des Datensatzes und was das Zielmodell vorhersagen wird.
- Datensatz: Dies ist ein Satz automatisch gekennzeichneter Daten, die zum Trainieren des Zielmodells verwendet werden können. Der Datensatz wird vom Basismodell unter Verwendung unbeschrifteter Eingabedaten und Ontologien generiert.
- Zielmodell: Das Zielmodell ist ein überwachtes Modell, das einen Datensatz nutzt und ein destilliertes Modell zur Bereitstellung ausgibt. Beispiele für Zielmodelle könnten YOLO, DETR usw. sein.
- Destillationsmodell: Dies ist die endgültige Ausgabe des AutoDistill-Prozesses. Dabei handelt es sich um eine Reihe von Gewichten, die genau auf Ihre Aufgabe abgestimmt sind und zum Erhalten von Vorhersagen verwendet werden können.
Die Benutzerfreundlichkeit von AutoDistill ist wirklich beeindruckend: Übergeben Sie unbeschriftete Eingabedaten an ein Basismodell wie Grounding DINO, verwenden Sie dann eine Ontologie, um den Datensatz zu kennzeichnen, um das Zielmodell zu trainieren, und erhalten Sie am Ende eine beschleunigte Destillation und Feinabstimmung. Optimierung aufgabenspezifischer Modelle
Bitte klicken Sie auf den Link unten, um das Video anzusehen und den Prozess in Aktion zu sehen: https://youtu.be/gKTYMfwPo4M
Auswirkungen von AutoDistill
Computer Vision hatte schon immer ein großes Hindernis , nämlich Annotation erfordert viel manuelle Arbeit. AutoDistill hat einen wichtigen Schritt zur Lösung dieses Problems getan. Das dem Tool zugrunde liegende Modell ist in der Lage, autonom Datensätze für viele gängige Anwendungsfälle zu erstellen, und verfügt über ein großes Potenzial zur Erweiterung des Nutzens durch kreative Eingabeaufforderungen und Lernen in wenigen Schritten.
Diese Fortschritte sind zwar beeindruckend, sie sind es aber nicht. Das bedeutet nicht Die markierten Daten werden nicht mehr benötigt. Da sich die zugrunde liegenden Modelle weiter verbessern, werden sie zunehmend in der Lage sein, Menschen im Annotationsprozess zu ersetzen oder zu ergänzen. Derzeit ist jedoch in gewissem Umfang noch eine manuelle Annotation erforderlich.
Die Zukunft der Objekterkennung
Da Forscher die Genauigkeit und Effizienz von Objekterkennungsalgorithmen weiter verbessern, erwarten wir, dass sie in einem breiteren Spektrum realer Anwendungen eingesetzt werden. Beispielsweise ist die Objekterkennung in Echtzeit ein zentrales Forschungsgebiet mit zahlreichen Anwendungen in Bereichen wie autonomes Fahren, Überwachungssysteme und Sportanalysen.
Die Objekterkennung in Videos ist ein anspruchsvolles Forschungsgebiet, bei dem es um die Verfolgung von Objekten über mehrere Bilder und den Umgang mit Bewegungsunschärfe geht. Entwicklungen in diesen Bereichen werden neue Möglichkeiten für die Objekterkennung mit sich bringen und gleichzeitig das Potenzial von Tools wie AutoDistill demonstrieren.
Fazit
AutoDistill stellt eine spannende Entwicklung im Bereich des maschinellen Lernens dar. Durch die Verwendung von Basismodellen zum Trainieren überwachter Modelle ebnet dieses Tool den Weg für eine Zukunft, in der die mühsame Aufgabe der Datenannotation kein Engpass mehr bei der Entwicklung und Bereitstellung von Modellen für maschinelles Lernen darstellt.
Das obige ist der detaillierte Inhalt vonIst die Ära der Objekterkennung und -kennzeichnung vorbei?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- JavaScript-Maschinenlernen basierend auf TensorFlow.js
- Erweitern Sie Ihr Wissen! Maschinelles Lernen mit logischen Regeln
- Die neueste Deep-Architektur zur Zielerkennung hat die Hälfte der Parameter und ist dreimal schneller +
- So schreiben Sie ein auf künstlicher Intelligenz basierendes Zielerkennungssystem mit Java
- Problem der Änderung des Zielmaßstabs in der Zielerkennungstechnologie