
Heim >Technologie-Peripheriegeräte >KI >Was ist Regularisierung beim maschinellen Lernen?
Was ist Regularisierung beim maschinellen Lernen?

- 王林nach vorne
- 2023-11-06 11:25:011051Durchsuche
1. Einführung
Im Bereich des maschinellen Lernens können relevante Modelle während des Trainingsprozesses über- und unterpassen. Um dies zu verhindern, verwenden wir Regularisierungsoperationen beim maschinellen Lernen, um das Modell richtig an unseren Testsatz anzupassen. Im Allgemeinen helfen Regularisierungsoperationen jedem, das beste Modell zu erhalten, indem sie die Möglichkeit einer Über- und Unteranpassung verringern.
In diesem Artikel werden wir verstehen, was Regularisierung ist und welche Arten der Regularisierung es gibt. Darüber hinaus werden wir verwandte Konzepte wie Bias, Varianz, Unteranpassung und Überanpassung diskutieren.
Kein Unsinn mehr, fangen wir an!
2. Bias und Varianz sind zwei Aspekte, die verwendet werden, um die Lücke zwischen dem Modell, das wir gelernt haben, und dem realen Modell zu beschreiben. Was neu geschrieben werden muss, ist: die beiden Es ist wie folgt definiert:
Bias ist die Differenz zwischen dem Durchschnitt der Ausgabe aller mit allen möglichen Trainingsdatensätzen trainierten Modelle und dem Ausgabewert des realen Modells. Varianz ist die Differenz zwischen den Ausgabewerten des Modells, das auf verschiedenen Trainingsdatensätzen trainiert wurde.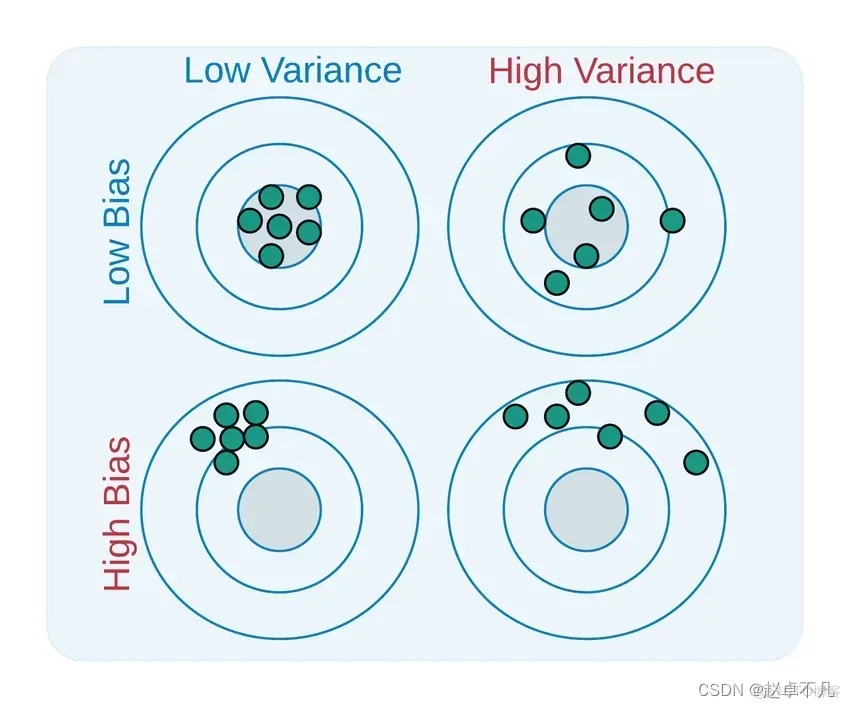 Varianz (Varianz) beim maschinellen Lernen bezieht sich auf Fehler, die durch die Empfindlichkeit des Modells gegenüber kleinen Änderungen in den Daten verursacht werden Satz. Da der Datensatz erhebliche Schwankungen aufweist, modelliert der Algorithmus Rauschen und Ausreißer im Trainingssatz. Diese Situation wird oft als Überanpassung bezeichnet. Wenn es anhand eines neuen Datensatzes ausgewertet wird, kann es keine genauen Vorhersagen liefern, da das Modell im Wesentlichen jeden Datenpunkt lernt Unteranpassung und Überanpassung.
Varianz (Varianz) beim maschinellen Lernen bezieht sich auf Fehler, die durch die Empfindlichkeit des Modells gegenüber kleinen Änderungen in den Daten verursacht werden Satz. Da der Datensatz erhebliche Schwankungen aufweist, modelliert der Algorithmus Rauschen und Ausreißer im Trainingssatz. Diese Situation wird oft als Überanpassung bezeichnet. Wenn es anhand eines neuen Datensatzes ausgewertet wird, kann es keine genauen Vorhersagen liefern, da das Modell im Wesentlichen jeden Datenpunkt lernt Unteranpassung und Überanpassung.
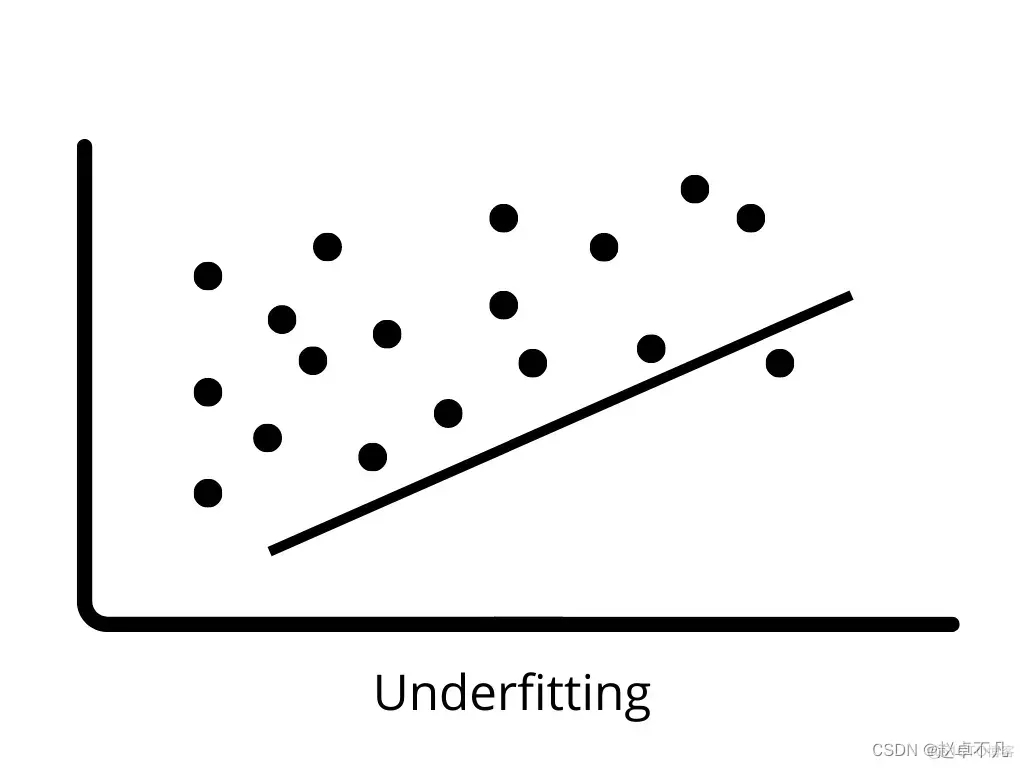
3. Unteranpassung
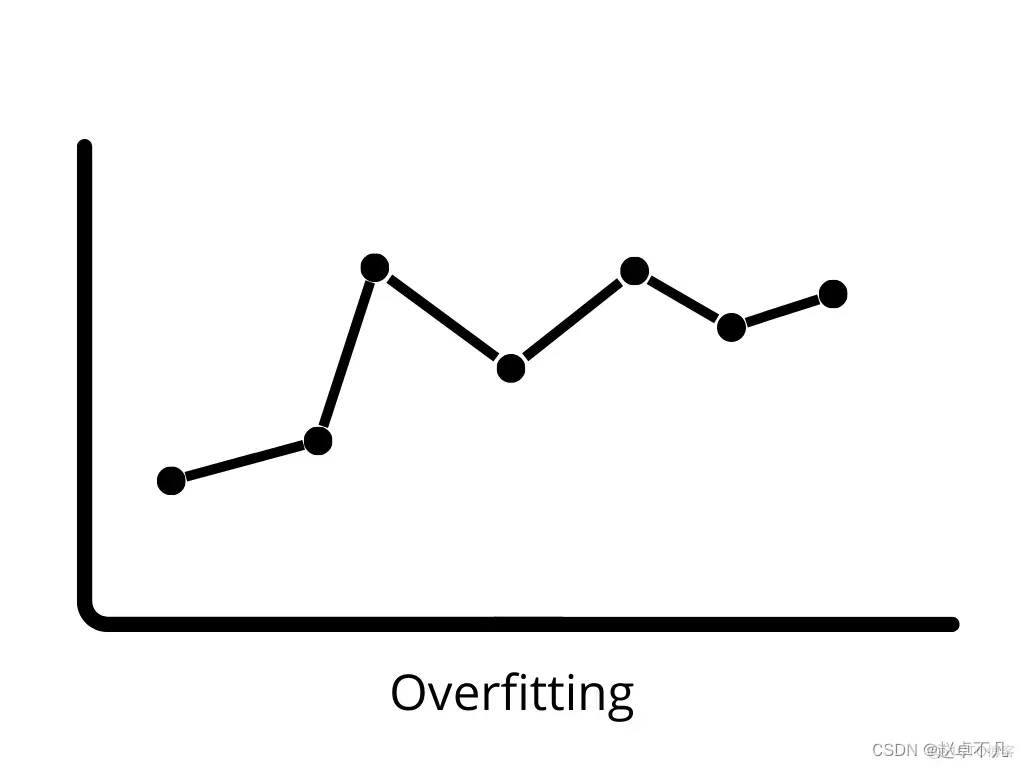
Unteranpassung tritt auf, wenn das Modell die Muster in den Trainingsdaten nicht richtig lernen und auf neue Daten verallgemeinern kann. Unterpassende Modelle schneiden bei Trainingsdaten schlecht ab und können zu falschen Vorhersagen führen. Wenn eine hohe Verzerrung und eine geringe Varianz auftreten, kann es zu einer Unteranpassung kommen Bei neuen Daten spricht man von Überanpassung. In diesem Fall wird das maschinelle Lernmodell an das Rauschen in den Trainingsdaten angepasst, was sich negativ auf die Leistung des Modells bei den Testdaten auswirkt. Ein geringer Bias und eine hohe Varianz können zu einer Überanpassung führen.
5. Regularisierungskonzept
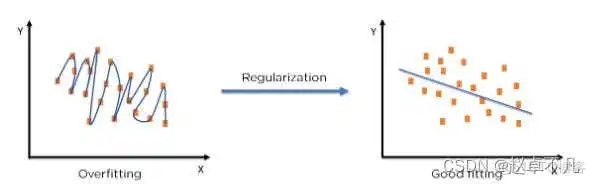
Der Begriff „Regularisierung“ beschreibt die Methode zur Kalibrierung eines maschinellen Lernmodells, um die angepasste Verlustfunktion zu reduzieren und eine Über- oder Unteranpassung zu vermeiden.
Durch den Einsatz der Regularisierungstechnologie können wir das Modell des maschinellen Lernens genauer an einen bestimmten Testsatz anpassen und so den Fehler im Testsatz effektiv reduzieren
6. L1-Regularisierung
Im Vergleich zur Collar-Regression besteht die Implementierung der L1-Regularisierung hauptsächlich darin, der Verlustfunktion einen Strafterm hinzuzufügen. Der Strafwert dieses Termes ist die Summe der absoluten Werte aller Koeffizienten wie folgt:
Im Lasso-Regressionsmodell wird dies erreicht, indem der Strafterm des Absolutwerts des Regressionskoeffizienten ähnlich wie bei der Ridge-Regression erhöht wird. Darüber hinaus bietet die L1-Regularisierung eine gute Leistung bei der Verbesserung der Genauigkeit linearer Regressionsmodelle. Da die L1-Regularisierung gleichzeitig alle Parameter gleichermaßen bestraft, kann sie gleichzeitig dazu führen, dass einige Gewichte zu Null werden, wodurch ein spärliches Modell entsteht, das bestimmte Merkmale entfernen kann (ein Gewicht von 0 entspricht einer Entfernung).
7. L2-Regularisierung
L2-Regularisierung wird auch durch Hinzufügen eines Strafterms zur Verlustfunktion erreicht, der der Summe der Quadrate aller Koeffizienten entspricht. Wie unten gezeigt:
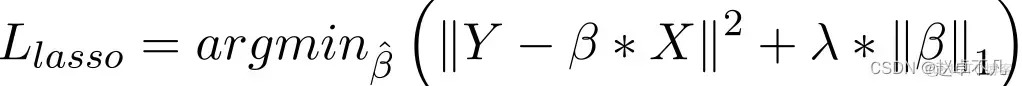
Im Allgemeinen wird dies als eine anzuwendende Methode angesehen, wenn die Daten Multikollinearität aufweisen (unabhängige Variablen sind stark korreliert). Obwohl Kleinste-Quadrate-Schätzungen (OLS) in der Multikollinearität unvoreingenommen sind, können ihre großen Varianzen dazu führen, dass beobachtete Werte erheblich von tatsächlichen Werten abweichen. L2 reduziert den Fehler von Regressionsschätzungen bis zu einem gewissen Grad. Normalerweise werden Schrumpfungsparameter verwendet, um Multikollinearitätsprobleme zu lösen. Die L2-Regularisierung reduziert den festen Anteil der Gewichte und glättet die Gewichte.
8. Zusammenfassung
Nach der obigen Analyse wird das relevante Regularisierungswissen in diesem Artikel wie folgt zusammengefasst:
L1-Regularisierung kann eine spärliche Gewichtsmatrix generieren, das heißt, ein spärliches Modell generieren , die zur Merkmalsauswahl verwendet werden kann;
L2-Regularisierung kann eine Überanpassung des Modells verhindern und die Generalisierungsfähigkeit des Modells verbessern
L1 (Lagrange)-Regularisierungshypothese Die Laplace-Verteilung kann die Sparsität des Modells sicherstellen, d des Modells, das heißt, der Wert des Parameters wird nicht zu groß oder zu klein sein
Wenn das Merkmal in der Praxis hochdimensional und dünn besetzt ist, sollte die L1-Regularisierung verwendet werden, wenn das Merkmal niedrigdimensional und dicht ist , L2-Regularisierung sollte verwendet werden
Das obige ist der detaillierte Inhalt vonWas ist Regularisierung beim maschinellen Lernen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- [Maschinelles Lernen] Datenvorverarbeitung: Konvertieren Sie kategoriale Daten in numerische Werte
- Was ist maschinelles Lernen? Welche Probleme kann maschinelles Lernen lösen?
- Grundlagen der künstlichen Intelligenz: Einführung in gängige Algorithmen im maschinellen Lernen
- Maschinelles Lernen für Blockchain: Die wichtigsten Fortschritte und was Sie wissen müssen
- Welche Anwendungen gibt es für maschinelles Lernen?