
Heim >Technologie-Peripheriegeräte >KI >Ein Artikel über Zeitreihenvorhersagen unter der Welle großräumiger Modelle
Ein Artikel über Zeitreihenvorhersagen unter der Welle großräumiger Modelle

- 王林nach vorne
- 2023-11-06 08:13:381241Durchsuche
Heute werde ich mit Ihnen über die Anwendung großer Modelle bei der Zeitreihenvorhersage sprechen. Mit der Entwicklung großer Modelle im Bereich NLP wird immer mehr versucht, große Modelle auf den Bereich der Zeitreihenvorhersage anzuwenden. In diesem Artikel werden die wichtigsten Methoden zur Anwendung großer Modelle auf die Zeitreihenvorhersage vorgestellt und einige aktuelle verwandte Arbeiten zusammengefasst, um jedem zu helfen, die Forschungsmethoden der Zeitreihenvorhersage im Zeitalter großer Modelle zu verstehen.
1. Methoden zur Vorhersage großer Modellzeitreihen
In den letzten drei Monaten sind viele Arbeiten zur Vorhersage großer Modellzeitreihen entstanden, die grundsätzlich in zwei Typen unterteilt werden können.
Umgeschriebener Inhalt: Ein Ansatz besteht darin, groß angelegte NLP-Modelle direkt für die Zeitreihenvorhersage zu verwenden. Bei dieser Methode werden große NLP-Modelle wie GPT und Llama für die Zeitreihenvorhersage verwendet. Der Schlüssel liegt darin, Zeitreihendaten in Daten umzuwandeln, die für die Eingabe großer Modelle geeignet sind. Bei dieser Art von Methode wird eine große Anzahl von Zeitreihendatensätzen verwendet, um gemeinsam ein großes Modell wie GPT oder Llama im Zeitreihenbereich zu trainieren und für nachgelagerte Zeitreihenaufgaben zu verwenden.
Für die beiden oben genannten Arten von Methoden finden Sie hier einige verwandte klassische Arbeiten zur Darstellung großer Modellzeitreihen.
2. Wenden Sie NLP-Großmodelle auf Zeitreihen an
Diese Methode ist eine der frühesten Arbeiten zur Vorhersage großer Modellzeitreihen.
Der gemeinsam von der New York University und der Carnegie Mellon University veröffentlichte Artikel „Large Language Models as Zero Samples“. Im „Time Series Predictor“ soll die digitale Darstellung der Zeitreihe tokenisiert werden, um sie in eine Eingabe umzuwandeln, die von großen Modellen wie GPT und LLaMa erkannt werden kann. Da verschiedene groß angelegte Modelle Zahlen unterschiedlich tokenisieren, ist bei der Verwendung verschiedener Modelle eine Personalisierung erforderlich. GPT teilt beispielsweise eine Zahlenfolge in verschiedene Teilsequenzen auf, was sich auf das Lernen des Modells auswirkt. Daher erzwingt dieser Artikel ein Leerzeichen zwischen Zahlen, um dem Eingabeformat von GPT Rechnung zu tragen. Bei kürzlich veröffentlichten großen Modellen wie LLaMa werden einzelne Zahlen grundsätzlich geteilt, sodass keine Leerzeichen hinzugefügt werden müssen. Um zu vermeiden, dass die Eingabesequenz aufgrund zu großer Zeitreihenwerte zu lang wird, werden im Artikel gleichzeitig einige Skalierungsvorgänge durchgeführt, um die Werte der ursprünglichen Zeitreihe auf einen vernünftigeren Bereich zu begrenzen
Bilder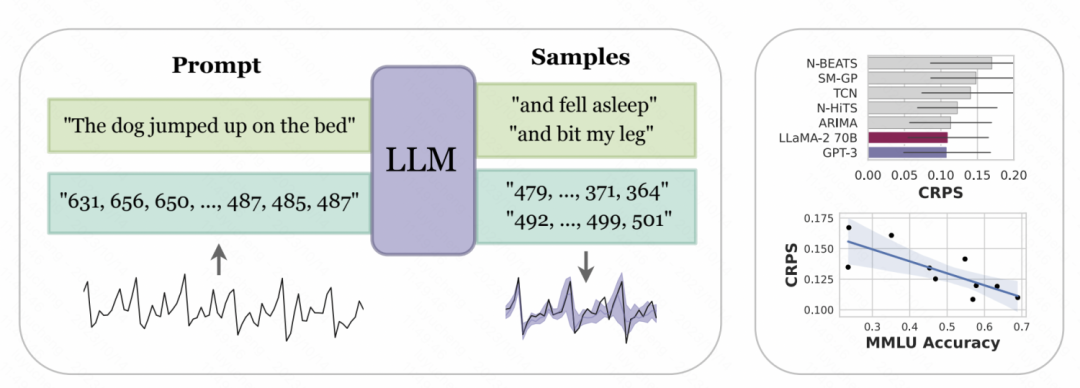 Zahlenzeichen nach der obigen Verarbeitung Die Zeichenfolge wird in das große Modell eingegeben, und das große Modell sagt die nächste Zahl autoregressiv voraus und wandelt schließlich die vorhergesagte Zahl in den entsprechenden Zeitreihenwert um. Die folgende Abbildung zeigt ein schematisches Diagramm. Die Verwendung der bedingten Wahrscheinlichkeit des Sprachmodells zur Modellierung von Zahlen dient dazu, die Wahrscheinlichkeit vorherzusagen, dass die nächste Ziffer basierend auf den vorherigen Zahlen sein wird. Es handelt sich um eine iterative hierarchische Softmax-Struktur, gekoppelt mit der Darstellung Die Fähigkeit des großen Modells kann sich an eine Vielzahl von Verteilungstypen anpassen, weshalb große Modelle auf diese Weise für die Zeitreihenvorhersage verwendet werden können. Gleichzeitig kann die vom Modell vorhergesagte Wahrscheinlichkeit der nächsten Zahl auch in eine Unsicherheitsvorhersage umgewandelt werden, um eine Unsicherheitsschätzung der Zeitreihe zu erreichen.
Zahlenzeichen nach der obigen Verarbeitung Die Zeichenfolge wird in das große Modell eingegeben, und das große Modell sagt die nächste Zahl autoregressiv voraus und wandelt schließlich die vorhergesagte Zahl in den entsprechenden Zeitreihenwert um. Die folgende Abbildung zeigt ein schematisches Diagramm. Die Verwendung der bedingten Wahrscheinlichkeit des Sprachmodells zur Modellierung von Zahlen dient dazu, die Wahrscheinlichkeit vorherzusagen, dass die nächste Ziffer basierend auf den vorherigen Zahlen sein wird. Es handelt sich um eine iterative hierarchische Softmax-Struktur, gekoppelt mit der Darstellung Die Fähigkeit des großen Modells kann sich an eine Vielzahl von Verteilungstypen anpassen, weshalb große Modelle auf diese Weise für die Zeitreihenvorhersage verwendet werden können. Gleichzeitig kann die vom Modell vorhergesagte Wahrscheinlichkeit der nächsten Zahl auch in eine Unsicherheitsvorhersage umgewandelt werden, um eine Unsicherheitsschätzung der Zeitreihe zu erreichen.
Bilder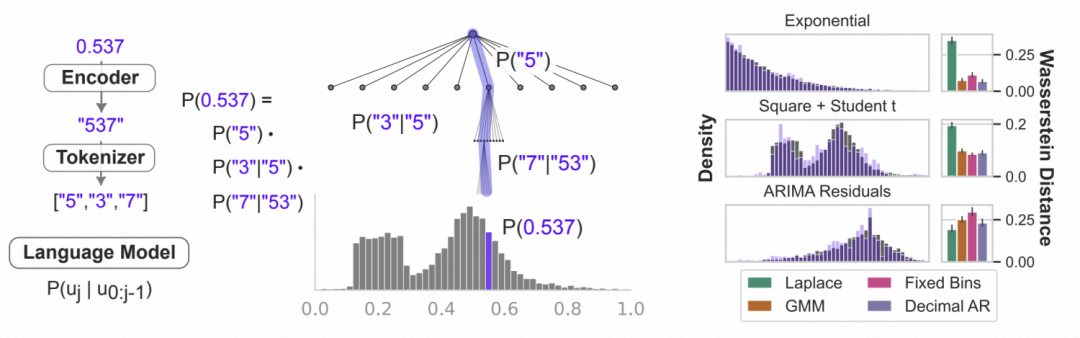 In einem anderen Artikel mit dem Titel „TIME-LLM: ZEITREIHENVORHERSAGE DURCH REPROGRAMMIERUNG GROßER SPRACHENMODELLE“ schlug der Autor eine Reprogrammierungsmethode vor, um Zeitreihen in Text umzuwandeln, um eine Ausrichtung zwischen den beiden Formen von Zeitreihen zu erreichen und Text
In einem anderen Artikel mit dem Titel „TIME-LLM: ZEITREIHENVORHERSAGE DURCH REPROGRAMMIERUNG GROßER SPRACHENMODELLE“ schlug der Autor eine Reprogrammierungsmethode vor, um Zeitreihen in Text umzuwandeln, um eine Ausrichtung zwischen den beiden Formen von Zeitreihen zu erreichen und Text
Die spezifische Implementierungsmethode besteht darin, die Zeitreihe zunächst in mehrere Patches zu unterteilen und jeder Patch über MLP einzubetten. Anschließend wird die Patch-Einbettung dem Wortvektor im Sprachmodell zugeordnet, um eine Zuordnung und modalübergreifende Ausrichtung von Zeitreihensegmenten und Text zu erreichen. Der Artikel schlägt die Idee eines Textprototyps vor, der mehrere Wörter einem Prototyp zuordnet, um die Semantik einer Sequenz von Patches über einen bestimmten Zeitraum darzustellen. Im folgenden Beispiel werden beispielsweise die Wörter „shot“ und „up“ roten Dreiecken zugeordnet, die Flecken kurzfristig ansteigender Teilsequenzen in der Zeitreihe entsprechen.
Bilder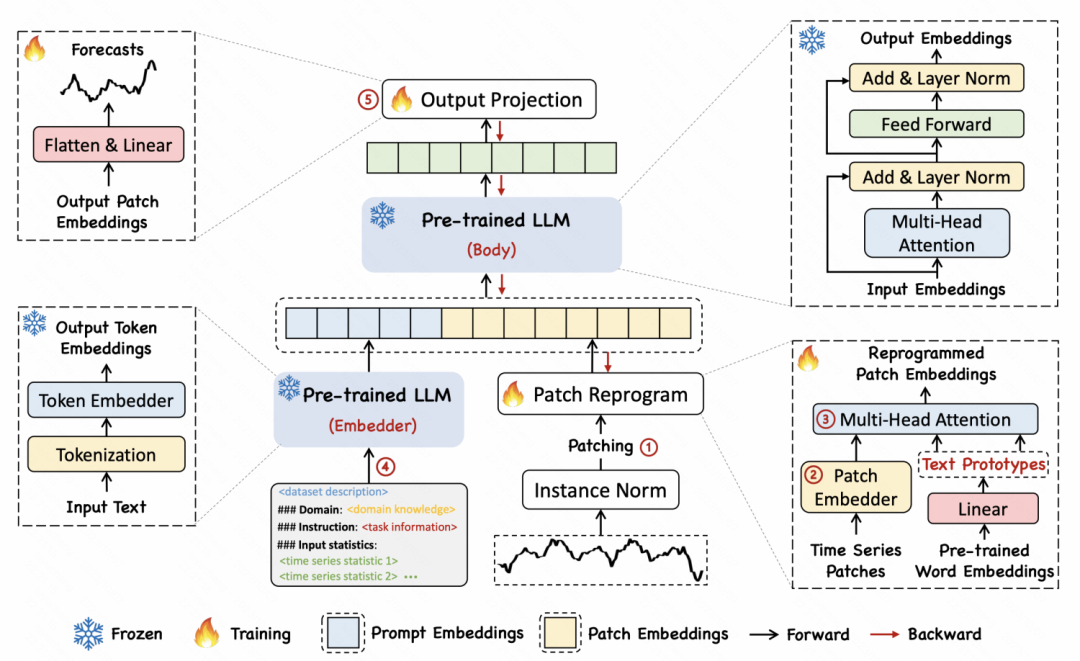 3. Großes Zeitreihenmodell
3. Großes Zeitreihenmodell
Eine weitere Forschungsrichtung besteht darin, direkt ein großes Modell für die Zeitreihenvorhersage zu erstellen, indem man sich auf die Konstruktionsmethode für große Modelle im Bereich der Verarbeitung natürlicher Sprache bezieht
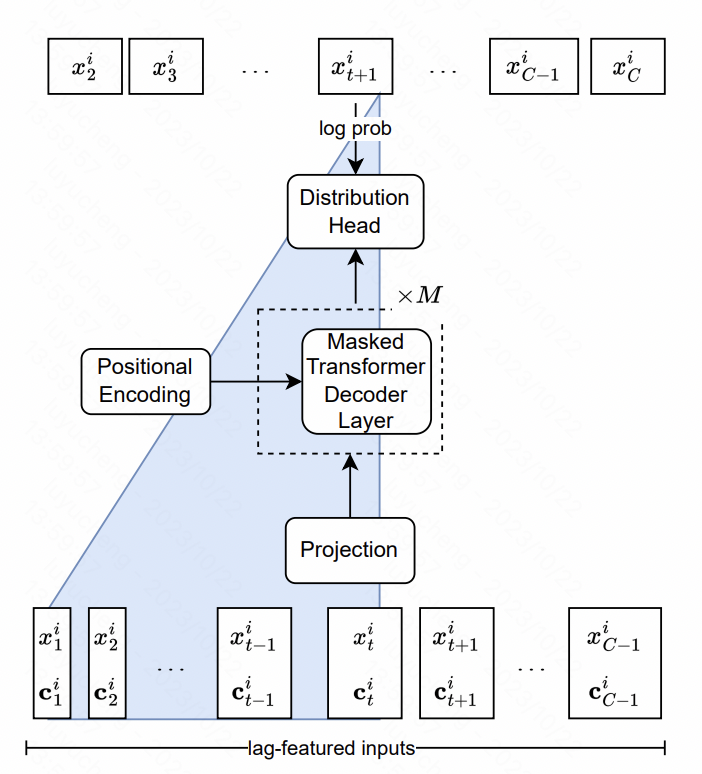
Lag-Llama : Auf dem Weg zu grundlegenden Modellen für die Zeitreihenvorhersage In diesem Artikel wird das Llama-Modell in Zeitreihen erstellt. Der Kern umfasst das Design auf Funktionsebene und Modellstrukturebene.
In Bezug auf Merkmale extrahiert der Artikel Verzögerungsmerkmale mit mehreren Maßstäben und mehreren Typen, bei denen es sich hauptsächlich um statistische Werte historischer Sequenzen in verschiedenen Zeitfenstern der ursprünglichen Zeitreihe handelt. Diese Sequenzen werden als zusätzliche Merkmale in das Modell eingegeben. In Bezug auf die Modellstruktur ist Transformer der Kern der LlaMA-Struktur in NLP, in dem die Normalisierungsmethode und der Positionscodierungsteil optimiert wurden. Die endgültige Ausgabeschicht verwendet mehrere Köpfe, um die Parameter der Wahrscheinlichkeitsverteilung anzupassen. In diesem Artikel werden beispielsweise die Student-t-Verteilung und die drei entsprechenden Parameter Freiheit, Mittelwert und Skala verwendet werden ausgegeben und schließlich jedes Mal das vorhergesagte Wahrscheinlichkeitsverteilungsergebnis des Punktes erhalten.
 Bilder
Bilder
Eine weitere ähnliche Arbeit ist TimeGPT-1, die ein GPT-Modell im Zeitreihenbereich erstellt. In Bezug auf das Datentraining verwendet TimeGPT eine große Menge an Zeitreihendaten und erreicht insgesamt 10 Milliarden Datenabtastpunkte, die verschiedene Arten von Domänendaten umfassen. Während des Trainings werden größere Batchgrößen und kleinere Lernraten verwendet, um die Trainingsrobustheit zu verbessern. Die Hauptstruktur des Modells ist das klassische GPT-Modell
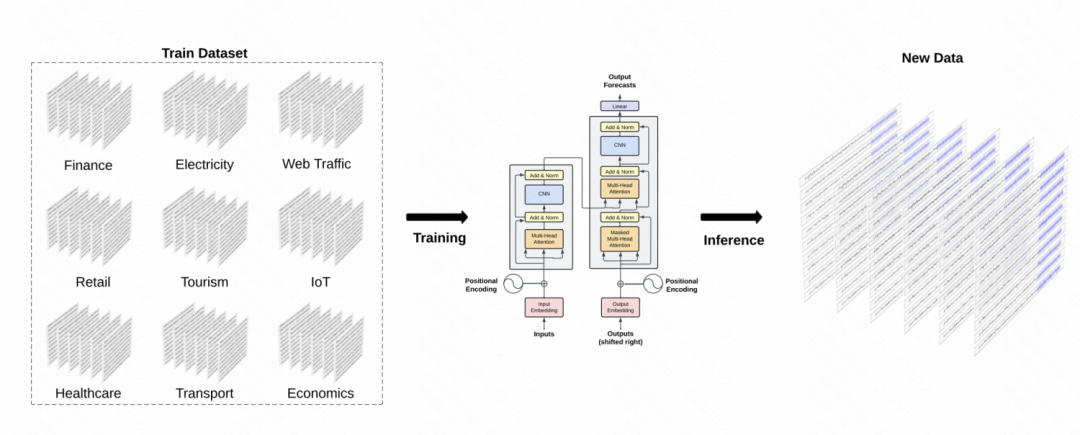 Bild
Bild
Aus den folgenden experimentellen Ergebnissen ist auch ersichtlich, dass dieses vorab trainierte große Zeitreihenmodell bei einigen Lernaufgaben ohne Stichprobe bessere Ergebnisse erzielt hat als das Basismodell. Deutliche Leistungsverbesserung.
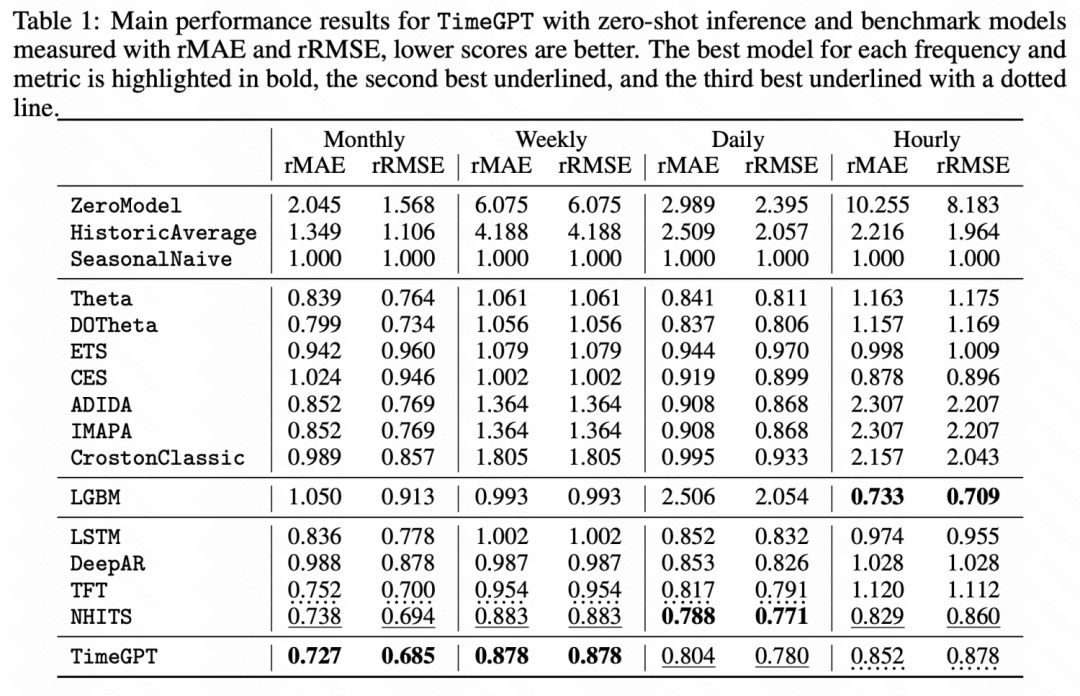 Bilder
Bilder
4. Zusammenfassung
In diesem Artikel werden die Forschungsideen der Zeitreihenvorhersage unter der Welle großer Modelle vorgestellt. Der Gesamtprozess umfasst die direkte Verwendung großer NLP-Modelle für die Zeitreihenvorhersage und das Training großer Modelle in der Zeit Serienfeld. Unabhängig davon, welche Methode verwendet wird, zeigt sie uns das Potenzial großer Modelle + Zeitreihen und ist eine Richtung, die einer eingehenden Untersuchung würdig ist.
Das obige ist der detaillierte Inhalt vonEin Artikel über Zeitreihenvorhersagen unter der Welle großräumiger Modelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist ein Haufen? Was ist der Methodenbereich? Einführung in den Heap- und Methodenbereich im JVM-Speichermodell
- Was sind im ISO/OSI-Referenzmodell die Hauptfunktionen der Netzwerkschicht?
- Welches Datenmodell verwenden derzeit die meisten Datenbankverwaltungssysteme?
- Was sind in der Datenbanktechnologie die vier wichtigsten Datenmodelle?
- Auswahl des richtigen Sprachmodells für NLP