
Heim >Technologie-Peripheriegeräte >KI >Erstellen Sie mit Ray effiziente Deep-Learning-Datenpipelines
Erstellen Sie mit Ray effiziente Deep-Learning-Datenpipelines

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-11-02 20:17:15874Durchsuche
Die für das Deep-Learning-Modelltraining erforderliche GPU ist leistungsstark, aber teuer. Um die GPU vollständig nutzen zu können, benötigen Entwickler einen effizienten Datenübertragungskanal, der Daten schnell an die GPU übertragen kann, wenn diese für die Berechnung des nächsten Trainingsschritts bereit ist. Die Verwendung von Ray kann die Effizienz des Datenübertragungskanals erheblich verbessern.
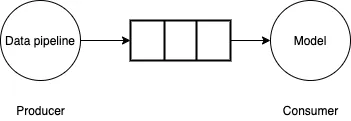
1 Die Struktur der Trainingsdatenpipeline. Schauen wir uns zunächst den Pseudocode des Modelltrainings an die nächste Mini-Charge. In Schritt 2 werden sie an die Funktion train_step übergeben, die sie auf die GPU kopiert, einen Vorwärts- und Rückwärtsdurchlauf durchführt, um den Verlust und den Gradienten zu berechnen, und die Gewichte des Optimierers aktualisiert.
Bitte erfahren Sie mehr über Schritt 1. Wenn der Datensatz zu groß ist, um in den Speicher zu passen, ruft Schritt 1 den nächsten Mini-Batch von der Festplatte oder dem Netzwerk ab. Darüber hinaus beinhaltet Schritt 1 auch eine gewisse Vorverarbeitung. Eingabedaten müssen in numerische Tensoren oder Tensorsammlungen umgewandelt werden, bevor sie dem Modell zugeführt werden. In einigen Fällen werden auch andere Transformationen am Tensor durchgeführt, bevor sie an das Modell übergeben werden, z. B. Normalisierung, Drehung um die Achse, zufälliges Mischen usw.
Wenn der Workflow streng nacheinander ausgeführt wird, ist Schritt 1 der Fall Zuerst ausführen und dann Schritt 2 ausführen, muss das Modell immer auf die Eingabe-, Ausgabe- und Vorverarbeitungsvorgänge des nächsten Datenstapels warten. Die GPU wird nicht effizient genutzt und bleibt beim Laden des nächsten Mini-Datenstapels im Leerlauf.
Um dieses Problem zu lösen, kann die Datenpipeline als Producer-Consumer-Problem betrachtet werden. Die Datenpipeline generiert kleine Datenmengen und schreibt sie in begrenzte Puffer. Das Modell/die GPU verbraucht kleine Datenmengen aus dem Puffer, führt Vorwärts-/Rückwärtsberechnungen durch und aktualisiert die Modellgewichtungen. Wenn die Datenpipeline kleine Datenmengen so schnell generieren kann, wie das Modell/die GPU sie verbraucht, ist der Trainingsprozess sehr effizient.
Bilder
 2. Tensorflow tf.data APITensorflow tf.data API bietet eine Vielzahl von Funktionen, die zum effizienten Erstellen von Datenpipelines verwendet werden können, indem Hintergrundthreads verwendet werden, um kleine Datenmengen abzurufen Das Modell muss nicht warten. Das Vorababrufen der Daten reicht nicht aus. Wenn das Generieren kleiner Datenmengen langsamer ist, als die GPU die Daten verbrauchen kann, müssen Sie Parallelisierung verwenden, um das Lesen und Umwandeln der Daten zu beschleunigen. Zu diesem Zweck bietet Tensorflow Interleave-Funktionalität, um mehrere Threads zum parallelen Lesen von Daten zu nutzen, und parallele Mapping-Funktionalität, um mehrere Threads zum Transformieren kleiner Datenmengen zu verwenden.
2. Tensorflow tf.data APITensorflow tf.data API bietet eine Vielzahl von Funktionen, die zum effizienten Erstellen von Datenpipelines verwendet werden können, indem Hintergrundthreads verwendet werden, um kleine Datenmengen abzurufen Das Modell muss nicht warten. Das Vorababrufen der Daten reicht nicht aus. Wenn das Generieren kleiner Datenmengen langsamer ist, als die GPU die Daten verbrauchen kann, müssen Sie Parallelisierung verwenden, um das Lesen und Umwandeln der Daten zu beschleunigen. Zu diesem Zweck bietet Tensorflow Interleave-Funktionalität, um mehrere Threads zum parallelen Lesen von Daten zu nutzen, und parallele Mapping-Funktionalität, um mehrere Threads zum Transformieren kleiner Datenmengen zu verwenden.
Da diese APIs auf Multithreading basieren, können sie durch den Python Global Interpreter Lock (GIL) eingeschränkt sein. Pythons GIL beschränkt den Bytecode auf jeweils nur einen Thread, der gleichzeitig ausgeführt wird. Wenn Sie reinen TensorFlow-Code in Ihrer Pipeline verwenden, leiden Sie im Allgemeinen nicht unter dieser Einschränkung, da die TensorFlow-Kernausführungs-Engine außerhalb des Geltungsbereichs der GIL arbeitet. Wenn die verwendete Bibliothek eines Drittanbieters jedoch die GIL-Beschränkungen nicht aufhebt oder Python zur Durchführung einer großen Anzahl von Berechnungen verwendet, ist es nicht möglich, sich auf Multithreading zur Parallelisierung der Pipeline zu verlassen.
3 Verwenden Sie eine Multiprozessparallelisierung der Daten Pipeline
Betrachten Sie die folgende Generatorfunktion. Die Funktion simuliert das Laden und Durchführen einiger Berechnungen, um Mini-Batches von Datenbeispielen und Etiketten zu generieren.
for step in range(num_steps):sample, target = next(dataset) # 步骤1train_step(sample, target) # 步骤2
Als nächstes verwenden Sie den Generator in einer Dummy-Trainingspipeline und messen die durchschnittliche Zeit, die zum Generieren von Mini-Datenmengen benötigt wird.
def data_generator():for _ in range(10):# 模拟获取# 从磁盘/网络time.sleep(0.5)# 模拟计算for _ in range(10000):passyield (np.random.random((4, 1000000, 3)).astype(np.float32), np.random.random((4, 1)).astype(np.float32))
Es wurde beobachtet, dass die durchschnittliche benötigte Zeit etwa 0,57 Sekunden betrug (gemessen auf einem Mac-Laptop mit Intel Core i7-Prozessor). Wenn es sich um eine echte Trainingsschleife handeln würde, wäre die GPU-Auslastung ziemlich gering, sie würde nur 0,1 Sekunden für die Berechnung aufwenden und dann 0,57 Sekunden im Leerlauf bleiben und auf den nächsten Datenstapel warten.
Um das Laden der Daten zu beschleunigen, können Sie einen Multiprozessgenerator verwenden.
generator_dataset = tf.data.Dataset.from_generator(data_generator,output_types=(tf.float64, tf.float64),output_shapes=((4, 1000000, 3), (4, 1))).prefetch(tf.data.experimental.AUTOTUNE)st = time.perf_counter()times = []for _ in generator_dataset:en = time.perf_counter()times.append(en - st)# 模拟训练步骤time.sleep(0.1)st = time.perf_counter()print(np.mean(times))
Wenn wir nun die Zeit messen, die wir mit dem Warten auf den nächsten Mini-Datenstapel verbringen, erhalten wir eine durchschnittliche Zeit von 0,08 Sekunden. Das ist fast eine 7-fache Beschleunigung, aber idealerweise sollte diese Zeit nahe bei 0 liegen.
Wenn Sie es analysieren, können Sie feststellen, dass viel Zeit für die Vorbereitung der Deserialisierung von Daten aufgewendet wird. In einem Multiprozessgenerator gibt der Produzentenprozess große NumPy-Arrays zurück, die vorbereitet und dann im Hauptprozess deserialisiert werden müssen. Wie lässt sich also die Effizienz beim Übergeben großer Arrays zwischen Prozessen verbessern?
4. Verwenden Sie Ray, um die Datenpipeline zu parallelisieren.
Hier kommt Ray ins Spiel. Ray ist ein Framework zum Ausführen verteilter Datenverarbeitung in Python. Es verfügt über einen Shared-Memory-Objektspeicher, um Objekte effizient zwischen verschiedenen Prozessen zu übertragen. Insbesondere können Numpy-Arrays im Objektspeicher ohne Serialisierung und Deserialisierung von Workern auf demselben Knoten gemeinsam genutzt werden. Ray macht es außerdem einfach, das Laden von Daten auf mehrere Maschinen zu skalieren und Apache Arrow zu verwenden, um große Arrays effizient zu serialisieren und zu deserialisieren.
Ray verfügt über eine Dienstprogrammfunktion from_iterators, mit der parallele Iteratoren erstellt werden können, und Entwickler können damit die Generatorfunktion data_generator umschließen.
from multiprocessing import Queue, cpu_count, Processdef mp_data_generator():def producer(q):for _ in range(10):# 模拟获取# 从磁盘/网络time.sleep(0.5)# 模拟计算for _ in range(10000000):passq.put((np.random.random((4, 1000000, 3)).astype(np.float32),np.random.random((4, 1)).astype(np.float32)))q.put("DONE")queue = Queue(cpu_count()*2)num_parallel_processes = cpu_count()producers = []for _ in range(num_parallel_processes):p = Process(target=producer, args=(queue,))p.start()producers.append(p)done_counts = 0while done_counts <p>Mit ray_generator wurde die Wartezeit auf den nächsten Mini-Datenstapel mit 0,02 Sekunden gemessen, was viermal schneller ist als mit der Multiprozessverarbeitung. </p>Das obige ist der detaillierte Inhalt vonErstellen Sie mit Ray effiziente Deep-Learning-Datenpipelines. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Ausführliche Erklärung, wie man den Array-Schlüsselnamen mit PHP array_keys() erhält
- Welche Beziehung besteht zwischen künstlicher Intelligenz, maschinellem Lernen und Deep Learning?
- 13 Wahrscheinlichkeitsverteilungen, die beim Deep Learning beherrscht werden müssen
- Wie können Deep-Learning-Modelle mithilfe kleiner Datensätze verbessert werden?
- Wie nutzt man die Go-Sprache für die Deep-Learning-Entwicklung?