
Heim >Technologie-Peripheriegeräte >KI >DeepMind: Wer hat gesagt, dass Faltungsnetzwerke ViT unterlegen sind?
DeepMind: Wer hat gesagt, dass Faltungsnetzwerke ViT unterlegen sind?

- PHPznach vorne
- 2023-11-02 09:13:01973Durchsuche
Dieses Papier bewertet vergrößerte NFNets und stellt die Idee in Frage, dass ConvNets bei großen Problemen schlechter abschneiden als ViTs.
Der frühe Erfolg von Deep Learning kann auf die Verwendung von Faltungs-Neuronalen Netzen (ConvNets) zurückgeführt werden. entwickeln. ConvNets dominieren seit fast einem Jahrzehnt die Benchmarks für Computer Vision. In den letzten Jahren wurden sie jedoch zunehmend durch ViTs (Vision Transformers) ersetzt.
Viele Menschen glauben, dass ConvNets bei kleinen oder mittelgroßen Datensätzen eine gute Leistung erbringen, bei größeren Datensätzen in Netzwerkgröße jedoch nicht mit ViTs konkurrieren können.
Mittlerweile ist die CV-Community von der Bewertung der Leistung zufällig initialisierter Netzwerke für bestimmte Datensätze (wie ImageNet) zur Bewertung der Leistung von Netzwerken übergegangen, die für große allgemeine Datensätze aus dem Netzwerk vorab trainiert wurden. Dies führt zu einer wichtigen Frage: Übertreffen Vision Transformers vorab trainierte ConvNets-Architekturen bei ähnlichen Rechenbudgets?
In diesem Artikel untersuchen Forscher von Google DeepMind dieses Problem. Durch das Vortraining mehrerer NFNet-Modelle auf dem JFT-4B-Datensatz unterschiedlicher Maßstäbe erzielten sie eine ähnliche Leistung wie ViTs auf ImageNet Die Forschung in diesem Artikel diskutiert das Rechenbudget vor dem Training zwischen 0,4.000 und 110.000 TPU-v4-Kernrechenstunden und nutzt die Erhöhung der Tiefe und Breite der NFNet-Modellfamilie, um eine Reihe von Netzwerkschulungen durchzuführen. Untersuchungen haben ergeben, dass es ein Log-Log-Skalierungsgesetz zwischen dem ausgehaltenen Verlust und dem Rechenbudget gibt. Dieser Artikel basiert beispielsweise auf JFT-4B, wobei die TPU-v4-Kernstunde (Kernstunde) bei 0,4 k liegt auf 110.000 erweitert und NFNet ist vorab trainiert. Nach der Feinabstimmung erreichte das größte Modell eine Genauigkeit von 90,4 % auf ImageNet Top-1 und konkurrierte mit dem vorab trainierten ViT-Modell bei gleichem Rechenbudget. Man kann sagen, dass dieses Papier durch die Bewertung vergrößerter NFNets, Die Ansicht wird in Frage gestellt, dass ConvNets bei großen Datensätzen schlechter abschneiden als ViTs. Darüber hinaus bleiben ConvNets bei ausreichenden Daten und Berechnungen wettbewerbsfähig und Modelldesign und Ressourcen sind wichtiger als Architektur.

Werfen wir einen Blick auf den spezifischen Inhalt des Papiers.
Vorab trainierte NFNets folgen dem Skalierungsgesetz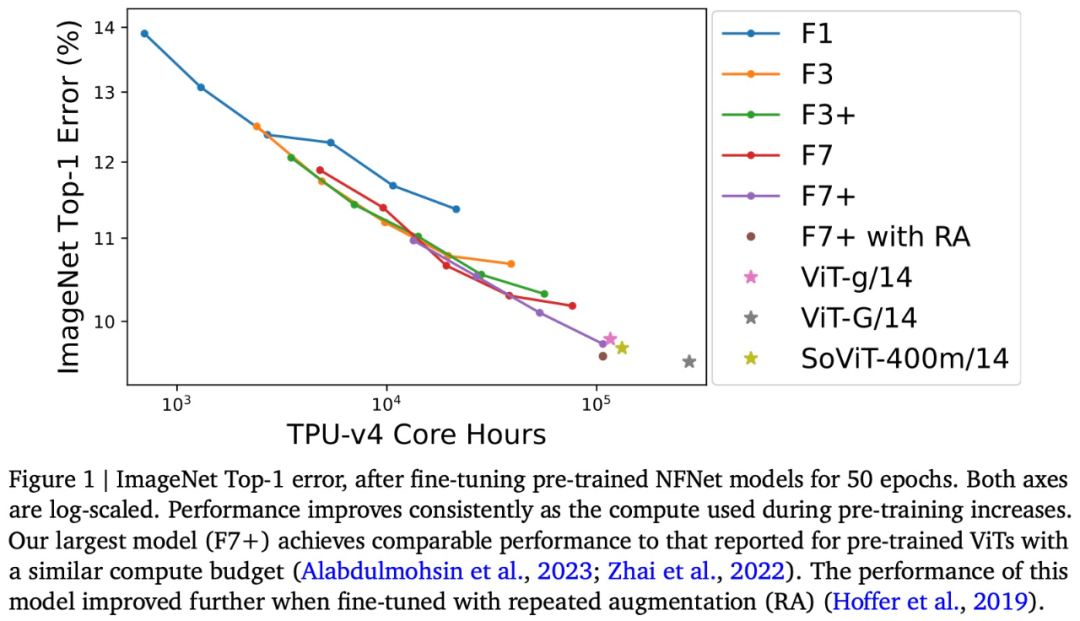

Was neu geschrieben werden muss, ist: Es ist zu beachten, dass einige der vorab trainierten Modelle in Abbildung 2 nicht die erwartete Leistung erbrachten. Das Forschungsteam geht davon aus, dass der Grund für diese Situation darin liegt, dass bei einem vorzeitigen/neuen Start des Trainingslaufs der Datenladeprozess nicht garantieren kann, dass jede Trainingsprobe in jeder Epoche einmal abgetastet werden kann. Wenn der Trainingslauf mehrmals neu gestartet wird, kann dies dazu führen, dass einige Trainingsbeispiele zu wenig abgetastet werden. optimierte das NFNet vor dem Training auf ImageNet und zeichnete die Beziehung zwischen der Berechnung vor dem Training und dem Top-1-Fehler auf, wie in Abbildung 1 oben dargestellt.
Die Genauigkeit von ImageNet Top-1 verbessert sich mit zunehmendem Budget weiter. Unter diesen ist NFNet-F7+ das teuerste vorab trainierte Modell, das für 8 Epochen vorab trainiert ist und in ImageNet Top-1 eine Genauigkeit von 90,3 % aufweist. Für das Vortraining und die Feinabstimmung sind etwa 110.000 TPU-v4-Kernstunden und 1,6.000 TPU-v4-Kernstunden erforderlich. Wenn darüber hinaus bei der Feinabstimmung zusätzliche repetitive Verbesserungstechniken eingeführt werden, kann eine Top-1-Genauigkeit von 90,4 % erreicht werden. NFNet profitiert stark vom groß angelegten Vortraining Obwohl es offensichtliche Unterschiede zwischen den beiden Modellarchitekturen NFNet und ViT gibt, ist die Leistung von vorab trainiertem NFNet und vorab trainiertem ViT vergleichbar. Beispielsweise erreichte ViT-g/14 nach dem Vortraining von JFT-3B mit 210.000 TPU-v3-Kernstunden eine Top-1-Genauigkeit von 90,2 % bei einer Leistung von mehr als 500.000 TPU-v3 auf JFT-3B nach Kernstunden Vor dem Training erreichte ViT-G/14 eine Top-1-Genauigkeit von 90,45 %
Dieser Artikel bewertet die Geschwindigkeit dieser Modelle vor dem Training auf TPU-v4 und schätzt, dass ViT-g/14 120.000 TPU-v4-Kerne erfordert Stunden für das Vortraining, während ViTG/14 280.000 TPU-v4-Kernstunden und SoViT-400m/14 130.000 TPU-v4-Kernstunden erfordert. In diesem Artikel werden diese Schätzungen verwendet, um die Vortrainingseffizienz von ViT und NFNet in Abbildung 1 zu vergleichen. In der Studie wurde festgestellt, dass NFNet für TPU-v4 optimiert ist und bei der Auswertung auf anderen Geräten eine schlechte Leistung erbringt.
Abschließend wird in diesem Artikel darauf hingewiesen, dass vorab trainierte Prüfpunkte den geringsten Validierungsverlust auf JFT-4B erzielen, nach der Feinabstimmung jedoch nicht immer die höchste Top-1-Genauigkeit auf ImageNet erreichen. In diesem Artikel wird insbesondere festgestellt, dass der Feinabstimmungsmechanismus bei einem festen Rechenbudget vor dem Training dazu tendiert, ein etwas größeres Modell und ein etwas kleineres Epochenbudget auszuwählen. Intuitiv haben größere Modelle eine größere Kapazität und können sich daher besser an neue Aufgaben anpassen. In manchen Fällen kann auch eine etwas größere Lernrate (während des Vortrainings) nach der Feinabstimmung zu einer besseren Leistung führen
Das obige ist der detaillierte Inhalt vonDeepMind: Wer hat gesagt, dass Faltungsnetzwerke ViT unterlegen sind?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist eine PS-Projektdatei?
- Bringen Sie Ihnen Schritt für Schritt bei, wie Sie ein Maven-Projekt in vscode erstellen (Kombination aus Grafiken und Text).
- Das neue Modell von DeepMind lernt wie ein Baby und lernt die Regeln der physischen Welt in 28 Stunden
- Google ist wirklich besorgt und unterstützt DeepMind! 70 Milliarden Parameter Sparrow Hard ChatGTP
- Wer hat die einflussreichste KI-Forschung veröffentlicht? Google liegt weit vorne, die Erfolgskonversionsrate von OpenAI übertrifft DeepMind