
Heim >Technologie-Peripheriegeräte >KI >Tiefgreifendes Q-Learning-Verstärkungslernen mit der Roboterarmsimulation von Panda-Gym
Tiefgreifendes Q-Learning-Verstärkungslernen mit der Roboterarmsimulation von Panda-Gym

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-10-31 17:57:04849Durchsuche
Reinforcement Learning (RL) ist eine maschinelle Lernmethode, die es Agenten ermöglicht, durch Versuch und Irrtum zu lernen, wie sie sich in ihrer Umgebung verhalten sollen. Agenten werden dafür belohnt oder bestraft, dass sie Maßnahmen ergreifen, die zu den gewünschten Ergebnissen führen. Mit der Zeit lernt der Agent, Maßnahmen zu ergreifen, die seine erwartete Belohnung maximieren. RL-Agenten werden in der Regel mithilfe von Markov-Entscheidungsprozessen (MDPs) trainiert, die einen mathematischen Rahmen für sequentielle Entscheidungsprobleme modellieren. MDP besteht aus vier Teilen:
Aktion: Eine Reihe von Aktionen, die ein Agent ausführen kann.
- Übergangsfunktion: Eine Funktion, die die Wahrscheinlichkeit des Übergangs in einen neuen Zustand angesichts des aktuellen Zustands und der aktuellen Aktion vorhersagt.
- Belohnungsfunktion: Eine Funktion, die dem Agenten für jede Conversion eine Belohnung zuweist.
- Das Ziel des Agenten ist es, eine Richtlinienfunktion zu erlernen, die Zustände Aktionen zuordnet. Maximieren Sie die erwartete Rendite des Agenten im Laufe der Zeit durch eine Richtlinienfunktion.
- Deep Q-Learning ist ein Reinforcement-Learning-Algorithmus, der tiefe neuronale Netze nutzt, um Richtlinienfunktionen zu erlernen. Tiefe neuronale Netze nehmen den aktuellen Zustand als Eingabe und geben einen Wertevektor aus, wobei jeder Wert eine mögliche Aktion darstellt. Der Agent führt dann die Aktion basierend auf dem höchsten Wert aus.
Deep Q-Learning ist ein wertbasierter Reinforcement-Learning-Algorithmus, das heißt, er lernt den Wert jedes Zustands-Aktionspaars. Der Wert eines Zustands-Aktionspaars ist die erwartete Belohnung für den Agenten, diese Aktion in diesem Zustand auszuführen.
Actor-Critic ist ein RL-Algorithmus, der wertebasiert und richtlinienbasiert kombiniert. Es gibt zwei Komponenten:
Akteur: Der Akteur ist für die Auswahl von Operationen verantwortlich.
Kritiker: Verantwortlich für die Bewertung des Verhaltens des Schauspielers.
Schauspieler und Kritiker werden gleichzeitig ausgebildet. Akteure werden darin geschult, die erwarteten Belohnungen zu maximieren, und Kritiker werden darin geschult, die erwarteten Belohnungen für jedes Zustands-Aktions-Paar genau vorherzusagen.
Der Akteur-Kritiker-Algorithmus hat mehrere Vorteile gegenüber anderen Verstärkungslernalgorithmen. Erstens ist es stabiler, was bedeutet, dass es während des Trainings weniger wahrscheinlich zu Verzerrungen kommt. Zweitens ist es effizienter, was bedeutet, dass es schneller lernen kann. Drittens ist es besser skalierbar und kann auf Probleme mit großen Zustands- und Aktionsräumen angewendet werden
Die folgende Tabelle fasst die Hauptunterschiede zwischen Deep Q-Learning und Actor-Critic zusammen:
Vorteile von Actor- Critic (A2C)
 Actor-Critic ist eine beliebte Architektur für verstärkendes Lernen, die richtlinienbasierte und wertebasierte Ansätze kombiniert. Es hat viele Vorteile, die es zu einer guten Wahl für die Lösung verschiedener Verstärkungslernaufgaben machen:
Actor-Critic ist eine beliebte Architektur für verstärkendes Lernen, die richtlinienbasierte und wertebasierte Ansätze kombiniert. Es hat viele Vorteile, die es zu einer guten Wahl für die Lösung verschiedener Verstärkungslernaufgaben machen:
1. Geringe Varianz
Im Vergleich zu herkömmlichen Richtliniengradientenmethoden weist A2C normalerweise eine geringere Leistung beim Training der Varianz auf. Dies liegt daran, dass A2C sowohl den Richtliniengradienten als auch die Wertfunktion verwendet und die Wertfunktion verwendet, um die Varianz bei der Berechnung des Gradienten zu verringern. Geringe Varianz bedeutet, dass der Trainingsprozess stabiler ist und schneller zu einer besseren Richtlinie konvergieren kann.
2. Schnellere Lerngeschwindigkeit. Aufgrund der Merkmale geringer Varianz kann A2C eine Richtlinie normalerweise schneller erlernen Strategie. Dies ist besonders wichtig für Aufgaben, die umfangreiche Simulationen erfordern, da schnellere Lerngeschwindigkeiten wertvolle Zeit und Rechenressourcen sparen.
3. Kombination von Richtlinien- und Wertefunktion
Ein bemerkenswertes Merkmal von A2C ist, dass es gleichzeitig Richtlinien- und Wertefunktionen lernt. Diese Kombination ermöglicht es dem Agenten, die Korrelation zwischen Umgebung und Aktionen besser zu verstehen und so Richtlinienverbesserungen besser zu steuern. Das Vorhandensein der Wertfunktion trägt auch dazu bei, Fehler bei der Richtlinienoptimierung zu reduzieren und die Trainingseffizienz zu verbessern.
4. Unterstützt kontinuierliche und diskrete Aktionsräume
A2C kann sich an verschiedene Arten von Aktionsräumen anpassen, einschließlich kontinuierlicher und diskreter Aktionen, und ist sehr vielseitig. Dies macht A2C zu einem weit verbreiteten Reinforcement-Learning-Algorithmus, der auf eine Vielzahl von Aufgaben angewendet werden kann, von der Robotersteuerung bis zur Gameplay-Optimierung Verarbeitungsserver und verteilte Computerressourcen. Dies bedeutet, dass mehr empirische Daten in kürzerer Zeit gesammelt werden können, wodurch die Trainingseffizienz verbessert wird.
Obwohl schauspielerkritische Methoden einige Vorteile haben, stehen sie auch vor einigen Herausforderungen, wie z. B. Hyperparameter-Tuning und potenzieller Instabilität beim Training. Mit geeigneter Abstimmung und Techniken wie Experience Replay und Target Networks können diese Herausforderungen jedoch weitgehend gemildert werden, was Actor-Critic zu einer wertvollen Methode beim Reinforcement Learning macht
Panda-Gym
Panda-Gym wurde auf Basis der PyBullet-Engine entwickelt und umfasst 6 Aufgaben wie Greifen, Schieben, Schieben, Aufnehmen und Platzieren, Stapeln und Umdrehen des Panda-Roboterarms von OpenAI Fetch.
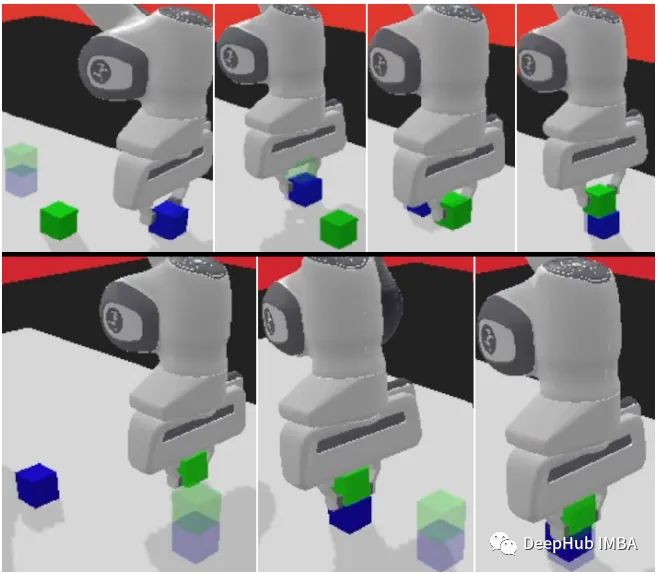
Wir verwenden Panda-Gym als Beispiel, um den folgenden Code zu zeigen
1. Installieren Sie die Bibliothek
Zuerst müssen wir den Code für die Verstärkungslernumgebung initialisieren:
!apt-get install -y \libgl1-mesa-dev \libgl1-mesa-glx \libglew-dev \xvfb \libosmesa6-dev \software-properties-common \patchelf !pip install \free-mujoco-py \pytorch-lightning \optuna \pyvirtualdisplay \PyOpenGL \PyOpenGL-accelerate\stable-baselines3[extra] \gymnasium \huggingface_sb3 \huggingface_hub \ panda_gym
2. Importieren Sie die Bibliothek
import os import gymnasium as gym import panda_gym from huggingface_sb3 import load_from_hub, package_to_hub from stable_baselines3 import A2C from stable_baselines3.common.evaluation import evaluate_policy from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize from stable_baselines3.common.env_util import make_vec_env
3. Erstellen Sie die Laufumgebung
env_id = "PandaReachDense-v3" # Create the env env = gym.make(env_id) # Get the state space and action space s_size = env.observation_space.shape a_size = env.action_space print("\n _____ACTION SPACE_____ \n") print("The Action Space is: ", a_size) print("Action Space Sample", env.action_space.sample()) # Take a random action
4. Normalisierung von Beobachtungen und Belohnungen
Eine gute Möglichkeit, das Verstärkungslernen zu optimieren. Wir berechnen den laufenden Mittelwert und die Standardabweichung der Eingabemerkmale über den Wrapper. Normalisieren Sie auch Belohnungen, indem Sie norm_reward = True
env = make_vec_env(env_id, n_envs=4) env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10.)
5 hinzufügen. Erstellen Sie ein A2C-Modell. Wir verwenden offizielle Agenten, die vom Stable-Baselines3-Team geschult wurden , Bewertung Agent
model = A2C(policy = "MultiInputPolicy",env = env,verbose=1)
Zusammenfassung
In „Panda-Gym“ ermöglicht uns die effektive Kombination aus Panda-Roboterarm und GYM-Umgebung, das Verstärkungslernen des Roboterarms einfach vor Ort durchzuführen,
Akteur-Kritiker Die Architektur bei der der Agent lernt, bei jedem Zeitschritt schrittweise Verbesserungen vorzunehmen, steht im Gegensatz zu einer spärlichen Belohnungsfunktion (bei der das Ergebnis binär ist), was die Actor-Critic-Methode für diese Art von Aufgabe besonders geeignet macht.
Durch die nahtlose Kombination von Richtlinienlernen und Wertschätzung ist der Roboteragent in der Lage, den Endeffektor des Roboterarms geschickt zu manipulieren und die angegebene Zielposition genau zu erreichen. Dies bietet nicht nur eine praktische Lösung für Aufgaben wie die Robotersteuerung, sondern hat auch das Potenzial, eine Vielzahl von Bereichen zu verändern, die eine agile und fundierte Entscheidungsfindung erfordern
Das obige ist der detaillierte Inhalt vonTiefgreifendes Q-Learning-Verstärkungslernen mit der Roboterarmsimulation von Panda-Gym. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Zusammenfassung häufig verwendeter Bibliotheken für maschinelles Lernen in Python
- Einführung in häufig verwendete Bibliotheken für maschinelles Lernen und Deep Learning in Python (Zusammenfassungsfreigabe)
- Wie künstliche Intelligenz und maschinelles Lernen die Zukunft des Gesundheitswesens beeinflussen werden
- Grundlagen des maschinellen Lernens: Wie kann eine Überanpassung verhindert werden?
- Von Mäusen, die durch das Labyrinth laufen, bis hin zu AlphaGo, das Menschen besiegt, die Entwicklung des verstärkenden Lernens