
Heim >Technologie-Peripheriegeräte >KI >SMPLer-X: Untergräbt die sieben Hauptlisten und präsentiert das erste menschliche Bewegungserfassungsmodell!
SMPLer-X: Untergräbt die sieben Hauptlisten und präsentiert das erste menschliche Bewegungserfassungsmodell!

- 王林nach vorne
- 2023-10-30 16:01:08735Durchsuche
Obwohl derzeit große Forschungsfortschritte bei der Expressive Human Pose and Shape Estimation (EHPS) erzielt wurden, sind die fortschrittlichsten Methoden immer noch durch die Einschränkungen des Trainingsdatensatzes eingeschränkt
Kürzlich haben Forscher der S -Lab, SenseTime, das Shanghai Artificial Intelligence Laboratory, die Universität Tokio und das IDEA Research Institute haben zum ersten Mal das groß angelegte Bewegungserfassungsmodell SMPLer-X für Aufgaben zur menschlichen Körperhaltung und Körpergrößenschätzung vorgeschlagen. Die Studie nutzte bis zu 4,5 Millionen Instanzen aus verschiedenen Datenquellen, um das Modell zu trainieren und erzielte dabei die beste Leistung bei 7 Schlüssellisten
SMPLer-X kann nicht nur Körperbewegungen erfassen, sondern auch Gesichter und Handbewegungen ausgeben und schätzen Körperform

Papierlink: https://arxiv.org/abs/2309.17448
Projekthomepage: https://caizhongang.github.io/projects/ SMPLer-X/
Mit umfangreichen Daten und riesigen Modellen hat SMPLer-X in verschiedenen Tests und Rankings eine starke Leistung gezeigt und verfügt auch in unbekannten Umgebungen über eine hervorragende Vielseitigkeit. Im Hinblick auf die Datenerweiterung führten die Forscher eine umfassende Bewertung und Analyse von 32 3D-Modellen durch Datensätze zum menschlichen Körper als Referenz für das Modelltraining
2. Im Hinblick auf die Modellskalierung wurde ein visuelles großes Modell verwendet, um die Auswirkungen einer Erhöhung der Anzahl von Modellparametern auf die Leistung zu untersuchen
3 Das allgemeine große Modell von SMPLer-X kann durch Feinabstimmungsstrategien in ein dediziertes großes Modell umgewandelt werden, wodurch weitere Leistungsverbesserungen erzielt werden können.
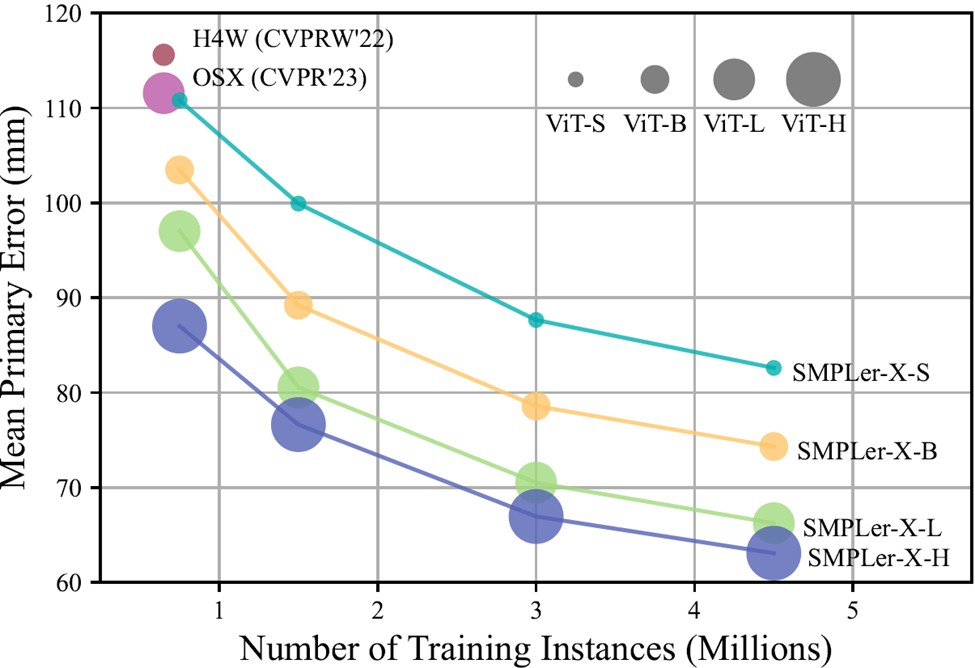
Zusammenfassend führte SMPLer-X eine Untersuchung der Datenskalierung und Modellskalierung durch (siehe Abbildung 1) und bewertete 32 akademische Datensätze, während es sein 4,5-Millionen-Instanzen-Training durchführte, und erzielte dabei die beste Leistung in 7 Schlüssellisten einschließlich AGORA, UBody, EgoBody und EHF. MPE)
Durchführung einer Generalisierungsstudie an vorhandenen 3D-Datensätzen des menschlichen Körpers
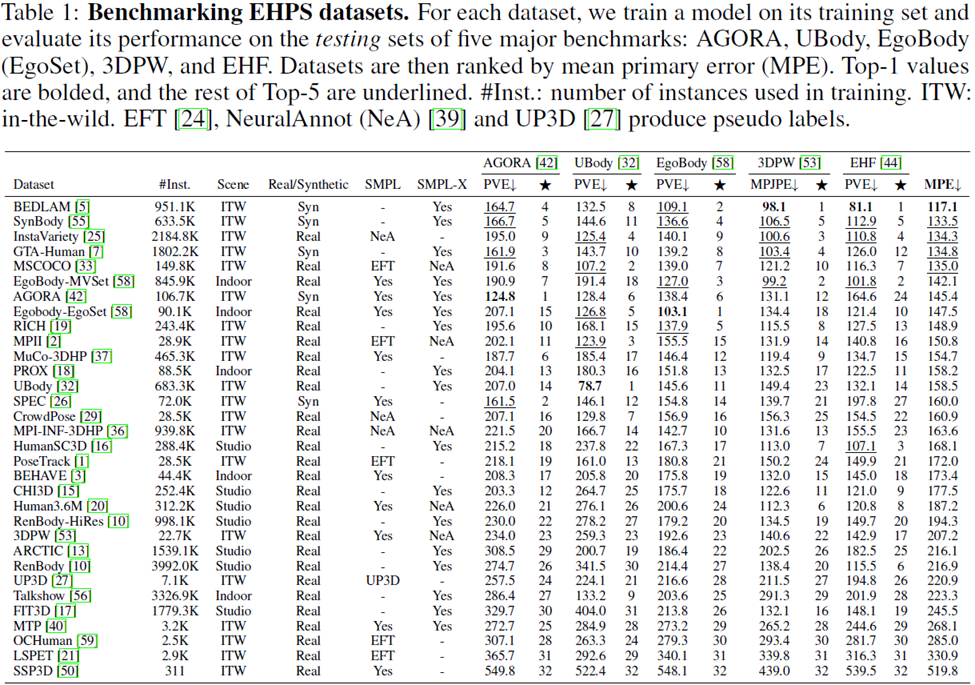
Forscher führten eine Generalisierungsstudie an 32 akademischen Datensätzen durch. Die Datensätze wurden in eine Rangfolge gebracht: Um die Leistung jedes Datensatzes zu messen, wurde ein Modell mit diesem Datensatz trainiert und das Modell wurde anhand von fünf Bewertungsdatensätzen bewertet: AGORA, UBody, EgoBody, 3DPW und EHF.
Der mittlere Primärfehler (MPE) wird ebenfalls in der Tabelle berechnet, um einen einfachen Vergleich zwischen verschiedenen Datensätzen zu ermöglichen.
Inspiration aus der Untersuchung der Verallgemeinerung von Datensätzen
Durch die Analyse einer großen Anzahl von Datensätzen (siehe Abbildung 3) können die folgenden vier Schlussfolgerungen gezogen werden:
1 Das Datenvolumen eines einzelnen Datensatzes kann für das Modelltraining verwendet werden, um eine höhere Kostenleistung zu erzielen
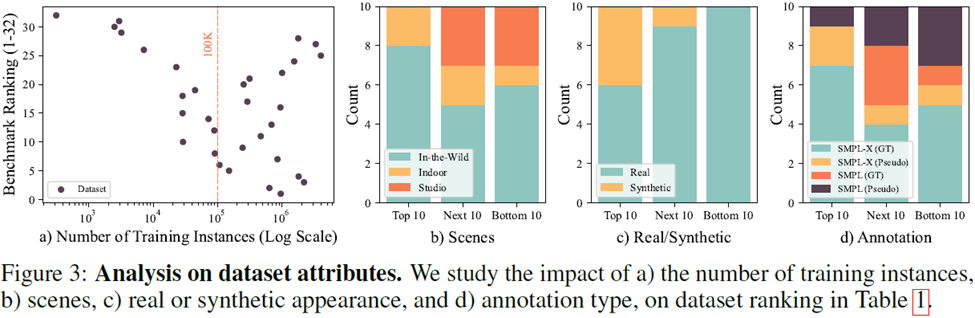 2 In Bezug auf das Erfassungsszenario des Datensatzes -Wild-Datensatz hat die beste Wirkung. Wenn Daten nur in Innenräumen erfasst werden können, müssen Sie zur Verbesserung des Trainingseffekts die Verwendung von Daten aus einer einzelnen Szene vermeiden.
2 In Bezug auf das Erfassungsszenario des Datensatzes -Wild-Datensatz hat die beste Wirkung. Wenn Daten nur in Innenräumen erfasst werden können, müssen Sie zur Verbesserung des Trainingseffekts die Verwendung von Daten aus einer einzelnen Szene vermeiden.
In Bezug auf die Erfassung von Datensätzen sind zwei der drei wichtigsten Datensätze generierte Datensätze. In den letzten Jahren haben generierte Datensätze eine starke Leistung gezeigt
In Bezug auf die Annotation von Datensätzen spielen Pseudo-Labels auch eine sehr wichtige Rolle beim Training
Training und Feinabstimmung großer Motion-Capture-Modelle
Heutzutage Die meisten hochmodernen Methoden verwenden normalerweise nur wenige Datensätze (z. B. MSCOCO, MPII und Human3.6M) für das Training, während in diesem Artikel mehr Datensätze verwendet werden
Angesichts der Tatsache, dass höherrangige Datensätze bevorzugt werden, haben wir vier verschiedene Datengrößen verwendet: 5, 10, 20 und 32 Datensätze als Trainingssätze mit einer Gesamtgröße von 750.000, 1,5 Millionen, 3 Millionen und 4,5 Millionen Instanzen Darüber hinaus demonstrierten die Forscher auch kostengünstige Feinabstimmungsstrategien, um allgemeine große Modelle an spezifische Szenarien anzupassen. Die obige Tabelle zeigt einige der Haupttests, wie AGORA-Testsatz (Tabelle 3), AGORA-Verifizierungssatz (Tabelle 4), EHF (Tabelle 5), UBody (Tabelle). 6) , EgoBody-EgoSet (Tabelle 7). Darüber hinaus evaluierten die Forscher auch die Verallgemeinerung des großen Motion-Capture-Modells auf zwei Testsätzen, ARCTIC und DNA-Rendering Die Forscher hoffen, dass SMPLer-X Vorteile bieten kann, die über das Algorithmusdesign hinausgehen akademische Gemeinschaft mit leistungsstarken Modellen zur Erfassung menschlicher Ganzkörperbewegungen. Der Code und das vorab trainierte Modell wurden als Open Source auf der Projekthomepage bereitgestellt. Weitere Informationen finden Sie unter https://caizhongang.github.io/projects/SMPLer-X/. Ergebnisanzeige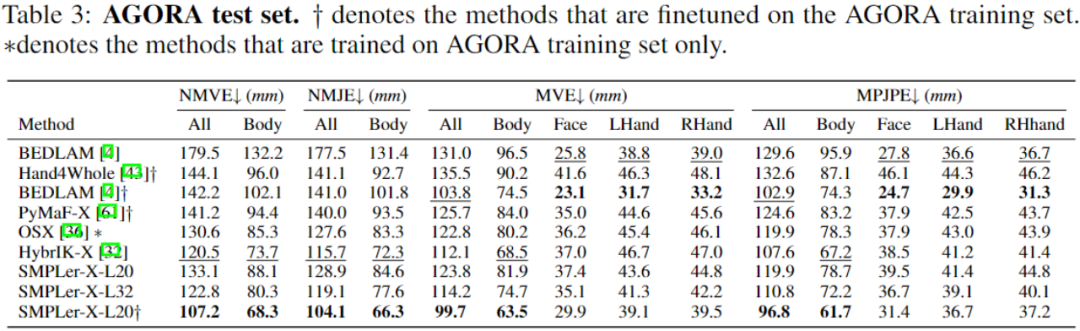
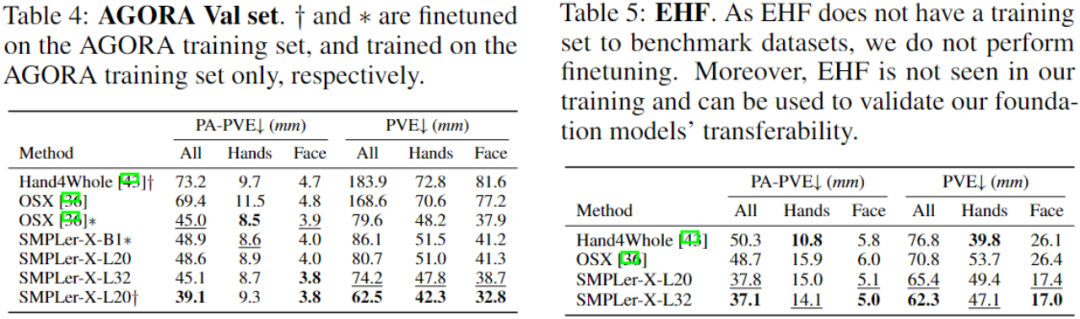
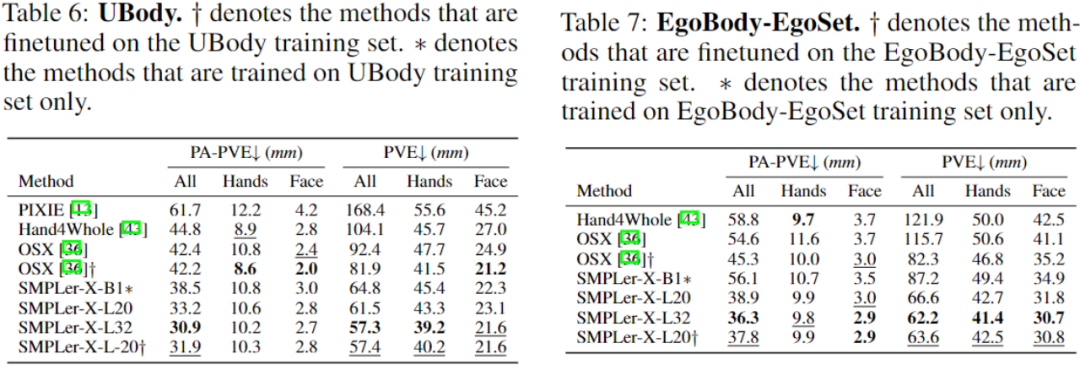



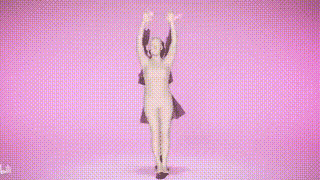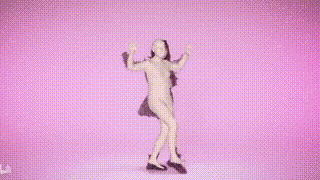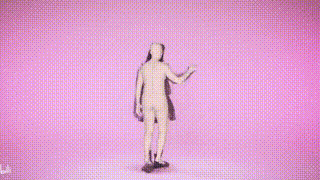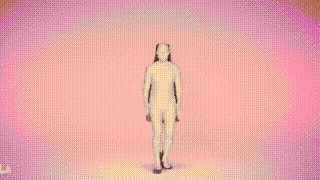



Das obige ist der detaillierte Inhalt vonSMPLer-X: Untergräbt die sieben Hauptlisten und präsentiert das erste menschliche Bewegungserfassungsmodell!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was sind die Boxmodelleigenschaften von CSS? Einführung in die Eigenschaften von CSS-Boxmodellen
- Der Unterschied zwischen has und with im Laravel-Assoziationsmodell (ausführliche Einführung)
- So speichern Sie PS-Bilder im AI-Format
- So konvertieren Sie ps in ai
- Was ist der Hauptbeitrag des Turing-Maschinen-Rechenmodells?