
Heim >Technologie-Peripheriegeräte >KI >NVIDIA eröffnet eine neue Ära: die „Perpetuum Mobile' für Robotertrainingsdaten
NVIDIA eröffnet eine neue Ära: die „Perpetuum Mobile' für Robotertrainingsdaten

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-10-30 14:49:02769Durchsuche
Die meisten der bisherigen synthetischen Daten wurden für das Training großer KI-Modelle verwendet. Diesmal hat NVIDIA einen „Datenspeicher“ für das Robotertraining aufgebaut. Einer der Hauptgründe, warum das Entwicklungstempo der Robotertechnologie weit hinter anderen KI-Bereichen zurückbleibt Mangel an Daten. Mit nur 200 menschlichen Demonstrationsquelldaten kann das System direkt 50.000 Trainingsdaten generieren.
Angesichts des enormen Datenbedarfs von KI sind die Datenressourcen fast erschöpft. Daher haben verschiedene Unternehmen begonnen, einen „neuen Weg“ zur Datenbeschaffung zu erkunden – indem sie ihre eigenen Daten „erstellen“. Allerdings wurden die meisten der bisherigen synthetischen Daten für das Training großer KI-Modelle verwendet. Dieses Mal hat NVIDIA einen „Datenspeicher“ für das Robotertraining erstellt.
Ein aktuelles Forschungspapier von NVIDIA und der University of Texas in Austin stellt ein System namens „MimicGen“ vor, das mit nur wenigen menschlichen Demonstrationen automatisch umfangreiche Robotertrainingsdatensätze generieren kann. Jim Fan, leitender Wissenschaftler bei Nvidia, sagte, das Unternehmen werde alles Open Source anbieten, einschließlich der generierten Datensätze.
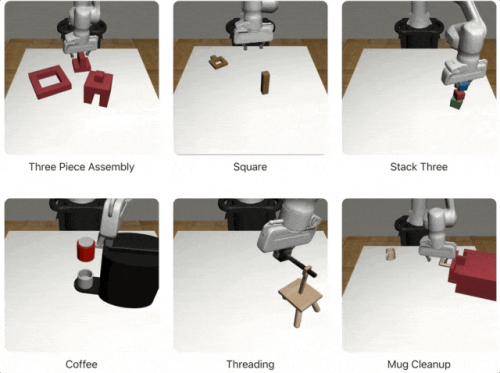
Wie groß sind die generierten Daten? Mit 10 menschlichen Demos kann MimicGen 1.000 synthetische Beispiele generieren, mit 200 menschlichen Demos kann MimicGen direkt 50.000 Trainingsdaten generieren, die 18 Aufgaben und mehrere Simulationsumgebungen umfassen.
Wie ist der generierte Datensatz?MimicGen kann dieselbe Szene basierend auf vorhandenen Daten in verschiedenen Stadien „entwickeln“:

Darüber hinaus gibt es auch Aufgabendaten, die ein langfristiges Training erfordern:


. Darüber hinaus verglichen die Forscher auch die Daten von 10 menschlichen Demonstrationen und 200 menschlichen Demonstrationen, und die Ergebnisse unterschieden sich auch nicht wesentlich. Daher räumt das Papier auch ein, dass weitere Untersuchungen darüber erforderlich sind, ob mehr menschliche Demonstrationsdaten zu Redundanz und unnötigen Kosten für die Datenannotation führen.
Warum sind Sie so besessen von synthetischen Daten? Zusätzlich zu den am Anfang des Artikels erwähnten begrenzten Quelldatenressourcen ist das Sammeln von Daten auch extrem teuer und zeitaufwändig. Mit Systemen wie MimicGen können
automatisch große umfangreiche Datensätze mit nur einer kleinen Datenmenge generiert werden. und diese Daten Es integriert mehrere Szenen, Objektfähigkeiten und Roboterarme und kann auch für Langzeit- oder Hochpräzisionsaufgaben verwendet werden. Man kann es als „leistungsstarke und wirtschaftliche Möglichkeit zur Erweiterung des Roboterlernens“ bezeichnen.„Synthetische Daten werden die nächste Welle von Terascale-Daten für unsere ‚hungrigen‘ Modelle liefern.
“ Der leitende NVIDIA-Wissenschaftler Jim Fan sagte bei der Einführung von MimicGen: „Die Entwicklung der Robotiktechnologie liegt weit hinter der anderer KI zurück. Einer der Hauptgründe auf diesem Gebiet.“ ist der Mangel an Daten – man kann keine Steuersignale (von Robotern) aus dem Internet bekommen“ „Uns gehen die hochwertigen realen Daten aus dem Internet schnell aus, und aus synthetischen Daten hervorgegangene KI wird die zukünftige Entwicklungsrichtung sein .“
Quelle: Science and Technology Innovation Board DailyDas obige ist der detaillierte Inhalt vonNVIDIA eröffnet eine neue Ära: die „Perpetuum Mobile' für Robotertrainingsdaten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!