
Heim >Technologie-Peripheriegeräte >KI >Ein Überblick über End-to-End-Planungsmethoden für autonomes Fahren
Ein Überblick über End-to-End-Planungsmethoden für autonomes Fahren

- 王林nach vorne
- 2023-10-30 14:45:051007Durchsuche
Dieser Artikel wurde mit Genehmigung des öffentlichen Kontos von Heart of Autonomous Driving nachgedruckt.
1. Der Plan von Woven Planet (Toyota-Tochtergesellschaft): Urban Driver 2021.
Obwohl dieser Artikel ist ab 21 Jahren, aber viele neue Artikel verwenden es als Vergleichsbasis, daher ist es auch notwendig, seine Methode zu verstehen Mit dieser Zuordnung kann die Funktion die gesamte Ausführungsbahn Schritt für Schritt ableiten. Der endgültige Verlust besteht darin, die durch diese Ableitung gegebene Flugbahn so nah wie möglich an die Expertenbahn heranzuführen.
Der Effekt sollte zu diesem Zeitpunkt ziemlich gut sein, sodass er zur Grundlage für neue Algorithmen werden kann. 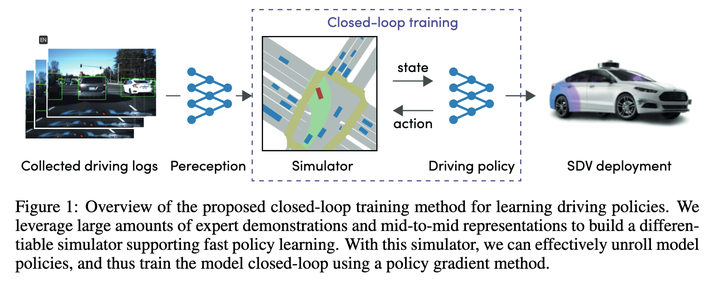
2. Nanyang Technological University Plan 1 Conditional Predictive Behavior Planning with Inverse Reinforcement Learning 2023.04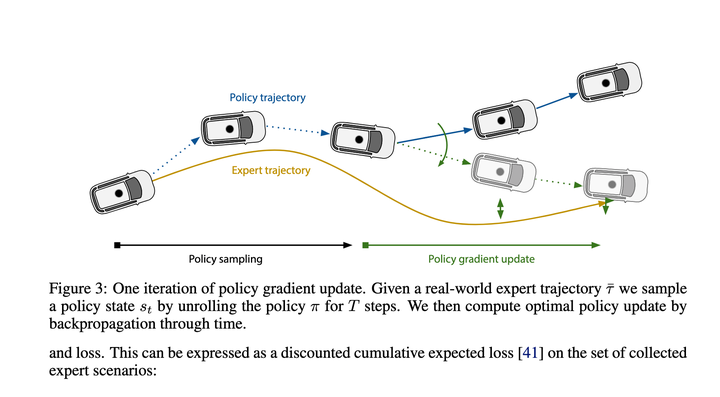
Verwenden Sie die bedingte Vorhersage, um die Vorhersageergebnisse für die Kandidatenflugbahn jedes Host-Fahrzeugs zu berechnen, und verwenden Sie dann IRL, um die Kandidatenflugbahn zu bewerten. Das Conditional Joint Prediction-Modell sieht folgendermaßen aus:
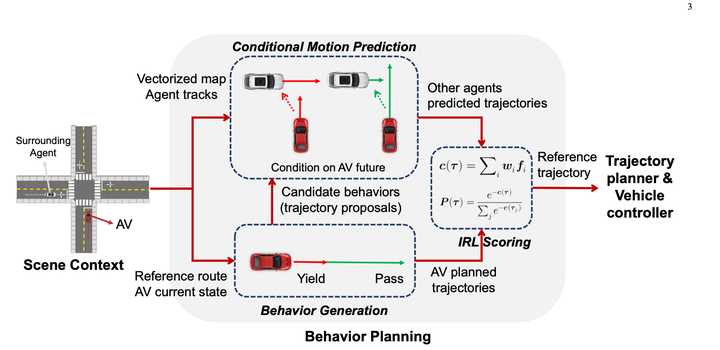
Das grundsätzlich Tolle an dieser Methode ist, dass sie Conditional Joint Prediction verwendet, um interaktive Vorhersagen zu vervollständigen, was dem Algorithmus eine gewisse Spielfähigkeit verleiht.
Aber ich persönlich denke, dass das Manko des Algorithmus darin besteht, dass zuvor nur 10 bis 30 Trajektorien generiert wurden und Vorhersagen bei der Generierung von Trajektorien nicht berücksichtigt wurden und am Ende eine dieser Trajektorien direkt als Endergebnis nach IRL ausgewählt wird Wertung, die es einfacher macht, 10 bis 30 Situationen zu erkennen, die nach Berücksichtigung der Vorhersagen nicht ideal waren. Es ist gleichbedeutend mit der Wahl eines Generals unter Krüppeln, und diejenigen, die ausgewählt werden, sind immer noch Krüppel. Basierend auf dieser Lösung wird es eine gute Möglichkeit sein, das Problem der Qualität der Stichprobengenerierung zu lösen.
 Da es jedoch eine weitere Dimension gibt, ist der Lösungsraum nach zu vielen Erweiterungen immer noch groß und die Berechnungsmenge ist zu groß. Die im aktuellen Artikel beschriebene Methode besteht darin, einige Knoten zufällig zu verwerfen, wenn sie vorhanden sind Es gibt zu viele Knoten. Stellen Sie sicher, dass der Berechnungsaufwand kontrollierbar ist (es scheint, dass es nach n Ebenen passieren kann, wenn zu viele Knoten vorhanden sind und die Auswirkungen relativ gering sein können)
Da es jedoch eine weitere Dimension gibt, ist der Lösungsraum nach zu vielen Erweiterungen immer noch groß und die Berechnungsmenge ist zu groß. Die im aktuellen Artikel beschriebene Methode besteht darin, einige Knoten zufällig zu verwerfen, wenn sie vorhanden sind Es gibt zu viele Knoten. Stellen Sie sicher, dass der Berechnungsaufwand kontrollierbar ist (es scheint, dass es nach n Ebenen passieren kann, wenn zu viele Knoten vorhanden sind und die Auswirkungen relativ gering sein können)
Der Hauptbeitrag dieses Artikels besteht darin, einen kontinuierlichen Lösungsraum durch diesen Baumstichprobenregelprozess in eine Markov-Entscheidung umzuwandeln und ihn dann mit dp zu lösen.
4. Der neueste gemeinsame Plan der Nanyang Technological University und NVIDIA im Oktober 2023: DTPP: Differenzierbare gemeinsame bedingte Vorhersage und Kostenbewertung für die Planung von Baumrichtlinien beim autonomen Fahren
Der Titel fühlt sich sehr spannend an: 1 ein gewisser Gaming-Effekt2. Es ist differenzierbar und kann den gesamten Gradienten zurückgeben, sodass Vorhersagen zusammen mit IRL trainiert werden können. Dies ist auch eine notwendige Voraussetzung für den Aufbau eines durchgängigen autonomen Fahrens. Drittens verfügt Tree Policy Planning möglicherweise über bestimmte interaktive Schlussfolgerungsfunktionen. Nach sorgfältiger Lektüre habe ich festgestellt, dass dieser Artikel sehr informativ und die Methode sehr gut ist clever.
Nach der Kombination und Verbesserung von NVIDIAs TPP und der bedingten prädiktiven Verhaltensplanung der Nanyang Polytechnic mit Inverse Reinforcement Learning wurde das Problem schlechter Kandidatenverläufe in der vorherigen Arbeit der Nanyang Polytechnic erfolgreich gelöst
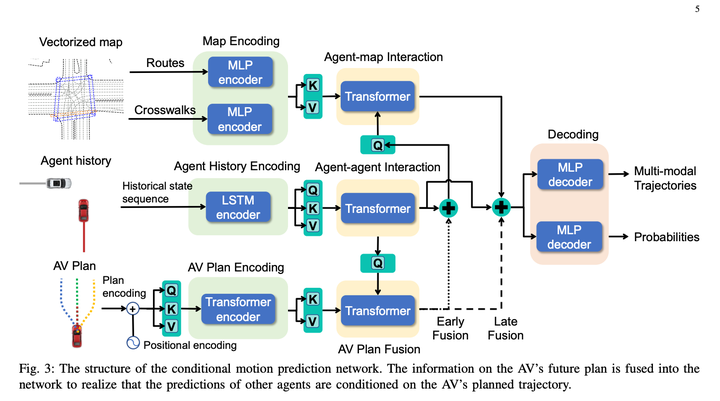
Zu den Hauptmodulen des Papierplans gehören:1. Das Modul „Bedingte Vorhersage“ gibt eine historische Flugbahn des Hauptfahrzeugs + eine sofortige Flugbahn + eine historische Flugbahn des Hindernisfahrzeugs ein und gibt die vorhergesagte Flugbahn des Hauptfahrzeugs an, die sich der sofortigen Flugbahn nähert, und die vorhergesagte Flugbahn des Hindernisfahrzeugs, die konsistent ist mit dem Verhalten des Hauptfahrzeugs.
2. Das Bewertungsmodul kann die Flugbahn eines Hauptfahrzeugs und eines Hindernisfahrzeugs bewerten, um festzustellen, ob diese Flugbahn dem Verhalten eines Experten ähnelt. Die Lernmethode ist IRL.
3. Baumrichtlinien-Suchmodul, das zum Generieren einer Reihe von Kandidatenverläufen verwendet wird
Der Baumsuchalgorithmus wird verwendet, um die mögliche Lösung des Hauptfahrzeugs zu erkunden. Jeder Schritt im Erkundungsprozess verwendet die erkundete Flugbahn als Eingabe, verwendet den bedingten Vorhersagealgorithmus, um die vorhergesagten Flugbahnen des Hauptfahrzeugs und des Hindernisfahrzeugs zu generieren Ruft das Bewertungsmodul auf, um die Qualität der Flugbahn zu bewerten, was sich auf die Richtung der nächsten Suche nach Erweiterungsknoten auswirkt. Mit dieser Methode können Sie einige Hauptfahrzeugtrajektorien generieren, die sich von anderen Lösungen unterscheiden, und beim Generieren von Trajektorien die Interaktion mit dem Hindernisfahrzeug berücksichtigen.
Traditionelles IRL erstellt manuell viele Features, wie z. B. eine Reihe verschiedener Front- und Heckfeatures Merkmale von Hindernissen in der Trajektorienzeitdimension (wie relative s, l und ttc). Um das Modell differenzierbar zu machen, wird in diesem Artikel der Ego-Kontext MLP der Vorhersage direkt verwendet, um ein Gewichtsarray (Größe = 1 *) zu generieren. C) stellt implizit die Umgebungsinformationen rund um das Host-Fahrzeug dar und verwendet dann MLP, um die Trajektorie des Host-Fahrzeugs + entsprechende multimodale Vorhersageergebnisse direkt in ein Feature-Array umzuwandeln (Größe = C * N, N bezieht sich auf die Anzahl der Kandidatentrajektorien ) , und dann werden die beiden Matrizen multipliziert, um die endgültige Flugbahnbewertung zu erhalten. Dann ließ IRL die Experten die höchste Punktzahl erzielen. Persönlich bin ich der Meinung, dass dies der Berechnungseffizienz dient und den Decoder so einfach wie möglich macht, aber es gibt immer noch einen gewissen Verlust an Hauptfahrzeuginformationen. Wenn Sie nicht auf die Berechnungseffizienz achten, können Sie einige mehr verwenden Komplexe Netzwerke zur Verbindung von Ego-Kontext und vorhergesagten Trajektorien, und der Effekt sollte besser sein? Wenn Sie auf die Differenzierbarkeit verzichten, können Sie dennoch darüber nachdenken, manuell festgelegte Funktionen hinzuzufügen, was ebenfalls den Modelleffekt verbessern sollte.
Was die Zeit anbelangt, verwendet diese Lösung eine Methode aus einer Neukodierung + mehreren leichten Dekodierungen, wodurch Berechnungsverzögerungen erfolgreich reduziert werden. Der Artikel weist darauf hin, dass die Verzögerung auf 98 Millisekunden komprimiert werden kann
Es gehört zu den SOTA-Rängen unter den lernbasierten Planern und der Closed-Loop-Effekt kommt dem im vorherigen Artikel erwähnten regelbasierten Schema-PDM Nr. 1 von nuplan nahe.
Zusammenfassung
Wenn ich es mir ansehe, halte ich dieses Paradigma für eine gute Idee. Sie können Wege finden, den spezifischen Prozess in der Mitte anzupassen:
- Verwenden Sie das Vorhersagemodell, um einige Regeln zu verwenden, um ein gewisses Kandidaten-Ego zu generieren Trajektorien
- Verwenden Sie für jede Trajektorie die bedingte gemeinsame Vorhersage, um interaktive Vorhersagen zu treffen und Agentenvorhersagen zu generieren. Kann die Spieleleistung verbessern.
- IRL und andere Methoden verwenden die Ergebnisse der bedingten Gelenkvorhersage, um die vorherige Hauptfahrzeugbahn zu bewerten und die optimale Flugbahn auszuwählen

Der Inhalt, der neu geschrieben werden muss, ist: Originallink: https://mp.weixin. qq. com/s/ZJtMU3zGciot1g5BoCe9Ow
Das obige ist der detaillierte Inhalt vonEin Überblick über End-to-End-Planungsmethoden für autonomes Fahren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was sind die Web-Backend-Entwicklungstechnologien?
- Ein optisches Laufwerk ist ein Gerät, das welche Technologie zum Speichern von Informationen verwendet?
- Welche Etappen hat die Datenmanagement-Technologie bisher durchlaufen?
- Wird sich Teslas selbstfahrender Guru an ChatGPT beteiligen? Werde OpenAI beitreten
- Autonome Fahrtechnologie und intelligente Transportsystempraxis in Java implementiert