
Heim >Technologie-Peripheriegeräte >KI >Hervorragende Praxis der 3D-Rekonstruktion intelligenten Fahrens in der Cloud
Hervorragende Praxis der 3D-Rekonstruktion intelligenten Fahrens in der Cloud

- PHPznach vorne
- 2023-10-27 17:13:041400Durchsuche

Die kontinuierliche Weiterentwicklung der intelligenten Fahrtechnologie verändert unsere Reisemethoden und Transportsysteme. Als eine der Schlüsseltechnologien spielt die 3D-Rekonstruktion eine wichtige Rolle in intelligenten Fahrsystemen. Zusätzlich zu den Wahrnehmungs- und Rekonstruktionsalgorithmen des Autos selbst erfordert die Implementierung und Entwicklung autonomer Fahrtechnologie die Unterstützung riesiger Cloud-Rekonstruktionsfunktionen. Das Volcano Engine Multimedia Laboratory nutzt branchenführende selbstentwickelte 3D-Rekonstruktionstechnologie in Kombination mit einer leistungsstarken Cloud Plattformressourcen und -fähigkeiten, um die Implementierung und Anwendung verwandter Technologien in Szenarien wie groß angelegter Rekonstruktion, automatischer Annotation und realistischer Simulation in der Cloud zu unterstützen.
Dieser Artikel konzentriert sich auf die Prinzipien und Praktiken der 3D-Rekonstruktionstechnologie des Volcano Engine Multimedia Laboratory in dynamischen und statischen Szenen und kombiniert mit fortschrittlicher Lichtfeld-Rekonstruktionstechnologie, um jedem besser zu helfen, besser zu verstehen und zu verstehen, wie intelligente 3D-Rekonstruktion in der Cloud dem Bereich der Intelligenz dient Fahren, um die Entwicklung der Branche zu unterstützen.
1. Technische Herausforderungen und Schwierigkeiten
Die Fahrszenenrekonstruktion erfordert eine dreidimensionale Rekonstruktion der Straßenumgebung auf Punktwolkenebene. Im Vergleich zu herkömmlichen Anwendungsszenarien der dreidimensionalen Rekonstruktionstechnologie weist die Fahrszenenrekonstruktionstechnologie die folgenden Schwierigkeiten auf:
- Fahrzeugbetriebsprozess Die Umgebungsfaktoren im Fahrzeug sind komplex und unkontrollierbar. Unterschiedliches Wetter, Beleuchtung, Fahrzeuggeschwindigkeit, Straßenbedingungen usw. wirken sich alle auf die von den Bordsensoren erfassten Daten aus, was eine Herausforderung für die Robustheit der Rekonstruktion darstellt Technologie.
- Merkmalsverschlechterung und Texturverlust treten in Straßenszenen häufig auf. Beispielsweise erhält die Kamera Bildinformationen, die nicht reich an visuellen Merkmalen sind, oder das Lidar erhält Szenenstrukturinformationen mit hoher Ähnlichkeit Der Schlüssel zur Rekonstruktion ist, dass die Farbe einzeln ist und nicht genügend Texturinformationen enthält, was höhere Anforderungen an die Rekonstruktionstechnologie stellt.
- Es gibt eine große Anzahl fahrzeugmontierter Sensoren. Zu den gebräuchlichsten gehören Kameras, Lidar, Millimeterwellenradar, Trägheitsnavigation, GPS-Positionierungssystem, Radgeschwindigkeitsmesser usw. So fusionieren Sie Daten von mehreren Sensoren, um genauere Rekonstruktionsergebnisse zu erhalten ?Technologie stellt Herausforderungen dar.
- Das Vorhandensein dynamischer Objekte wie sich bewegender Fahrzeuge, nicht motorisierter Fahrzeuge und Fußgänger auf der Straße stellt herkömmliche Rekonstruktionsalgorithmen vor Herausforderungen. So eliminieren Sie dynamische Objekte, die die statische Szenenrekonstruktion beeinträchtigen, und schätzen die Position, Größe usw. ein Geschwindigkeit dynamischer Objekte gleichzeitig, was auch eine der Schwierigkeiten des Projekts ist.
2. Einführung in die Fahrszenen-Rekonstruktionstechnologie
Rekonstruktionsalgorithmen im Bereich des autonomen Fahrens nutzen in der Regel Lidar und Kameras als Haupttechnologie, ergänzt durch GPS und Trägheitsnavigation. LiDAR kann hochpräzise Entfernungsinformationen direkt abrufen und schnell die Szenenstruktur ermitteln. Durch die gemeinsame Kalibrierung vor der Lidar-Kamera kann das von der Kamera erhaltene Bild der Laserpunktwolke Farb-, Semantik- und andere Informationen verleihen. Gleichzeitig können GPS und Trägheitsnavigation bei der Positionierung helfen und die Drift reduzieren, die durch die Verschlechterung der Merkmale während des Rekonstruktionsprozesses verursacht wird. Aufgrund des hohen Preises von Mehrleitungs-Lidar wird es jedoch normalerweise in technischen Fahrzeugen eingesetzt und ist in Massenfahrzeugen nur schwer in großem Maßstab einsetzbar.
In diesem Zusammenhang hat das Volcano Engine Multimedia Laboratory unabhängig eine Reihe rein visueller Technologien zur Rekonstruktion von Fahrszenen entwickelt, darunter die Rekonstruktion statischer Szenen, die Rekonstruktion dynamischer Objekte und die Rekonstruktion neuronaler Strahlungsfelder, mit denen dynamische und statische Objekte in der Szene unterschieden und wiederhergestellt werden können Statische Szenen heben wichtige Elemente wie Straßenoberflächen, Schilder und Ampeln hervor und können die Position, Größe, Ausrichtung und Geschwindigkeit sich bewegender Objekte in der Szene effektiv abschätzen Statische Szenen rekonstruieren Im Wesentlichen wird das neuronale Strahlungsfeld zum Rekonstruieren und Reproduzieren der Szene verwendet, um ein Free-View-Roaming zu erreichen, das für die Szenenbearbeitung und das Simulationsrendering verwendet werden kann. Diese technische Lösung ist nicht auf Lidar angewiesen und kann relative Fehler im Dezimeterbereich erzielen, wodurch Rekonstruktionseffekte nahe an Lidar bei minimalen Hardwarekosten erzielt werden.
2.1 Statische Szenenrekonstruktionstechnologie: Beseitigen Sie dynamische Interferenzen und stellen Sie statische Szenen wieder her.
Die visuelle Rekonstruktionstechnologie basiert auf der Geometrie mehrerer Ansichten und erfordert, dass die zu rekonstruierende Szene oder das zu rekonstruierende Objekt eine Interframe-Konsistenz aufweist, d. h. in verschiedenen Bildframes Im stationären Zustand müssen dynamische Objekte während des Rekonstruktionsprozesses eliminiert werden. Entsprechend der Bedeutung verschiedener Elemente in der Szene müssen irrelevante Punktwolken aus der dichten Punktwolke entfernt werden, während einige wichtige Elementpunktwolken beibehalten werden. Daher muss das Bild im Voraus semantisch segmentiert werden. In diesem Zusammenhang kombiniert Volcano Engine Multimedia Laboratory KI-Technologie und Grundprinzipien der Multi-View-Geometrie, um ein fortschrittliches, robustes, genaues und vollständiges visuelles Rekonstruktionsalgorithmus-Framework zu erstellen. Der Rekonstruktionsprozess umfasst drei Schlüsselschritte: Bildvorverarbeitung, spärliche Rekonstruktion und dichte Rekonstruktion.
Die am Fahrzeug montierte Kamera ist während der Aufnahme in Bewegung. Aufgrund der Belichtungszeit treten bei zunehmender Fahrzeuggeschwindigkeit starke Bewegungsunschärfen auf. Um Bandbreite und Speicherplatz zu sparen, wird das Bild außerdem während des Übertragungsprozesses irreversibel verlustbehaftet komprimiert, was zu einer weiteren Verschlechterung der Bildqualität führt. Zu diesem Zweck nutzt das Volcano Engine Multimedia Laboratory ein durchgängiges neuronales Netzwerk, um das Bild zu entschärfen, was die Bildqualität verbessern und gleichzeitig Bewegungsunschärfe unterdrücken kann. Der Vergleich vor und nach dem Entschärfen ist in der folgenden Abbildung dargestellt.

Vor dem Entschärfen (links) Nach dem Entschärfen (rechts)
Um dynamische Objekte zu unterscheiden, verwendet das Volcano Engine Multimedia Laboratory eine dynamische Objekterkennungstechnologie basierend auf dem optischen Fluss, mit der dynamische Objekte auf Pixelebene maskiert werden können . Beim anschließenden Rekonstruktionsprozess der statischen Szene werden Merkmalspunkte, die auf den dynamischen Objektbereich fallen, eliminiert und nur statische Szenen und Objekte bleiben erhalten.

Optischer Fluss (links) Bewegtes Objekt (rechts)
Während des spärlichen Rekonstruktionsprozesses müssen Position, Ausrichtung und Szenenpunktwolke der Kamera gleichzeitig berechnet werden. Zu den häufig verwendeten Algorithmen gehört der SLAM-Algorithmus (Simultaneous). Lokalisierung und Kartierung) und SFM-Algorithmus (Structure from Motion, kurz SfM). Der SFM-Algorithmus kann eine höhere Rekonstruktionsgenauigkeit erreichen, ohne dass eine Echtzeitleistung erforderlich ist. Der herkömmliche SFM-Algorithmus behandelt jedoch normalerweise jede Kamera als unabhängige Kamera, während mehrere Kameras normalerweise in verschiedenen Richtungen am Fahrzeug angeordnet sind und die relativen Positionen zwischen diesen Kameras tatsächlich fest sind (unter Berücksichtigung geringfügiger Änderungen durch Vibrationen). . Wenn die relativen Positionsbeschränkungen zwischen Kameras ignoriert werden, ist der berechnete Posenfehler jeder Kamera relativ groß. Darüber hinaus ist es bei starker Okklusion schwierig, die Position der einzelnen Kameras zu berechnen. In diesem Zusammenhang hat das Volcano Engine Multimedia Laboratory selbst einen SFM-Algorithmus entwickelt, der auf der gesamten Kameragruppe basiert und die vorherigen relativen Posenbeschränkungen zwischen Kameras verwenden kann, um die Pose der Kameragruppe als Ganzes zu berechnen, und außerdem GPS plus Trägheit verwendet Durch die Fusion von Positionierungsergebnissen zur Einschränkung der Mittelposition der Kameragruppe können die Erfolgsrate und Genauigkeit der Posenschätzung effektiv verbessert, Punktwolkeninkonsistenzen zwischen verschiedenen Kameras verbessert und die Punktwolkenschichtung reduziert werden.


Traditionelles SFM (links) Kameragruppe SFM (rechts)
Aufgrund der einzelnen Farbe und der fehlenden Textur auf dem Boden ist es für die traditionelle visuelle Rekonstruktion schwierig, den gesamten Boden wiederherzustellen, aber Es gibt Fahrspurlinien, Schlüsselelemente wie Pfeile, Text/Logos usw. Daher verwendet das Volcano Engine Multimedia Laboratory eine quadratische Oberfläche zur Anpassung an den Boden, um die Tiefenschätzung und Punktwolkenfusion des Bodenbereichs zu unterstützen. Im Vergleich zur Ebenenanpassung eignet sich die quadratische Oberfläche besser für tatsächliche Straßenszenen, da die tatsächliche Straßenoberfläche häufig keine ideale Ebene ist. Das Folgende ist ein Vergleich der Auswirkungen der Verwendung von Ebenengleichungen und quadratischen Oberflächengleichungen zur Anpassung an den Boden.

Ebenengleichung (links) Quadratische Oberflächengleichung (rechts)
Wenn man die Laserpunktwolke als wahren Wert betrachtet und die visuellen Rekonstruktionsergebnisse damit überlagert, kann die Genauigkeit der rekonstruierten Punktwolke intuitiv gemessen werden. Wie aus der folgenden Abbildung ersichtlich ist, ist die Übereinstimmung zwischen der rekonstruierten Punktwolke und der echten Punktwolke sehr hoch. Nach der Messung beträgt der relative Fehler des Rekonstruktionsergebnisses etwa 15 cm.

Rekonstruktionsergebnisse des Volcano Engine Multimedia Laboratory (Farbe) und echte Punktwolken (weiß)
Das Folgende ist ein Vergleich der Auswirkungen des visuellen Rekonstruktionsalgorithmus des Volcano Engine Multimedia Laboratory und einer gängigen kommerziellen Rekonstruktionssoftware. Es zeigt sich, dass der selbst entwickelte Algorithmus des Volcano Engine Multimedia Laboratory im Vergleich zu kommerzieller Software eine bessere und vollständigere Rekonstruktionswirkung auf Straßenschilder, Ampeln, Telefonmasten sowie Fahrspurlinien und Pfeile auf der Straße hat Die Szene weist einen sehr hohen Restaurierungsgrad auf. Die rekonstruierte Punktwolke kommerzieller Software ist jedoch sehr spärlich und die Straßenoberfläche fehlt in großen Bereichen.

Eine gängige kommerzielle Software (links) und ein Volcano Engine Multimedia Laboratory-Algorithmus (rechts)
2.2 Dynamische Rekonstruktionstechnologie:
Es ist sehr schwierig, Objekte auf Bildern in 3D zu kommentieren und erfordert die Hilfe von Punktwolken. Wenn das Fahrzeug nur über visuelle Sensoren verfügt, ist es sehr schwierig, eine vollständige Punktwolke des Zielobjekts zu erhalten in der Szene. Insbesondere bei dynamischen Objekten können dichte Punktwolken mit herkömmlichen 3D-Rekonstruktionstechniken nicht erhalten werden. Um den Ausdruck bewegter Objekte bereitzustellen und 4D-Anmerkungen zu ermöglichen, wird ein 3D-Begrenzungsrahmen (im Folgenden als 3D-Bbox bezeichnet) verwendet, um dynamische Objekte darzustellen, und um die 3D-Bbox-Position, -Größe und -Geschwindigkeit dynamischer Objekte in der jeweiligen Szene zu bestimmen Momente werden durch selbst entwickelte dynamische Rekonstruktionsalgorithmen usw. gewonnen und ergänzen so die Fähigkeit zur dynamischen Objektrekonstruktion.
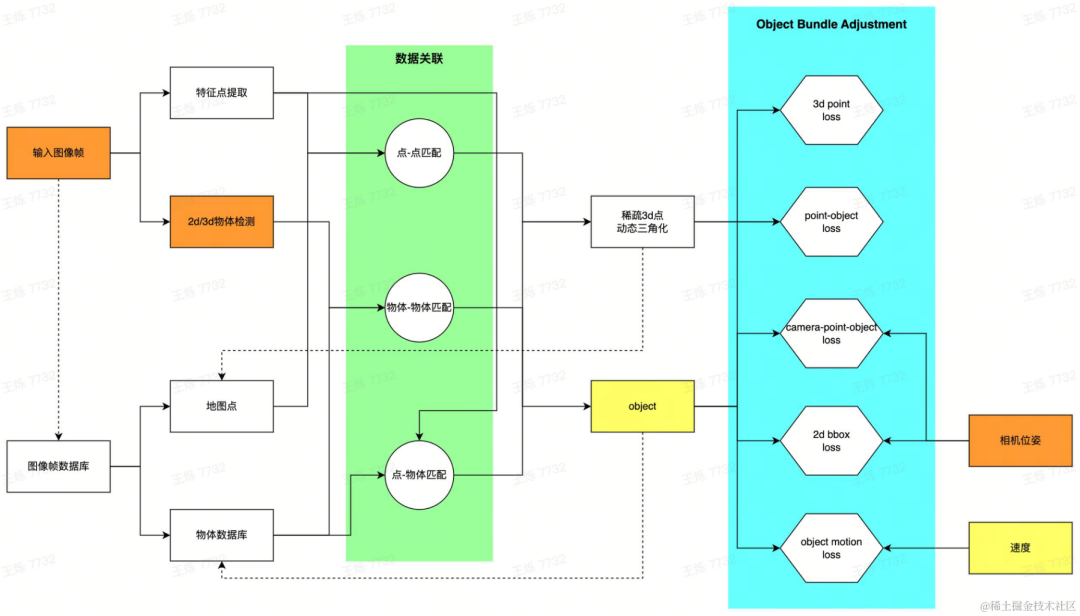
Dynamische Rekonstruktionspipeline
Für jedes vom Fahrzeug erfasste Bild wird zunächst das dynamische Ziel in der Szene extrahiert und ein erster Vorschlag für die 3D-Bbox generiert: Verwendung der 2D-Zielerkennung und Durch Kamerapose Schätzen Sie die entsprechende 3D-Bbox; verwenden Sie die 3D-Zielerkennung direkt. Die beiden Methoden können flexibel für unterschiedliche Daten ausgewählt werden. Die 2D-Erkennung weist eine gute Generalisierung auf, und die 3D-Erkennung kann bessere Anfangswerte erzielen. Gleichzeitig werden Merkmalspunkte innerhalb des dynamischen Bereichs des Bildes extrahiert. Nachdem Sie den ersten 3D-Bbox-Vorschlag und die Merkmalspunkte eines Einzelbildes erhalten haben, stellen Sie eine Datenkorrelation zwischen mehreren Bildern her: Stellen Sie den Objektabgleich mithilfe eines selbst entwickelten Multi-Target-Tracking-Algorithmus her und gleichen Sie Bildmerkmale mithilfe der Feature-Matching-Technologie ab. Nach Erhalt der Übereinstimmungsbeziehung werden die Bildrahmen mit gemeinsamen Ansichtsbeziehungen als lokale Karten erstellt und ein Optimierungsproblem erstellt, um die global konsistente Ziel-Bbox-Schätzung zu lösen. Insbesondere werden durch Feature-Point-Matching und dynamische Triangulationstechnologie dynamische 3D-Punkte wiederhergestellt; Fahrzeugbewegungen werden modelliert und Beobachtungen zwischen Objekten, 3D-Punkten und Kameras werden gemeinsam optimiert, um die optimale geschätzte dynamische Objekt-3D-Bbox zu erhalten.

2D generiertes 3D (zweite von links) 3D-Zielerkennungsbeispiel
2.3 NeRFRekonstruktion: fotorealistische Darstellung, freie Perspektive
Neuronales Netzwerk verwenden für die implizite Rekonstruktion unter Verwendung von A Das differenzierbare Rendering-Modell lernt, Bilder aus vorhandenen Ansichten aus neuen Perspektiven zu rendern und erreicht so eine fotorealistische Bildwiedergabe, also die Neural Radiation Field (NeRF)-Technologie. Gleichzeitig weist die implizite Rekonstruktion die Eigenschaften auf, bearbeitbar zu sein und kontinuierlichen Raum abzufragen, und kann für Aufgaben wie automatische Annotation und Simulationsdatenkonstruktion in autonomen Fahrszenarien verwendet werden. Die Szenenrekonstruktion mithilfe der NeRF-Technologie ist äußerst wertvoll.
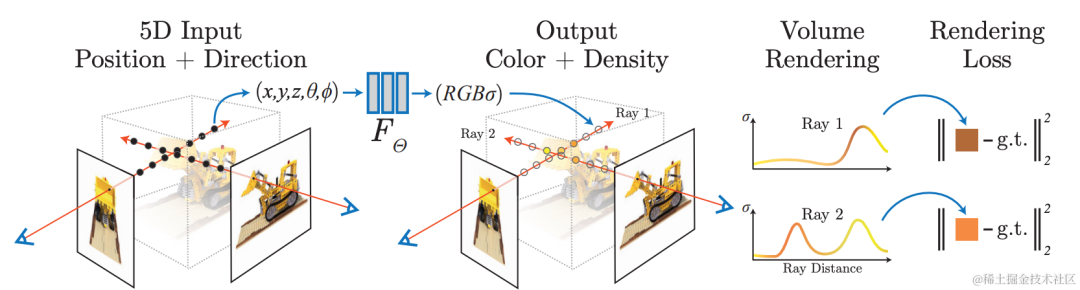
Das Volcano Engine Multimedia Laboratory kombiniert neuronale Strahlungsfeldtechnologie und große Szenenmodellierungstechnologie. In der konkreten Praxis werden zunächst dynamische Objekte in der Szene verarbeitet, die mithilfe von selbst entwickelten dynamischen und statischen Segmentierungs-, Schattenerkennungs- und anderen Algorithmen Artefakte in der Szene verursachen Die Geometrie wird extrahiert und eine Maske generiert. Gleichzeitig wird der Video-Inpainting-Algorithmus verwendet, um die entfernten Bereiche zu reparieren. Mit Hilfe selbst entwickelter 3D-Rekonstruktionsfunktionen wird eine hochpräzise geometrische Rekonstruktion der Szene durchgeführt, einschließlich der Schätzung der Kameraparameter und der Erzeugung spärlicher und dichter Punktwolken. Darüber hinaus ist das Szenario aufgeteilt, um den Verbrauch einzelner Schulungsressourcen zu reduzieren, und es können verteilte Schulungen und Wartungsarbeiten durchgeführt werden. Während des neuronalen Strahlungsfeld-Trainingsprozesses für große randlose Außenszenen verwendete das Team einige Optimierungsstrategien, um den Effekt der neuen Perspektivengenerierung in dieser Szene zu verbessern, z. B. die Verbesserung der Rekonstruktionsgenauigkeit durch gleichzeitige Optimierung der Posen während des Trainings und basierend auf der Ebene von Hash-Codierung. Ausdruck verbessert die Geschwindigkeit des Modelltrainings, Aussehenscodierung wird verwendet, um die Aussehenskonsistenz von Szenen zu verbessern, die zu unterschiedlichen Zeiten gesammelt wurden, und mvs-dichte Tiefeninformationen werden verwendet, um die geometrische Genauigkeit zu verbessern. Das Team arbeitete mit HaoMo Zhixing zusammen, um die Einkanal-Erfassung und die zusammengeführte Mehrkanal-NeRF-Rekonstruktion abzuschließen. Die relevanten Ergebnisse wurden am Haomo AI Day veröffentlicht.

Dynamisches Objekt-/Schatten-Culling, Füllen
Das obige ist der detaillierte Inhalt vonHervorragende Praxis der 3D-Rekonstruktion intelligenten Fahrens in der Cloud. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Welche Servicemodelle gibt es beim Cloud Computing?
- Was ist das Cloud-Computing-Betriebssystem, das Microsoft im Oktober 2008 eingeführt hat?
- Was sind die drei Servicemodelle des Cloud Computing?
- Wie verwende ich die Go-Sprache für die Cloud-Computing-Entwicklung?
- Das intelligente Fahrerlebnis wurde noch einmal verbessert! Xpeng P7 startet das 24. OTA-Upgrade