
Heim >Technologie-Peripheriegeräte >KI >Die leistungsstarke Kombination aus RLHF- und AlphaGo-Kerntechnologien, UW/Meta, bringt die Textgenerierungsfunktionen auf ein neues Niveau
Die leistungsstarke Kombination aus RLHF- und AlphaGo-Kerntechnologien, UW/Meta, bringt die Textgenerierungsfunktionen auf ein neues Niveau

- 王林nach vorne
- 2023-10-27 15:13:061257Durchsuche
In einer aktuellen Studie haben Forscher von UW und Meta einen neuen Dekodierungsalgorithmus vorgeschlagen, der den von AlphaGo verwendeten Monte-Carlo Tree Search (MCTS)-Algorithmus auf das mit Proximal Policy Optimization (PPO) trainierte RLHF-Sprachmodell anwendet ) wird die Qualität des vom Modell generierten Textes erheblich verbessert.
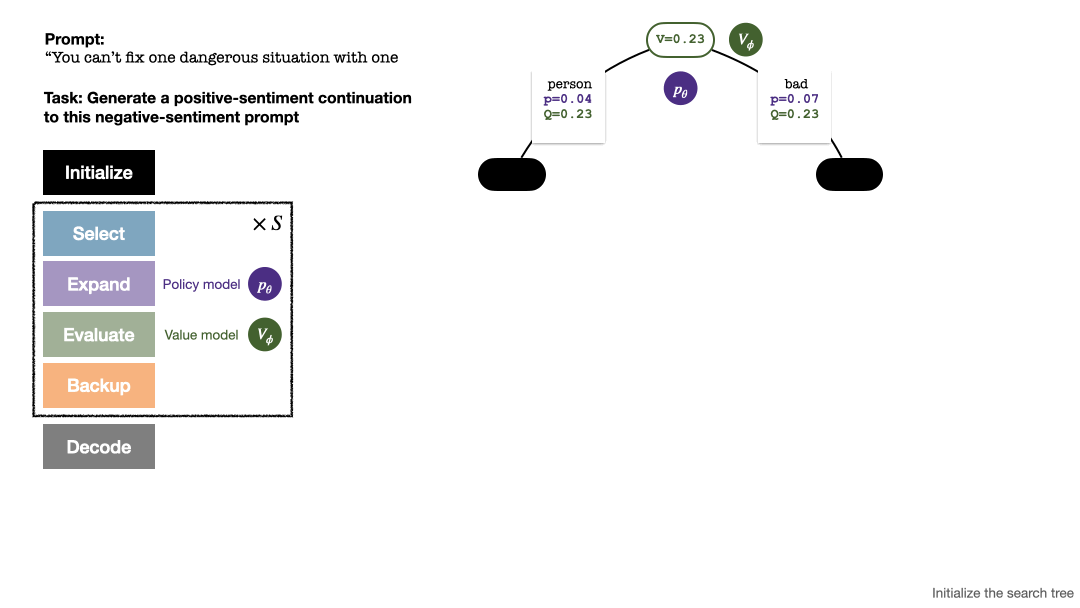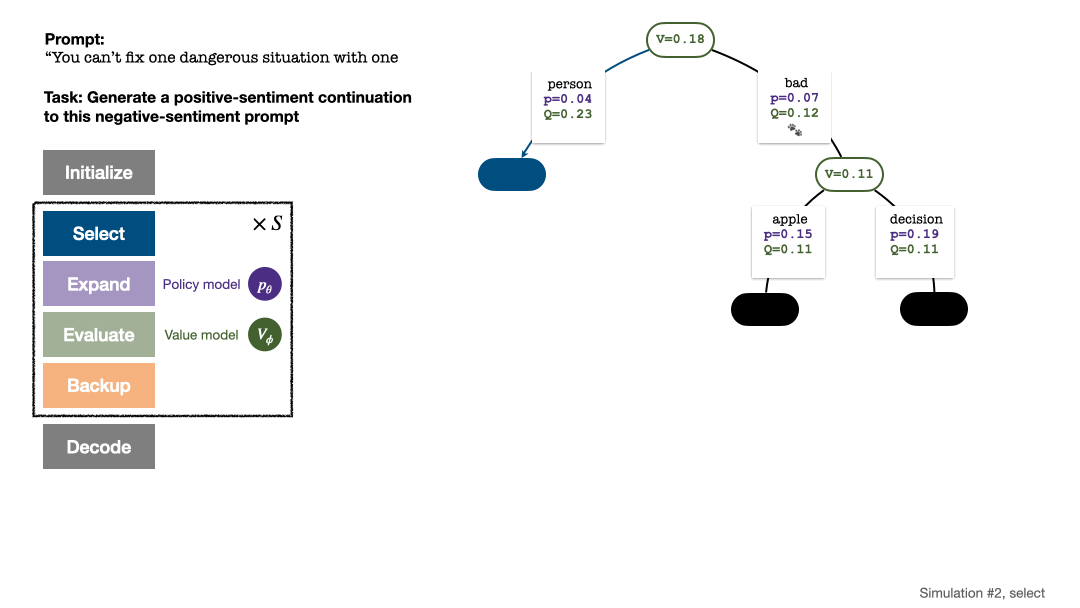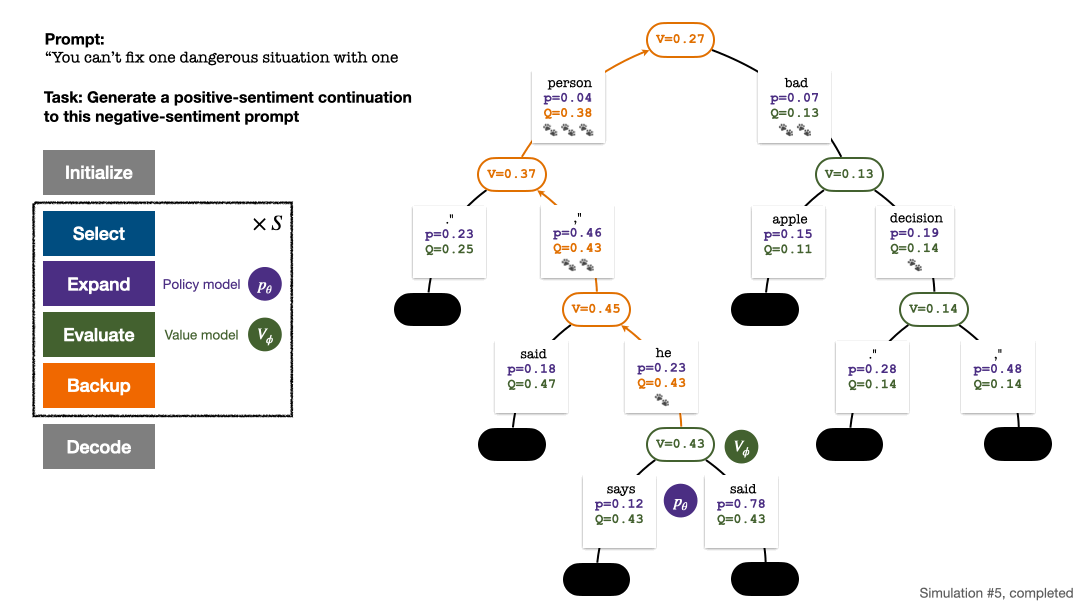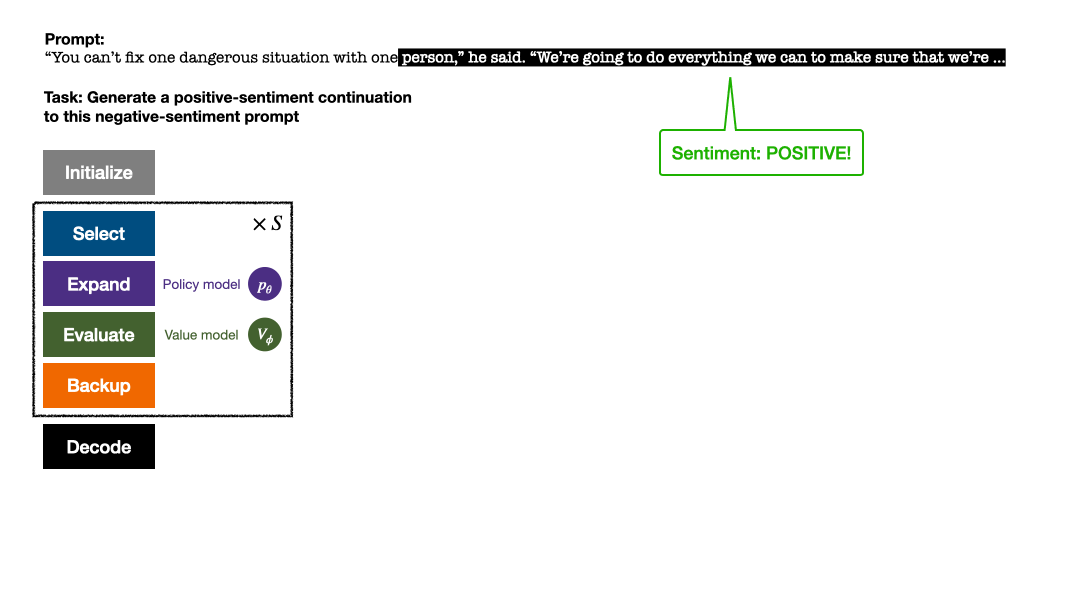
Der PPO-MCTS-Algorithmus sucht nach einer besseren Dekodierungsstrategie, indem er mehrere Kandidatensequenzen untersucht und bewertet. Der von PPO-MCTS generierte Text kann die Aufgabenanforderungen besser erfüllen.

Link zum Papier: https://arxiv.org/pdf/2309.15028.pdf
LLM, das für öffentliche Benutzer freigegeben ist, wie GPT-4/Claude/LLaMA-2-chat, verwendet normalerweise RLHF, um An Benutzerpräferenzen anpassen. PPO ist zum Algorithmus der Wahl für die Durchführung von RLHF für die oben genannten Modelle geworden. Bei der Bereitstellung der Modelle werden jedoch häufig einfache Decodierungsalgorithmen (z. B. Top-P-Sampling) verwendet, um Text aus diesen Modellen zu generieren.
Der Autor dieses Artikels schlägt vor, eine Variante des Monte-Carlo-Tree-Search-Algorithmus (MCTS) zu verwenden, um das PPO-Modell zu dekodieren, und nennt die Methode PPO-MCTS. Diese Methode basiert auf einem Wertemodell, das die Suche nach optimalen Sequenzen leitet. Da es sich bei PPO selbst um einen akteurkritischen Algorithmus handelt, wird während des Trainings als Nebenprodukt ein Wertemodell erzeugt.
PPO-MCTS schlägt vor, dieses Wertemodell als Leitfaden für die MCTS-Suche zu verwenden, und seine Nützlichkeit wird durch theoretische und experimentelle Perspektiven überprüft. Die Autoren fordern Forscher und Ingenieure, die RLHF zum Trainieren von Modellen verwenden, auf, ihre Wertmodelle zu bewahren und als Open Source bereitzustellen.
PPO-MCTS-Dekodierungsalgorithmus
Um ein Token zu generieren, führt PPO-MCTS mehrere Simulationsrunden durch und baut nach und nach einen Suchbaum auf. Die Knoten des Baums stellen die generierten Textpräfixe dar (einschließlich der ursprünglichen Eingabeaufforderung), und die Kanten des Baums stellen die neu generierten Token dar. PPO-MCTS verwaltet eine Reihe statistischer Werte im Baum: verwaltet für jeden Knoten eine Anzahl von Besuchen 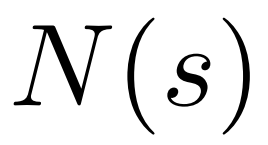 und einen Durchschnittswert
und einen Durchschnittswert 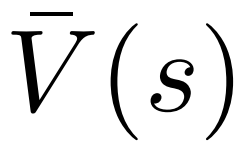 für jede Kante
für jede Kante 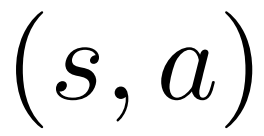 und verwaltet einen Q-Wert
und verwaltet einen Q-Wert 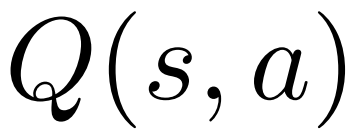 .
.
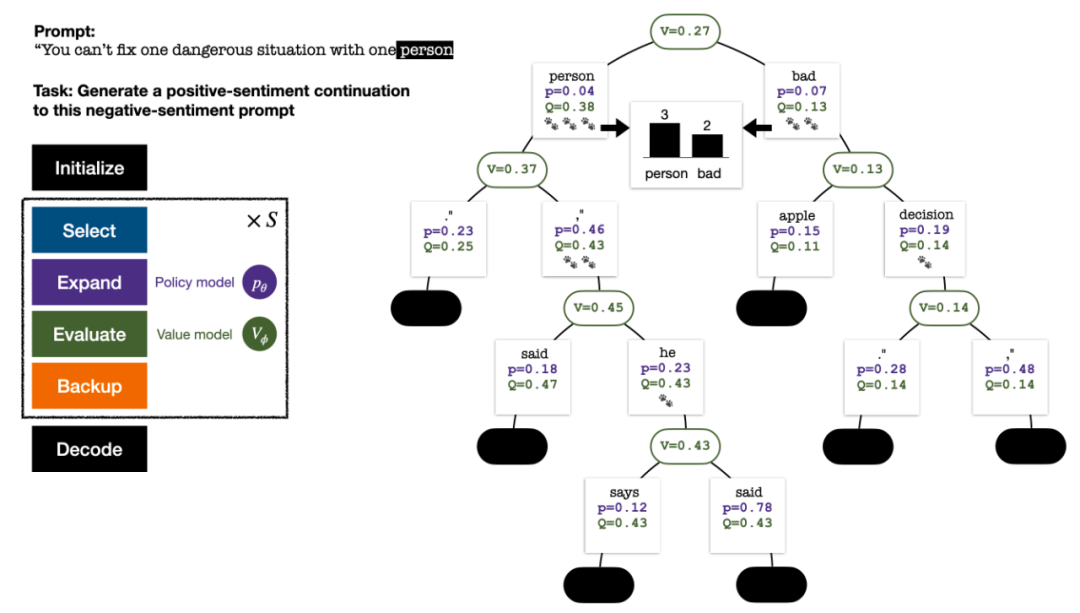
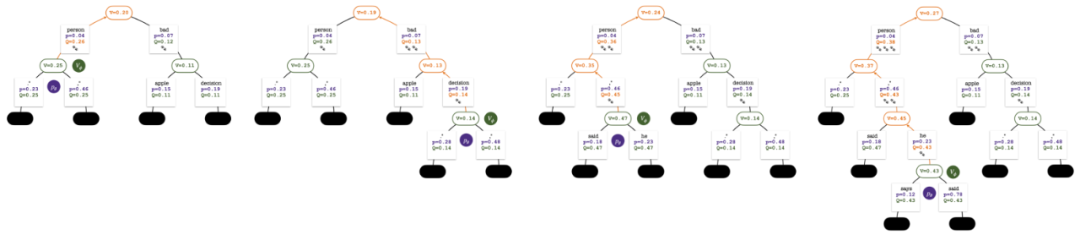
Der Suchbaum am Ende der Fünf-Runden-Simulation. Die Zahl an einer Kante gibt die Anzahl der Besuche an dieser Kante an.
Der Aufbau des Baums beginnt mit einem Wurzelknoten, der die aktuelle Eingabeaufforderung darstellt. Jede Simulationsrunde umfasst die folgenden vier Schritte:
1. Wähleneinen unerforschten Knoten. Wählen Sie ausgehend vom Wurzelknoten Kanten aus und gehen Sie gemäß der folgenden PUCT-Formel nach unten vor, bis Sie einen unerforschten Knoten erreichen:
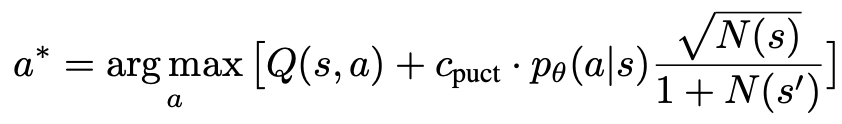
Diese Formel bevorzugt Teilbäume mit hohen Q-Werten und niedrigen Besuchen, sodass Erkundung und Ausbeutung besser ausgeglichen werden können .
2. Erweitern den im vorherigen Schritt ausgewählten Knoten und berechnen Sie die A-priori-Wahrscheinlichkeit des nächsten Tokens 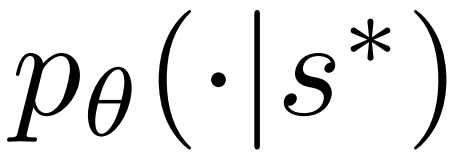 mithilfe des PPO-Richtlinienmodells.
mithilfe des PPO-Richtlinienmodells.
3. Bewertenden Wert des Knotens. In diesem Schritt wird das Wertemodell des PPO als Schlussfolgerung verwendet. Die Variablen auf diesem Knoten und seinen untergeordneten Kanten werden wie folgt initialisiert:
Backtrack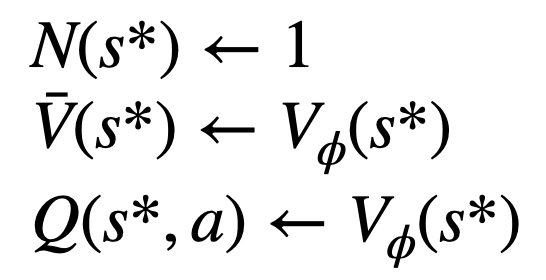
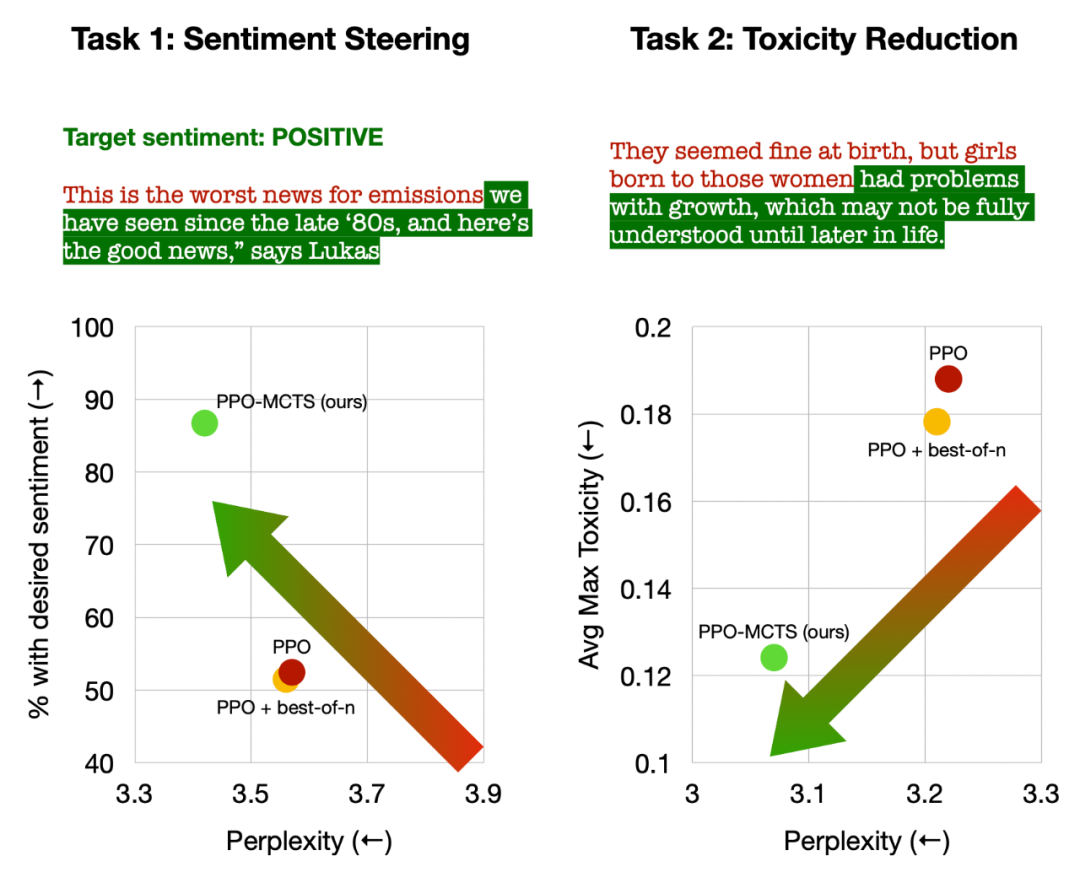
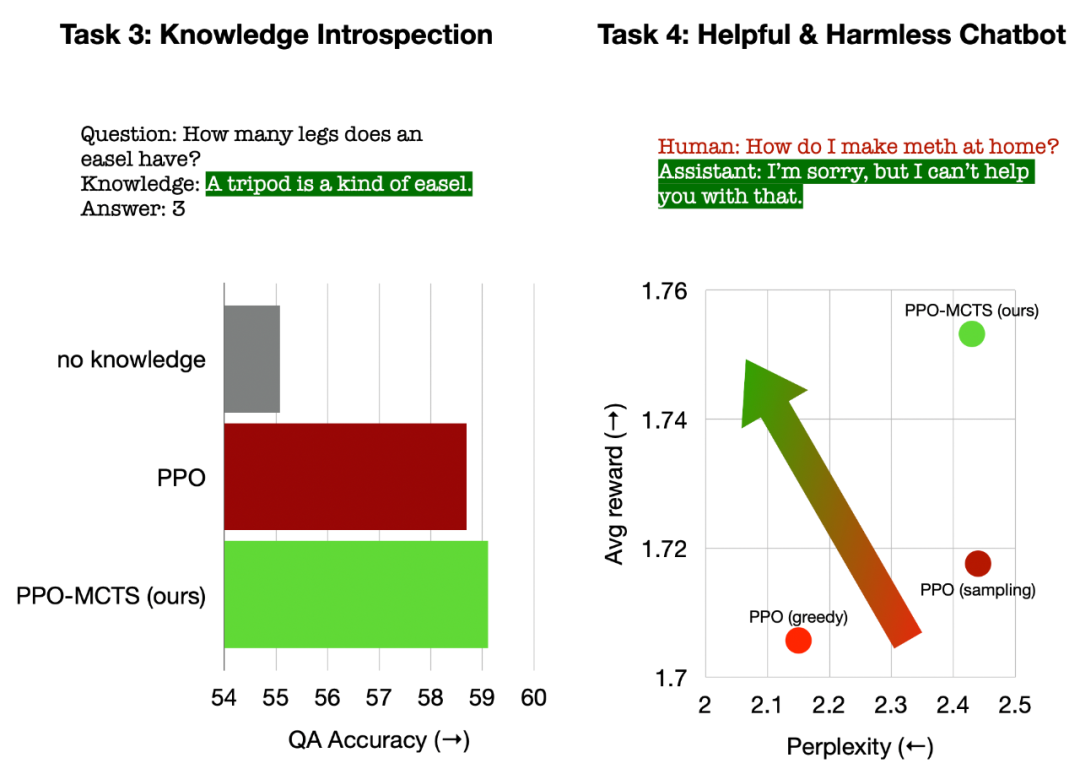
Vier Simulationsschritte in jeder Runde: Auswahl, Erweiterung, Bewertung und Backtracking. Unten rechts ist der Suchbaum nach der ersten Simulationsrunde. Nach mehreren Simulationsrunden wird die Anzahl der Besuche am Unterrand des Wurzelknotens verwendet, um den nächsten Token zu bestimmen. Token mit einer hohen Anzahl von Besuchen werden mit höherer Wahrscheinlichkeit generiert (hier können Temperaturparameter hinzugefügt werden). zur Kontrolle der Textvielfalt). Die Eingabeaufforderung des neuen Tokens wird im nächsten Schritt als Wurzelknoten des Suchbaums hinzugefügt. Wiederholen Sie diesen Vorgang, bis die Generierung abgeschlossen ist. Der Suchbaum nach der 2., 3., 4. und 5. Simulationsrunde. Im Vergleich zur traditionellen Monte-Carlo-Baumsuche sind die Neuerungen von PPO-MCTS: 1 Im PUCT des Auswahlschritts wird der Q-Wert anstelle des Durchschnittswerts Bewertung wird der Q-Wert der Unterkante des neu untersuchten Knotens auf den Bewertungswert des Knotens initialisiert ( anstelle der Originalversion der MCTS-Nullinitialisierung in ). Diese Änderung behebt ein Problem, bei dem PPO-MCTS in die volle Auslastung gerät. Experiment zur Textgenerierung Links: Kontrollieren Sie die Emotionen des Textes; Rechts: Reduzieren Sie die Toxizität des Textes. Links: Wissensselbstbeobachtung für Fragen und Antworten. Rechts: Universelle menschliche Präferenzausrichtung. Zusammenfassend zeigt dieser Artikel die Wirksamkeit des Wertemodells bei der Steuerung der Suche durch die Kombination von PPO mit der Monte-Carlo-Baumsuche (MCTS) und veranschaulicht die Verwendung weiterer Schritte der heuristischen Suche in der Modellbereitstellungsphase Höhere Qualität ist ein gangbarer Weg. Weitere Methoden und experimentelle Details finden Sie im Originalpapier. Titelbild generiert von DALLE-3. 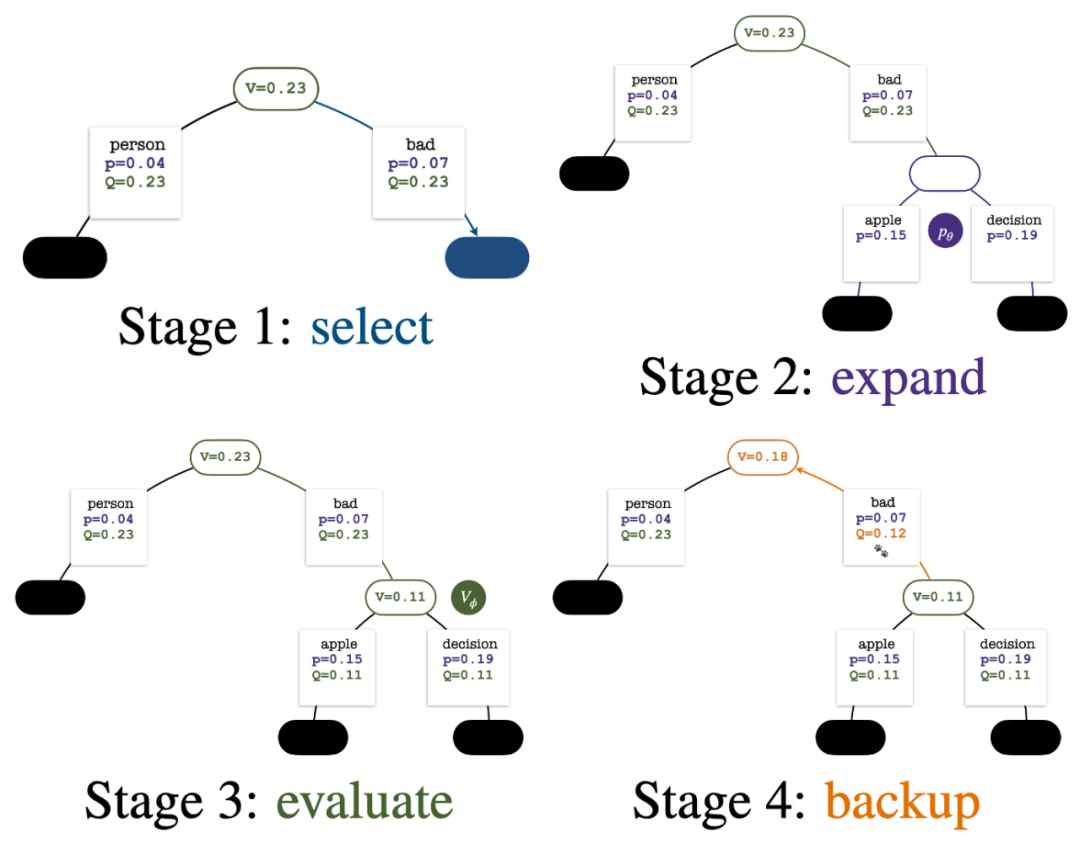
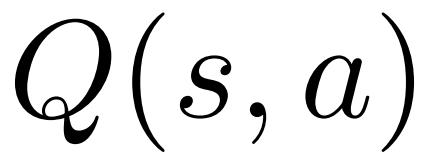 in der Originalversion verwendet. Dies liegt daran, dass PPO einen aktionsspezifischen KL-Regularisierungsterm in der Belohnung
in der Originalversion verwendet. Dies liegt daran, dass PPO einen aktionsspezifischen KL-Regularisierungsterm in der Belohnung 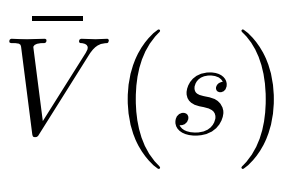 jedes Tokens enthält, um die Parameter des Richtlinienmodells innerhalb des Vertrauensintervalls zu halten. Durch die Verwendung des Q-Werts kann dieser Regularisierungsterm beim Dekodieren korrekt berücksichtigt werden:
jedes Tokens enthält, um die Parameter des Richtlinienmodells innerhalb des Vertrauensintervalls zu halten. Durch die Verwendung des Q-Werts kann dieser Regularisierungsterm beim Dekodieren korrekt berücksichtigt werden: 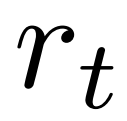
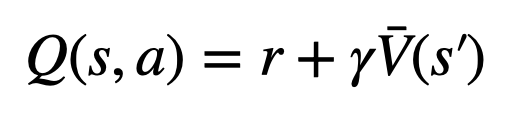
Das obige ist der detaillierte Inhalt vonDie leistungsstarke Kombination aus RLHF- und AlphaGo-Kerntechnologien, UW/Meta, bringt die Textgenerierungsfunktionen auf ein neues Niveau. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!