
Heim >Technologie-Peripheriegeräte >KI >Lange Texte können mit einer Fensterlänge von 4 KB gelesen werden. Chen Danqi und seine Schüler haben gemeinsam mit Meta eine neue Methode zur Verbesserung des Gedächtnisses großer Modelle eingeführt.
Lange Texte können mit einer Fensterlänge von 4 KB gelesen werden. Chen Danqi und seine Schüler haben gemeinsam mit Meta eine neue Methode zur Verbesserung des Gedächtnisses großer Modelle eingeführt.

- 王林nach vorne
- 2023-10-24 20:13:01843Durchsuche
Ein großes Modell mit nur 4k Fensterlänge kann immer noch große Textabschnitte lesen!
Eine neueste Errungenschaft eines chinesischen Doktoranden in Princeton „durchbricht“ erfolgreich die Grenze der Fensterlänge großer Modelle.
Es kann nicht nur verschiedene Fragen beantworten, sondern der gesamte Implementierungsprozess kann vollständig und zeitnah und ohne zusätzliche Schulung abgeschlossen werden.

Das Forschungsteam hat eine Baumspeicherstrategie namens MemWalker entwickelt, die die Fensterlängenbeschränkung des Modells selbst durchbrechen kann.
Während des Tests enthielt der längste vom Modell gelesene Text mehr als 12.000 Token und die Ergebnisse waren im Vergleich zu LongChat deutlich verbessert.
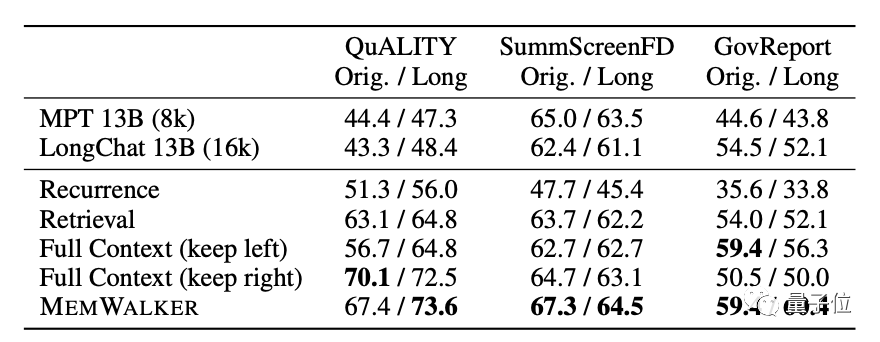
Im Vergleich zum ähnlichen TreeIndex kann MemWalker jede Frage begründen und beantworten, anstatt nur Verallgemeinerungen vorzunehmen.
MemWalker wurde nach dem Prinzip „Teile und herrsche“ entwickelt. Einige Internetnutzer kommentierten:
Jedes Mal, wenn wir den Denkprozess großer Modelle menschlicher gestalten, wird ihre Leistung besser sein

Also , Was genau ist die Baumspeicherstrategie und wie liest man langen Text mit einer begrenzten Fensterlänge?
Wenn ein Fenster nicht ausreicht, öffnen Sie einfach ein paar mehr
Auf dem Modell verwendet MemWalker Stable Beluga 2 als Basismodell, das von Llama 2-70B nach der Befehlsabstimmung erhalten wird.
Bevor die Entwickler sich für dieses Modell entschieden, verglichen sie dessen Leistung mit der des ursprünglichen Llama 2 und entschieden sich schließlich dafür.
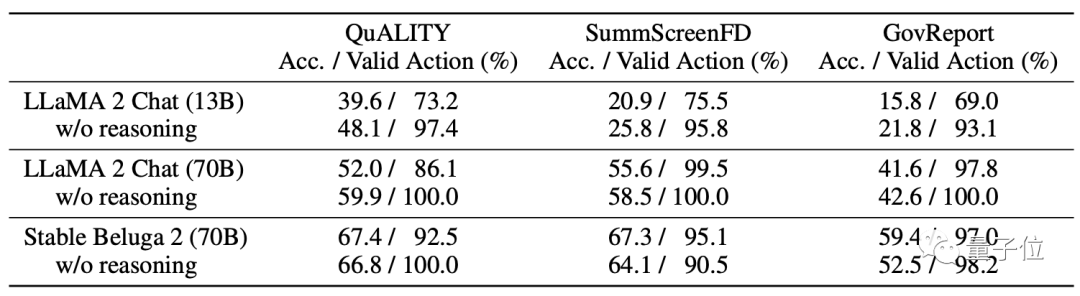
Genau wie der Name MemWalker ist sein Arbeitsprozess wie ein wandelnder Gedächtnisstrom.
Im Einzelnen ist es grob in zwei Phasen unterteilt: Speicherbaumaufbau und Navigationsabruf.
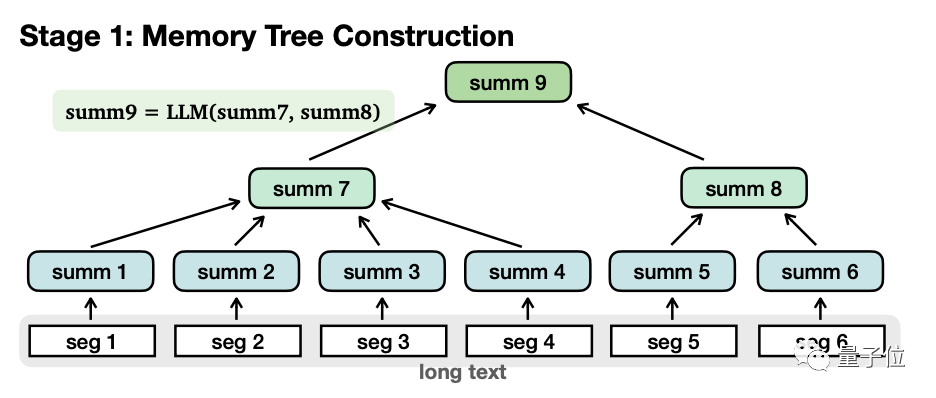
Beim Erstellen eines Speicherbaums wird der Langtext in mehrere kleine Segmente (Seg1-6) unterteilt, und das große Modell fasst jedes Segment separat zusammen und erhält „Blattknoten“ (Blattknoten, Summe1-6).
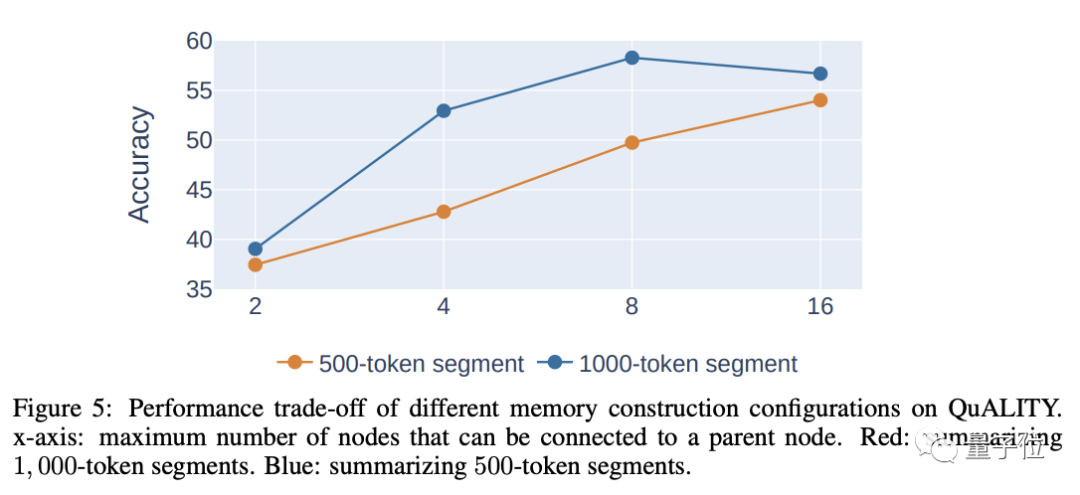
Beim Segmentieren gilt: Je länger jedes Segment ist, desto weniger Ebenen sind vorhanden, was sich positiv auf den späteren Abruf auswirkt. Allerdings führt eine zu lange Länge selbst zu einer Verringerung der Genauigkeit, sodass umfassende Überlegungen zur Bestimmung der Länge erforderlich sind jedes Segments.
Der Autor geht davon aus, dass die angemessene Länge jedes Absatzes 500-2000 Token beträgt und die im Experiment verwendete Länge 1000 Token beträgt.
Dann fasst das Modell den Inhalt dieser Blattknoten erneut rekursiv zusammen, um „Nicht-Blattknoten“(Nicht-Blattknoten, summ7-8) zu bilden.
Ein weiterer Unterschied zwischen den beiden besteht darin, dass Blattknoten Originalinformationen enthalten, während Nicht-Blattknoten nur Sekundärinformationen enthalten, die durch zusammengefasst werden.
In Bezug auf die Funktion werden Nicht-Blattknoten zum Navigieren und Lokalisieren der Blattknoten verwendet, in denen sich die Antwort befindet, während die Blattknoten zum Nachdenken über die Antwort verwendet werden.
Die Nicht-Blattknoten können mehrere Ebenen haben, und das Modell wird schrittweise zusammengefasst, bis der „Wurzelknoten“ erhalten wird, um eine vollständige Baumstruktur zu bilden.
Nachdem der Speicherbaum erstellt wurde, können Sie in die Navigationsabrufphase eintreten, um Antworten zu generieren.
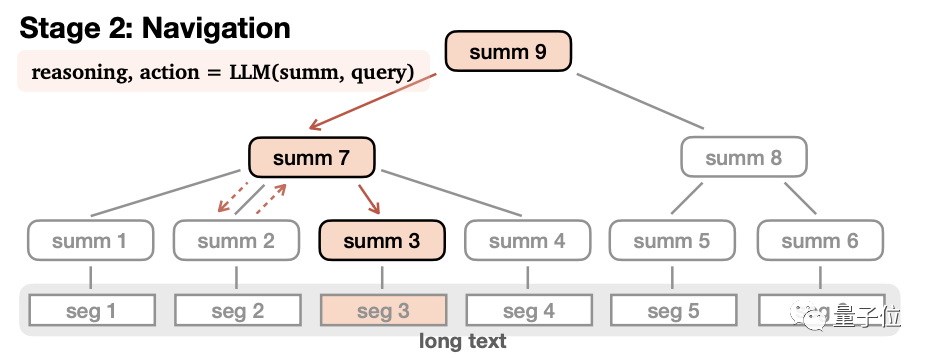
In diesem Prozess beginnt das Modell am Wurzelknoten, liest nacheinander den Inhalt der Unterknoten der ersten Ebene und leitet dann ab, ob dieser Knoten betreten oder zurückgegeben werden soll.
Nachdem Sie sich entschieden haben, diesen Knoten einzugeben, wiederholen Sie den Vorgang erneut, bis der Blattknoten gelesen ist. Wenn der Inhalt des Blattknotens geeignet ist, wird die Antwort generiert, andernfalls wird sie zurückgegeben. Um die Vollständigkeit der Antwort sicherzustellen, besteht die Endbedingung dieses Prozesses nicht darin, dass ein geeigneter Blattknoten gefunden wird, sondern dass das Modell davon ausgeht, dass eine vollständige Antwort erhalten wird oder die maximale Anzahl von Schritten erreicht wird. Wenn das Modell während des Navigationsvorgangs feststellt, dass es den falschen Pfad eingegeben hat, kann es auch zurück navigieren.Darüber hinaus führt MemWalker auch einen Arbeitsspeichermechanismus ein, um die Genauigkeit zu verbessern.
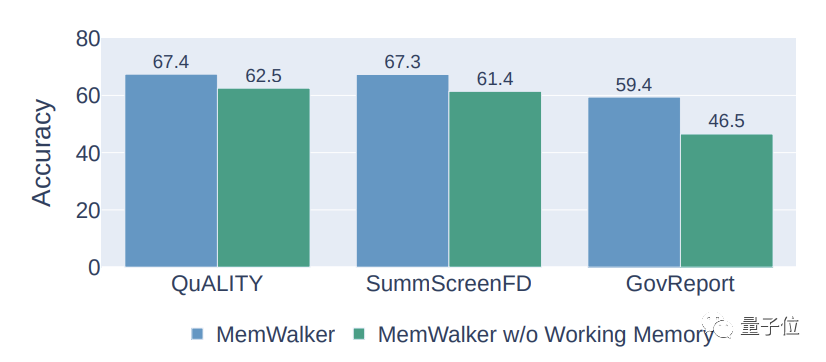
Dieser Mechanismus fügt den Inhalt des besuchten Knotens dem Kontext des aktuellen Inhalts hinzu.
Wenn das Modell einen neuen Knoten betritt, wird der aktuelle Knoteninhalt dem Speicher hinzugefügt.
Dieser Mechanismus ermöglicht es dem Modell, bei jedem Schritt den Inhalt der besuchten Knoten zu nutzen, um den Verlust wichtiger Informationen zu vermeiden.
Experimentelle Ergebnisse zeigen, dass der Arbeitsgedächtnismechanismus die Genauigkeit von MemWalker um etwa 10 % steigern kann.
Darüber hinaus kann der oben genannte Prozess nur abgeschlossen werden, indem man sich auf Eingabeaufforderungen verlässt, und es ist keine zusätzliche Schulung erforderlich.

Theoretisch kann MemWalker unendlich lange Texte lesen, solange er über genügend Rechenleistung verfügt.
Allerdings nimmt die zeitliche und räumliche Komplexität der Speicherbaumkonstruktion mit zunehmender Textlänge exponentiell zu.
Über den Autor
Der Erstautor des Artikels ist Howard Chen, ein chinesischer Doktorand am NLP-Labor der Princeton University.
Die Absolventin der Tsinghua Yao-Klasse, Chen Danqi, ist Howards Mentorin, und ihr akademischer Bericht über ACL in diesem Jahr bezog sich auch auf die Suche.
Dieses Ergebnis wurde von Howard während seines Praktikums bei Meta Ramakanth Pasunuru vervollständigt. Jason Weston und Asli Celikyilmaz, drei Wissenschaftler des Meta AI Laboratory, nahmen ebenfalls an diesem Projekt teil.
Papieradresse: https://arxiv.org/abs/2310.05029
Das obige ist der detaillierte Inhalt vonLange Texte können mit einer Fensterlänge von 4 KB gelesen werden. Chen Danqi und seine Schüler haben gemeinsam mit Meta eine neue Methode zur Verbesserung des Gedächtnisses großer Modelle eingeführt.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Die C-Sprache kann beim Aufrufen der Funktion in main keinen Bezeichner finden
- Mit welcher Software können AI-Dateien geöffnet und bearbeitet werden?
- Implementieren Sie Edge-Training mit weniger als 256 KB Speicher, und die Kosten betragen weniger als ein Tausendstel von PyTorch
- Eine systematische Überprüfung des Deep Reinforcement Learning vor dem Training sowie Online- und Offline-Forschung ist ausreichend.
- Maßgeschneidertes Training von Deep-Learning-Modellen mithilfe von Transfer-Learning-Techniken