
Heim >Technologie-Peripheriegeräte >KI >In der AIGC-Ära veröffentlichten Fudan und andere Teams die erste Überprüfung des Videodiffusionsmodells auf diesem Gebiet
In der AIGC-Ära veröffentlichten Fudan und andere Teams die erste Überprüfung des Videodiffusionsmodells auf diesem Gebiet

- 王林nach vorne
- 2023-10-23 14:13:091430Durchsuche
KI-generierte Inhalte sind zu einem der heißesten Themen im aktuellen Bereich der künstlichen Intelligenz geworden und stellen die Spitzentechnologie in diesem Bereich dar. In den letzten Jahren hat der Bereich der KI-Bilderzeugung und -bearbeitung mit der Veröffentlichung neuer Technologien wie Stable Diffusion, DALL-E3 und ControlNet atemberaubende visuelle Effekte erzielt und sowohl in der Wissenschaft als auch in der Industrie große Aufmerksamkeit und Diskussion erhalten. Die meisten dieser Methoden basieren auf Diffusionsmodellen, was der Schlüssel zu ihrer Fähigkeit ist, eine leistungsstarke steuerbare Erzeugung, fotorealistische Erzeugung und Diversität zu erreichen.
Im Vergleich zu einfachen statischen Bildern verfügen Videos jedoch über umfangreichere semantische Informationen und dynamische Änderungen. Videos können die dynamische Entwicklung physischer Objekte zeigen, daher sind die Anforderungen und Herausforderungen im Bereich der Videogenerierung und -bearbeitung komplexer. Obwohl die Forschung zur Videogenerierung in diesem Bereich aufgrund der begrenzten annotierten Daten und Rechenressourcen auf Schwierigkeiten stößt, haben einige repräsentative Forschungsarbeiten, wie z. B. Make-A-Video, Imagen Video und Gen-2-Methoden, bereits begonnen über die beherrschende Stellung.
Diese Forschungsarbeiten geben die Entwicklungsrichtung der Videoerzeugungs- und Bearbeitungstechnologie vor. Forschungsdaten zeigen, dass die Forschungsarbeiten zu Diffusionsmodellen für Videoaufgaben seit 2022 ein explosionsartiges Wachstum verzeichnet haben. Dieser Trend spiegelt nicht nur die Beliebtheit von Videodiffusionsmodellen in Wissenschaft und Industrie wider, sondern unterstreicht auch die dringende Notwendigkeit, dass Forscher auf diesem Gebiet weiterhin Durchbrüche und Innovationen in der Videoerzeugungstechnologie erzielen.
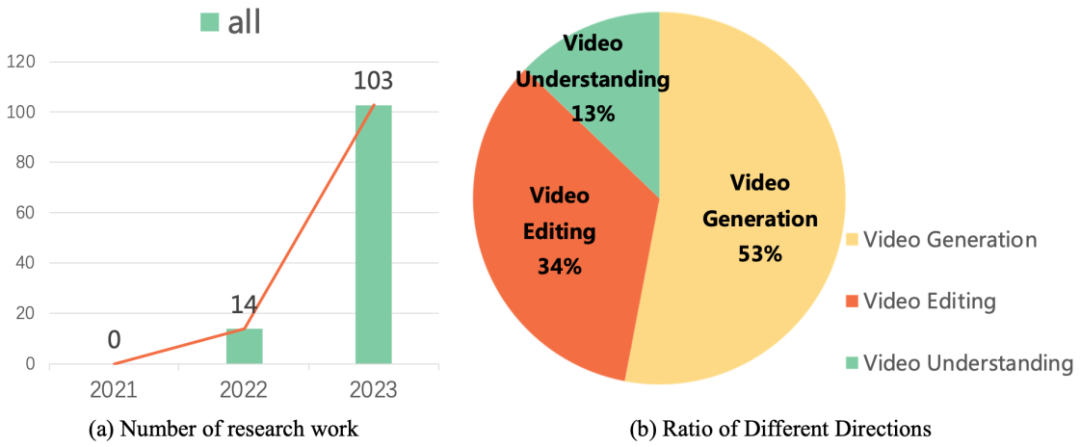
Kürzlich hat das Vision and Learning Laboratory der Fudan-Universität zusammen mit Microsoft, Huawei und anderen akademischen Institutionen die erste Überprüfung der Arbeit von Diffusionsmodellen zu Videoaufgaben veröffentlicht und die Anwendung systematisch sortiert von Diffusionsmodellen in der Videogenerierung, Video Akademische Spitzenergebnisse in der Bearbeitung und im Videoverständnis.

- Papierlink: https://arxiv.org/abs/2310.10647
- Homepage-Link: https://github.com/ChenHsing/Awesome-Video-Diffusion-Models
Videogenerierung
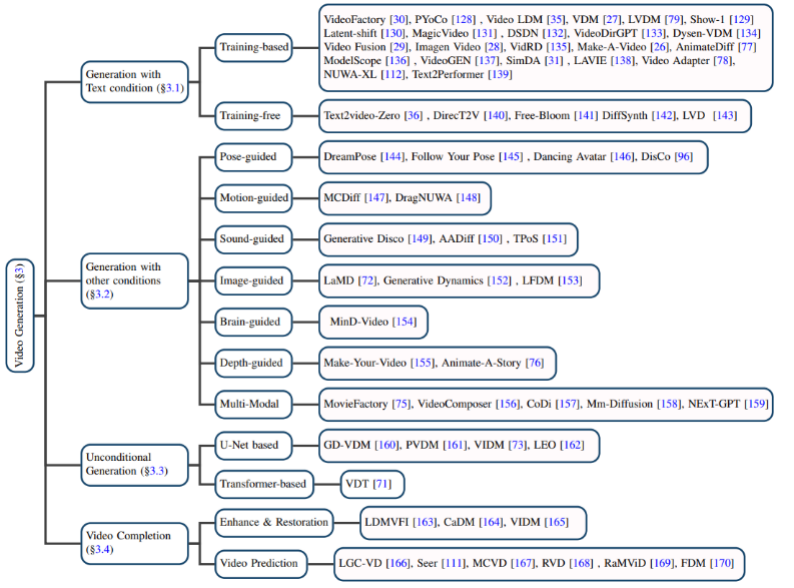
Textbasierte Videogenerierung: Die Videogenerierung mit natürlicher Sprache als Eingabe ist eine der wichtigsten Aufgaben im Bereich der Videogenerierung. Der Autor überprüft zunächst die Forschungsergebnisse in diesem Bereich, bevor das Diffusionsmodell vorgeschlagen wurde, und stellt dann trainingsbasierte bzw. trainingsfreie Text-Video-Generierungsmodelle vor.

Weihnachtsbaumfeiertagsfeier Winterschneeanimation.
Videogenerierung basierend auf anderen Bedingungen: Videogenerierungsarbeit in Nischenbereichen. Der Autor klassifiziert sie anhand der folgenden Bedingungen: Pose (posegesteuert), Aktion (bewegungsgesteuert), Ton (tongesteuert), Bild (bildgesteuert), Tiefenkarte (tiefengesteuert) usw.


Bedingungslose Videogenerierung: Diese Aufgabe bezieht sich auf die Videogenerierung ohne Eingabebedingungen in einem bestimmten Bereich, der Autor ist hauptsächlich in U-Net unterteilt basierendes und Transformer-basiertes generatives Modell.
Videovervollständigung: Beinhaltet hauptsächlich Videoverbesserung und -wiederherstellung, Videovorhersage und andere Aufgaben.
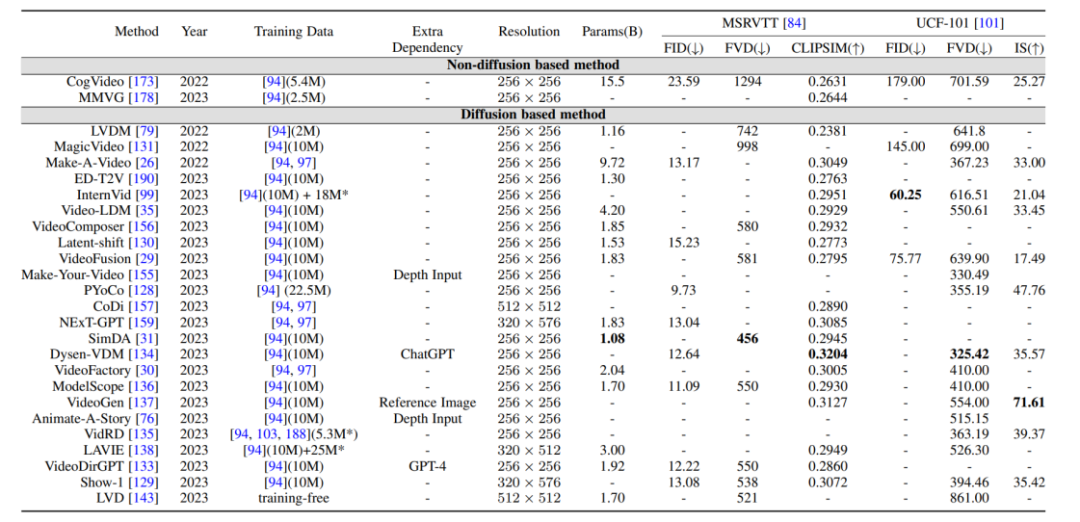
Datensatz: Der in der Videogenerierungsaufgabe verwendete Datensatz kann in die folgenden zwei Kategorien unterteilt werden:
1.Untertitelebene: Jedes Video verfügt über entsprechende Textbeschreibungsinformationen und das letzte Am repräsentativsten ist der WebVid10M-Datensatz.
2.Kategorieebene: Videos haben nur Klassifizierungsbezeichnungen, aber keine Textbeschreibungsinformationen. UCF-101 ist derzeit der am häufigsten verwendete Datensatz für Aufgaben wie Videogenerierung und Videovorhersage.
Vergleich der Bewertungsindikatoren und -ergebnisse: Die durch das Video generierten Bewertungsindikatoren sind hauptsächlich in Bewertungsindikatoren auf Qualitätsebene und Bewertungsindikatoren auf quantitativer Ebene unterteilt. Die Bewertungsindikatoren auf Qualitätsebene basieren hauptsächlich auf manueller Subjektivität Bewertung, während die quantitativen Bewertungsindikatoren auf Bildebene unterteilt werden können in:
1 Bewertungsindikatoren auf Bildebene: Das Video besteht aus einer Reihe von Bildrahmen, daher bezieht sich die Bewertungsmethode auf Bildebene im Wesentlichen auf die Bewertungsindikatoren des T2I-Modells.
2. Bewertungsindikatoren auf Videoebene: Im Vergleich zu Bewertungsindikatoren auf Bildebene, die stärker auf die Einzelbildmessung ausgerichtet sind, können Bewertungsindikatoren auf Videoebene Aspekte wie die zeitliche Kohärenz des generierten Videos messen.
Darüber hinaus hat der Autor auch einen horizontalen Vergleich der Bewertungsindikatoren der oben genannten generativen Modelle anhand des Benchmark-Datensatzes durchgeführt.
Videobearbeitung
Durch Durchsicht vieler Studien stellte der Autor fest, dass das Hauptziel der Videobearbeitung darin besteht, Folgendes zu erreichen:
1 Bearbeitete Videoframes sollten inhaltlich mit dem Originalvideo übereinstimmen.
2. Ausrichtung: Das bearbeitete Video muss an den Eingabebedingungen ausgerichtet sein.
3. Hohe Qualität: Das bearbeitete Video sollte stimmig und von hoher Qualität sein.
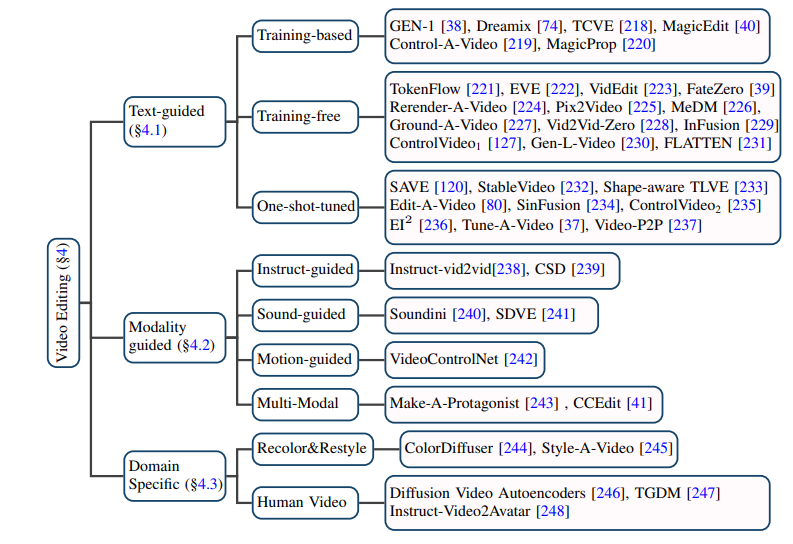
Textbasierte Videobearbeitung: Angesichts des begrenzten Umfangs vorhandener Text-Video-Daten neigen die meisten aktuellen textbasierten Videobearbeitungsaufgaben dazu, vorab trainierte T2I-Modelle zu verwenden und auf dieser Grundlage Videoframes Kohärenzprobleme zu lösen und semantische Inkonsistenz. Der Autor unterteilt solche Aufgaben weiter in trainingsbasierte, trainingsfreie und One-Shot-Tuned-Methoden und fasst diese jeweils zusammen.


Videobearbeitung basierend auf anderen Bedingungen: Mit dem Aufkommen der Ära großer Modelle besteht sie neben den direktesten Informationen in natürlicher Sprache als bedingter Videobearbeitung aus Anweisungen, Sounds, Aktionen, Multi-Mode-Videobearbeitung mit Status und anderen Bedingungen als Bedingung erhält immer mehr Aufmerksamkeit, und der Autor hat auch die entsprechenden Arbeiten klassifiziert und sortiert.
Videobearbeitung in bestimmten Nischenbereichen: Einige Arbeiten konzentrieren sich auf die Notwendigkeit einer speziellen Anpassung von Videobearbeitungsaufgaben in bestimmten Bereichen, wie z. B. Videokolorierung, Porträtvideobearbeitung usw.
Videoverständnis
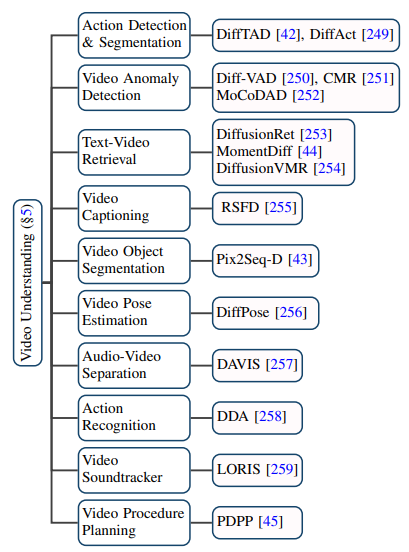
Die Anwendung des Diffusionsmodells im Videobereich geht weit über herkömmliche Videogenerierungs- und -bearbeitungsaufgaben hinaus. Es hat auch großes Potenzial bei Videoverständnisaufgaben gezeigt. Durch die Verfolgung aktueller Veröffentlichungen fasste der Autor zehn bestehende Anwendungsszenarien zusammen, z. B. zeitliche Videosegmentierung, Erkennung von Videoanomalien, Segmentierung von Videoobjekten, Text-Video-Abruf und Aktionserkennung.
Zukunft und Zusammenfassung
Diese Rezension fasst die neuesten Forschungsergebnisse zu Videoaufgaben im Diffusionsmodell in der AIGC-Ära umfassend und akribisch zusammen. Entsprechend den Forschungsobjekten und technischen Merkmalen handelt es sich um mehr als hundert hochmoderne Arbeiten Diese Modelle werden anhand einiger klassischer Benchmarks klassifiziert und zusammengefasst. Darüber hinaus bringt das Diffusionsmodell auch einige neue Forschungsrichtungen und Herausforderungen im Bereich Videoaufgaben mit sich, wie zum Beispiel:
1 Umfangreiche Sammlung von Text-Video-Datensätzen: Der Erfolg des T2I-Modells ist untrennbar mit Hunderten verbunden von Millionen hochwertiger Daten. Ebenso benötigt das T2V-Modell als Unterstützung eine große Menge wasserzeichenfreier, hochauflösender Text-Video-Daten.
2. Effizientes Training und Inferenz: Im Vergleich zu Bilddaten sind Videodaten enorm umfangreich und die in der Trainings- und Inferenzphase erforderliche Rechenleistung hat ebenfalls exponentiell zugenommen. Effiziente Trainings- und Inferenzalgorithmen können die Kosten erheblich senken.
3. Zuverlässige Benchmarks und Bewertungsindikatoren: Die vorhandenen Bewertungsindikatoren im Videobereich messen häufig den Unterschied in der Verteilung zwischen dem generierten Video und dem Originalvideo, können jedoch die Qualität des generierten Videos nicht vollständig messen. Gleichzeitig sind Benutzertests immer noch eine der wichtigen Bewertungsmethoden, da sie viel Personal erfordern und sehr subjektiv sind. Daher besteht ein dringender Bedarf an objektiveren und umfassenderen Bewertungsindikatoren.
Das obige ist der detaillierte Inhalt vonIn der AIGC-Ära veröffentlichten Fudan und andere Teams die erste Überprüfung des Videodiffusionsmodells auf diesem Gebiet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Auf welches Modell bezieht sich die 7-schichtige Netzwerkstruktur?
- So kopieren Sie ein Modell in eine andere Datei in 3dmax
- Implementieren Sie Edge-Training mit weniger als 256 KB Speicher, und die Kosten betragen weniger als ein Tausendstel von PyTorch
- Musk kündigt an, dass er Microsoft wegen der Verwendung von Twitter-Daten zum Trainieren künstlicher Intelligenz verklagen wird
- Meta wirft die KI kontinuierlich, um den ultimativen Zug zu beschleunigen! Der erste KI-Inferenzchip, KI-Supercomputer, der speziell für das Training großer Modelle entwickelt wurde