
Heim >Technologie-Peripheriegeräte >KI >Wie können Code und Experimente in der wissenschaftlichen Deep-Learning-Forschung effizient verwaltet werden?
Wie können Code und Experimente in der wissenschaftlichen Deep-Learning-Forschung effizient verwaltet werden?

- PHPznach vorne
- 2023-10-23 11:21:011490Durchsuche
Antwort 1
Autor: Ye Xiaofei
Link: https://www.zhihu.com/question/269707221/answer/2281374258
Als ich bei Mercedes-Benz in Nordamerika landete, gab es eine gewisse Zeit Um verschiedene Strukturen und Parameter zu testen, können mehr als hundert verschiedene Modelle in einer Woche trainiert werden Aus diesem Grund habe ich die Praktiken der Vorgänger des Unternehmens und meine eigenen Gedanken kombiniert, um eine Reihe effizienter Code-Experiment-Management-Methoden zusammenzufassen. was zur erfolgreichen Umsetzung des Projekts beigetragen hat. Jetzt teile ich es hier mit allen.
Verwenden Sie Yaml-Dateien, um Trainingsparameter zu konfigurieren
Ich weiß, dass viele Open-Source-Repos gerne Eingabe-Argparse verwenden, um viele Trainings- und modellbezogene Parameter zu übertragen, was eigentlich sehr ineffizient ist. Einerseits ist es mühsam, bei jedem Training eine große Anzahl von Parametern manuell einzugeben. Wenn Sie die Standardwerte direkt ändern und sie dann im Code ändern, wird viel Zeit verschwendet. Hier empfehle ich, dass Sie direkt eine Yaml-Datei verwenden, um alle modell- und trainingsbezogenen Parameter zu steuern und die Benennung des Yaml mit dem Modellnamen und dem Zeitstempel zu verknüpfen. Dies ist, was die berühmte 3D-Punktwolkenerkennungsbibliothek OpenPCDet wie folgt tut diesen Link. github.com/open-mmlab/OpenPCDet/blob/master/tools/cfgs/kitti_models/pointrcnn.yaml
Ich habe einen Teil der Yaml-Datei aus dem oben angegebenen Link abgeschnitten, wie in der Abbildung unten gezeigt, diese Konfiguration Die Datei umfasst die Vorverarbeitung von Punktwolken, Klassifizierungstypen, verschiedene Parameter des Backbones sowie die Auswahl von Optimierer und Verlust (in der Abbildung nicht dargestellt, vollständige Einzelheiten finden Sie im obigen Link). Mit anderen Worten:
Grundsätzlich sind alle Faktoren, die Ihr Modell beeinflussen können, in dieser Datei enthalten, und im Code müssen Sie nur ein einfaches yaml.load() verwenden, um alle diese Parameter in einem Diktat zu lesen. Noch wichtiger: Diese Konfigurationsdatei kann im selben Ordner wie Ihr Prüfpunkt gespeichert werden, sodass Sie sie direkt für das Breakpoint-Training, die Feinabstimmung oder das direkte Testen verwenden können. Sie ist auch sehr praktisch für die Verwendung zum Testen die entsprechenden Parameter.
 Codemodularisierung ist sehr wichtig
Codemodularisierung ist sehr wichtig
Einige Forscher koppeln beim Schreiben von Code gerne das gesamte System, indem sie beispielsweise die Verlustfunktion und das Modell zusammen schreiben, was häufig dazu führt, dass das gesamte System beeinträchtigt wird Ändern Sie einen bestimmten kleinen Teil, ändern sich auch die nachfolgenden Schnittstellen vollständig. Wenn der Code also gut modularisiert ist, können Sie viel Zeit sparen. Allgemeiner Deep-Learning-Code kann grundsätzlich in mehrere große Blöcke unterteilt werden (am Beispiel von Pytorch): I/O-Modul, Vorverarbeitungsmodul, Visualisierungsmodul, Modellkörper (wenn ein großes Modell Untermodelle enthält, sollte eine neue Klasse hinzugefügt werden) , Verlustfunktionen, Nachbearbeitung und verkettet in einem Trainings- oder Testskript. Ein weiterer Vorteil der Code-Modularisierung besteht darin, dass Sie damit verschiedene Parameter in Yaml definieren können, um das Lesen zu erleichtern. Darüber hinaus wird die Importlib-Bibliothek in vielen ausgereiften Codes verwendet. Sie ermöglicht es Ihnen, nicht zu bestimmen, welches Modell oder Untermodell während des Trainings im Code verwendet werden soll, sondern kann direkt in Yaml definiert werden.
Tensorboard, tqdm
Ich verwende diese beiden Bibliotheken grundsätzlich jedes Mal. Tensorboard kann die Änderungen in der Verlustkurve Ihres Trainings sehr gut verfolgen, sodass Sie leichter beurteilen können, ob das Modell immer noch konvergiert und überpasst. Wenn Sie bildbezogene Arbeiten ausführen, können Sie auch einige Visualisierungsergebnisse hinzufügen. Oftmals müssen Sie sich nur den Konvergenzstatus des Tensorboards ansehen, um grundsätzlich zu wissen, wie sich Ihr Modell verhält. Ist es notwendig, Zeit für separate Tests und Feinabstimmungen aufzuwenden? Hören Sie frühzeitig auf.Machen Sie Github voll aus.Egal, ob Sie gemeinsam mit mehreren Personen entwickeln oder an einem Einzelprojekt arbeiten, ich empfehle dringend, Github (das Unternehmen verwendet möglicherweise mehr oder weniger Bitbucket) zum Aufzeichnen Ihres Codes zu verwenden. Einzelheiten finden Sie in meiner Antwort: Welche wissenschaftlichen Forschungsinstrumente halten Sie als Doktorand für nützlich?https://www.zhihu.com/question/484596211/answer/2163122684
Zeichnen Sie die experimentellen Ergebnisse auf
Antwort 2
Autor: Jason Link: https://www.zhihu.com/question/269707221/answer/470576066
Git-Management-Code hat nichts mit Deep Learning oder wissenschaftlicher Forschung zu tun Verwenden Sie Versionsverwaltungstools. Ich persönlich bin der Meinung, dass es eine Frage der Wahl ist, ob man GitHub nutzt oder nicht. Schließlich ist es unmöglich, den gesamten Code im Unternehmen mit externem Git zu verknüpfen.
Andererseits glaube ich, dass Sie nach dem Testen von Tausenden von Versionen nicht wissen werden, welches Modell welche Parameter hat. Gute Gewohnheiten sind sehr effektiv. Versuchen Sie außerdem, Standardwerte für neu hinzugefügte Parameter bereitzustellen, um den Aufruf der alten Version der Konfigurationsdatei zu erleichtern.
2. Versuchen Sie, verschiedene Modelle so weit wie möglich zu entkoppeln.
Im selben Projekt ist eine gute Wiederverwendbarkeit eine sehr gute Programmiergewohnheit, aber in der sich schnell entwickelnden DL-Codierung wird davon ausgegangen, dass das Projekt aufgabengesteuert ist Dies kann manchmal ein Hindernis sein. Versuchen Sie daher, einige wiederverwendbare Funktionen zu extrahieren. Versuchen Sie in Bezug auf die Modellstruktur, verschiedene Modelle in verschiedene Dateien zu entkoppeln, um zukünftige Aktualisierungen komfortabler zu gestalten. Andernfalls werden einige scheinbar schöne Designs nach ein paar Monaten unbrauchbar.
3. Halten Sie ein gewisses Maß an Stabilität ein und verfolgen Sie regelmäßig neue Versionen des Frameworks.
Vom Anfang bis zum Ende eines Projekts wurde das Framework auf mehrere Versionen aktualisiert Die neue Version verfügt über einige köstliche Funktionen, aber leider haben sich einige APIs geändert. Daher können Sie versuchen, die Framework-Version innerhalb des Projekts stabil zu halten. Versuchen Sie, die Vor- und Nachteile verschiedener Versionen abzuwägen, bevor Sie mit dem Projekt beginnen.
Außerdem ein tolerantes Herz gegenüber unterschiedlichen Rahmenbedingungen haben.
4. Eine Trainingssitzung dauert nicht blind nach dem Codieren. Persönliche Erfahrung zeigt, dass es eine gute Wahl ist, mit kleinen Datenmengen und mehr Protokollen zu experimentieren.
5. Notieren Sie sich die Änderungen in der Modellaktualisierungsleistung, da Sie möglicherweise jederzeit zurückgehen und von vorne beginnen müssen.
Autor: OpenMMLab
Link: https://www.zhihu.com/question/269707221/answer/2480772257
Quelle: Zhihu
Das Urheberrecht liegt beim Autor. Für den kommerziellen Nachdruck wenden Sie sich bitte an den Autor, um eine Genehmigung einzuholen. Für den nichtkommerziellen Nachdruck geben Sie bitte die Quelle an.
Hallo Fragesteller, in der vorherigen Antwort wurde die Verwendung von Tensorboard, Weights&Biases, MLFlow, Neptune und anderen Tools zur Verwaltung experimenteller Daten erwähnt. Da jedoch immer mehr Räder für experimentelle Managementtools gebaut werden, werden die Kosten für das Erlernen der Tools immer höher. Wie sollten wir wählen?
MMCV erfüllt alle Ihre Fantasien und Sie können die Tools wechseln, indem Sie die Konfigurationsdatei ändern.
github.com/open-mmlab/mmcv
Tensorboard zeichnet experimentelle Daten auf:
Konfigurationsdatei:
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='TensorboardLoggerHook') ])
TensorBoard-Datenvisualisierungseffekt
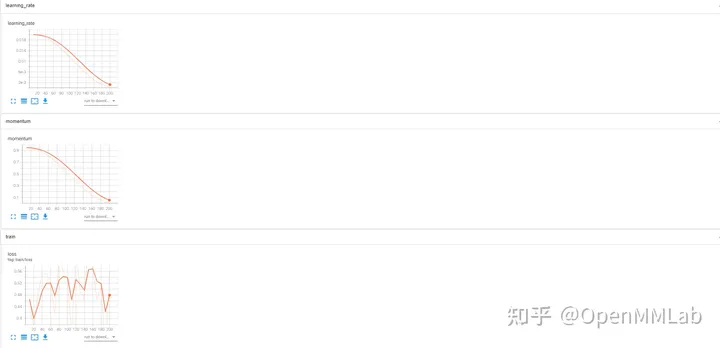
WandB zeichnet experimentelle Daten auf
Konfigurationsdatei
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='WandbLoggerHook') ])
Wandb-Datenvisualisierungseffekt
(Sie müssen sich vorab mit der Python-API bei wandb anmelden)
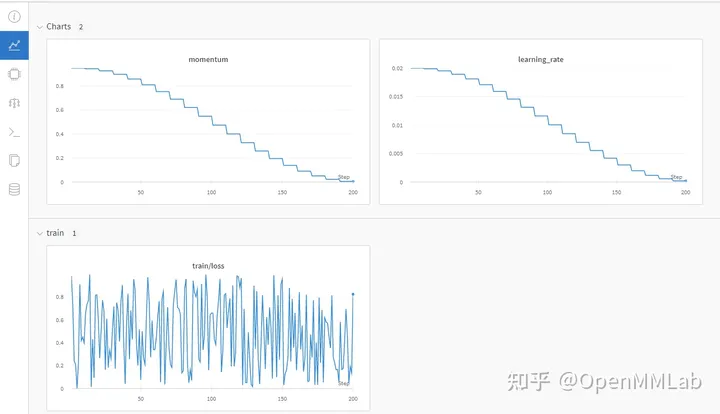
Neptume zeichnet experimentelle Daten auf
Konfigurationsdatei
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='NeptuneLoggerHook', init_kwargs=dict(project='Your Neptume account/mmcv')) ])
Neptume-Visualisierungseffekt
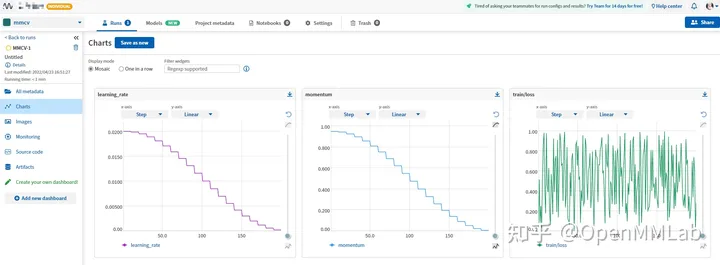
mlflow zeichnet experimentell auf Daten
Konfigurationsdatei
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='MlflowLoggerHook') ])
MLFlow-Visualisierung
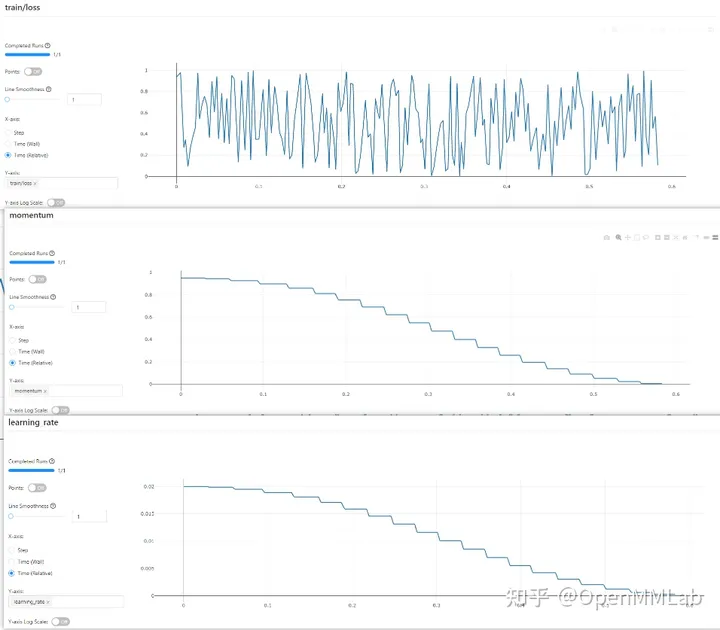
dvclive Experimentelle Daten aufzeichnen
Konfigurationsdatei
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='DvcliveLoggerHook') ])
Generierte HTML-Datei
Die oben Verwendet nur die grundlegendsten Funktionen verschiedener experimenteller Managementtools können wir das Profil weiter ändern, um weitere Posen freizuschalten.
Der Besitz von MMCV ist gleichbedeutend mit dem Besitz aller experimentellen Management-Tools. Wenn Sie zuvor ein TF-Junge waren, können Sie den klassischen nostalgischen Stil von TensorBoard wählen. Wenn Sie alle experimentellen Daten und die experimentelle Umgebung aufzeichnen möchten, können Sie es auch mit Wandb (Weights & Biases) oder Neptume versuchen Wenn Sie mit dem Internet verbunden sind, können Sie mlflow auswählen. Die experimentellen Daten werden lokal gespeichert und es gibt immer ein für Sie geeignetes Tool.
Darüber hinaus verfügt MMCV auch über ein eigenes Protokollverwaltungssystem, nämlich TextLoggerHook! Es speichert alle während des Trainingsprozesses generierten Informationen, wie Geräteumgebung, Datensatz, Modellinitialisierungsmethode, Verlust, Metrik und andere während des Trainings generierte Informationen, in der lokalen Datei xxx.log. Sie können frühere experimentelle Daten überprüfen, ohne Werkzeuge zu verwenden.
Sie fragen sich immer noch, welches Experiment-Management-Tool Sie verwenden sollen? Sind Sie immer noch besorgt über die Lernkosten verschiedener Tools? Beeilen Sie sich und steigen Sie in MMCV ein und erleben Sie verschiedene Tools problemlos mit nur wenigen Zeilen Konfigurationsdateien.
github.com/open-mmlab/mmcv
Das obige ist der detaillierte Inhalt vonWie können Code und Experimente in der wissenschaftlichen Deep-Learning-Forschung effizient verwaltet werden?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie viel wissen Sie über die Trägheitsnavigationstechnologie für autonomes Fahren?
- Überblick über das Technologie-Framework für autonomes Fahren
- Der „Graspflanzungs'-Mechanismus von Xiaohongshu wird zum ersten Mal entschlüsselt: Wie groß angelegte Deep-Learning-Systemtechnologie angewendet wird
- Basierend auf PyTorch ist die benutzerfreundliche, feinkörnige Bilderkennungs-Deep-Learning-Tool-Bibliothek Hawkeye Open Source
- Plötzlich! Li Feifeis Lehrling Karpathy ist zurückgetreten. Wird Teslas autonomes Fahren ausgesetzt?