
Heim >Technologie-Peripheriegeräte >KI >Mit GPT-4 hat der Roboter gelernt, Stifte zu drehen und Walnüsse zu tellern.
Mit GPT-4 hat der Roboter gelernt, Stifte zu drehen und Walnüsse zu tellern.

- PHPznach vorne
- 2023-10-21 14:17:011194Durchsuche
In Bezug auf das Lernen ist GPT-4 ein großartiger Schüler. Nachdem es eine große Menge menschlicher Daten verdaut hat, beherrscht es verschiedene Kenntnisse und kann sogar den Mathematiker Terence Tao in Chats inspirieren.
Gleichzeitig ist es auch ein hervorragender Lehrer geworden, der nicht nur Buchwissen vermittelt, sondern dem Roboter auch das Drehen von Stiften beibringt.

Der Roboter heißt Eureka und ist ein Ergebnis der Forschung von NVIDIA, der University of Pennsylvania, dem California Institute of Technology und der University of Texas at Austin. Diese Forschung kombiniert Forschung zu großen Sprachmodellen und verstärkendem Lernen: GPT-4 wird verwendet, um die Belohnungsfunktion zu verfeinern, und verstärkendes Lernen wird verwendet, um Robotersteuerungen zu trainieren.
Mit der Fähigkeit, Code in GPT-4 zu schreiben, verfügt Eureka über hervorragende Designfunktionen für Belohnungsfunktionen. Seine unabhängig generierten Belohnungen sind in 83 % der Aufgaben besser als die von menschlichen Experten. Diese Fähigkeit ermöglicht es Robotern, viele Aufgaben zu erledigen, die vorher nicht einfach zu erledigen waren, wie zum Beispiel das Drehen von Stiften, das Öffnen von Schubladen und Schränken, das Werfen und Fangen von Bällen, das Dribbeln und das Bedienen von Scheren. Dies geschieht jedoch vorerst alles in einer virtuellen Umgebung.



Darüber hinaus implementiert Eureka eine neue Art von kontextbezogenem RLHF, das in der Lage ist, Feedback in natürlicher Sprache von menschlichen Bedienern zu integrieren, um Belohnungsfunktionen zu steuern und auszurichten. Es kann leistungsstarke Hilfsfunktionen für Roboteringenieure bereitstellen und Ingenieuren dabei helfen, komplexe Bewegungsverhalten zu entwerfen. Jim Fan, ein leitender KI-Wissenschaftler bei NVIDIA und einer der Autoren des Papiers, verglich diese Forschung mit „Voyager (der von den Vereinigten Staaten entwickelten und gebauten Raumsonde für die äußere Galaxie) im Physik-Simulator-API-Raum.“

Es ist erwähnenswert, dass diese Forschung vollständig Open Source ist. Die Open-Source-Adresse lautet wie folgt:

- Papierlink: https://arxiv.org/pdf/2310.12931 .pdf
- Projektlink: https://eureka-research.github.io/
- Code-Link: https://github.com/eureka-research/Eureka
Papierübersicht
Große Sprachmodelle (LLMs) zeichnen sich durch semantische Planung auf hoher Ebene für Roboteraufgaben aus (z. B. Googles SayCan, RT-2-Roboter), können aber auch zum Erlernen komplexer Manipulationsaufgaben auf niedriger Ebene verwendet werden, z Federumdrehen, immer noch eine offene Frage. Bestehende Versuche erfordern umfangreiches Fachwissen zum Erstellen von Aufgabenaufforderungen oder erlernen nur einfache Fertigkeiten und bleiben weit hinter der menschlichen Flexibilität zurück.

Googles RT-2-Roboter.
Auf der anderen Seite hat Reinforcement Learning (RL) beeindruckende Ergebnisse in Bezug auf Flexibilität und viele andere Aspekte erzielt (z. B. die Rubik’s Cube-spielende Roboterhand von OpenAI), erfordert jedoch, dass menschliche Designer die Belohnungsfunktion sorgfältig konstruieren, genau kodifizieren und bereitstellen Lernsignale für gewünschtes Verhalten. Da viele Aufgaben des verstärkenden Lernens in der realen Welt nur spärliche Belohnungen bieten, die schwer zum Lernen zu verwenden sind, ist in der Praxis eine Belohnungsformung erforderlich, um progressive Lernsignale bereitzustellen. Trotz ihrer Bedeutung ist die Belohnungsfunktion bekanntermaßen schwierig zu gestalten. Eine kürzlich durchgeführte Umfrage ergab, dass 92 % der befragten Forscher und Praktiker des Reinforcement Learning angaben, bei der Gestaltung von Belohnungen manuelles Ausprobieren zu betreiben, und 89 % sagten, die von ihnen entworfenen Belohnungen seien suboptimal und führten zu unbeabsichtigtem Verhalten.
Angesichts der Tatsache, dass das Design von Belohnungen so wichtig ist, kommen wir nicht umhin zu fragen: Ist es möglich, einen allgemeinen Algorithmus zur Belohnungsprogrammierung unter Verwendung modernster Codierungs-LLM (wie GPT-4) zu entwickeln? Diese LLMs weisen eine hervorragende Leistung beim Schreiben von Code, bei der Zero-Shot-Generierung und beim Lernen im Kontext auf und haben die Leistung von Programmieragenten erheblich verbessert. Im Idealfall sollten solche Belohnungsdesign-Algorithmen über Funktionen zur Belohnungsgenerierung auf menschlicher Ebene verfügen, auf eine Vielzahl von Aufgaben skalierbar sein, den langwierigen Versuch-und-Irrtum-Prozess ohne menschliche Aufsicht automatisieren und gleichzeitig mit menschlicher Aufsicht kompatibel sein, um Sicherheit und Konsistenz zu gewährleisten .
Dieses Papier schlägt einen Belohnungsdesign-Algorithmus EUREKA (vollständiger Name ist Evolution-driven Universal REward Kit for Agent) vor, der von LLM gesteuert wird. Der Algorithmus hat die folgenden Erfolge erzielt:
1 Die Leistung des Belohnungsdesigns hat in 29 verschiedenen Open-Source-RL-Umgebungen menschliches Niveau erreicht, darunter 10 verschiedene Roboterformen (Vierbeinroboter, Quadrocopterroboter, Zweibeinroboter, Manipulatoren und mehrere). Geschickte Hände, siehe Abbildung 1. Ohne aufgabenspezifische Eingabeaufforderungen oder Belohnungsvorlagen übertrafen die automatisch generierten Belohnungen von EUREKA die Belohnungen menschlicher Experten bei 83 % der Aufgaben und erzielten eine durchschnittliche normalisierte Verbesserung

2 Die geschickten Bedienungsaufgaben, die zuvor durch manuelle Belohnungstechnik nicht zu erreichen waren, nehmen als Beispiel das Problem des Stiftdrehens. In diesem Fall muss die Hand den Stift entsprechend der voreingestellten Rotationskonfiguration schnell drehen Durch die Kombination von EUREKA mit Kurslernen demonstrierten die Forscher zum ersten Mal die Wirkungsweise der schnellen Stiftrotation an der simulierten anthropomorphen „Schattenhand“ (siehe unten in Abbildung 1). Bietet eine neue Gradienten-freie Kontext-Lernmethode für verstärktes Lernen basierend auf menschlichem Feedback (RLHF), die auf der Grundlage verschiedener Formen menschlicher Eingaben effizientere und auf den Menschen abgestimmte Bilder erzeugen kann. Das Papier zeigt, dass EUREKA kann von bestehenden menschlichen Belohnungsfunktionen profitieren und diese verbessern. Im Gegensatz zu früheren L2R-Arbeiten, die LLM-gestütztes Belohnungsdesign verwendeten, können sie auch menschliches Text-Feedback nutzen, um bei der Gestaltung von Belohnungsfunktionen zu helfen EUREKA verfügt über keine spezifischen Aufgabenaufforderungen, Belohnungsvorlagen und eine kleine Anzahl von Beispielen. Im Experiment schnitt EUREKA deutlich besser ab als L2R und profitierte von seiner Fähigkeit, freie, ausdrucksstarke Belohnungsprogramme zu erstellen und zu verfeinern Die Vielseitigkeit profitiert von drei wichtigen Algorithmus-Designoptionen: Umgebung als Kontext, evolutionäre Suche und Belohnungsreflexion Anschließend schlägt EUREKA iterativ eine Reihe von Belohnungskandidaten vor und verfeinert die vielversprechendsten Belohnungen innerhalb des LLM-Kontextfensters, wodurch die Belohnungsqualität erheblich verbessert wird Belohnungsreflexion, eine textliche Zusammenfassung der Belohnungsqualität basierend auf Richtlinienschulungsstatistiken Um sicherzustellen, dass EUREKA seine Belohnungssuche auf sein maximales Potenzial ausweiten kann, wird in IsaacGym GPU-beschleunigtes verteiltes Verstärkungslernen verwendet, um Zwischenbelohnungen zu bewerten, was eine Verbesserung der Richtlinienlerngeschwindigkeit um bis zu drei Größenordnungen ermöglicht. Dies macht EUREKA zu einem breiten Algorithmus, der sich auf natürliche Weise mit zunehmendem Rechenaufwand skaliert.
Wie in Abbildung 2 dargestellt. Die Forscher sind bestrebt, alle Eingabeaufforderungen, Umgebungen und generierten Belohnungsfunktionen als Open-Source-Lösung bereitzustellen, um die weitere Forschung zum LLM-basierten Belohnungsdesign zu erleichtern.
Einführung in die Methode
EUREKA kann den Belohnungsalgorithmus unabhängig schreiben.
 EUREKA besteht aus drei algorithmischen Komponenten: 1) Umgebung als Kontext, wodurch die Zero-Shot-Generierung ausführbarer Belohnungen unterstützt wird; 2) evolutionäre Suche, iteratives Vorschlagen und Verbessern von Belohnungskandidaten; 3) Belohnungsreflexion, die feinkörnige Belohnungsverbesserungen unterstützt .
EUREKA besteht aus drei algorithmischen Komponenten: 1) Umgebung als Kontext, wodurch die Zero-Shot-Generierung ausführbarer Belohnungen unterstützt wird; 2) evolutionäre Suche, iteratives Vorschlagen und Verbessern von Belohnungskandidaten; 3) Belohnungsreflexion, die feinkörnige Belohnungsverbesserungen unterstützt .
Umgebung als Kontext
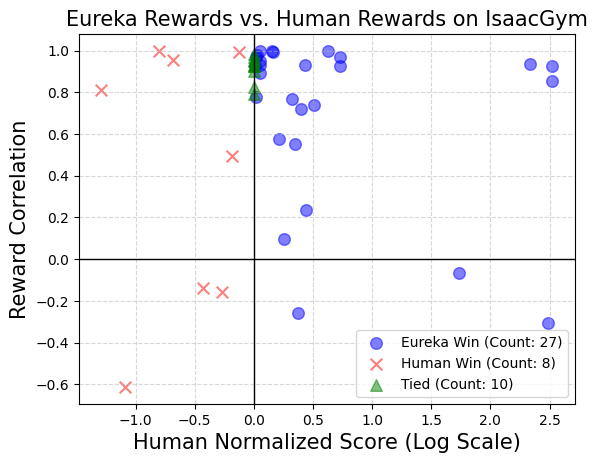
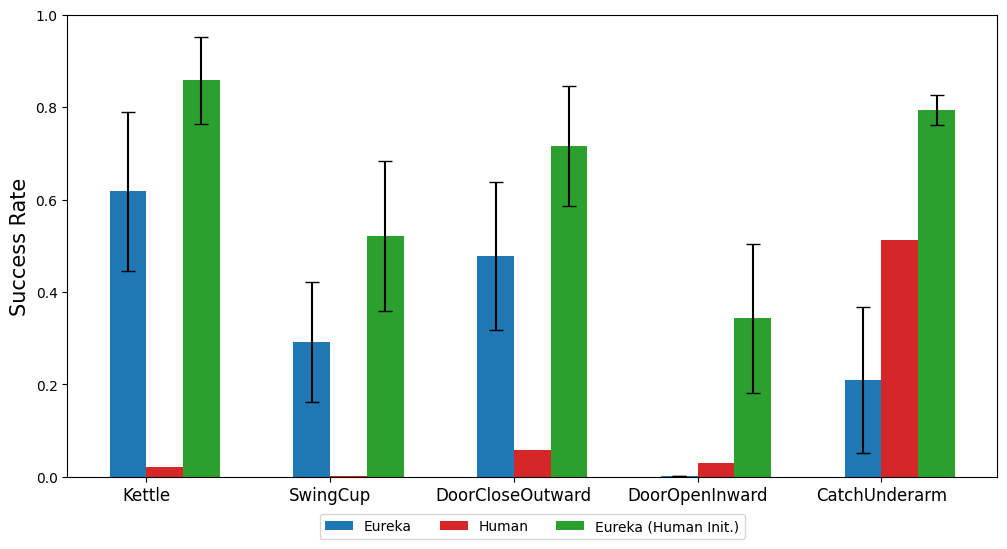
In diesem Artikel wird empfohlen, den ursprünglichen Umgebungscode direkt als Kontext bereitzustellen. Mit nur minimalen Anweisungen kann EUREKA Belohnungen in verschiedenen Umgebungen ohne Proben generieren. Ein Beispiel für die EUREKA-Ausgabe ist in Abbildung 3 dargestellt. EUREKA kombiniert fachmännisch vorhandene Beobachtungsvariablen (z. B. Fingerspitzenposition) innerhalb des bereitgestellten Umgebungscodes und erstellt einen gültigen Belohnungscode – und das alles ohne umgebungsspezifische Hinweistechnik oder Belohnungsvorlagen. Allerdings ist die generierte Belohnung möglicherweise nicht immer beim ersten Versuch ausführbar, und selbst wenn sie ausführbar ist, kann sie suboptimal sein. Dies wirft die Frage auf, wie man die Suboptimalität der Generierung von Einzelprobenbelohnungen effektiv überwinden kann. Evolutionäre Suche Dann stellt das Papier vor, wie die evolutionäre Suche die oben genannten Probleme suboptimaler Lösungen lösen kann. Sie werden so verfeinert, dass EUREKA in jeder Iteration mehrere unabhängige Ausgaben des LLM abtastet (Zeile 5 in Algorithmus 1). Da jede Iteration (Generationen) unabhängig und identisch verteilt ist, nimmt die Wahrscheinlichkeit von Fehlern in allen Belohnungsfunktionen in der Iteration mit zunehmender Anzahl von Stichproben exponentiell ab. Belohnungsreflexion Um eine komplexere und gezieltere Belohnungsanalyse bereitzustellen, schlägt dieser Artikel den Aufbau eines automatisierten Feedbacks vor, um die Dynamik der Richtlinienschulung im Text zusammenzufassen. Insbesondere angesichts der Tatsache, dass die EUREKA-Belohnungsfunktion einzelne Komponenten im Belohnungsprogramm erfordert (wie die Belohnungskomponenten in Abbildung 3), verfolgen wir die Skalarwerte aller Belohnungskomponenten an Zwischenkontrollpunkten der Richtlinie während des gesamten Trainingsprozesses. Obwohl es sehr einfach ist, einen solchen Belohnungsreflexionsprozess aufzubauen, ist diese Art des Aufbaus aufgrund der Abhängigkeiten des Belohnungsoptimierungsalgorithmus sehr wichtig. Das heißt, ob die Belohnungsfunktion effizient ist, wird durch die spezifische Wahl des RL-Algorithmus beeinflusst, und dieselbe Belohnung kann sich bei unterschiedlichen Hyperparametern selbst unter demselben Optimierer sehr unterschiedlich verhalten. Durch die detaillierte Beschreibung, wie RL-Algorithmen einzelne Belohnungskomponenten optimieren, ermöglicht die Belohnungsreflexion EUREKA, gezieltere Belohnungsänderungen vorzunehmen und Belohnungsfunktionen zu synthetisieren, die besser mit festen RL-Algorithmen harmonieren. Der experimentelle Teil führt eine umfassende Bewertung von Eureka durch, einschließlich seiner Fähigkeit, Belohnungsfunktionen zu generieren, seiner Fähigkeit, neue Aufgaben zu lösen, und seiner Fähigkeit, verschiedene menschliche Eingaben zu integrieren. Die experimentelle Umgebung umfasst 10 verschiedene Roboter und 29 Aufgaben, von denen diese 29 Aufgaben vom IsaacGym-Simulator umgesetzt werden. Die Experimente wurden unter Verwendung von 9 Originalumgebungen von IsaacGym (Isaac) durchgeführt und deckten eine Vielzahl von Robotermorphologien ab, von Vierbeinern, Zweibeinern, Quadrocoptern, Manipulatoren und geschickten Roboterhänden. Darüber hinaus gewährleistet das Papier eine tiefe Bewertung, indem es 20 Aufgaben aus dem Dexterity-Benchmark einbezieht. Eureka kann Belohnungsfunktionen auf übermenschlichem Niveau generieren. Bei 29 Aufgaben schnitt die Belohnungsfunktion von Eureka bei 83 % der Aufgaben besser ab als die von Experten geschriebene Belohnung, mit einer durchschnittlichen Verbesserung von 52 %. Insbesondere im hochdimensionalen Dexterity-Benchmark-Umfeld erzielt Eureka größere Zuwächse. Eureka ist in der Lage, die Prämiensuche so weiterzuentwickeln, dass die Prämien im Laufe der Zeit immer besser werden. Durch die Kombination einer groß angelegten Belohnungssuche mit detailliertem Feedback zur Belohnungsreflexion erzielt Eureka nach und nach bessere Belohnungen, die letztendlich das menschliche Niveau übertreffen. Eureka generiert auch neuartige Belohnungen. In diesem Artikel wird die Neuheit von Eureka-Belohnungen bewertet, indem die Korrelation zwischen Eureka-Belohnungen und menschlichen Belohnungen für alle Isaac-Aufgaben berechnet wird. Wie in der Abbildung gezeigt, generiert Eureka hauptsächlich schwach korrelierte Belohnungsfunktionen, die menschliche Belohnungsfunktionen übertreffen. Darüber hinaus stellen wir fest, dass die Eureka-Belohnung umso weniger relevant ist, je schwieriger die Aufgabe ist. In einigen Fällen korrelierten Eureka-Belohnungen sogar negativ mit menschlichen Belohnungen, übertrafen diese jedoch deutlich. Wenn Sie erkennen möchten, dass die geschickte Hand des Roboters den Stift weiter drehen kann, muss das Bedienprogramm möglichst viele Zyklen haben. Dieser Artikel befasst sich mit dieser Aufgabe, indem er (1) Eureka anweist, eine Belohnungsfunktion zu generieren, die zum Umleiten von Stiften in zufällige Zielkonfigurationen verwendet wird, und dann (2) Eureka-Belohnungen verwendet, um diese vorab trainierte Richtlinie zu verfeinern, um die gewünschte Drehung der Stiftsequenz zu erreichen Konfiguration. Wie in der Abbildung gezeigt, passte sich der Eureka-Spinner schnell an die Strategie an und rotierte erfolgreich viele Zyklen hintereinander. Im Gegensatz dazu können weder vorgefertigte noch von Grund auf erlernte Richtlinien einen einzelnen Rotationszyklus abschließen. In diesem Artikel wird auch untersucht, ob es für Eureka von Vorteil ist, mit der Initialisierung einer menschlichen Belohnungsfunktion zu beginnen. Wie gezeigt, verbessert Eureka menschliche Belohnungen und profitiert davon, unabhängig von deren Qualität. Eureka implementiert auch RLHF, das menschliches Feedback kombinieren kann, um Belohnungen zu ändern und so den Agenten schrittweise zu sichereren und menschenähnlicheren Verhaltensweisen zu führen. Das Beispiel zeigt, wie Eureka einem humanoiden Roboter beibringt, aufrecht zu laufen, mit menschlichem Feedback, das die bisherige automatische Belohnungsreflexion ersetzt. Humanoider Roboter lernt durch Eureka den Laufgang. Weitere Informationen finden Sie im Originalpapier. 




Experiment





Das obige ist der detaillierte Inhalt vonMit GPT-4 hat der Roboter gelernt, Stifte zu drehen und Walnüsse zu tellern.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!