
Heim >Technologie-Peripheriegeräte >KI >Große Veröffentlichung, „gehirnähnliche Wissenschaft' oder die optimale Lösung für das Problem des Rechenleistungsverbrauchs und der Kontextlänge eines großen Sprachmodells künstlicher Intelligenz!
Große Veröffentlichung, „gehirnähnliche Wissenschaft' oder die optimale Lösung für das Problem des Rechenleistungsverbrauchs und der Kontextlänge eines großen Sprachmodells künstlicher Intelligenz!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-10-20 17:25:03928Durchsuche
Bei einem großen Science-Fiction-Ereignis erstrahlt Science-Fiction plötzlich in der Realität.
Kürzlich veranstalteten die Shenzhen University of Technology Education Foundation und der Science and Fantasy Growth Fund am Shenzhen Advanced Institute eine Veranstaltung zum Thema Science-Fiction und KI. Ein Team aus Shenzhen namens Luxi Technology hat sein großes Sprachmodell für künstliche Intelligenz – NLM (Neuromorphic Generative Pre-trained Language Model) – zum ersten Mal öffentlich veröffentlicht, ein großes Sprachmodell, das nicht auf Transformer basiert.
Im Gegensatz zu vielen großen Modellen im In- und Ausland basiert dieses Team auf gehirnähnlicher Wissenschaft und gehirnähnlicher Intelligenz, integriert gleichzeitig die Eigenschaften wiederkehrender neuronaler Netze und entwickelt große Sprachmodelle, die von den effizienten Recheneigenschaften des Gehirns inspiriert sind .
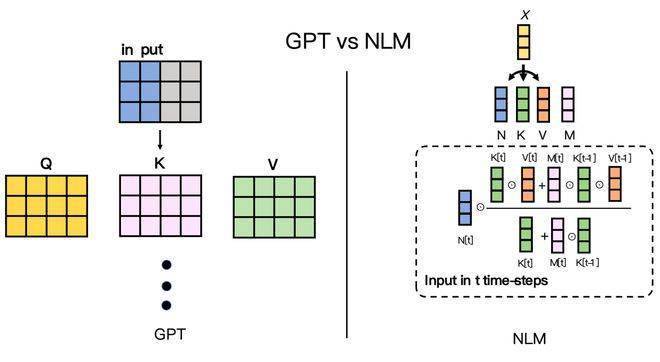
Was noch erstaunlicher ist, ist, dass der Rechenleistungsverbrauch dieses Modells bei gleicher Parameterebene 1/22 der Transformer-Architektur beträgt. Auch auf die Frage der Kontextlänge hat NLM eine perfekte Antwort gegeben: Das Kontextlängenfenster kann unbegrenzt erreicht werden Wachstum, sei es die 2-KB-Grenze von Open Source LLM oder andere Kontextlängenbeschränkungen von 32 KB oder 100 KB, ist kein Problem.
Was ist gehirninspiriertes Computing?
Brain-like Computing ist ein Computermodell, das die Struktur und Funktion des menschlichen Gehirns nachahmt. Es simuliert die neuronalen Netzwerkverbindungen des menschlichen Gehirns in Bezug auf Architektur, Designprinzipien und Informationsverarbeitungsmethoden. Diese Art der Berechnung geht über den bloßen Versuch hinaus, die Oberflächeneigenschaften biologischer neuronaler Netze zu simulieren, sondern beschäftigt sich intensiv mit der Simulation des grundlegenden Aufbaus biologischer neuronaler Netze, d. h. der Verarbeitung und Speicherung von Sequenzinformationen durch groß angelegte Verbindungen von Neuronen und Synapsen .
Im Gegensatz zu herkömmlichen regelbasierten Algorithmen ist das vom Gehirn inspirierte Computing auf eine große Anzahl miteinander verbundener neuronaler Netze angewiesen, um autonom zu lernen und Informationen zu extrahieren, genau wie das menschliche Gehirn. Dieser Ansatz ermöglicht es Computersystemen, aus Erfahrungen zu lernen, sich an neue Situationen anzupassen, komplexe Muster zu verstehen und erweiterte Entscheidungen und Vorhersagen zu treffen.
Aufgrund ihrer hohen Anpassungsfähigkeit und parallelen Verarbeitungsfähigkeiten haben vom Gehirn inspirierte Computersysteme eine äußerst hohe Effizienz und Genauigkeit bei der Verarbeitung großer Datenmengen, der Bild- und Spracherkennung, der Verarbeitung natürlicher Sprache und anderen Bereichen gezeigt. Diese Systeme können nicht nur komplexe und sich ändernde Informationen schnell verarbeiten, sondern ihr Energieverbrauch und ihre Rechenressourcen sind auch weitaus geringer als bei herkömmlichen Computerarchitekturen, da sie keine umfangreiche Vorprogrammierung und Dateneingabe erfordern.
Im Allgemeinen eröffnet gehirninspiriertes Computing ein neues Computing-Paradigma. Es geht über traditionelle künstliche neuronale Netze hinaus und bewegt sich hin zu fortschrittlichen intelligenten Systemen, die selbst lernen, sich selbst organisieren und sogar über ein gewisses Maß an Selbstbewusstsein verfügen können.
Die Weiterentwicklung großer, vom Gehirn inspirierter Modelle
Bei der Veranstaltung erläuterte Dr. Zhou Peng aus Lu Xis Team ausführlich den Implementierungsmechanismus des großen gehirnähnlichen Modells.
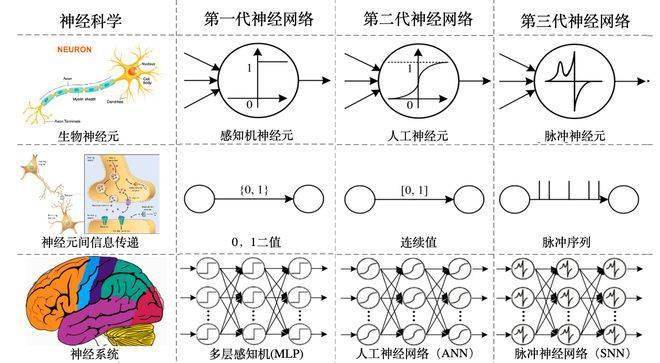
Als Modell einer neuen Generation neuronaler Netzwerke, auch bekannt als gehirnähnliches neuronales Netzwerk, durchbricht es die Mängel der beiden vorherigen Generationen neuronaler Netzwerke.
-Das neuronale Netzwerk der ersten Generation (auch bekannt als: MLP-Mehrschicht-Perzeptron), das Signale als 0 und 1 überträgt, kann übermäßig komplexe Aufgaben nicht bewältigen und benötigt nicht viel Rechenleistung.
-Das neuronale Netzwerk der zweiten Generation, auch als künstliches neuronales Netzwerk bekannt, ändert das Übertragungssignal in ein kontinuierliches Intervall von [0-1], das zwar ausreichend komplex ist, aber auch den Rechenleistungsaufwand stark erhöht hat.
- Die dritte Generation neuronaler Netze, auch gehirnähnliche neuronale Netze genannt, wandelt Signale in Impulssequenzen um, was nicht nur eine ausreichende Komplexität aufweist, sondern auch die Kosten für die Rechenleistung kontrollierbar macht. Diese Pulssequenz wird durch die Nachahmung der Dynamik neuronaler Strukturen erreicht. Gleichzeitig bedeutet Sequenz Zeit, und das neuronale Netzwerk der dritten Generation kann die Zeitinformationen effektiv in die Informationen integrieren und ausgeben.
-Im Vergleich zu den beiden vorherigen Generationen neuronaler Netze kann es Sequenzinformationen mit Zeitdimension effektiver verarbeiten und die reale Welt effektiver verstehen.
Das Argumentationsprinzip großer Modelle, die auf gehirnähnlichen Algorithmen basieren, unterscheidet sich ebenfalls völlig von Transformer. Während des Denkprozesses gibt es erhebliche Unterschiede in den Wirkmechanismen des Transformer-Modells und des gehirnähnlichen Modells. Immer wenn das Transformer-Modell eine Inferenz durchführt, berücksichtigt es alle Kontextinformationen, um das nächste Token zu generieren. Dieser Vorgang kann mit einem Chat verglichen werden: Jedes Mal, wenn wir ein Wort sagen, müssen wir uns an alle Erlebnisse des Tages erinnern. Dies ist auch der Hauptgrund dafür, dass die Berechnungskosten von Großmodellen immer weiter steigen, während ihre Parameter immer weiter wachsen.
Relativ gesehen muss sich das gehirnähnliche Modell beim Denken nur auf seinen inneren Zustand und ein Token verlassen. Dies lässt sich damit vergleichen, dass wir beim Sprechen mit dem nächsten Wort herausplatzen, ohne uns konkret an alle vorherigen Situationen erinnern zu müssen, und auch der Inhalt der Rede ist untrennbar mit früheren Erfahrungen verbunden. Dieser Mechanismus ist der Schlüssel zur Fähigkeit von NLM, den Rechenleistungsaufwand erheblich zu reduzieren, es näher an die Funktionsweise des menschlichen Gehirns heranzuführen und so seine Leistung erheblich zu verbessern.
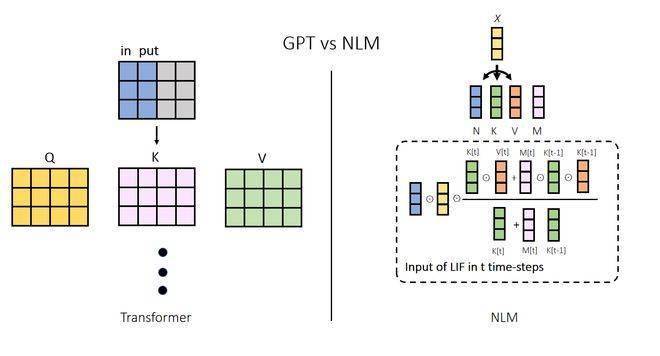
Auch aufgrund der vom Gehirn inspirierten Funktionen ist die begrenzte Kontextlänge kein störendes Problem mehr. Das große NLM-Modell, das das neuronale Netzwerk der dritten Generation verwendet, weist keinen Engpass bei der Kontextlänge auf, da die für die Verarbeitung des nächsten Tokens erforderliche Rechenleistung nicht mit der Kontextlänge zusammenhängt. Die Kontextlänge des großen Sprachmodells der öffentlich verfügbaren Transformer-Architektur beträgt nur 100 KB. Die Erhöhung der Kontextlänge ist nicht nur eine Frage des Rechenleistungsaufwands, sondern auch eine Frage des „Könnens“.
Der unendlich lange Kontext von NLM öffnet die Tür zur Fantasie großer Sprachmodellanwendungen, sei es das Studium komplexer Finanzberichte, das Lesen von Hunderttausenden Wörtern von Romanen oder das Veranlassen großer Modelle, Sie durch Kontext unbegrenzter Länge „besser zu verstehen“. „kann Wirklichkeit werden.
KI in den Augen von Lu Xis Team
Bei dieser Veranstaltung erklärte Dr. Zhou Peng, der Gründer und CTO von Luxi Technology, die aktuelle Mission des Teams – alle Dinge mit Weisheit zu stärken.
Im Zeitalter der künstlichen Intelligenz muss künstliche Intelligenz überall populär gemacht werden, so wie das Internet und die Elektrizität bereits überall um uns herum sind. Obwohl die derzeitige künstliche Intelligenz hinsichtlich ihrer Fähigkeiten beeindruckend ist, stellen ihre Betriebskosten eine enorme Belastung für Unternehmen und Verbraucher dar. Die überwiegende Mehrheit der Mobiltelefone, Uhren, Tablets und Laptops ist mit der aktuellen Technologie nicht in der Lage, große Sprachmodelle mit generativer künstlicher Intelligenz vollständig, systematisch, effizient und qualitativ hochwertig auszuführen. Die Schwelle für die Entwicklung großer Modellanwendungen hat auch viele herausragende Modelle behindert Entwickler, die daran interessiert sind, sind eingeschüchtert.
Bei der Veranstaltung zeigte Luxi Technology dem Publikum, wie man das große Modell „NLM-GPT“ im Offline-Modus eines gewöhnlichen Android-Telefons nutzen kann, um verschiedene häufige Aufgaben im Beruf und im Privatleben zu erledigen, was der Veranstaltung einen Höhepunkt bescherte.
- Die an der Demonstration teilnehmenden Mobiltelefone sind mit marktüblichen Chiparchitekturen ausgestattet und ihre Leistung ähnelt der gängiger Android-Modelle auf dem Verbrauchermarkt. Während sich das Telefon im Flugmodus befand und nicht mit dem Internet verbunden war, demonstrierte Luxi Technology ein großes Modell von „NLM-GPT“, das in Echtzeit mit Benutzern am Telefon sprechen, von Benutzern gestellte Fragen beantworten und Aufgaben wie das Verfassen von Gedichten erledigen kann. Rezeptschreiben, Wissensanweisungen wie das Abrufen und die Dateiinterpretation sind hochkomplex, erfordern Hochleistungsparameter der Mobiltelefon-Hardware und erfordern traditionell eine Netzwerkanbindung.
- Während des gesamten Demonstrationsprozesses war der Energieverbrauch des Mobiltelefons stabil, mit minimalen Auswirkungen auf die normale Standby-Zeit und ohne Auswirkungen auf die Gesamtleistung des Mobiltelefons.
-Diese Demonstration hat erfolgreich bewiesen, dass das große Modell „NLM-GPT“ das Potenzial hat, in allen Szenarien mit hoher Effizienz, geringem Stromverbrauch und keinem Datenverkehr in kleinen kommerziellen C-End-Geräten wie Smartphones und Tablets zu laufen. Das bedeutet, dass Mobiltelefone, Uhren, Tablets, Laptops und andere Geräte dank der Leistungsfähigkeit des „NLM-GPT“-Großmodells die wahren Absichten des Menschen genauer und effizienter verstehen und in verschiedenen Situationen eingesetzt werden können, z Büro, Studium, soziale Netzwerke, Unterhaltung usw. Erfüllen Sie verschiedene von Menschen vorgeschlagene Anweisungen und Aufgaben mit höherer Qualität in Anwendungsszenarien und verbessern Sie so die Effizienz und Qualität der sozialen Produktion und des menschlichen Lebens erheblich.
Luxi Technology ist davon überzeugt, dass das „große Sprachmodell der generativen künstlichen Intelligenz“, das auf „gehirnähnlicher Technologie“ basiert, das menschliche Denken, die Wahrnehmung und das Handeln in verschiedenen Bereichen wie Lernen, Arbeiten und Leben umfassend erweitern und die Gesamtqualität der gesamten Menschheit verbessern wird . Weisheit. Dank der Stärkung gehirnähnlicher Technologie wird künstliche Intelligenz nicht mehr ein neuer intelligenter Agent sein, der den Menschen ersetzt, sondern ein effizientes intelligentes Werkzeug für den Menschen, um die Welt zu verändern und eine bessere Zukunft zu schaffen.
So wie die Alten Hunde und Falken trainierten, wird der Beruf des Jägers durch das Aufkommen von Hunden und Falken nicht verschwinden. Im Gegenteil, Jäger haben davon profitiert und sich die Macht von Hunden und Falken zunutze gemacht, die der Mensch jedoch nicht besitzt. Sie können effizienter Beute machen und so Kraft und Nährstoffe für das Wachstum menschlicher Gruppen und die Entwicklung der menschlichen Zivilisation bereitstellen.
In Zukunft wird die Anwendung großer Sprachmodelle künstlicher Intelligenz in der täglichen Arbeit und im Leben kein komplexes Multiprozess-Systemprojekt mehr sein, sondern wie „Öffnen des Zahlungscodes beim Auschecken“ und „Drücken des Auslösers beim Aufnehmen eines Fotos“. ", "Wischen ... „Ein-Klick-Drei-Wege-Kurzvideo“ ist im Allgemeinen einfach, natürlich und flüssig. Das Team von Lu Xi wird weiterhin auf dem Gebiet der gehirninspirierten Datenverarbeitung arbeiten, eingehende Forschungen zum Gehirn, dem wertvollsten Geschenk der Natur an die Menschheit, durchführen und gehirninspirierte Intelligenz in das tägliche Leben bringen.
Vielleicht wird der Mensch in naher Zukunft weitere neue Partner für künstliche Intelligenz haben. In ihren Körpern fließt kein Blut und ihre Intelligenz wird den Menschen nicht ersetzen. Mit der Unterstützung gehirninspirierter Technologie werden sie mit uns zusammenarbeiten, um die Geheimnisse des Universums zu erforschen, die Grenzen der Gesellschaft zu erweitern und eine bessere Zukunft zu schaffen.
Quelle: Life Daily
(Quelle: undefiniert)
Für weitere spannende Informationen laden Sie bitte den „Jimu News“-Client im Anwendungsmarkt herunter. Bitte drucken Sie ihn nicht ohne Genehmigung aus. Willkommen, um Nachrichtenhinweise zu geben, und Sie werden bezahlt, sobald Sie angenommen werden. Die 24-Stunden-Meldehotline ist 027-86777777.
Das obige ist der detaillierte Inhalt vonGroße Veröffentlichung, „gehirnähnliche Wissenschaft' oder die optimale Lösung für das Problem des Rechenleistungsverbrauchs und der Kontextlänge eines großen Sprachmodells künstlicher Intelligenz!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr