
Heim >Technologie-Peripheriegeräte >KI >MiniGPT-4 wurde auf MiniGPT-v2 aktualisiert. Multimodale Aufgaben können weiterhin ohne GPT-4 erledigt werden.
MiniGPT-4 wurde auf MiniGPT-v2 aktualisiert. Multimodale Aufgaben können weiterhin ohne GPT-4 erledigt werden.

- PHPznach vorne
- 2023-10-17 14:41:091501Durchsuche
Vor einigen Monaten haben mehrere Forscher von KAUST (King Abdullah University of Science and Technology, Saudi-Arabien) ein Projekt namens MiniGPT-4 vorgeschlagen, das ein ähnliches GPT-4-Bildverständnis und einen ähnlichen Dialog ermöglichen kann Fähigkeiten.
MiniGPT-4 kann beispielsweise die Szene im Bild unten beantworten: „Das Bild beschreibt einen Kaktus, der auf einem zugefrorenen See wächst. Um den Kaktus herum befinden sich riesige Eiskristalle und in der Ferne sind schneebedeckte Gipfel zu sehen.“ ...“ Wenn Sie sich dann fragen, ob dieses Szenario in der realen Welt passieren könnte? Die Antwort von MiniGPT-4 lautet, dass dieses Bild in der realen Welt nicht häufig vorkommt und warum.

Vor Kurzem gaben das KAUST-Team und Forscher von Meta bekannt, dass sie MiniGPT-4 auf die MiniGPT-v2-Version aktualisiert haben.

Papieradresse: https://arxiv.org/pdf/2310.09478.pdf
Papierhomepage: https://minigpt-v2.github.io/
Demo: https: //minigpt-v2.github.io/
Konkret kann MiniGPT-v2 als einheitliche Schnittstelle dienen, um verschiedene visuell-linguistische Aufgaben besser zu bewältigen. Gleichzeitig empfiehlt dieser Artikel die Verwendung eindeutiger Identifikationssymbole für verschiedene Aufgaben beim Training des Modells. Diese Identifikationssymbole helfen dem Modell, jede Aufgabenanweisung leicht zu unterscheiden und die Lerneffizienz jedes Aufgabenmodells zu verbessern.
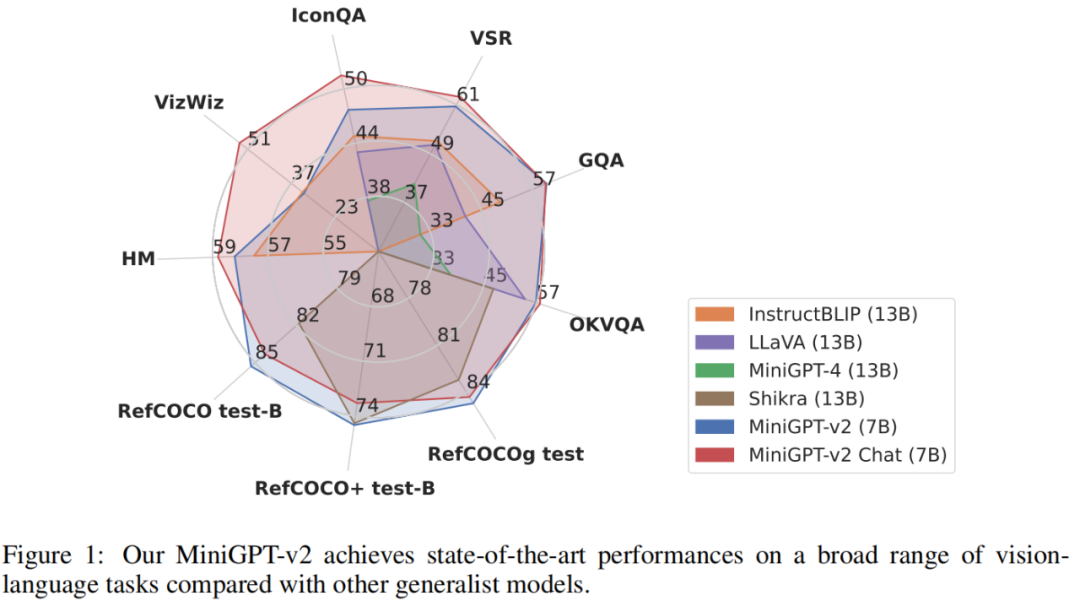
Um die Leistung des MiniGPT-v2-Modells zu bewerten, führten die Forscher umfangreiche Experimente zu verschiedenen visuellen Sprachaufgaben durch. Die Ergebnisse zeigen, dass MiniGPT-v2 bei verschiedenen Benchmarks eine SOTA- oder vergleichbare Leistung im Vergleich zu früheren Vision-Language-Allzweckmodellen wie MiniGPT-4, InstructBLIP, LLaVA und Shikra erreicht. Beispielsweise übertrifft MiniGPT-v2 MiniGPT-4 um 21,3 %, InstructBLIP um 11,3 % und LLaVA um 11,7 % im VSR-Benchmark.
Im Folgenden veranschaulichen wir anhand konkreter Beispiele die Rolle von MiniGPT-v2-Identifikationssymbolen.
Durch Hinzufügen des Erkennungssymbols [Erdung] kann das Modell beispielsweise problemlos eine Bildbeschreibung mit räumlicher Standorterkennung generieren:

Durch Hinzufügen des Erkennungssymbols [Erkennung] kann das Modell direkt extrahieren Geben Sie den Eingabetext ein und finden Sie ihre räumliche Position im Bild:

Durch Hinzufügen von [identifizieren] kann das Modell den Namen des Objekts direkt identifizieren:
 Übergeben Sie Add [refer] und eine Beschreibung eines Objekts, und das Modell kann Ihnen direkt dabei helfen, die entsprechende räumliche Position des Objekts zu finden:
Übergeben Sie Add [refer] und eine Beschreibung eines Objekts, und das Modell kann Ihnen direkt dabei helfen, die entsprechende räumliche Position des Objekts zu finden:

Sie können die Übereinstimmung auch identifizieren, ohne Aufgaben hinzuzufügen, und ein Gespräch mit ihnen führen Das Bild:

Die räumliche Wahrnehmung des Modells ist ebenfalls stärker geworden. Sie können das Modell, das links, in der Mitte und rechts im Bild erscheint, direkt fragen:

Methodeneinführung
Die Modellarchitektur von MiniGPT-v2 ist in der folgenden Abbildung dargestellt. Sie besteht aus drei Teilen: visuellem Rückgrat, linearer Projektionsschicht und großem Sprachmodell.

Visuelles Rückgrat: MiniGPT-v2 verwendet EVA als Rückgratmodell und das visuelle Rückgrat wird während des Trainings eingefroren. Das Modell wird auf eine Bildauflösung von 448 x 448 trainiert und zur Skalierung auf höhere Bildauflösungen wird eine Positionskodierung eingefügt.
Lineare Projektionsebene: Dieser Artikel zielt darauf ab, alle visuellen Token aus dem eingefrorenen visuellen Rückgrat in den Sprachmodellraum zu projizieren. Bei Bildern mit höherer Auflösung (z. B. 448 x 448) führt die Projektion aller Bildtoken jedoch zu sehr langen Sequenzeingaben (z. B. 1024 Token), wodurch die Trainings- und Inferenzeffizienz erheblich verringert wird. Daher verkettet dieser Artikel einfach vier benachbarte visuelle Token im Einbettungsraum und projiziert sie zusammen in eine einzige Einbettung im gleichen Merkmalsraum eines großen Sprachmodells, wodurch die Anzahl der visuellen Eingabetoken um den Faktor 4 reduziert wird.
Groß angelegtes Sprachmodell: MiniGPT-v2 verwendet den Open-Source-LLaMA2-Chat (7B) als Rückgrat des Sprachmodells. In dieser Forschung wird das Sprachmodell als einheitliche Schnittstelle für verschiedene visuelle Spracheingaben betrachtet. In diesem Artikel werden LLaMA-2-Sprachtoken direkt verwendet, um verschiedene visuelle Sprachaufgaben auszuführen. Für grundlegende Sehaufgaben, die die Generierung räumlicher Standorte erfordern, erfordert dieser Artikel direkt, dass das Sprachmodell Textdarstellungen von Begrenzungsrahmen generiert, um deren räumliche Standorte darzustellen.
Multitask-Anweisungstraining
In diesem Artikel werden symbolische Anweisungen zur Aufgabenerkennung verwendet, um das Modell zu trainieren, das in drei Phasen unterteilt ist. Die in jeder Trainingsphase verwendeten Datensätze sind in Tabelle 2 aufgeführt.

Phase 1: Vortraining. Dieses Papier gibt schwach gekennzeichneten Datensätzen eine hohe Abtastrate, um vielfältigeres Wissen zu erhalten.
Phase 2: Multitasking-Training. Um die Leistung von MiniGPT-v2 bei jeder Aufgabe zu verbessern, konzentriert sich die aktuelle Phase nur auf die Verwendung feinkörniger Datensätze zum Trainieren des Modells. Die Forscher schlossen schwach überwachte Datensätze wie GRIT-20M und LAION aus Stufe 1 aus und aktualisierten das Datenabtastverhältnis entsprechend der Häufigkeit jeder Aufgabe. Diese Strategie ermöglicht es unserem Modell, qualitativ hochwertige ausgerichtete Bild-Text-Daten zu priorisieren, was zu einer überlegenen Leistung bei einer Vielzahl von Aufgaben führt.
Phase 3: Multimodale Instruktionsabstimmung. Anschließend konzentriert sich dieses Papier auf die Verwendung weiterer multimodaler Befehlsdatensätze, um das Modell zu verfeinern und seine Konversationsfähigkeiten als Chatbot zu verbessern.
Schließlich stellt der Beamte den Lesern auch eine Demo zum Testen zur Verfügung. Auf der linken Seite des Bildes unten laden wir beispielsweise ein Foto hoch, wählen dann [Erkennung] und geben dann „roter Ballon“ ein werden den roten Ballon auf dem Bild erkennen können:

Interessierte Leser können auf der Homepage der Zeitung nach weiteren Informationen suchen.
Das obige ist der detaillierte Inhalt vonMiniGPT-4 wurde auf MiniGPT-v2 aktualisiert. Multimodale Aufgaben können weiterhin ohne GPT-4 erledigt werden.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!