
Heim >Technologie-Peripheriegeräte >KI >Was sind die effektiven Methoden und gängigen Basismethoden für die Vorhersage der Fußgängerbahn? Teilen der besten Konferenzbeiträge!
Was sind die effektiven Methoden und gängigen Basismethoden für die Vorhersage der Fußgängerbahn? Teilen der besten Konferenzbeiträge!

- 王林nach vorne
- 2023-10-17 11:13:012168Durchsuche
Trajektorienvorhersage stand in den letzten zwei Jahren im Rampenlicht, aber der größte Teil davon konzentriert sich auf die Richtung der Fahrzeugtrajektorienvorhersage. Heute wird Autonomous Driving Heart den Algorithmus für die Vorhersage der Fußgängertrajektorie auf NeurIPS – SHENet, der menschlichen Bewegung, vorstellen Muster in eingeschränkten Szenen entspricht normalerweise bis zu einem gewissen Grad begrenzten Gesetzen. Basierend auf dieser Annahme sagt SHENet die zukünftige Flugbahn einer Person voraus, indem es implizite Szenenregeln lernt. Der Artikel wurde von Autonomous Driving Heart als Original zertifiziert!
Das persönliche Verständnis des Autors
Aufgrund der Zufälligkeit und Subjektivität menschlicher Bewegungen ist die Vorhersage der zukünftigen Flugbahn einer Person derzeit immer noch ein herausforderndes Problem. Aufgrund von Szenenbeschränkungen (z. B. Grundrissen, Straßen und Hindernissen) und der Interaktivität von Mensch zu Mensch oder Mensch zu Objekt entsprechen menschliche Bewegungsmuster in eingeschränkten Szenen jedoch normalerweise bis zu einem gewissen Grad begrenzten Gesetzen. Daher sollte in diesem Fall auch die Flugbahn des Individuums einem dieser Gesetze folgen. Mit anderen Worten: Der weitere Weg einer Person ist wahrscheinlich von anderen gegangen. Basierend auf dieser Annahme sagt der Algorithmus dieses Artikels (SHENet) die zukünftige Flugbahn einer Person voraus, indem er implizite Szenenregeln lernt. Konkret bezeichnen wir die Regelmäßigkeiten, die der vergangenen Dynamik von Menschen und Umgebungen in einer Szene innewohnen, als Szenengeschichte. Die Szenenverlaufsinformationen werden dann in zwei Kategorien unterteilt: historische Gruppenverläufe und Interaktionen zwischen Individuen und der Umgebung. Um diese beiden Arten von Informationen für die Flugbahnvorhersage zu nutzen, schlägt dieser Artikel ein neuartiges Framework für das Scene History Mining Network (SHENet) vor, in dem der Szenenverlauf auf einfache und effektive Weise ausgenutzt wird. Insbesondere zwei Komponenten des Entwurfs sind: das Gruppen-Trajektorien-Bibliotheksmodul, das verwendet wird, um repräsentative Gruppen-Trajektorien als Kandidaten für zukünftige Pfade zu extrahieren, und das modalübergreifende Interaktionsmodul, das verwendet wird, um die Interaktion zwischen den vergangenen Trajektorien eines Individuums zu modellieren und seiner Umgebung zur Verfeinerung der Flugbahn. Um außerdem die durch die oben erwähnte Zufälligkeit und Subjektivität der menschlichen Bewegung verursachte Unsicherheit über die tatsächliche Flugbahn zu verringern, integriert SHENet Glätte in den Trainingsprozess und in die Bewertungsindikatoren. Schließlich haben wir es anhand verschiedener experimenteller Datensätze verifiziert und im Vergleich zu SOTA-Methoden eine hervorragende Leistung gezeigt.
Einführung
Human Trajectory Prediction (HTP) zielt darauf ab, den zukünftigen Weg einer Zielperson anhand von Videoclips vorherzusagen. Dies ist für den intelligenten Transport von entscheidender Bedeutung, da Fahrzeuge so den Fußgängerstatus im Voraus erkennen und so mögliche Kollisionen vermeiden können. Überwachungssysteme mit HTP-Funktionen können Sicherheitspersonal dabei unterstützen, mögliche Fluchtwege von Verdächtigen vorherzusagen. Obwohl in den letzten Jahren viel Arbeit geleistet wurde, sind nur wenige ausreichend zuverlässig und auf Anwendungen in realen Szenarien übertragbar, was hauptsächlich auf zwei Herausforderungen der Aufgabe zurückzuführen ist: Zufälligkeit und Subjektivität der menschlichen Bewegung. In eingeschränkten realen Szenarien sind die Herausforderungen jedoch nicht absolut unlösbar. Wie in Abbildung 1 dargestellt, wird die zukünftige Flugbahn der Zielperson (rotes Kästchen) angesichts der zuvor aufgenommenen Videos in dieser Szene vorhersehbarer, da das Bewegungsmuster des Menschen normalerweise mehreren Grundgesetzen entspricht, denen die Zielperson in dieser Szene folgen wird. Um Flugbahnen vorherzusagen, müssen wir daher zunächst diese Muster verstehen. Wir argumentieren, dass diese Regelmäßigkeiten implizit in historischen menschlichen Flugbahnen (Abbildung 1 links), individuellen vergangenen Flugbahnen, umgebenden Umgebungen und Interaktionen zwischen ihnen (Abbildung 1 rechts) kodiert sind, die wir als Szenengeschichten bezeichnen.

Abbildung 1: Schematische Darstellung der Nutzung des Szenenverlaufs: historische Gruppentrajektorien und individuelle Umgebungsinteraktionen für die Vorhersage menschlicher Trajektorien.
Wir unterteilen historische Informationen in zwei Kategorien: historische Gruppenverläufe (HGT) und Individuum-Umwelt-Interaktionen (ISI). HGT bezieht sich auf die Gruppendarstellung aller historischen Trajektorien in einer Szene. Der Grund für die Verwendung von HGT liegt darin, dass bei einer neuen Zielperson in der Szene deren/ihrer Weg mit größerer Wahrscheinlichkeit mehr Ähnlichkeit, Subjektivität und Regelmäßigkeit mit einer der Gruppenverläufe aufweist als mit irgendeiner einzelnen Instanz der historischen Verläufe die oben erwähnte Zufälligkeit. Gruppenverläufe sind jedoch weniger relevant für die vergangenen Zustände von Einzelpersonen und die entsprechenden Umgebungen und können sich auch auf die zukünftigen Verlaufsverläufe von Einzelpersonen auswirken. ISI muss historische Informationen umfassender nutzen, indem es Kontextinformationen extrahiert. Bestehende Methoden berücksichtigen selten die Ähnlichkeit zwischen vergangenen und historischen Werdegängen einzelner Personen. Die meisten Versuche untersuchen nur die Interaktion zwischen dem Individuum und der Umwelt, wobei viel Aufwand in die Modellierung der individuellen Flugbahn, der semantischen Informationen der Umwelt und der Beziehung zwischen ihnen gesteckt wird. Obwohl MANTRA Ähnlichkeit mithilfe eines auf Rekonstruktionsmethode trainierten Encoders modelliert und MemoNet die Ähnlichkeit durch die Speicherung der Absicht historischer Trajektorien vereinfacht, führen beide Ähnlichkeitsberechnungen auf Instanzebene und nicht auf Gruppenebene durch, wodurch es empfindlich auf die Fähigkeiten des Trainierten reagiert Programmierer. Basierend auf der obigen Analyse schlagen wir ein einfaches, aber effektives Framework vor, das Scene History Mining Network (SHENet), das HGT und ISI gemeinsam für HTP nutzt. Das Framework besteht insbesondere aus zwei Hauptkomponenten: (i) dem Group Trajectory Base (GTB)-Modul und (ii) dem Cross-Modal Interaction (CMI)-Modul. GTB erstellt repräsentative Gruppentrajektorien aus allen historischen Einzeltrajektorien und stellt Kandidatenpfade für die Vorhersage zukünftiger Trajektorien bereit. CMI kodiert die beobachteten individuellen Trajektorien und die Umgebung separat und modelliert ihre Interaktion mithilfe eines modalübergreifenden Transformators, um die gesuchten Kandidatentrajektorien zu verfeinern.
Um die Unsicherheit der beiden oben genannten Merkmale (d. h. Zufälligkeit und Subjektivität) zu verringern, führen wir außerdem Curve Smoothing (CS) in den Trainingsprozess ein und erhalten aktuelle Bewertungsmetriken, durchschnittliche und endgültige Verschiebungsfehler (d. h. ADE und FDE). zwei neue Indikatoren CS-ADE und CS-FDE. Um die Entwicklung der HTP-Forschung zu erleichtern, haben wir außerdem einen neuen herausfordernden Datensatz mit verschiedenen Bewegungsmustern namens PAV gesammelt. Dieser Datensatz wird durch Auswahl von Videos mit festen Kameraansichten und komplexer menschlicher Bewegung aus dem MOT15-Datensatz erhalten.
Die Beiträge dieser Arbeit können wie folgt zusammengefasst werden: 1) Wir führen die Gruppengeschichte ein, um nach individuellen Trajektorien von HTP zu suchen. 2) Wir schlagen ein einfaches, aber effektives Framework vor, SHENet, das gemeinsam zwei Arten von Szenenverläufen (d. h. historische Gruppenverläufe und Interaktionen zwischen Individuum und Umgebung) für HTP nutzt. 3) Wir haben einen neuen herausfordernden Datensatz PAV erstellt. Darüber hinaus werden unter Berücksichtigung der Zufälligkeit und Subjektivität menschlicher Bewegungsmuster eine neuartige Verlustfunktion und zwei neue Indikatoren vorgeschlagen, um eine bessere Baseline-HTTP-Leistung zu erzielen. 4) Wir haben umfassende Experimente zu ETH, UCY und PAV durchgeführt, um die überlegene Leistung von SHENet und die Wirksamkeit jeder Komponente zu demonstrieren.
Verwandte Arbeit
Unimodale MethodenUnimodale Methoden basieren auf dem Erlernen der Regelmäßigkeit einzelner Bewegungen aus vergangenen Trajektorien, um zukünftige Trajektorien vorherzusagen. Beispielsweise modelliert Social LSTM die Interaktionen zwischen einzelnen Trajektorien durch das Social-Pooling-Modul. STGAT verwendet ein Aufmerksamkeitsmodul, um räumliche Interaktionen zu lernen und Nachbarn eine angemessene Bedeutung zuzuweisen. PIE verwendet ein zeitliches Aufmerksamkeitsmodul, um die Bedeutung der beobachteten Trajektorien in jedem Zeitschritt zu berechnen.
Multimodale MethodeDarüber hinaus untersucht die multimodale Methode auch den Einfluss von Umweltinformationen auf HTP. SS-LSTM schlägt ein Szeneninteraktionsmodul vor, um die globalen Informationen der Szene zu erfassen. Trajectron++ verwendet Graphstrukturen, um Flugbahnen zu modellieren und mit Umweltinformationen und anderen Personen zu interagieren. MANTRA nutzt externen Speicher, um langfristige Abhängigkeiten zu modellieren. Es speichert historische Flugbahnen einzelner Agenten im Speicher und kodiert Umgebungsinformationen, um die gesuchten Flugbahnen aus diesem Speicher zu verfeinern.
Unterschiede zu früheren ArbeitenSowohl monomodale als auch multimodale Ansätze nutzen einzelne oder teilweise Aspekte der Szenengeschichte und ignorieren historische Gruppenverläufe. In unserer Arbeit integrieren wir Informationen zur Szenengeschichte auf umfassendere Weise und schlagen spezielle Module vor, um jeweils verschiedene Arten von Informationen zu verarbeiten. Die Hauptunterschiede zwischen unserer Methode und früheren Arbeiten, insbesondere speicherbasierten Methoden und Clustering-basierten Methoden, sind wie folgt: i) MANTRA und MemoNet berücksichtigen historische individuelle Trajektorien, während sich unser vorgeschlagenes SHENet auf historische Gruppentrajektorien konzentriert, die in unterschiedlicher Weise universeller sind Szenarien. ii) Es gibt auch einige Arbeiten, die Personen-Nachbarn für die Trajektorienvorhersage in eine feste Anzahl von Kategorien einteilen; unser SHENet generiert repräsentative Trajektorien als Referenzen für die individuelle Trajektorienvorhersage.
Methode
Gesamteinführung
Die Architektur des vorgeschlagenen Scene History Mining Network (SHENet) ist in Abbildung 2 dargestellt. Sie besteht aus zwei Hauptkomponenten: dem Group Trajectory Library Module (GTB) und dem Cross-Modal Interaction Modul (CMI). Formal sind alle Trajektorien , Szenenbilder im beobachteten Video der Szene und die vergangenen Trajektorien der Zielperson im letzten Zeitschritt gegeben, wobei die Position der p-ten Person im Zeitschritt t dargestellt wird , SHENet muss vorhersagen, dass die zukünftige Position des Fußgängers im nächsten Frame so nah wie möglich an der Flugbahn der Grundwahrheit liegt. Das vorgeschlagene GTB komprimiert zunächst in repräsentative Gruppentrajektorien. Verwenden Sie dann die beobachtete Trajektorie als Schlüssel für die Suche nach der nächstgelegenen repräsentativen Gruppentrajektorie als mögliche zukünftige Trajektorie. Gleichzeitig werden die vergangenen Trajektorien und Szenenbilder an den Trajektorien-Encoder bzw. Szenen-Encoder übergeben, um Trajektorienmerkmale bzw. Szenenmerkmale zu generieren. Die codierten Merkmale werden in einen modalübergreifenden Transformator eingespeist, um den Offset aus der Ground-Truth-Trajektorie zu lernen. Durch Addition von zu erhalten wir die endgültige Vorhersage . Wenn während der Trainingsphase die Entfernung zu höher als der Schwellenwert ist, wird die Flugbahn der Person (d. h. und) zur Flugbahnbibliothek hinzugefügt. Nach Abschluss des Trainings wird die Bank zur Schlussfolgerung fixiert.
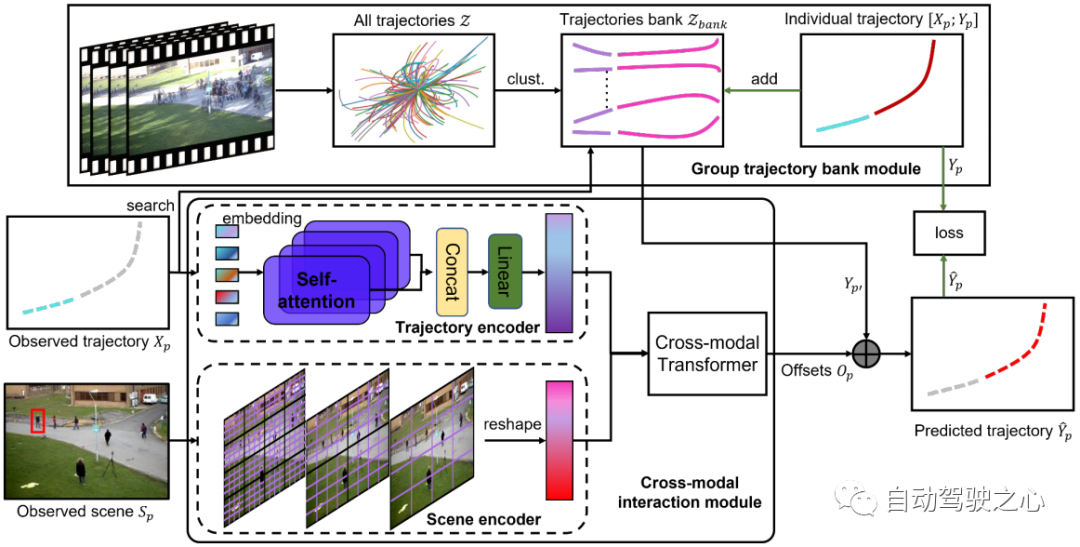
Abbildung 2: Die Architektur von SHENet besteht aus zwei Komponenten: dem Group Trajectory Library-Modul (GTB) und dem Cross-Modal Interaction Module (CMI). GTB gruppiert alle historischen Trajektorien zu einem Satz repräsentativer Gruppentrajektorien und stellt Kandidaten für die endgültige Trajektorienvorhersage bereit. In der Trainingsphase kann GTB die Flugbahn der Zielperson basierend auf dem Fehler der vorhergesagten Flugbahn in die Gruppenflugbahnbibliothek integrieren, um die Ausdrucksfähigkeiten zu erweitern. CMI verwendet die vergangene Flugbahn der Zielperson und der beobachteten Szene als Eingabe des Flugbahn-Encoders bzw. Szenen-Encoders für die Merkmalsextraktion und modelliert dann effektiv die Interaktion zwischen der vergangenen Flugbahn und ihrer Umgebung durch den modalübergreifenden Konverter und die Verfeinerung wird durchgeführt, um Kandidatentrajektorien bereitzustellen.
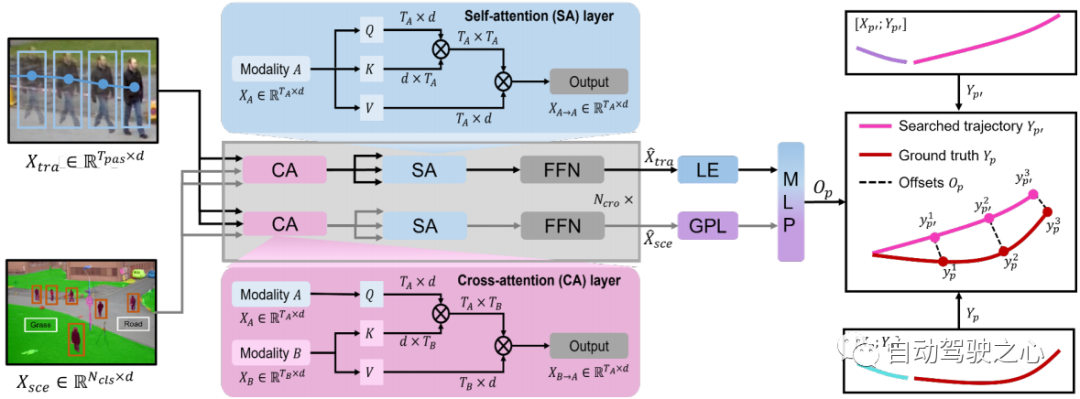
Abbildung 3: Darstellung des modalübergreifenden Transformators. Trajektorienmerkmale und Szenenmerkmale werden in den modalübergreifenden Transformator eingegeben, um den Versatz zwischen der Suchtrajektorie und der Ground-Truth-Trajektorie zu lernen.
Gruppen-Trajektorien-Bibliotheksmodul
Das Gruppen-Trajektorien-Bibliotheksmodul (GTB) wird verwendet, um repräsentative Gruppen-Trajektorien in der Szene zu erstellen. Die Kernfunktionen von GTB sind Bankinitialisierung, Trajektoriensuche und Trajektorienaktualisierung.
Initialisierung der TrajektorienbibliothekAufgrund der Redundanz einer großen Anzahl aufgezeichneter Trajektorien verwenden wir diese nicht einfach, sondern generieren einen Satz spärlicher und repräsentativer Trajektorien als Anfangswert der Trajektorienbibliothek. Konkret stellen wir die Trajektorien in den Trainingsdaten als dar und unterteilen jede in ein Paar Beobachtungstrajektorien und zukünftige Trajektorien , wodurch in einen Beobachtungssatz und einen entsprechenden zukünftigen Satz unterteilt wird. Dann berechnen wir den euklidischen Abstand zwischen jedem Trajektorienpaar in , und erhalten Trajektoriencluster durch den K-Medoids-Clustering-Algorithmus. Die anfänglichen Mitglieder von sind der Durchschnitt der Trajektorien, die zum selben Cluster gehören (siehe Algorithmus 1, Schritt 1). Jede Flugbahn repräsentiert das Bewegungsmuster einer Gruppe von Menschen.
Trajektoriensuche und -aktualisierungIn der Gruppen-Trajektorienbibliothek kann jede Trajektorie als Vergangenheit-Zukunft-Paar angezeigt werden. Numerisch, , wobei die Kombination aus vergangener und zukünftiger Flugbahn darstellt und die Anzahl der Vergangenheit-Zukunfts-Paare in ist. Bei gegebener Flugbahn verwenden wir die beobachtete als Schlüssel, um ihren Ähnlichkeitswert mit früheren Flugbahnen in zu berechnen und die repräsentative Flugbahn entsprechend dem maximalen Ähnlichkeitswert zu finden (siehe Algorithmus 1, Schritt 2). Die Ähnlichkeitsfunktion kann wie folgt ausgedrückt werden:
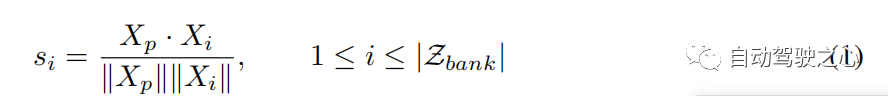
Durch Addition des Versatzes (siehe Gleichung 2) zur repräsentativen Flugbahn erhalten wir die vorhergesagte Flugbahn des Beobachters (siehe Abbildung 2). Obwohl die anfängliche Trajektorienbibliothek in den meisten Fällen gut funktioniert, entscheiden wir, um die Verallgemeinerung der Bibliothek zu verbessern (siehe Algorithmus 1, Schritt 3), basierend auf dem Entfernungsschwellenwert θ, ob eine Aktualisierung durchgeführt werden soll.
Crossmodales Interaktionsmodul
Dieses Modul konzentriert sich auf die Interaktion zwischen individuellen Vergangenheitsverläufen und Umweltinformationen. Es besteht aus zwei Single-Modal-Encodern zum Erlernen menschlicher Bewegungs- bzw. Szeneninformationen und einem Cross-Modal-Transformer zur Modellierung ihrer Interaktion.
Trajectory EncoderTrajectory Encoder verwendet eine Multi-Head-Aufmerksamkeitsstruktur von Transformer Network, die über eine Self-Attention (SA)-Schicht verfügt. Die SA-Schicht erfasst menschliche Bewegungen in verschiedenen Zeitschritten mit der Größe und projiziert Bewegungsmerkmale von Dimension bis , wobei die Einbettungsdimension des Trajektorienencoders ist. Daher verwenden wir einen Trajektorienencoder, um eine Darstellung der menschlichen Bewegung zu erhalten: .
Szenen-Encoder Da der vorab trainierte Swin Transformer eine überzeugende Leistung bei der Feature-Darstellung aufweist, übernehmen wir ihn als Szenen-Encoder. Es extrahiert szenensemantische Merkmale der Größe , wobei ( im vorab trainierten Szenenencoder) die Anzahl semantischer Klassen wie Personen und Straßen ist und und die räumlichen Auflösungen sind. Um es nachfolgenden Modulen zu ermöglichen, Bewegungsdarstellung und Umgebungsinformationen einfach zu verschmelzen, ändern wir die semantischen Merkmale von Größe () in () um und projizieren sie von Dimension () in () durch mehrschichtige Wahrnehmungsschichten. Als Ergebnis erhalten wir eine Szenendarstellung unter Verwendung eines Szenenencoders .
Kreuzmodaler Transformator Ein modaler Encoder extrahiert Merkmale aus seiner eigenen Modalität und ignoriert dabei die Interaktion zwischen menschlicher Bewegung und Umgebungsinformationen. Ein modalübergreifender Transformator mit Schichten zielt darauf ab, Kandidatentrajektorien zu verfeinern, indem er diese Interaktion lernt (siehe Abschnitt 3.2). Wir verwenden eine Zwei-Stream-Struktur: Der eine wird verwendet, um wichtige menschliche Bewegungen zu erfassen, die durch Umgebungsinformationen eingeschränkt werden, und der andere wird verwendet, um Umgebungsinformationen im Zusammenhang mit menschlichen Bewegungen auszuwählen. Die Cross-Attention-Schicht (CA) und die Self-Attention-Schicht (SA) sind die Hauptkomponenten des Cross-Modal-Konverters (siehe Abbildung 3). Um wichtige menschliche Bewegungen zu erfassen, die von der Umwelt beeinflusst werden, und bewegungsbezogene Umweltinformationen zu erhalten, behandelt die CA-Schicht eine Modalität als Abfrage und die andere Modalität als Schlüssel und Wert, die mit den beiden Modalitäten interagieren. Die SA-Schicht wird verwendet, um bessere interne Verbindungen zu fördern und die Ähnlichkeit zwischen Elementen (Abfrage) und anderen Elementen (Schlüssel) in szenenbeschränkten Bewegungen oder bewegungsbezogenen Umgebungsinformationen zu berechnen. Daher erhalten wir die multimodale Darstellung über den Cross-Modal-Transformer(). Um den Versatz zwischen der Suchtrajektorie und der realen Trajektorie vorherzusagen, nehmen wir das letzte Element (LE) von und das der Ausgabe nach der globalen Poolingschicht (GPL). Der Versatz kann wie folgt ausgedrückt werden:
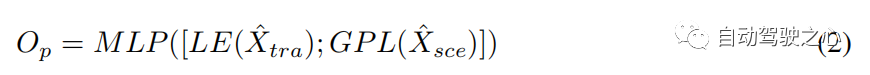
.
Im anspruchsvolleren PAV-Datensatz verwenden wir einen Kurvenglättungs-(CS)-Regressionsverlust, der dazu beiträgt, die Auswirkungen individueller Verzerrungen zu reduzieren. Es berechnet den MSE nach Glättung der Flugbahn. Der CS-Verlust kann wie folgt ausgedrückt werden: wobei CS die Kurvenglättungsfunktion darstellt [2].
Experiment
Experimenteller AufbauDatensatz Wir evaluieren unsere Methode anhand der Datensätze ETH, UCY, PAV und Stanford Drone Dataset (SDD). Singlemodale Methoden konzentrieren sich nur auf Flugbahndaten, multimodale Methoden müssen jedoch Szeneninformationen berücksichtigen.
Im Vergleich zum ETH/UCY-Datensatz ist PAV mit mehreren Bewegungsmodi anspruchsvoller, darunter PETS09-S2L1 (PETS), ADL-Rundle-6 (ADL) und Venice-2 (VENICE), bei denen es sich um Aufnahmen von statischen Kameras handelt stellt ausreichend Traces für HTP-Aufgaben bereit. Wir unterteilen die Videos in Trainingssatz (80 %) und Testsatz (20 %), und PETS/ADL/VENICE enthält 2.370/2.935/4.200 Trainingssequenzen bzw. 664/306/650 Testsequenzen. Wir verwendenBeobachtungsrahmen, um zukünftige Rahmen vorherzusagen, damit wir die langfristigen Vorhersageergebnisse verschiedener Methoden vergleichen können.
Im Gegensatz zu den ETH/UCY- und PAV-Datensätzen handelt es sich bei SDD um einen groß angelegten Datensatz, der aus der Vogelperspektive eines Universitätscampus erfasst wird. Es besteht aus mehreren interagierenden Akteuren (z. B. Fußgängern, Radfahrern und Autos) und verschiedenen Szenarien (z. B. Gehwegen und Kreuzungen). In Anlehnung an frühere Arbeiten verwenden wir die letzten 8 Frames, um die zukünftigen 12 Frames vorherzusagen.
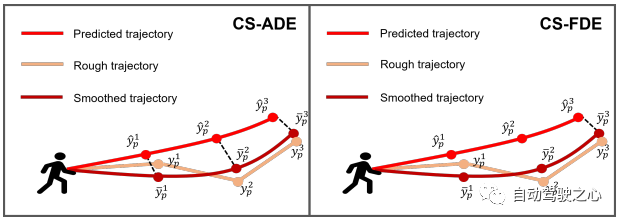
Abbildung 4: Darstellung unserer vorgeschlagenen Metriken CS-ADE und CS-FDE.

Abbildung 5: Visualisierung einiger Proben nach Kurvenglättung.
Bewertungsmetriken Für die ETH- und UCY-Datensätze verwenden wir die Standardmetriken von HTP: durchschnittlicher Verschiebungsfehler (ADE) und endgültiger Verschiebungsfehler (FDE). ADE ist der durchschnittliche Fehler zwischen der vorhergesagten Flugbahn und der wahren Flugbahn in allen Zeitschritten, und FDE ist der Fehler zwischen der vorhergesagten Flugbahn und der wahren Flugbahn im letzten Zeitschritt. Die Flugbahn im PAV weist einige Schwankungen auf (z. B. scharfe Kurven). Daher kann eine vernünftige Prognose ungefähr den gleichen Fehler erzeugen wie eine unrealistische Prognose unter Verwendung der traditionellen Metriken ADE und FDE (siehe Abbildung 7(a)). Um sich auf das Muster und die Form der Flugbahn selbst zu konzentrieren und den Einfluss von Zufälligkeit und Subjektivität zu reduzieren, schlagen wir CS-Metric vor: CS-ADE und CS-FDE (siehe Abbildung 4). CS-ADE wird wie folgt berechnet:
wobei CS die Kurvenglättungsfunktion ist, die genauso definiert ist wie Lcs in Abschnitt 3.4. Ähnlich wie CS-ADE berechnet CS-FDE den endgültigen Verschiebungsfehler nach der Trajektorienglättung: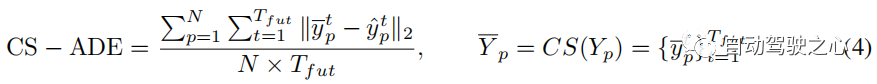
In SHENet ist die anfängliche Größe der Gruppentrajektorienbibliothek auf eingestellt. Sowohl der Trajektorien-Encoder als auch der Szenen-Encoder verfügen über 4 Selbstaufmerksamkeitsschichten (SA). Der Cross-Modal Transformer verfügt über 6 SA-Schichten und Cross Attention (CA)-Schichten. Wir haben alle Einbettungsmaße auf 512 eingestellt. Für den Trajektorien-Encoder lernt er menschliche Bewegungsinformationen der Größe ( in ETH/UCY, in PAV). Für den Szenenencoder werden semantische Merkmale der Größe 150 × 56 × 56 ausgegeben. Wir ändern die Größe von 150 × 56 × 56 auf 150 × 3136 und projizieren sie von den Abmessungen 150 × 3136 auf 150 × 512. Wir trainieren das Modell für 100 Epochen auf 4 NVIDIA Quadro RTX 6000 GPUs und verwenden den Adam-Optimierer mit einer festen Lernrate von 1e − 5. AblationsexperimentIn Tabelle 1 bewerten wir jede Komponente von SHENet, einschließlich des Group Trajectory Library (GTB)-Moduls und des Cross-Modal Interaction (CMI)-Moduls, das den Trajectory Encoder (TE) und den Szenencodierungsserver enthält ( SE) und Cross-Modal Interaction (CMI)-Module.
Auswirkungen von GTB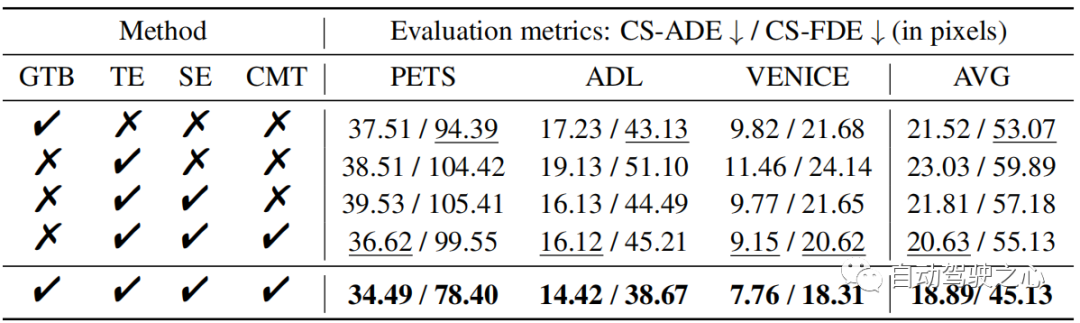
Wir untersuchen zunächst die Leistung von GTB. Im Vergleich zu CMI (d. h. TE, SE und CMT) verbessert GTB die FDE bei PETS um 21,2 %, was eine deutliche Verbesserung darstellt und die Bedeutung von GTB verdeutlicht. Allerdings reicht GTB allein (Tabelle 1 Zeile 1) nicht aus und schneidet sogar etwas schlechter ab als CMI. Daher haben wir die Rolle verschiedener Teile im CMI-Modul untersucht. Einfluss von TE und SE Um die Leistung von TE und SE zu bewerten, verketten wir die aus TE extrahierten Trajektorienmerkmale und die aus SE extrahierten Szenenmerkmale (Zeile 3 in Tabelle 1) und vergleichen kleine Bewegungen, die die Leistung von ADL verbessern und VENICE (im Vergleich zur alleinigen Verwendung von TE. Dies zeigt, dass die Einbeziehung von Umgebungsinformationen in die Flugbahnvorhersage die Genauigkeit der Ergebnisse verbessern kann. Wirkung von CMT Im Vergleich zur dritten Zeile von Tabelle 1 kann sich CMT (Tabelle 1) erheblich verbessern Insbesondere übertrifft es TE und SE in der Serie auf PETS, wobei sich ADE im Vergleich zu GTB allein um 12,2 % verbessert
Vergleich mit SOTA
Vergleichen Sie unser Modell mit modernsten Methoden zum ETH/UCY-Datensatz: SS-LSTM, Social-STGCN, MANTRA, AgentFormer, YNet. Die Ergebnisse sind in Tabelle 2 zusammengefasst. Unser Modell reduziert den durchschnittlichen FDE von 0,39 auf 0,36, was einer Verbesserung von 7,7 % im Vergleich zur hochmodernen Methode YNet entspricht. Insbesondere wenn die Flugbahn großen Bewegungen unterliegt, übertrifft unser Modell frühere Methoden für ETH deutlich und verbessert ADE und FDE um 12,8 % bzw. 15,3 %.
Tabelle 2: Vergleich modernster (SOTA) Methoden am ETH/UCY-Datensatz. * zeigt an, dass wir eine kleinere Menge als beim unimodalen Ansatz verwenden. Bewerten Sie anhand der Besten der Top 20.
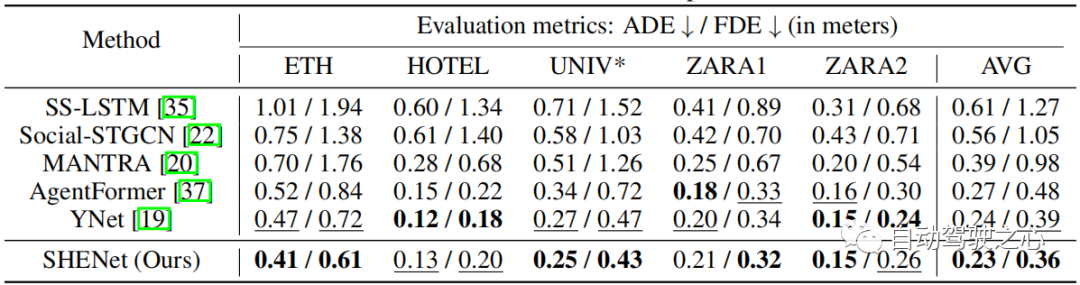
Tabelle 3: Vergleich mit SOTA-Methoden im PAV-Datensatz.
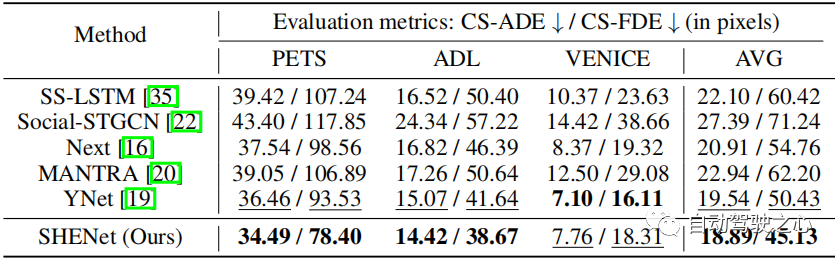
Um die Leistung unseres Modells bei der Langzeitvorhersage zu bewerten, haben wir PAV-Experimente mit Beobachtungsrahmen und Zukunftsrahmen pro Trajektorie durchgeführt. Tabelle 3 zeigt den Leistungsvergleich mit früheren HTP-Methoden: SS-LSTM, Social-STGCN, Next, MANTRA, YNet. Im Vergleich zu den neuesten Ergebnissen von YNet erzielen die vorgeschlagenen SHENet CS-ADE und CS-FDE eine durchschnittliche Verbesserung von 3,3 % bzw. 10,5 %. Da YNet Heatmaps von Trajektorien vorhersagt, ist die Leistung besser, wenn Trajektorien kleine Bewegungen aufweisen (z. B. VENEDIG). Dennoch ist unsere Methode in VENICE immer noch konkurrenzfähig und bei PETS mit größeren Bewegungen und Schnittpunkten deutlich besser als andere Methoden. Insbesondere verbessert unsere Methode CS-FDE bei PETS im Vergleich zu YNet um 16,2 %. Auch bei den traditionellen ADE/FDE-Metriken haben wir große Fortschritte gemacht.
Analyse
Der Distanzschwellenwert θθ wird verwendet, um die Aktualisierung der Trajektorienbibliothek zu bestimmen. Typische Werte für θ werden basierend auf der Flugbahnlänge festgelegt. Der absolute Wert des Vorhersagefehlers ist im Allgemeinen größer, wenn die Ground-Truth-Trajektorie länger in Pixeln ist. Ihre relativen Fehler sind jedoch vergleichbar. Wenn die Fehler konvergieren, wird daher θ auf 75 % des Trainingsfehlers gesetzt. In Experimenten haben wir θ = 25 in PETS und θ = 6 in ADL festgelegt. Der „75 %-Trainingsfehler“ ergibt sich aus den experimentellen Ergebnissen, wie in Tabelle 4 dargestellt.
Tabelle 4: Vergleich verschiedener Parameter θ im PAV-Datensatz. Die Ergebnisse sind der Durchschnitt der drei Fälle.
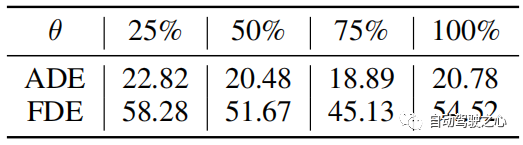
Tabelle 5: Vergleich der anfänglichen Clusternummer K im PAV-Datensatz.

K Anzahl der Cluster im Mittelpunkt Wir haben die Auswirkung der Einstellung unterschiedlicher Anzahlen von anfänglichen Clustern K untersucht, wie in Tabelle 5 gezeigt. Wir können feststellen, dass die anfängliche Clusteranzahl nicht von den Vorhersageergebnissen abhängt, insbesondere wenn die anfängliche Clusteranzahl 24–36 beträgt. Daher können wir im Experiment K auf 32 setzen.
Analyse der Bankkomplexität Die zeitliche Komplexität von Suche und Aktualisierung beträgt O(N) bzw. O(1). Ihre Raumkomplexität ist O(N). Die Anzahl der Gruppentrajektorien N≤1000. Die zeitliche Komplexität des Clustering-Prozesses beträgt ββ und die räumliche Komplexität beträgt ββ. β ist die Anzahl der Clustering-Trajektorien. ist die Anzahl der Cluster, ist die Anzahl der Iterationen der Clustering-Methode.

Abbildung 6: Qualitative Visualisierung unserer Vorgehensweise und State-of-the-Art-Methoden. Die blaue Linie ist die beobachtete Flugbahn. Die roten und grünen Linien zeigen die vorhergesagte und tatsächliche Flugbahn.

Abbildung 7: Qualitative Visualisierung ohne/mit CS.
Qualitative Ergebnisse
Abbildung 6 zeigt die qualitativen Ergebnisse von SHENet und anderen Methoden. Im Gegensatz dazu sind wir überrascht festzustellen, dass in dem äußerst schwierigen Fall, dass eine Person zum Straßenrand geht und dann umkehrt (grüne Kurve), alle anderen Methoden damit nicht gut zurechtkommen, während unser vorgeschlagenes SHENet immer noch damit umgehen kann. Dies ist auf die Rolle unseres speziell entwickelten Bibliotheksmoduls für historische Gruppenbahnen zurückzuführen. Darüber hinaus suchen wir im Gegensatz zur gedächtnisbasierten Methode MANTRA [20] nach Trajektorien von Gruppen, nicht nur von Einzelpersonen. Dies ist vielseitiger und kann auf anspruchsvollere Szenarien angewendet werden. Abbildung 7 enthält qualitative Ergebnisse für YNet und unser SHENet ohne/mit Kurvenglättung (CS). Die erste Zeile zeigt die Ergebnisse unter Verwendung des MSE-Verlusts . Die von YNet vorhergesagten Trajektorienpunkte werden durch frühere Trajektorien mit etwas Rauschen (z. B. plötzliche und scharfe Kurven) beeinflusst und gruppieren sich und können keine klare Richtung darstellen, während unsere Methode potenzielle Pfade basierend auf historischen Gruppentrajektorien bereitstellen kann. Die beiden Vorhersagen unterscheiden sich optisch, die numerischen Fehler (ADE/FDE) sind jedoch ungefähr gleich. Im Gegensatz dazu sind die qualitativen Ergebnisse unseres vorgeschlagenen CS-Verlusts in der zweiten Zeile von Abbildung 7 dargestellt. Es ist ersichtlich, dass das vorgeschlagene CS den Einfluss von Zufälligkeit und Subjektivität erheblich reduziert und durch YNet und unsere Methode vernünftige Vorhersagen liefert.
Fazit
In diesem Artikel wird SHENet vorgestellt, ein neuartiger Ansatz, der die Geschichte der HTP-Szenarien voll ausnutzt. SHENet enthält ein GTB-Modul zum Aufbau einer Gruppen-Trajektorienbibliothek auf der Grundlage aller historischen Trajektorien und zum Abrufen repräsentativer Trajektorien beobachteter Personen aus der Bibliothek. Außerdem enthält es ein CMI-Modul (Interaktion zwischen menschlicher Bewegung und Umweltinformationen), um diese repräsentative Trajektorie zu verfeinern. Wir erreichen SOTA-Leistung beim HTP-Benchmark und unser Ansatz zeigt erhebliche Verbesserungen und Allgemeingültigkeit in anspruchsvollen Szenarien. Allerdings gibt es im aktuellen Rahmen noch einige unerforschte Aspekte, wie zum Beispiel, dass sich der Bankbauprozess derzeit nur auf menschliche Bewegungen konzentriert. Zukünftige Arbeiten umfassen die weitere Erforschung der Trajektorienbibliothek mithilfe interaktiver Informationen (menschliche Bewegungs- und Szeneninformationen).

Originallink: https://mp.weixin.qq.com/s/GE-t4LarwXJu2MC9njBInQ
Das obige ist der detaillierte Inhalt vonWas sind die effektiven Methoden und gängigen Basismethoden für die Vorhersage der Fußgängerbahn? Teilen der besten Konferenzbeiträge!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Das Verstehen natürlicher Sprache ist ein wichtiges Anwendungsgebiet der künstlichen Intelligenz. Was ist ihr Ziel?
- Was sind die Hauptantriebskräfte für die Entwicklung künstlicher Intelligenz?
- Wie heißt die künstliche Intelligenz von Oppo?
- Wahrnehmungsnetzwerk zur Tiefen-, Lage- und Straßeneinschätzung in gemeinsamen Fahrszenarien
- Smart App Control unter Windows 11: So aktivieren oder deaktivieren Sie es