
Heim >Technologie-Peripheriegeräte >KI >Brechen Sie die Blackbox großer Modelle und zerlegen Sie Neuronen vollständig! OpenAI-Konkurrent Anthropic durchbricht die Barriere der KI-Unerklärbarkeit
Brechen Sie die Blackbox großer Modelle und zerlegen Sie Neuronen vollständig! OpenAI-Konkurrent Anthropic durchbricht die Barriere der KI-Unerklärbarkeit

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-10-08 23:13:011259Durchsuche
Seit vielen Jahren können wir nicht verstehen, wie künstliche Intelligenz Entscheidungen trifft und Ergebnisse generiert.
Modellentwickler können nur über den Algorithmus und die Daten entscheiden und schließlich die Ausgabe des Modells erhalten Das Modell basiert auf diesen Algorithmen und die Ergebnisse der Datenausgabe werden zu unsichtbaren „Black Boxes“.

Es gibt also einen Witz wie „Modelltraining ist wie Alchemie“.
Aber jetzt ist die Modell-Blackbox endlich interpretierbar!
Das Forschungsteam von Anthropic extrahierte die interpretierbaren Merkmale der grundlegendsten Einheitsneuronen im neuronalen Netzwerk des Modells.

Dies wird ein bahnbrechender Schritt für die Menschheit sein, die KI-Blackbox aufzudecken.
Anthropic äußerte sich begeistert:
„Wenn wir verstehen können, wie das neuronale Netzwerk im Modell funktioniert, können wir die Fehlermodi des Modells diagnostizieren, Korrekturen entwerfen und dafür sorgen, dass das Modell sicher von Unternehmen und der Gesellschaft übernommen wird.“ Es wird in greifbarer Nähe Wirklichkeit werden!“
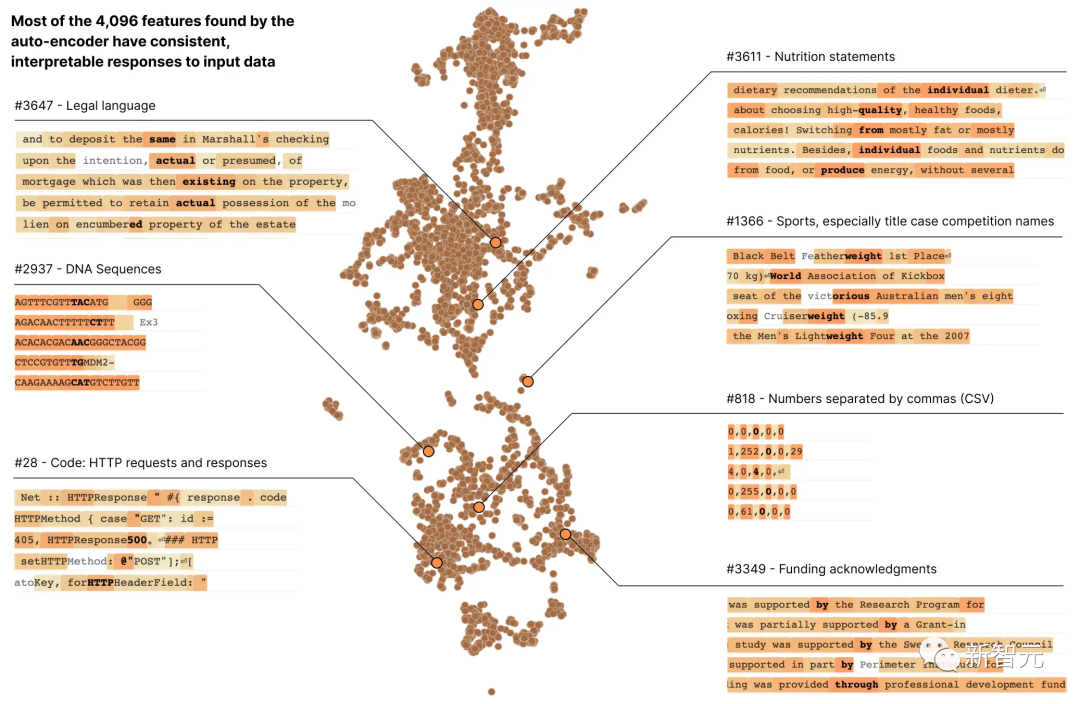
In Anthropics neuestem Forschungsbericht „Toward Monosemantity: Decomposed Language Models with Dictionary Learning“ verwendeten Forscher Wörterbuchlernmethoden, um die Schicht aus 512 Neuronen erfolgreich in mehrere zu zerlegen mehr als 4000 interpretierbare Merkmale Hebräischer Text, Nährwertangaben usw.
 Die meisten dieser Modelleigenschaften können wir nicht erkennen, wenn wir die Aktivierung eines einzelnen Neurons isoliert betrachten.
Die meisten dieser Modelleigenschaften können wir nicht erkennen, wenn wir die Aktivierung eines einzelnen Neurons isoliert betrachten.
Die meisten Neuronen sind „polysemantisch“, was so viel bedeutet Es gibt keine konsistente Entsprechung zwischen einzelnen Neuronen und dem Netzwerkverhalten.
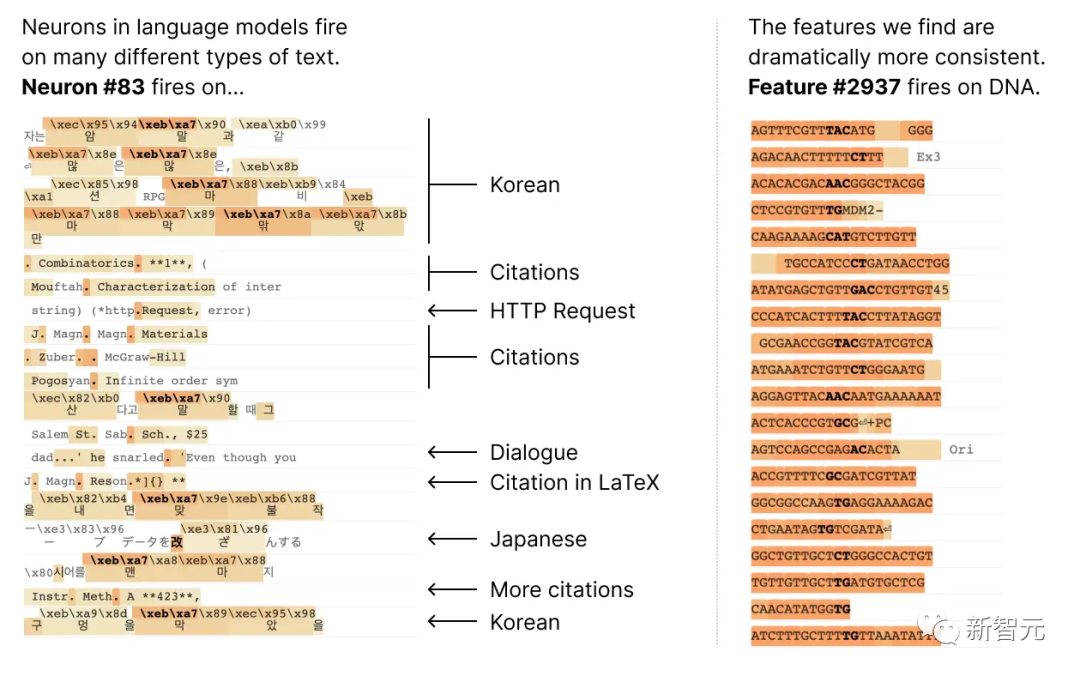
Beispielsweise ist in einem kleinen Sprachmodell ein einzelnes Neuronen-Meta in vielen unabhängigen Kontexten aktiv, darunter: akademische Zitate, englische Konversationen, HTTP-Anfragen und koreanischer Text.
 Und im klassischen Sehmodell würde ein einzelnes Neuron auf das Gesicht einer Katze und die Vorderseite eines Autos reagieren.
Und im klassischen Sehmodell würde ein einzelnes Neuron auf das Gesicht einer Katze und die Vorderseite eines Autos reagieren.
In verschiedenen Zusammenhängen haben viele Studien bewiesen, dass die Aktivierung eines Neurons unterschiedliche Bedeutungen haben kann
Ein möglicher Grund ist, dass die polysemantische Natur von Neuronen auf den Superpositionseffekt zurückzuführen ist. Dies ist ein hypothetisches Phänomen, bei dem neuronale Netze unabhängige Merkmale von Daten darstellen, indem sie jedem Merkmal eine eigene lineare Kombination von Neuronen zuweisen und die Anzahl dieser Merkmale die Anzahl der Neuronen übersteigt Vektor auf dem Neuron, dann bildet der Merkmalssatz eine übervollständige lineare Basis für die Aktivierung der Netzwerkneuronen.
In Anthropics früherem Papier „Toy Models of Superposition“ („Superposition Toy Model“) wurde bewiesen, dass Sparsity Mehrdeutigkeiten beim Training neuronaler Netze beseitigen kann, was dem Modell hilft, die Beziehung zwischen Merkmalen besser zu verstehen und dadurch die Aktivierungsunsicherheit zu reduzieren Die Quelleigenschaften des Vektors machen die Vorhersagen und Entscheidungen des Modells zuverlässiger.
 Dieses Konzept ähnelt der Idee beim Compressed Sensing, wo die Spärlichkeit des Signals es ermöglicht, das vollständige Signal aus begrenzten Beobachtungen wiederherzustellen.
Dieses Konzept ähnelt der Idee beim Compressed Sensing, wo die Spärlichkeit des Signals es ermöglicht, das vollständige Signal aus begrenzten Beobachtungen wiederherzustellen.

Aber unter den drei in Toy Models of Superposition vorgeschlagenen Strategien:
(1) Erstellen von Modellen ohne Überlagerung, möglicherweise Förderung der Aktivierungsparsität;
(2) Anzeigen von Überlagerungen im Zustandsmodell, Wörterbuchlernen wird verwendet, um übervollständige Features zu finden
(3) basiert auf einer Hybridmethode, die beide kombiniert.
Was neu geschrieben werden muss, ist: Methode (1) kann das Mehrdeutigkeitsproblem nicht lösen, während Methode (2) anfällig für starke Überanpassung ist
Daher verwendeten Anthropic-Forscher dieses Mal einen schwachen Wörterbuch-Lernalgorithmus, der als Sparse bezeichnet wird Der Autoencoder generiert erlernte Merkmale aus einem trainierten Modell, die eine einzige semantische Analyseeinheit bereitstellen als die Modellneuronen selbst.
Konkret verwendeten die Forscher einen MLP-Einschichttransformator mit 512 Neuronen und zerlegten schließlich die MLP-Aktivierungen in relativ interpretierbare, indem sie einen spärlichen Autoencoder auf MLP-Aktivierungen aus 8 Milliarden Datenpunkten trainierten. Der Erweiterungsfaktor reicht von 1 × (512 Features) bis 256× (131.072 Features).
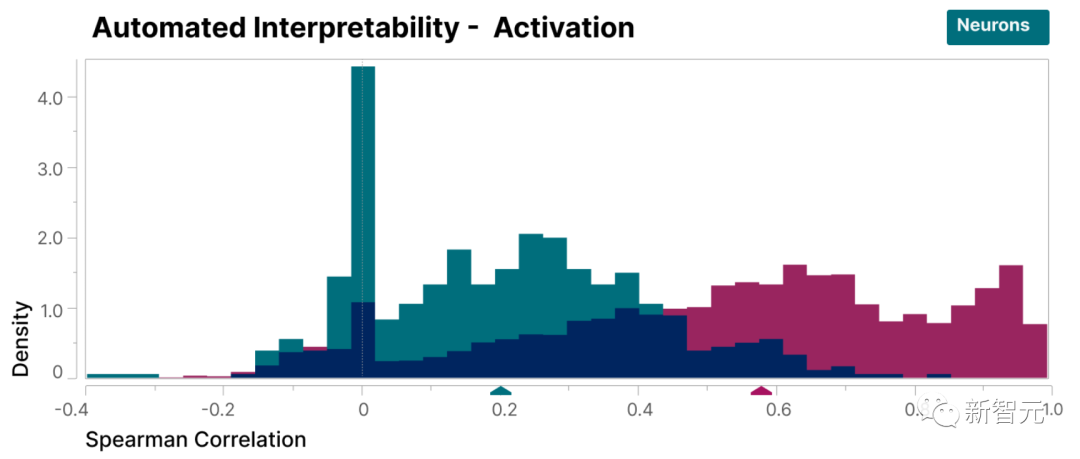
Um zu überprüfen, ob die in dieser Studie gefundenen Merkmale besser interpretierbar sind als die Neuronen des Modells, haben wir eine Blindbewertung durchgeführt und ihre Interpretierbarkeit von einem menschlichen Gutachter bewerten lassen.
Man erkennt, dass die Merkmale (rot) viel höher sind Punkte als Neuronen (Cyan).
Es wurde nachgewiesen, dass die von den Forschern entdeckten Merkmale im Vergleich zu den Neuronen im Modell leichter zu verstehen sind
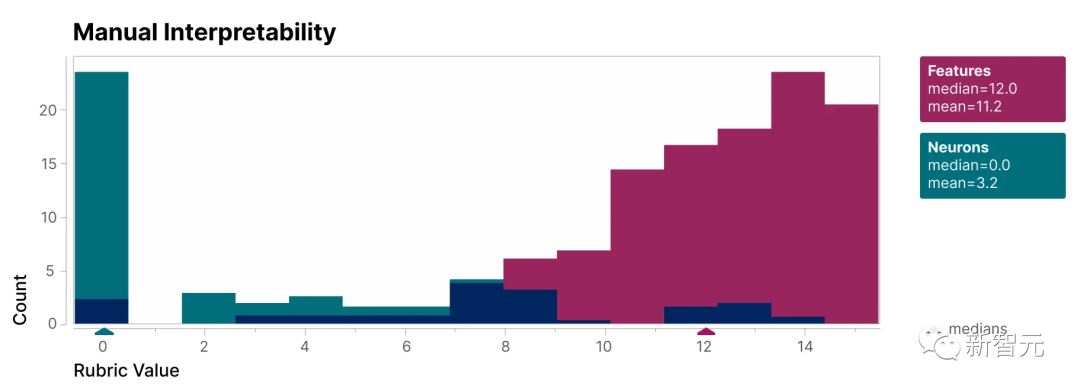
Darüber hinaus haben die Forscher mithilfe von The Large auch eine Methode der „automatischen Interpretierbarkeit“ übernommen Das Sprachmodell generiert eine kurze Beschreibung der Funktionen des kleinen Modells und lässt ein anderes Modell diese Beschreibung basierend auf seiner Fähigkeit, die Funktionsaktivierung vorherzusagen, bewerten.
In ähnlicher Weise erzielen Merkmale eine höhere Punktzahl als Neuronen, was eine konsistente Interpretation der Aktivierung von Merkmalen und ihrer nachgelagerten Auswirkungen auf das Modellverhalten zeigt.
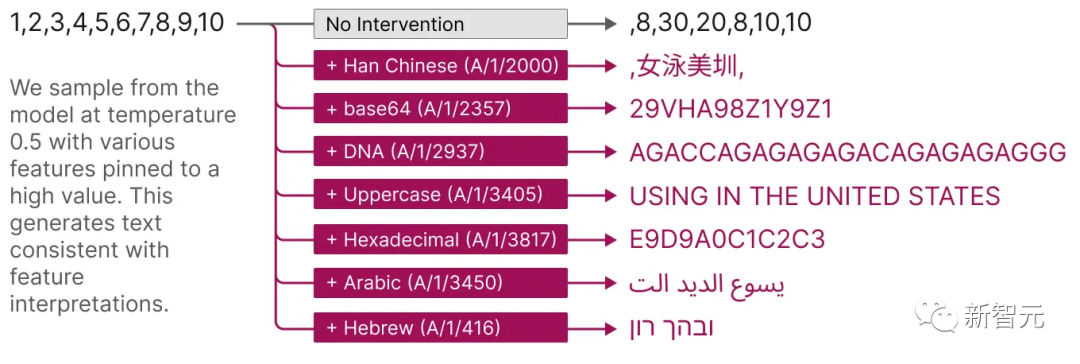
Darüber hinaus bieten diese extrahierten Features auch eine gezielte Methode zur Führung des Modells.
Wie in der Abbildung unten gezeigt, kann die künstliche Aktivierung von Funktionen dazu führen, dass sich das Modellverhalten auf vorhersehbare Weise ändert.
Das Folgende ist eine Visualisierung der extrahierten Interpretierbarkeitsmerkmale:
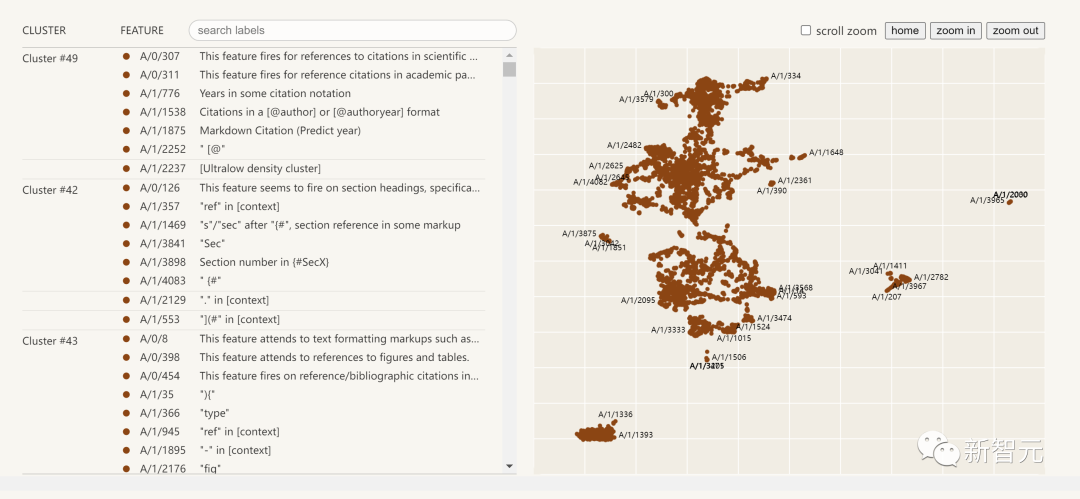
Klicken Sie auf die Funktionsliste auf der linken Seite und Sie können den Funktionsraum im neuronalen Netzwerk interaktiv erkunden.
Forschung Zusammenfassung des Berichts
Dieser Forschungsbericht von Anthropic, Towards Monosemantity: Decomposed Language Models With Dictionary Learning, kann in vier Teile unterteilt werden.
Bei der Problemstellung stellten die Forscher die Forschungsmotivation vor und erläuterten den trainierten Transformator und den Sparse-Autoencoder.
Detaillierte Untersuchung einzelner Merkmale, die beweist, dass mehrere in der Studie gefundene Merkmale funktionsspezifische kausale Einheiten sind.
Durch eine globale Analyse kamen wir zu dem Schluss, dass typische Merkmale interpretierbar sind und wichtige Komponenten der MLP-Schicht erklären können.
Phänomenanalyse, die mehrere Eigenschaften der Merkmale beschreibt, einschließlich Merkmalssegmentierung, Universalitätseigenschaften usw wie sie Systeme bilden, die „Automaten endlicher Zustände“ ähneln, um komplexe Verhaltensweisen zu erreichen.
Die Schlussfolgerungen umfassen die folgenden 7:
Der Sparse-Autoencoder hat die Fähigkeit, relativ einzelne semantische Merkmale zu extrahieren
Sparse-Autoencoder sind in der Lage, interpretierbare Merkmale zu erzeugen, die in der Basis von Neuronen tatsächlich unsichtbar sind.
3 Sparse-Autoencoder können verwendet werden, um einzugreifen und die Erzeugung von Transformatoren zu steuern.
4. Sparse-Autoencoder können relativ allgemeine Funktionen generieren.
Mit zunehmender Größe des Autoencoders neigen Funktionen dazu, sich zu „spalten“. Nach dem Umschreiben: Mit zunehmender Größe des Autoencoders zeigen Features einen Trend zur „Aufteilung“
6. Nur 512 Neuronen können Tausende von Features darstellen
7 Diese Features bilden durch die Verbindung ein System ähnlich einem „Finite-State-Automaton“ erreicht komplexe Verhaltensweisen, wie in der folgenden Abbildung dargestellt
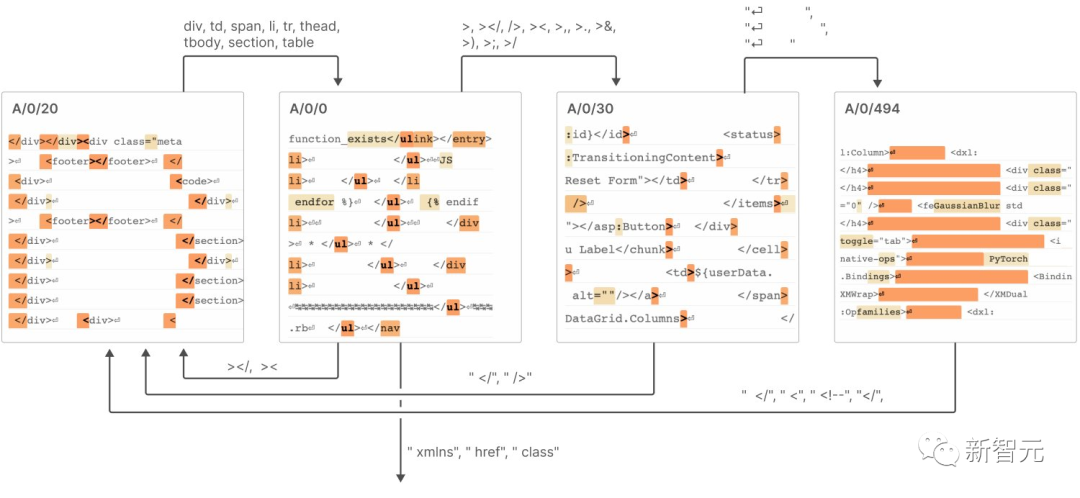
Weitere Einzelheiten finden Sie im Bericht.
Anthropic glaubt, dass die Herausforderung, vor der wir in Zukunft stehen, nicht länger ein wissenschaftliches, sondern ein technisches Problem sein wird, um den Erfolg des kleinen Modells in diesem Forschungsbericht auf ein größeres Modell zu übertragen.
Um dies zu erreichen Die Interpretierbarkeit eines großen Modells erfordert mehr Aufwand und Ressourcen im technischen Bereich, um die Herausforderungen zu meistern, die sich aus der Komplexität und dem Maßstab des Modells ergeben
Einschließlich der Entwicklung neuer Werkzeuge, Techniken und Methoden zur Bewältigung der Herausforderungen der Modellkomplexität und des Datenumfangs; Dazu gehört auch der Aufbau skalierbarer Interpretationsrahmen und Tools, um den Anforderungen großer Modelle gerecht zu werden.
Dies wird der neueste Trend im Bereich interpretativer künstlicher Intelligenz und groß angelegter Deep-Learning-Forschung sein
Das obige ist der detaillierte Inhalt vonBrechen Sie die Blackbox großer Modelle und zerlegen Sie Neuronen vollständig! OpenAI-Konkurrent Anthropic durchbricht die Barriere der KI-Unerklärbarkeit. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie deinstalliere ich den Datenbank-SQL-Server vollständig?
- Die beiden Forschungsgebiete der Künstlichen Intelligenz sind
- Welche Beziehung besteht zwischen Datenbank, Datenbanksystem und Datenbankverwaltungssystem?
- Was sind die Schritte, um mit JDBC eine Verbindung zur Datenbank herzustellen?
- Eine neu veröffentlichte Übersicht über groß angelegte Sprachmodelle: die umfassendste Übersicht von T5 bis GPT-4, gemeinsam verfasst von mehr als 20 inländischen Forschern